


Hallo Habr! Ik ben Artem Karamyshev, hoofd van het systeembeheerteam. Het afgelopen jaar hebben we veel nieuwe producten gelanceerd. We wilden ervoor zorgen dat API-services eenvoudig schaalbaar, fouttolerant en klaar voor een snelle groei van de gebruikersbelasting waren. Ons platform is geïmplementeerd op OpenStack, en ik wil u graag vertellen welke componentfouttolerantieproblemen we moesten oplossen om een fouttolerant systeem te krijgen. Ik denk dat dit interessant zal zijn voor degenen die ook producten op OpenStack ontwikkelen.
De algehele veerkracht van het platform wordt bepaald door de veerkracht van de componenten ervan. We zullen dus geleidelijk alle niveaus doorlopen waar we risico's hebben geïdentificeerd en opgelost.
Een videoversie van dit verhaal, waarvan de oorspronkelijke bron een presentatie was op de Uptime dag 4-conferentie, georganiseerd door , je kan zien .
Fysieke architectuurfouttolerantie
Het publieke deel van de MCS-cloud is momenteel ondergebracht in twee Tier III-datacenters, met daartussen een private dark fiber, die op fysiek niveau via verschillende routes is gereserveerd, met een doorvoersnelheid van 200 Gbps. Tier III biedt de benodigde fouttolerantie voor de fysieke infrastructuur.
Dark fiber is zowel fysiek als logisch redundant. Het proces van redundantie van kanalen verliep iteratief, er ontstonden problemen en we verbeteren voortdurend de verbinding tussen datacenters.
Zo doorboorde een graafmachine onlangs tijdens werkzaamheden in een boorput nabij een van de datacenters een pijp, en zowel de hoofd- als de reservekabels bevonden zich in die pijp. Ons fouttolerante communicatiekanaal met het datacenter bleek op een punt in de boorput kwetsbaar. Daardoor verloren we een deel van de infrastructuur. We trokken conclusies en ondernamen een aantal acties, waaronder het aanleggen van extra optische kabels via de aangrenzende boorput.
Datacenters beschikken over points of presence (PPS) van communicatieproviders, naar wie we onze prefixes via BGP uitzenden. Voor elke netwerkrichting wordt de beste metriek geselecteerd, waardoor we verschillende clients de beste verbindingskwaliteit kunnen bieden. Als de verbinding via één provider wordt verbroken, bouwen we onze routering opnieuw op via beschikbare providers.
Bij uitval van de provider schakelen we automatisch over naar de volgende. Bij uitval van een van de datacenters hebben we een kopie van onze diensten in het tweede datacenter, dat de volledige belasting overneemt.
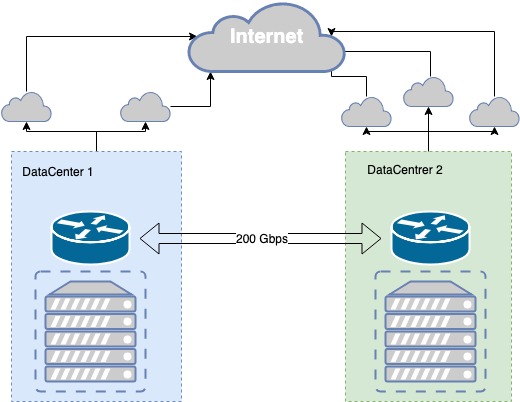
Veerkracht van fysieke infrastructuur
Wat we gebruiken voor fouttolerantie op applicatieniveau
Onze service is gebaseerd op een aantal opensourcecomponenten.
ExaBGP — een service die een aantal functies implementeert met behulp van het dynamische routeringsprotocol op basis van BGP. We gebruiken het actief om onze witte IP-adressen bekend te maken waarmee gebruikers toegang krijgen tot de API.
HAProxy — een high-load balancer waarmee u zeer flexibele regels voor verkeersverdeling kunt configureren op verschillende niveaus van het OSI-model. We gebruiken het voor de balancering vóór alle services: databases, berichtenbrokers, API-services, webservices, onze interne projecten — alles bevindt zich achter HAProxy.
API-applicatie — een webapplicatie geschreven in Python, waarmee de gebruiker zijn infrastructuur, zijn dienst, beheert.
Werknemerstoepassing (hierna simpelweg worker) — in OpenStack-services is dit een infrastructuurdaemon waarmee API-opdrachten naar de infrastructuur kunnen worden verzonden. Zo vindt het aanmaken van schijven plaats in worker, en de aanvraag voor het aanmaken ervan in API-applicatie.
