

Op 26 februari hielden we een Apache Ignite GreenSource-bijeenkomst, waar bijdragers aan het open source-project spraken . Een belangrijke gebeurtenis in het leven van deze gemeenschap was de herstructurering van de component , waarmee u aangepaste microservices rechtstreeks in een Ignite-cluster kunt implementeren. Tijdens de bijeenkomst sprak hij over dit moeilijke proces , software-ingenieur en bijdrager aan Apache Ignite gedurende meer dan twee jaar.
Laten we beginnen met wat Apache Ignite in het algemeen is. Dit is een database die een gedistribueerde sleutel/waarde-opslag is met ondersteuning voor SQL, transactionaliteit en caching. Bovendien kunt u met Ignite aangepaste services rechtstreeks in een Ignite-cluster implementeren. De ontwikkelaar heeft toegang tot alle tools die Ignite biedt: gedistribueerde datastructuren, Messaging, Streaming, Compute en Data Grid. Bij het gebruik van Data Grid verdwijnt bijvoorbeeld het probleem van het beheren van een aparte infrastructuur voor dataopslag en, als gevolg daarvan, de daaruit voortvloeiende overheadkosten.
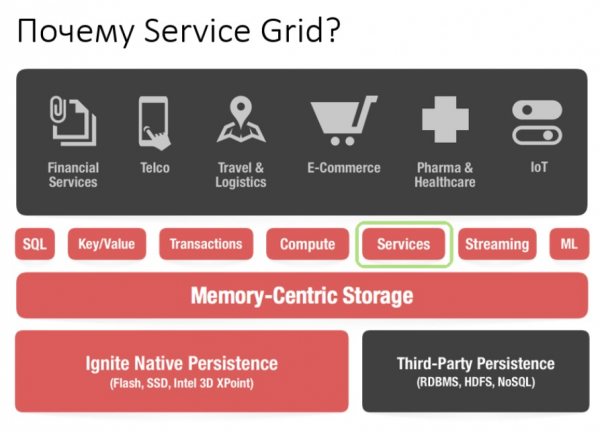
Met behulp van de Service Grid API kunt u een service implementeren door eenvoudigweg het implementatieschema en daarmee de service zelf in de configuratie op te geven.
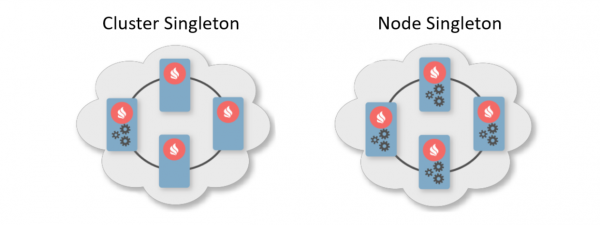
Normaal gesproken is een implementatieschema een indicatie van het aantal exemplaren dat op clusterknooppunten moet worden geïmplementeerd. Er zijn twee typische implementatieschema's. De eerste is Cluster Singleton: op elk moment is gegarandeerd één exemplaar van een gebruikersservice beschikbaar in het cluster. De tweede is Node Singleton: op elk clusterknooppunt wordt één exemplaar van de service geïmplementeerd.
De gebruiker kan ook het aantal service-instanties in het gehele cluster opgeven en een predicaat definiëren voor het filteren van geschikte knooppunten. In dit scenario berekent Service Grid zelf de optimale verdeling voor het inzetten van services.
Daarnaast is er een functie als Affinity Service. Affiniteit is een functie die de relatie van sleutels tot partities en de relatie van partijen tot knooppunten in de topologie definieert. Met behulp van de sleutel kunt u bepalen op welk primair knooppunt de gegevens worden opgeslagen. Op deze manier kunt u uw eigen service koppelen aan een sleutel- en affiniteitsfunctiecache. Als de affiniteitsfunctie verandert, vindt automatische herschikking plaats. Op deze manier zal de dienst zich altijd dicht bij de gegevens bevinden die hij moet manipuleren, en daardoor de overhead bij het verkrijgen van toegang tot informatie verminderen. Dit schema kan een soort collocated computing worden genoemd.
Nu we erachter zijn gekomen wat het mooie van Service Grid is, gaan we het hebben over de ontwikkelingsgeschiedenis ervan.
Wat er eerder gebeurde
De vorige implementatie van Service Grid was gebaseerd op Ignite's transactioneel gerepliceerde systeemcache. Het woord "cache" in Ignite verwijst naar opslag. Dat wil zeggen, dit is niet iets tijdelijks, zoals je misschien denkt. Ondanks het feit dat de cache wordt gerepliceerd en elk knooppunt de volledige dataset bevat, heeft deze binnen de cache een gepartitioneerde representatie. Dit komt door opslagoptimalisatie.
Wat gebeurde er toen de gebruiker de service wilde implementeren?
- Alle knooppunten in het cluster hebben zich geabonneerd om gegevens in de opslag bij te werken met behulp van het ingebouwde Continuous Query-mechanisme.
