

Beste community, Dit artikel gaat over het efficiënt opslaan en ophalen van honderden miljoenen kleine bestanden. In dit stadium wordt de definitieve oplossing voorgesteld voor POSIX-compatibele bestandssystemen met volledige ondersteuning voor vergrendelingen, inclusief clustervergrendelingen, en schijnbaar zelfs zonder krukken.
Daarom heb ik voor dit doel mijn eigen aangepaste server geschreven.
Tijdens de uitvoering van deze taak zijn we erin geslaagd het grootste probleem op te lossen en tegelijkertijd besparingen te realiseren in schijfruimte en RAM, die ons clusterbestandssysteem genadeloos verbruikte. Eigenlijk is een dergelijk aantal bestanden schadelijk voor elk geclusterd bestandssysteem.
Het idee is dit:
In eenvoudige woorden: kleine bestanden worden via de server geüpload, ze worden rechtstreeks in het archief opgeslagen en er ook uit gelezen, en grote bestanden worden naast elkaar geplaatst. Schema: 1 map = 1 archief, in totaal hebben we enkele miljoenen archieven met kleine bestanden, en niet enkele honderden miljoenen bestanden. En dit alles wordt volledig geïmplementeerd, zonder scripts of het plaatsen van bestanden in tar/zip-archieven.
Ik zal proberen het kort te houden, mijn excuses bij voorbaat als het bericht lang is.
Het begon allemaal met het feit dat ik geen geschikte server ter wereld kon vinden die via het HTTP-protocol ontvangen gegevens rechtstreeks in archieven kon opslaan, zonder de nadelen die inherent zijn aan conventionele archieven en objectopslag. En de reden voor de zoektocht was het Origin-cluster van 10 servers dat op grote schaal was gegroeid, waarin zich al 250,000,000 kleine bestanden hadden verzameld, en de groeitrend zou niet stoppen.
Voor degenen die niet graag artikelen lezen, is een beetje documentatie eenvoudiger:
и .
En tegelijkertijd docker, nu is er alleen een optie met nginx erin, voor het geval dat:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdVolgende:
Als er veel bestanden zijn, zijn er aanzienlijke bronnen nodig, en het ergste is dat sommige daarvan verloren gaan. Als u bijvoorbeeld een geclusterd bestandssysteem gebruikt (in dit geval MooseFS), neemt het bestand, ongeacht de werkelijke grootte, altijd minimaal 64 KB in beslag. Dat wil zeggen dat voor bestanden met een grootte van 3, 10 of 30 KB 64 KB op schijf vereist is. Als er een kwart miljard bestanden zijn, verliezen we 2 tot 10 terabytes. Het zal niet mogelijk zijn om voor onbepaalde tijd nieuwe bestanden te maken, aangezien MooseFS een beperking heeft: niet meer dan 1 miljard met één replica van elk bestand.
Naarmate het aantal bestanden toeneemt, is er veel RAM nodig voor metadata. Frequente grote metadatadumps dragen ook bij aan de slijtage van SSD-schijven.
wZD-server. We hebben orde op zaken gesteld op de schijven.
De server is geschreven in Go. Allereerst moest ik het aantal bestanden verminderen. Hoe je dat doet? Vanwege archivering, maar in dit geval zonder compressie, aangezien mijn bestanden slechts gecomprimeerde afbeeldingen zijn. BoltDB kwam te hulp, die nog moest worden geëlimineerd door zijn tekortkomingen, dit komt tot uiting in de documentatie.
In totaal waren er in mijn geval, in plaats van een kwart miljard bestanden, nog maar 10 miljoen Bolt-archieven over. Als ik de mogelijkheid had om de huidige mapbestandsstructuur te wijzigen, zou het mogelijk zijn deze terug te brengen tot ongeveer 1 miljoen bestanden.
Alle kleine bestanden worden ingepakt in Bolt-archieven, die automatisch de namen krijgen van de mappen waarin ze zich bevinden, en alle grote bestanden blijven naast de archieven; het heeft geen zin om ze in te pakken, dit is aanpasbaar. Kleine worden gearchiveerd, grote blijven ongewijzigd. De server werkt transparant met beide.
Architectuur en kenmerken van de wZD-server.