OpenStack-applicatiestandaardarchitectuur
De meeste services die voor OpenStack worden ontwikkeld, proberen één paradigma te volgen. De service bestaat meestal uit twee delen: API en workers (backend-executors). API is doorgaans een WSGI-applicatie in Python, die wordt gestart als een onafhankelijk proces (daemon) of met behulp van een kant-en-klare webserver (Nginx, Apache). De API verwerkt de aanvraag van de gebruiker en geeft verdere instructies voor uitvoering door aan de workerapplicatie. De overdracht vindt plaats via een berichtenbroker, meestal RabbitMQ; de rest wordt slecht ondersteund. Wanneer berichten de broker bereiken, worden ze verwerkt door workers en, indien nodig, geretourneerd.
Dit paradigma impliceert geïsoleerde, gemeenschappelijke faalpunten: RabbitMQ en de database. Maar RabbitMQ is geïsoleerd binnen één service en kan in theorie voor elke service afzonderlijk zijn. Daarom scheiden we deze services in MCS zoveel mogelijk; voor elk afzonderlijk project maken we een aparte database, een aparte RabbitMQ. Deze aanpak is effectief, omdat bij een storing op een kwetsbaar punt niet de hele service uitvalt, maar slechts een deel ervan.
Er is geen limiet aan het aantal werkapplicaties, dus de API kan eenvoudig horizontaal achter balancers worden geschaald om de prestaties en fouttolerantie te verbeteren.
Sommige services vereisen coördinatie binnen de service zelf, bijvoorbeeld wanneer complexe sequentiële bewerkingen plaatsvinden tussen API's en workers. In dat geval wordt één coördinatiecentrum gebruikt, een clustersysteem zoals Redis, Memcache, etcd, waarmee de ene worker de andere kan vertellen dat deze taak aan hem is toegewezen ("alsjeblieft, neem hem niet aan"). Wij gebruiken etcd. Workers communiceren doorgaans actief met de database en schrijven en lezen er informatie uit. Als database gebruiken we mariadb, dat zich in ons multi-master cluster bevindt.
Zo'n klassieke, enkelvoudige service is georganiseerd op een manier die algemeen geaccepteerd is voor OpenStack. Het kan worden beschouwd als een gesloten systeem, waarvan de methoden voor schaalbaarheid en fouttolerantie vrij voor de hand liggen. Voor fouttolerantie van API's is het bijvoorbeeld voldoende om er een balancer voor te plaatsen. Schaalbaarheid van workers wordt bereikt door hun aantal te verhogen.
Het zwakke punt in het hele plan is RabbitMQ en MariaDB. Hun architectuur verdient een apart artikel. In dit artikel wil ik me richten op API-fouttolerantie.
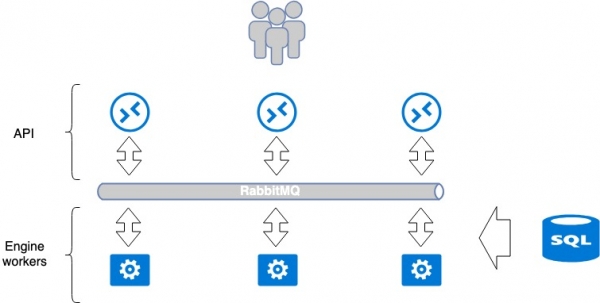
Openstack-applicatiearchitectuur. Balans en fouttolerantie van het cloudplatform
HAProxy Load Balancer fouttolerant maken met ExaBGP
Om onze API's schaalbaar, snel en fouttolerant te maken, hebben we er een balancer voor geplaatst. We kozen voor HAProxy. Naar mijn mening beschikt het over alle benodigde eigenschappen voor onze taak: balancering op meerdere OSI-niveaus, beheerinterface, flexibiliteit en schaalbaarheid, een groot aantal balanceringsmethoden en ondersteuning voor sessietabellen.
Het eerste probleem dat opgelost moest worden, was de fouttolerantie van de balancer zelf. Alleen al de installatie van de balancer creëert een point of failure: de balancer valt uit - de service crasht. Om dit te voorkomen, gebruikten we HAProxy in combinatie met ExaBGP.
ExaBGP maakt het mogelijk om een service health check-mechanisme te implementeren. We gebruikten dit mechanisme om de status van HAProxy te controleren en, in geval van problemen, de HAProxy-service vanuit BGP uit te schakelen.