- Het initiërende knooppunt maakte onder een voor lezen vastgelegde transactie een record in de database dat de serviceconfiguratie bevatte, inclusief het geserialiseerde exemplaar.
- Bij melding van een nieuwe inschrijving berekende de coördinator de verdeling op basis van de configuratie. Het resulterende object werd teruggeschreven naar de database.
- Als een knooppunt deel uitmaakte van de distributie, moest de coördinator het inzetten.
Wat ons niet beviel
Op een gegeven moment kwamen we tot de conclusie: dit is niet de manier om met diensten te werken. Er waren verschillende redenen.
Als er tijdens de implementatie een fout is opgetreden, kan deze alleen worden achterhaald via de logboeken van het knooppunt waar alles is gebeurd. Er was alleen sprake van asynchrone implementatie, dus na het teruggeven van de controle aan de gebruiker vanuit de implementatiemethode was er wat extra tijd nodig om de service te starten - en gedurende deze tijd had de gebruiker nergens controle over. Om het Service Grid verder te ontwikkelen, nieuwe functies te creëren, nieuwe gebruikers aan te trekken en ieders leven gemakkelijker te maken, moet er iets veranderen.
Bij het ontwerpen van het nieuwe Service Grid wilden we allereerst een garantie bieden voor synchrone inzet: zodra de gebruiker de controle terugkrijgt vanuit de API, kan hij direct gebruik maken van de diensten. Ik wilde de initiatiefnemer ook de mogelijkheid geven om implementatiefouten op te lossen.
Daarnaast wilde ik de implementatie vereenvoudigen, namelijk wegkomen van transacties en herbalanceren. Ondanks het feit dat de cache wordt gerepliceerd en er geen sprake is van balancering, ontstonden er problemen tijdens een grote implementatie met veel knooppunten. Wanneer de topologie verandert, moeten knooppunten informatie uitwisselen, en bij een grote implementatie kunnen deze gegevens veel wegen.
Wanneer de topologie onstabiel was, moest de coördinator de distributie van diensten herberekenen. En over het algemeen kan dit, als u met transacties op een onstabiele topologie moet werken, leiden tot moeilijk te voorspellen fouten.
Problemen
Wat zijn mondiale veranderingen zonder bijkomende problemen? De eerste hiervan was een verandering in de topologie. U moet begrijpen dat een knooppunt op elk moment, zelfs op het moment van de service-implementatie, het cluster kan binnenkomen of verlaten. Als het knooppunt zich op het moment van de implementatie bij het cluster voegt, zal het bovendien nodig zijn om op consistente wijze alle informatie over de services naar het nieuwe knooppunt over te dragen. En dan hebben we het niet alleen over wat er al is ingezet, maar ook over de huidige en toekomstige inzet.
Dit is slechts een van de problemen die in een aparte lijst kunnen worden verzameld:
- Hoe statisch geconfigureerde services implementeren bij het opstarten van een knooppunt?
- Een knooppunt uit het cluster verlaten: wat te doen als het knooppunt services host?
- Wat te doen als de coördinator is gewijzigd?
- Wat moet ik doen als de client opnieuw verbinding maakt met het cluster?
- Moeten activatie-/deactiveringsverzoeken worden verwerkt en hoe?
- Wat als ze oproepen tot vernietiging van de cache, en we daaraan gekoppelde affiniteitsdiensten hebben?
En dat is niet alles.
beslissing
Als doel kozen wij voor de Event Driven aanpak met de implementatie van procescommunicatie door middel van berichten. Ignite implementeert al twee componenten waarmee knooppunten onderling berichten kunnen doorsturen: communicatie-spi en ontdekkings-spi.
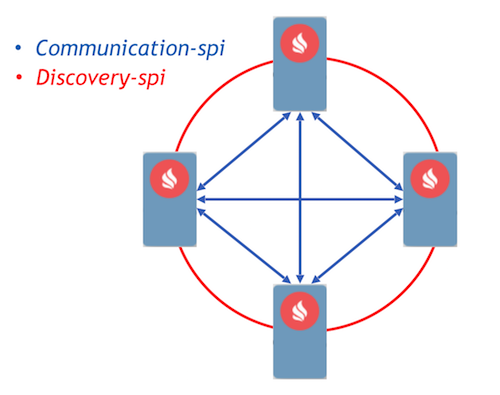
Met Communication-spi kunnen knooppunten rechtstreeks communiceren en berichten doorsturen. Het is zeer geschikt voor het verzenden van grote hoeveelheden gegevens. Met Discovery-spi kunt u een bericht naar alle knooppunten in het cluster sturen. In de standaardimplementatie gebeurt dit met behulp van een ringtopologie. Ook is er integratie met Zookeeper, in dit geval wordt gebruik gemaakt van een stertopologie. Een ander belangrijk punt dat het vermelden waard is, is dat discovery-spi garanties biedt dat het bericht zeker in de juiste volgorde bij alle knooppunten wordt afgeleverd.
