

Hallo allemaal, mijn naam is Alexander, ik werk bij CIAN als engineer en houd mij bezig met systeembeheer en automatisering van infrastructuurprocessen. In de reacties op een van de vorige artikelen werd ons gevraagd te vertellen waar we 4 TB aan logs per dag vandaan halen en wat we ermee doen. Ja, we hebben veel logbestanden en er is een apart infrastructuurcluster gemaakt om deze te verwerken, waardoor we problemen snel kunnen oplossen. In dit artikel zal ik vertellen hoe we het in de loop van een jaar hebben aangepast om te kunnen werken met een steeds groeiende stroom aan gegevens.
Waar zijn we begonnen?
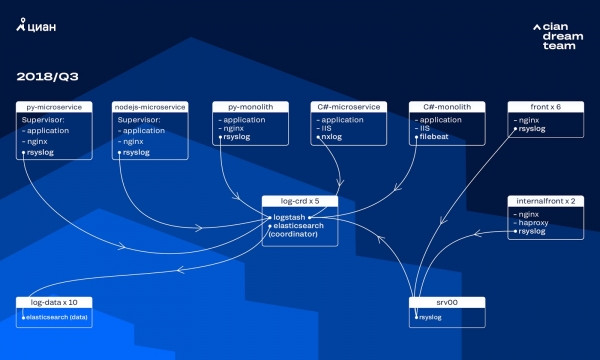
De afgelopen jaren is de belasting op cian.ru zeer snel gegroeid en in het derde kwartaal van 2018 bereikte het resourceverkeer 11.2 miljoen unieke gebruikers per maand. Op dat moment raakten we op kritieke momenten tot 40% van de logs kwijt, waardoor we incidenten niet snel konden afhandelen en veel tijd en moeite besteedden aan het oplossen ervan. Ook konden we vaak de oorzaak van het probleem niet vinden en kwam het na enige tijd weer terug. Het was een hel en er moest iets aan gedaan worden.
Destijds gebruikten we een cluster van 10 dataknooppunten met ElasticSearch versie 5.5.2 met standaard indexinstellingen om logs op te slaan. Het werd meer dan een jaar geleden geïntroduceerd als een populaire en betaalbare oplossing: toen was de stroom logboeken niet zo groot, het had geen zin om met niet-standaard configuraties te komen.
De verwerking van inkomende logs werd verzorgd door Logstash op verschillende poorten op vijf ElasticSearch-coördinatoren. Eén index, ongeacht de grootte, bestond uit vijf scherven. Er werd een rotatie per uur en per dag georganiseerd, waardoor er elk uur ongeveer 100 nieuwe scherven in de cluster verschenen. Hoewel er niet veel logboeken waren, kon het cluster het goed doen en lette niemand op de instellingen.
De uitdagingen van snelle groei
Het aantal gegenereerde logboeken groeide zeer snel, omdat twee processen elkaar overlapten. Enerzijds groeide het aantal gebruikers van de dienst. Aan de andere kant zijn we actief overgestapt op een microservice-architectuur, waarbij we onze oude monolieten in C# en Python hebben verzaagd. Enkele tientallen nieuwe microservices die delen van de monoliet vervingen, genereerden aanzienlijk meer logboeken voor het infrastructuurcluster.
Het was de schaalvergroting die ons op het punt bracht waarop het cluster praktisch onbeheersbaar werd. Toen de logboeken met een snelheid van 20 berichten per seconde arriveerden, verhoogde de frequente nutteloze rotatie het aantal shards tot 6, en er waren meer dan 600 shards per knooppunt.
Dit leidde tot problemen met de RAM-toewijzing, en wanneer een node crashte, migreerden alle shards tegelijkertijd, waardoor het verkeer toenam en de resterende nodes overbelast raakten, wat het vrijwel onmogelijk maakte om gegevens naar het cluster te schrijven. En gedurende deze periode hadden we geen logs. En als er een probleem was met server We verloren 1/10 van het cluster in totaal. Het grote aantal kleine indexen droeg bij aan de complexiteit.