ExaBGP+HAProxy-schema
- We installeren de benodigde software, ExaBGP en HAProxy, op drie servers.
- Op elke server creëren we een loopback-interface.
- Op alle drie de servers registreren we hetzelfde witte IP-adres op deze interface.
- Het witte IP-adres wordt via ExaBGP aan het internet bekendgemaakt.
Fouttolerantie wordt bereikt door hetzelfde IP-adres vanaf alle drie de servers aan te kondigen. Vanuit het netwerkperspectief is hetzelfde adres toegankelijk vanaf drie verschillende volgende hops. De router ziet drie identieke routes, selecteert de route met de hoogste prioriteit op basis van zijn eigen metriek (meestal dezelfde optie) en het verkeer gaat naar slechts één van de servers.
Bij problemen met de werking van HAProxy of een serverstoring stopt ExaBGP met het adverteren van de route en wordt het verkeer soepel overgeschakeld naar een andere server.
Op deze manier hebben we een fouttolerantie van de balancer bereikt.
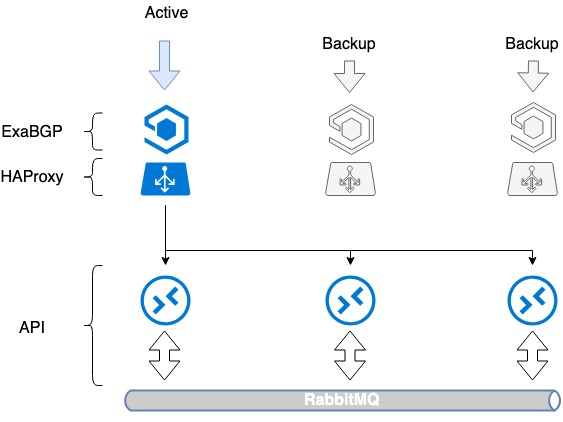
HAProxy Load Balancer fouttolerantie
Het schema bleek niet perfect: we leerden HAProxy te reserveren, maar niet de belasting binnen services te verdelen. Daarom breidden we dit schema iets uit: we schakelden over op balancering tussen meerdere witte IP-adressen.
DNS-gebaseerde balancering plus BGP
Het probleem van load balancing vóór onze HAProxy is nog steeds onopgelost. Het kan echter vrij eenvoudig worden opgelost, zoals we in de onze hebben gedaan.
Om drie servers in balans te brengen, heb je drie witte IP-adressen en de vertrouwde DNS nodig. Elk van deze adressen wordt gedefinieerd op de loopbackinterface van elke HAProxy en bekendgemaakt aan het internet.
In OpenStack wordt een servicecatalogus gebruikt om resources te beheren, waarin het API-eindpunt van een specifieke service wordt gespecificeerd. In deze catalogus specificeren we de domeinnaam public.infra.mail.ru, die via DNS wordt omgezet naar drie verschillende IP-adressen. Hierdoor verkrijgen we een belastingverdeling over drie adressen via DNS.
Maar omdat we de prioriteiten voor serverselectie niet bepalen bij het aankondigen van IP-adressen op de whitelist, is er nog geen sprake van balancering. Normaal gesproken wordt slechts één server geselecteerd op basis van de anciënniteit van het IP-adres, en blijven de andere twee inactief omdat er geen metrics zijn gespecificeerd in BGP.
We zijn begonnen met het uitgeven van routes via ExaBGP met verschillende metrieken. Elke balancer kondigt alle drie de witte IP-adressen aan, maar één ervan, het hoofdadres voor deze balancer, wordt aangekondigd met de minimale metriek. Dus zolang alle drie de balancers operationeel zijn, gaan verzoeken naar het eerste IP-adres naar de eerste balancer, verzoeken naar de tweede naar de tweede, verzoeken naar de derde naar de derde.
Wat gebeurt er als een van de balancers uitvalt? Wanneer een van de balancers uitvalt, wordt het hoofdadres nog steeds geadverteerd door de andere twee, en wordt het verkeer tussen de balancers herverdeeld. Zo geven we de gebruiker meerdere IP-adressen tegelijk via DNS. Door te balanceren via DNS en verschillende metrieken, krijgen we een gelijkmatige verdeling van de belasting over alle drie de balancers. En tegelijkertijd verliezen we geen foutentolerantie.