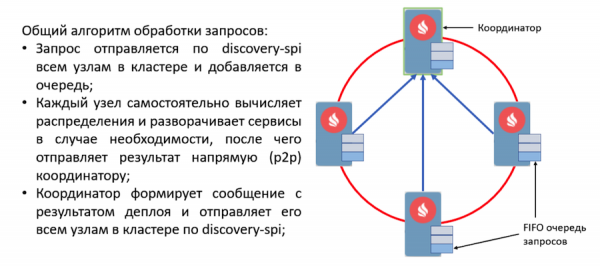
Laten we eens kijken naar het implementatieprotocol. Alle gebruikersverzoeken voor implementatie en unimplementatie worden verzonden via Discovery-spi. Dit geeft het volgende garantie:
- Het verzoek wordt door alle knooppunten in het cluster ontvangen. Hierdoor kan de aanvraag worden voortgezet wanneer de coördinator verandert. Dit betekent ook dat elk knooppunt in één bericht alle benodigde metagegevens heeft, zoals de serviceconfiguratie en het geserialiseerde exemplaar ervan.
- Een strikte volgorde van de berichtbezorging helpt bij het oplossen van configuratieconflicten en concurrerende verzoeken.
- Omdat de toegang van het knooppunt tot de topologie ook via discovery-spi wordt verwerkt, ontvangt het nieuwe knooppunt alle gegevens die nodig zijn om met services te werken.
Wanneer een aanvraag wordt ontvangen, valideren knooppunten in het cluster deze en creëren ze verwerkingstaken. Deze taken worden in de wachtrij geplaatst en vervolgens door een afzonderlijke werker in een andere thread verwerkt. Het wordt op deze manier geïmplementeerd omdat de implementatie een aanzienlijke hoeveelheid tijd kan vergen en de dure ontdekkingsstroom ondraaglijk kan vertragen.
Alle verzoeken uit de wachtrij worden verwerkt door de Deployment Manager. Het heeft een speciale werker die een taak uit deze wachtrij haalt en deze initialiseert om met de implementatie te beginnen. Hierna vinden de volgende acties plaats:
- Elk knooppunt berekent onafhankelijk de verdeling dankzij een nieuwe deterministische toewijzingsfunctie.
- Nodes genereren een bericht met de resultaten van de inzet en sturen dit naar de coördinator.
- De coördinator verzamelt alle berichten en genereert het resultaat van het gehele implementatieproces, dat via discovery-spi naar alle knooppunten in het cluster wordt verzonden.
- Wanneer het resultaat wordt ontvangen, eindigt het implementatieproces, waarna de taak uit de wachtrij wordt verwijderd.
Nieuw gebeurtenisgestuurd ontwerp: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Als er tijdens de implementatie een fout optreedt, neemt het knooppunt deze fout onmiddellijk op in een bericht dat het naar de coördinator verzendt. Na het verzamelen van berichten heeft de coördinator informatie over alle fouten tijdens de implementatie en verzendt dit bericht via Discovery-spi. Foutinformatie is beschikbaar op elk knooppunt in het cluster.
Alle belangrijke gebeurtenissen in het Service Grid worden verwerkt met behulp van dit bedieningsalgoritme. Het wijzigen van de topologie is bijvoorbeeld ook een bericht via discovery-spi. En over het algemeen bleek het protocol, vergeleken met wat voorheen was, vrij licht en betrouwbaar. Genoeg om elke situatie tijdens de inzet aan te kunnen.
Wat zal er daarna gebeuren?
Nu over de plannen. Elke grote wijziging in het Ignite-project wordt voltooid als een Ignite-verbeteringsinitiatief, een zogenaamde IEP. Het herontwerp van het Service Grid heeft ook een IEP - met de spottende titel “Olieverversing in het servicenet”. Maar feitelijk hebben we niet de motorolie ververst, maar de hele motor.
We hebben de taken in het IEP opgedeeld in 2 fases. De eerste is een belangrijke fase, die bestaat uit het herwerken van het implementatieprotocol. Het is al opgenomen in de master, u kunt het nieuwe Service Grid proberen, dat in versie 2.8 verschijnt. De tweede fase omvat vele andere taken:
- Heet opnieuw inzetten
- Serviceversiebeheer
- Verhoogde fouttolerantie
- Thin-client
- Hulpmiddelen voor het monitoren en berekenen van verschillende statistieken
Tot slot kunnen wij u adviseren over Service Grid voor het bouwen van fouttolerante systemen met hoge beschikbaarheid. Wij nodigen u ook uit om ons te bezoeken op и deel uw ervaring. Jouw ervaring is erg belangrijk voor de gemeenschap; het zal je helpen te begrijpen waar je heen moet en hoe je het onderdeel in de toekomst kunt ontwikkelen.
Bron: www.habr.com