De server werkt onder controle van besturingssystemen. Linux, BSD, Solaris en OSX. Ik heb alleen de AMD64-architectuur getest onder LinuxMaar het zou ook moeten werken voor ARM64, PPC64 en MIPS64.
Belangrijkste kenmerken:
- Multithreading;
- Multiserver, met fouttolerantie en taakverdeling;
- Maximale transparantie voor de gebruiker of ontwikkelaar;
- Ondersteunde HTTP-methoden: GET, HEAD, PUT en DELETE;
- Controle van lees- en schrijfgedrag via clientheaders;
- Ondersteuning voor flexibele virtuele hosts;
- Ondersteuning van CRC-gegevensintegriteit bij schrijven/lezen;
- Semi-dynamische buffers voor minimaal geheugengebruik en optimale afstemming van netwerkprestaties;
- Uitgestelde gegevensverdichting;
- Bovendien wordt een multi-threaded archiver wZA aangeboden voor het migreren van bestanden zonder de service te stoppen.
Echte ervaring:
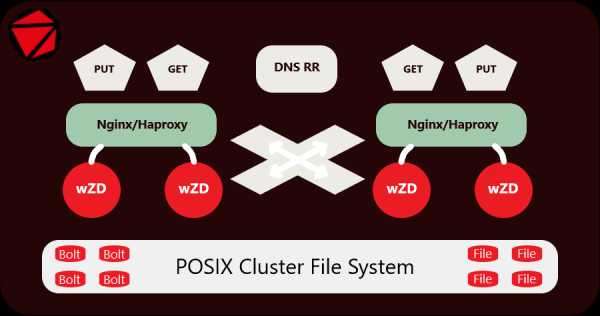
Ik heb de server en het archiveringsprogramma al geruime tijd ontwikkeld en getest op live gegevens, maar nu draait het met succes op een cluster met 250,000,000 kleine bestanden (afbeeldingen) in 15,000,000 mappen op afzonderlijke SATA-schijven. Een cluster van 10 servers is een Origin-server die achter een CDN-netwerk is geïnstalleerd. Om dit te onderhouden worden 2 Nginx-servers + 2 wZD-servers gebruikt.
Voor degenen die besluiten deze server te gebruiken, is het verstandig om, indien van toepassing, vóór gebruik de directorystructuur te plannen. Laat ik meteen voorop stellen dat de server niet bedoeld is om alles in een 1 Bolt-archief te proppen.
Prestatietesten:
Hoe kleiner de grootte van het gecomprimeerde bestand, hoe sneller GET- en PUT-bewerkingen erop worden uitgevoerd. Laten we de totale tijd voor het schrijven van HTTP-clients vergelijken met gewone bestanden en Bolt-archieven, evenals het lezen. Het werk met bestanden met de groottes 32 KB, 256 KB, 1024 KB, 4096 KB en 32768 KB wordt vergeleken.
Bij het werken met Bolt-archieven wordt de gegevensintegriteit van elk bestand gecontroleerd (CRC wordt gebruikt), vóór de opname en ook na de opname vindt er on-the-fly lezen en herberekening plaats. Dit brengt uiteraard vertragingen met zich mee, maar het belangrijkste is de gegevensbeveiliging.
Ik heb prestatietests uitgevoerd op SSD-schijven, omdat tests op SATA-schijven geen duidelijk verschil laten zien.
Grafieken gebaseerd op testresultaten:
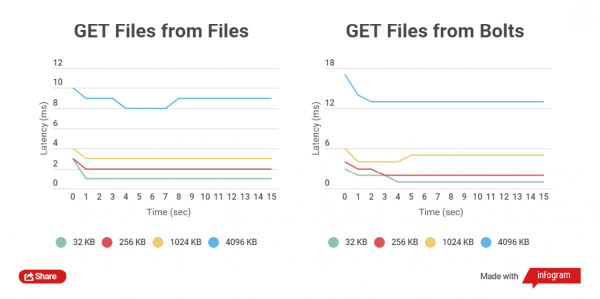
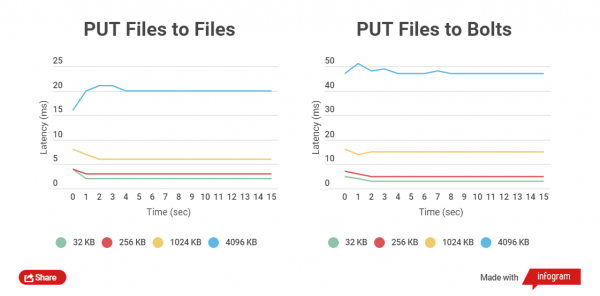
Zoals u kunt zien, is voor kleine bestanden het verschil in lees- en schrijftijden tussen gearchiveerde en niet-gearchiveerde bestanden klein.