Zonder logboeken begrepen we de redenen voor het incident niet en zouden we vroeg of laat weer op dezelfde hark kunnen stappen, en in de ideologie van ons team was dit onaanvaardbaar, aangezien al onze werkmechanismen zijn ontworpen om precies het tegenovergestelde te doen: nooit herhalen dezelfde problemen. Om dit te doen hadden we het volledige volume aan logboeken nodig en de levering ervan vrijwel in realtime, omdat een team van dienstdoende technici waarschuwingen niet alleen op basis van statistieken, maar ook op basis van logboeken bewaakte. Om de omvang van het probleem te begrijpen: op dat moment bedroeg het totale volume aan logboeken ongeveer 2 TB per dag.
We hebben ons ten doel gesteld om het verlies van logs volledig te elimineren en de tijd van levering ervan aan het ELK-cluster te verkorten tot maximaal 15 minuten tijdens overmacht (we hebben dit cijfer later als interne KPI gebruikt).
Nieuw rotatiemechanisme en warm-warme knooppunten
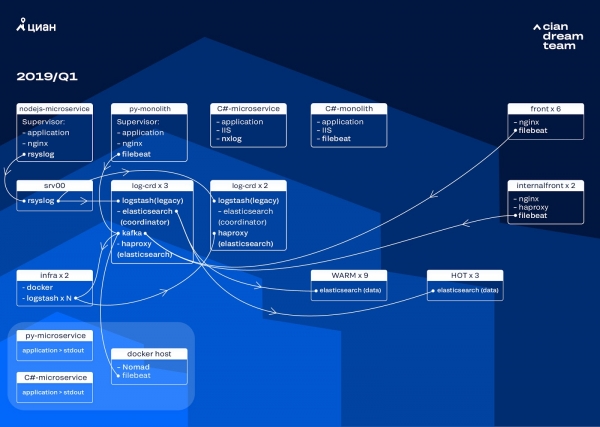
We zijn de clusterconversie gestart door de ElasticSearch-versie bij te werken van 5.5.2 naar 6.4.3. Opnieuw stierf ons versie 5-cluster en we besloten het uit te schakelen en volledig bij te werken - er zijn nog steeds geen logboeken. We hebben deze overstap dus in slechts een paar uur gemaakt.
De meest grootschalige transformatie in dit stadium was de implementatie van Apache Kafka op drie knooppunten met een coördinator als tussenbuffer. De berichtenmakelaar heeft ervoor gezorgd dat we geen logbestanden kwijtraakten tijdens problemen met ElasticSearch. Tegelijkertijd hebben we twee knooppunten aan het cluster toegevoegd en zijn we overgestapt op een warm-warme architectuur met drie ‘hot’ knooppunten in verschillende racks in het datacenter. We hebben logs naar hen doorgestuurd met behulp van een masker dat onder geen enkele omstandigheid verloren mag gaan: nginx, evenals logs met applicatiefouten. Kleine logs werden naar de resterende knooppunten gestuurd - foutopsporing, waarschuwingen, enz., en na 2 uur werden "belangrijke" logs van "hot" knooppunten overgedragen.
Om het aantal kleine indexen niet te vergroten, zijn we overgestapt van tijdrotatie naar het rollover-mechanisme. Er was veel informatie op de forums dat rotatie op basis van indexgrootte zeer onbetrouwbaar is, dus hebben we besloten om rotatie op basis van het aantal documenten in de index te gebruiken. We analyseerden elke index en registreerden het aantal documenten waarna rotatie zou moeten werken. We hebben dus de optimale scherfgrootte bereikt: niet meer dan 50 GB.