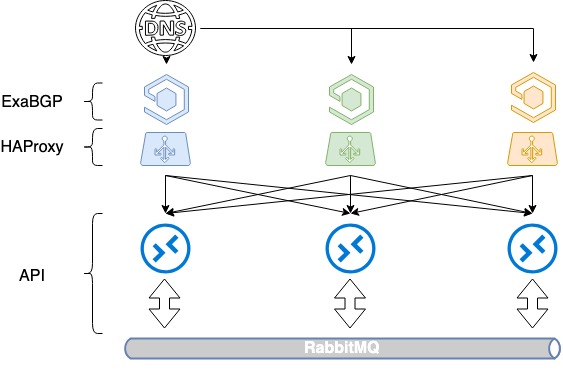
HAProxy Load Balancing op basis van DNS + BGP
Interactie tussen ExaBGP en HAProxy
We hebben dus fouttolerantie geïmplementeerd in geval van serveruitval, gebaseerd op het beëindigen van routeaankondigingen. Maar HAProxy kan ook om andere redenen dan serveruitval worden losgekoppeld: beheerfouten, storingen binnen de service. We willen de defecte balancer ook in deze gevallen onder de belasting vandaan halen, en daarvoor hebben we een ander mechanisme nodig.
Daarom hebben we, voortbouwend op het vorige schema, een heartbeat tussen ExaBGP en HAProxy geïmplementeerd. Dit is een software-implementatie van de interactie tussen ExaBGP en HAProxy, waarbij ExaBGP aangepaste scripts gebruikt om de status van applicaties te controleren.
Om dit te doen, moet u een health checker configureren in de ExaBGP-configuratie die de HAProxy-status kan controleren. In ons geval hebben we een health backend geconfigureerd in HAProxy, en vanaf de ExaBGP-kant controleren we met een eenvoudige GET-aanvraag. Als de aankondiging niet meer plaatsvindt, werkt HAProxy waarschijnlijk niet en is het niet nodig om deze aan te kondigen.
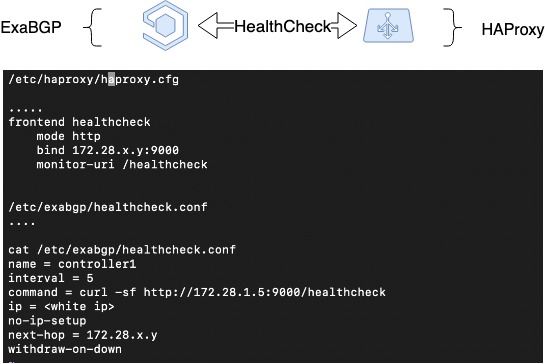
HAProxy-gezondheidscontrole
HAProxy-peers: sessiesynchronisatie
De volgende stap was het synchroniseren van sessies. Bij gebruik van gedistribueerde balancers is het lastig om de opslag van informatie over clientsessies te organiseren. Maar HAProxy is een van de weinige balancers die dit kan dankzij de Peers-functionaliteit: de mogelijkheid om een sessietabel over te dragen tussen verschillende HAProxy-processen.
Er zijn verschillende methoden om te balanceren: eenvoudige, zoals , en uitgebreidere, waarbij de sessie van de client wordt onthouden en hij telkens dezelfde server als voorheen bereikt. We wilden de tweede optie implementeren.
HAProxy gebruikt sticktabellen om clientsessies van dit mechanisme op te slaan. Ze slaan het bron-IP-adres van de client, het geselecteerde doeladres (backend) en wat service-informatie op. Sticktabellen worden meestal gebruikt om een bron-IP + bestemming-IP-paar op te slaan, wat vooral handig is voor applicaties die de context van de gebruikerssessie niet kunnen overdragen bij het overschakelen naar een andere balancer, bijvoorbeeld in de RoundRobin-balanceringsmodus.
Als we de sticktabel leren om te schakelen tussen verschillende HAProxy-processen (waartussen balancering plaatsvindt), kunnen onze balancers met één pool van sticktabellen werken. Dit maakt naadloze schakeling van het clientnetwerk mogelijk wanneer een van de balancers uitvalt. De clientsessies worden dan voortgezet op dezelfde backends die eerder zijn geselecteerd.
Voor een goede werking moet het probleem van het bron-IP-adres van de balancer waarmee de sessie tot stand wordt gebracht, worden opgelost. In ons geval is dit een dynamisch adres op de loopbackinterface.