Een heel ander beeld krijgen we bij het testen van lees- en schrijfbestanden van 32 MB groot:
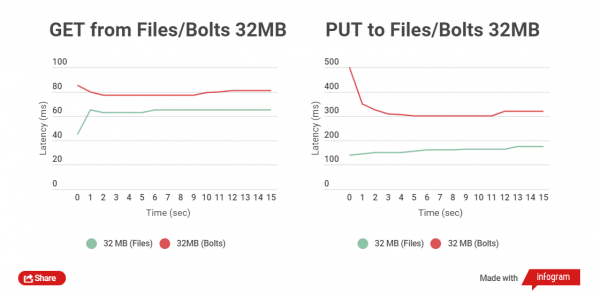
Het tijdsverschil tussen het lezen van bestanden bedraagt 5-25 ms. Bij opnemen is het nog erger, het verschil is ongeveer 150 ms. Maar in dit geval is het niet nodig om grote bestanden te uploaden; het heeft simpelweg geen zin om dit te doen; ze kunnen gescheiden van de archieven leven.
*Technisch gezien kunt u deze server gebruiken voor taken waarvoor NoSQL vereist is.
Basismethoden voor het werken met de wZD-server:
Een normaal bestand laden:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgEen bestand uploaden naar het Bolt-archief (als de serverparameter fmaxsize, die de maximale bestandsgrootte bepaalt die in het archief kan worden opgenomen, niet wordt overschreden; als deze wordt overschreden, wordt het bestand zoals gebruikelijk naast het archief geüpload):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgEen bestand downloaden (als er bestanden met dezelfde naam op de schijf en in het archief staan, wordt bij het downloaden standaard prioriteit gegeven aan het niet-gearchiveerde bestand):
curl -o test.jpg http://localhost/test/test.jpgEen bestand downloaden uit het Bolt-archief (geforceerd):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgBeschrijvingen van andere methoden staan in de documentatie.
De server ondersteunt momenteel alleen het HTTP-protocol; deze werkt nog niet met HTTPS. De POST-methode wordt ook niet ondersteund (er is nog niet besloten of deze nodig is of niet).
Iedereen die in de broncode graaft, zal daar butterscotch vinden, niet iedereen vindt het leuk, maar ik heb de hoofdcode niet aan de functies van het webframework gekoppeld, behalve de interrupthandler, dus in de toekomst kan ik het snel herschrijven voor vrijwel elk motor.
ToDo:
- Ontwikkeling van uw eigen replicator en distributeur + geo voor de mogelijkheid tot gebruik in grote systemen zonder clusterbestandssystemen (Alles voor volwassenen)
- Mogelijkheid tot volledig omgekeerd herstel van metadata als deze volledig verloren is gegaan (bij gebruik van een distributeur)
- Native protocol voor de mogelijkheid om persistente netwerkverbindingen en stuurprogramma's voor verschillende programmeertalen te gebruiken
- Geavanceerde mogelijkheden voor het gebruik van de NoSQL-component
- Compressies van verschillende typen (gzip, zstd, snappy) voor bestanden of waarden in Bolt-archieven en voor gewone bestanden
- Versleuteling van verschillende typen voor bestanden of waarden in Bolt-archieven en voor gewone bestanden
- Vertraagde videoconversie aan de serverzijde, ook op GPU
Ik heb alles, ik hoop dat deze server voor iemand nuttig zal zijn, BSD-3-licentie, dubbel auteursrecht, want als er geen bedrijf was waar ik werk, zou de server niet zijn geschreven. Ik ben de enige ontwikkelaar. Ik zou dankbaar zijn voor eventuele bugs en functieverzoeken die u tegenkomt.
Bron: www.habr.com