Clusteroptimalisatie
Toch zijn we nog niet helemaal van de problemen af. Helaas verschenen er nog steeds kleine indexen: ze bereikten het opgegeven volume niet, werden niet geroteerd en werden verwijderd door het globaal opschonen van indexen ouder dan drie dagen, omdat we de rotatie op datum hadden verwijderd. Dit leidde tot gegevensverlies doordat de index volledig uit het cluster verdween, en een poging om naar een niet-bestaande index te schrijven doorbrak de logica van de curator die we voor het beheer gebruikten. Alias voor schrijven werd omgezet in een index en doorbrak de rollover-logica, waardoor sommige indexen ongecontroleerd groeiden tot 600 GB.
Voor de rotatieconfiguratie bijvoorbeeld:
сurator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Als er geen rollover-alias was, is er een fout opgetreden:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
We lieten de oplossing voor dit probleem over aan de volgende iteratie en pakten een ander probleem op: we schakelden over op de pull-logica van Logstash, die binnenkomende logs verwerkt (onnodige informatie verwijdert en verrijkt). We hebben het in docker geplaatst, dat we starten via docker-compose, en we hebben daar ook logstash-exporter geplaatst, die statistieken naar Prometheus stuurt voor operationele monitoring van de logstroom. Op deze manier gaven we onszelf de mogelijkheid om het aantal logstash-instances dat verantwoordelijk is voor de verwerking van elk type log soepel te wijzigen.
Terwijl we het cluster aan het verbeteren waren, steeg het verkeer op cian.ru tot 12,8 miljoen unieke gebruikers per maand. Als gevolg hiervan bleek dat onze transformaties een beetje achterliepen op de veranderingen in de productie, en we werden geconfronteerd met het feit dat de "warme" knooppunten de belasting niet aankonden en de hele levering van logboeken vertraagden. We ontvingen zonder problemen ‘hot’ data, maar we moesten ingrijpen in de levering van de rest en een handmatige rollover uitvoeren om de indexen gelijkmatig te verdelen.
Tegelijkertijd werd het schalen en wijzigen van de instellingen van logstash-instanties in het cluster gecompliceerd door het feit dat het een lokale docker-compositie was en dat alle acties handmatig werden uitgevoerd (om nieuwe doelen toe te voegen was het nodig om handmatig alle acties te doorlopen). de servers en doe overal docker-compose up -d).
Herdistributie van logboeken
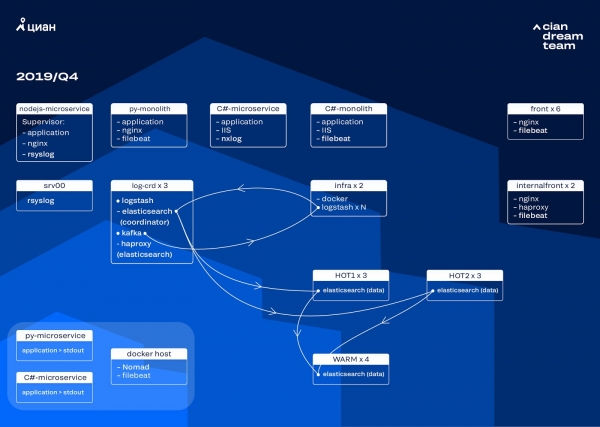
In september van dit jaar waren we nog steeds bezig met het in stukken snijden van de monoliet, de belasting van het cluster nam toe en de stroom logboeken naderde de 30 berichten per seconde.
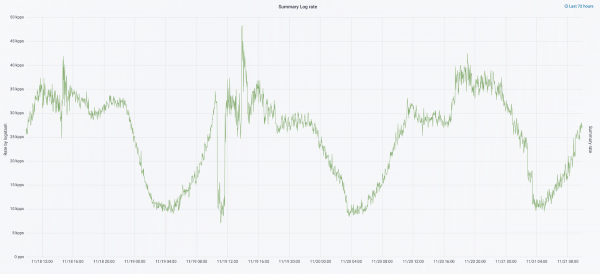
We zijn de volgende iteratie begonnen met een hardware-update. We zijn overgestapt van vijf coördinatoren naar drie, hebben dataknooppunten vervangen en hebben gewonnen qua geld en opslagruimte. Voor knooppunten gebruiken we twee configuraties:
- Voor “hot” knooppunten: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 voor Hot1 en 3 voor Hot2).