Peers werken alleen correct onder bepaalde voorwaarden. Dat wil zeggen dat TCP-time-outs groot genoeg moeten zijn of dat de switching snel genoeg moet zijn, zodat de TCP-sessie geen tijd heeft om te worden onderbroken. Dit maakt echter een naadloze switching mogelijk.
We hebben een IaaS-service die op dezelfde technologie is gebaseerd. Dit is , dat Octavia heet. Het is gebaseerd op twee HAProxy-processen en heeft vanaf het begin peer support ingebouwd. Ze hebben bewezen uitstekend te zijn in deze service.
De afbeelding geeft schematisch de verplaatsing van peertabellen tussen drie HAProxy-instanties weer. Er wordt ook een configuratie aangeboden over hoe dit kan worden ingesteld:
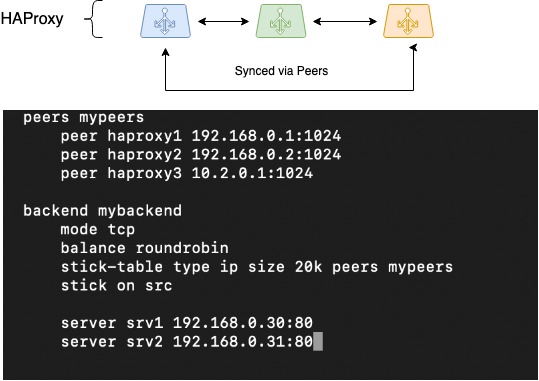
HAProxy Peers (sessiesynchronisatie)
Als je hetzelfde schema implementeert, moet je het zorgvuldig testen. Het is niet zeker dat het in 100% van de gevallen op dezelfde manier zal werken. Maar je zult in ieder geval geen stick-tabellen verliezen wanneer je het bron-IP-adres van de client moet onthouden.
Beperking van het aantal gelijktijdige verzoeken van dezelfde client
Alle openbaar toegankelijke diensten, inclusief onze API's, kunnen onderhevig zijn aan een stortvloed aan verzoeken. De redenen hiervoor kunnen sterk uiteenlopen, van gebruikersfouten tot gerichte aanvallen. We worden regelmatig getroffen door DDoS-aanvallen via IP-adressen. Klanten maken vaak fouten in hun scripts, wat leidt tot mini-DDoS-aanvallen.
Hoe dan ook, er moet extra bescherming worden geboden. De voor de hand liggende oplossing is om het aantal API-aanvragen te beperken en geen processortijd te verspillen aan het verwerken van kwaadaardige aanvragen.
Om dergelijke beperkingen te implementeren, gebruiken we snelheidslimieten, georganiseerd op basis van HAProxy, met behulp van dezelfde sticktabellen. De limieten zijn vrij eenvoudig te configureren en stellen u in staat om de gebruiker te beperken op basis van het aantal verzoeken aan de API. Het algoritme onthoudt het bron-IP-adres van waaruit de verzoeken worden gedaan en beperkt het aantal gelijktijdige verzoeken van één gebruiker. Uiteraard hebben we voor elke service het gemiddelde belastingsprofiel op de API berekend en een limiet ingesteld die ongeveer 10 keer hoger ligt dan deze waarde. We blijven de situatie nauwlettend volgen en houden de vinger aan de pols.
Hoe ziet dit er in de praktijk uit? We hebben klanten die onze API's continu gebruiken voor autoscaling. Ze maken 's ochtends zo'n twee- tot driehonderd virtuele machines aan en verwijderen ze tegen de avond. Voor OpenStack is het aanmaken van een virtuele machine, met name met PaaS-services, minstens 1000 API-aanvragen, aangezien de interactie tussen services ook via API's verloopt.
Dergelijke taakoverdrachten veroorzaken een behoorlijke belasting. We hebben deze belasting beoordeeld, dagelijkse pieken verzameld, deze vertienvoudigd en dit werd onze limiet. We houden de vinger aan de pols. We zien vaak bots, scanners die proberen te controleren of we CGA-scripts hebben die kunnen worden gestart, en die we actief uitschakelen.
Hoe u uw codebase kunt bijwerken zonder dat gebruikers het merken
We implementeren ook fouttolerantie op het niveau van code-implementatieprocessen. Er kunnen fouten optreden tijdens uitrolprocessen, maar de impact daarvan op de beschikbaarheid van de service kan worden geminimaliseerd.
We werken onze services voortdurend bij en moeten ervoor zorgen dat de codebase wordt bijgewerkt zonder dat dit gevolgen heeft voor gebruikers. We hebben dit bereikt door de beheermogelijkheden van HAProxy te benutten en Graceful Shutdown in onze services te implementeren.
Om dit probleem op te lossen was het noodzakelijk om het balancerbeheer en de ‘correcte’ afsluiting van de diensten te garanderen:
- In het geval van HAProxy wordt de besturing uitgevoerd via een stats-bestand, dat in wezen een socket is en gedefinieerd is in de HAProxy-configuratie. Je kunt er opdrachten naartoe sturen via stdio. Maar onze belangrijkste configuratietool is Ansible, dus deze heeft een ingebouwde module voor het beheer van HAProxy. Die gebruiken we actief.
- De meeste van onze API- en Engine-services ondersteunen graceful shutdown-technologieën: bij het afsluiten wachten ze tot de huidige taak is voltooid, of het nu een http-aanvraag of een servicetaak is. Hetzelfde gebeurt met een worker. Deze kent alle taken die hij uitvoert en beëindigt de sessie wanneer alles succesvol is voltooid.
Dankzij deze twee punten ziet ons algoritme voor veilige implementatie er als volgt uit.
- De ontwikkelaar bouwt een nieuw codepakket (in ons geval is dat RPM), test het in de ontwikkelomgeving, test het in de stage en laat het achter in de stage repository.
- De ontwikkelaar stelt een taak voor implementatie in met een zo gedetailleerd mogelijke beschrijving van de ‘artefacten’: de versie van het nieuwe pakket, een beschrijving van de nieuwe functionaliteit en indien nodig andere details over de implementatie.
- De systeembeheerder start de update. Voert het Ansible-playbook uit, dat vervolgens het volgende doet:
- Haalt een pakket uit de stage repository en werkt de pakketversie in de product repository op basis daarvan bij.
- Stelt een lijst samen van de back-ends van de service die wordt bijgewerkt.
- Sluit de eerste service in HAProxy die moet worden bijgewerkt af en wacht tot de processen zijn voltooid. Graceful shutdown zorgt ervoor dat alle huidige clientverzoeken succesvol worden voltooid.
- Na het volledig stoppen van de API, workers en het afsluiten van HAProxy, wordt de code bijgewerkt.
- Ansible start services.
- Voor elke service worden bepaalde "handles" gebruikt die unittests uitvoeren voor een aantal vooraf gedefinieerde sleuteltests. Nieuwe code wordt basisgecontroleerd.
- Als er in de vorige stap geen fouten zijn gevonden, wordt de backend geactiveerd.
- Laten we doorgaan naar de volgende backend.
- Nadat alle backends zijn bijgewerkt, worden functionele tests uitgevoerd. Als deze ontbreken, bekijkt de ontwikkelaar alle nieuwe functionaliteit die hij heeft toegevoegd.
Hiermee is de implementatie voltooid.
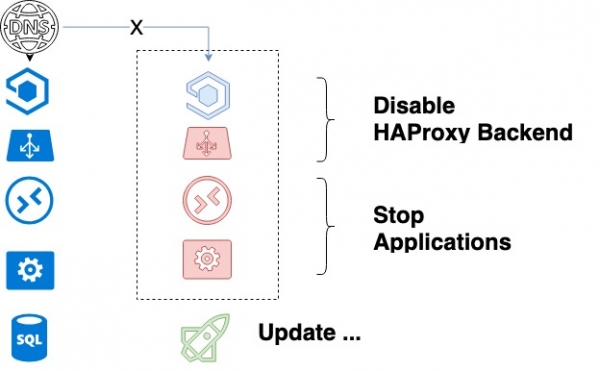
Service-updatecyclus
Deze aanpak zou niet werken als we geen regel hadden. We ondersteunen de oude en nieuwe versies gelijktijdig in de strijd. Van tevoren, tijdens de softwareontwikkelingsfase, wordt vastgelegd dat zelfs wijzigingen in de servicedatabase de vorige code niet zullen verstoren. Dit resulteert in een geleidelijke update van de codebase.
Conclusie
Ik deel mijn eigen gedachten over fouttolerante WEB-architectuur en wil de belangrijkste punten nog eens benadrukken:
- fysieke fouttolerantie;
- netwerkfouttolerantie (balancers, BGP);
- fouttolerantie van de gebruikte en ontwikkelde software.
Ik wens iedereen een stabiele uptime toe!
Bron: www.habr.com