- Voor “warme” knooppunten: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Bij deze iteratie hebben we de index met toegangslogboeken van microservices, die dezelfde ruimte in beslag nemen als front-line nginx-logboeken, verplaatst naar de tweede groep van drie ‘hot’ knooppunten. We slaan nu gegevens op ‘hot’ knooppunten gedurende 20 uur op en dragen ze vervolgens over naar ‘warme’ knooppunten naar de rest van de logs.
We hebben het probleem van het verdwijnen van kleine indexen opgelost door hun rotatie opnieuw te configureren. Nu worden de indexen in ieder geval elke 23 uur geroteerd, ook al zijn er weinig gegevens. Hierdoor is het aantal shards enigszins toegenomen (er waren er ongeveer 800), maar vanuit het oogpunt van clusterprestaties is dit aanvaardbaar.
Als gevolg hiervan waren er zes ‘hete’ en slechts vier ‘warme’ knooppunten in het cluster. Dit veroorzaakt een kleine vertraging bij verzoeken over lange tijdsintervallen, maar het vergroten van het aantal knooppunten in de toekomst zal dit probleem oplossen.
Deze iteratie loste ook het probleem op van het ontbreken van semi-automatische schaling. Om dit te doen, hebben we een Nomad-infrastructuurcluster geïmplementeerd, vergelijkbaar met wat we al in productie hebben geïmplementeerd. Voorlopig verandert de hoeveelheid Logstash niet automatisch afhankelijk van de belasting, maar daar komen we wel op terug.
Plannen voor de toekomst
De geïmplementeerde configuratie is perfect schaalbaar en nu slaan we 13,3 TB aan gegevens op - alle logboeken voor 4 dagen, wat nodig is voor noodanalyse van waarschuwingen. Een deel van de logs zetten we om in statistieken, die we toevoegen aan Graphite. Om het werk van technici eenvoudiger te maken, beschikken we over statistieken voor het infrastructuurcluster en scripts voor semi-automatische reparatie van veelvoorkomende problemen. Na de uitbreiding van het aantal dataknooppunten, die gepland staat voor volgend jaar, gaan we over op dataopslag van 4 naar 7 dagen. Voor operationeel werk zal dit voldoende zijn, aangezien we incidenten altijd zo snel mogelijk proberen te onderzoeken, en voor langetermijnonderzoeken zijn er telemetriegegevens.
In oktober 2019 was het verkeer naar cian.ru al gegroeid tot 15,3 miljoen unieke gebruikers per maand. Dit werd een serieuze test van de architectonische oplossing voor het aanleveren van logs.
Nu bereiden we ons voor om ElasticSearch bij te werken naar versie 7. Hiervoor zullen we echter de toewijzing van veel indexen in ElasticSearch moeten bijwerken, aangezien ze zijn overgestapt van versie 5.5 en in versie 6 als verouderd zijn verklaard (ze bestaan eenvoudigweg niet in versie 7). 7). Dit betekent dat er tijdens het updateproces zeker sprake zal zijn van een vorm van overmacht, waardoor we zonder logbestanden achterblijven terwijl het probleem is opgelost. Van versie XNUMX kijken we het meeste uit naar Kibana met een verbeterde interface en nieuwe filters.
We hebben ons hoofddoel bereikt: we zijn gestopt met het verliezen van logs en hebben de downtime van het infrastructuurcluster teruggebracht van 2-3 crashes per week naar een paar uur onderhoudswerk per maand. Al dit werk in de productie is bijna onzichtbaar. Nu we echter precies kunnen bepalen wat er met onze service gebeurt, kunnen we dit snel in een stille modus doen en hoeven we ons geen zorgen te maken dat de logs verloren gaan. Over het algemeen zijn we tevreden, gelukkig en bereiden we ons voor op nieuwe exploits, waarover we later zullen praten.
Bron: www.habr.com
