

Dag Allemaal! Mijn naam is Golov Nikolaj. Voorheen werkte ik bij Avito en beheerde ik het Data Platform gedurende zes jaar, dat wil zeggen dat ik aan alle databases werkte: analytisch (Vertica, ClickHouse), streaming en OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). Gedurende deze tijd heb ik met een groot aantal databases te maken gehad - heel verschillend en ongebruikelijk, en met niet-standaard gevallen van gebruik ervan.
Momenteel werk ik bij ManyChat. In wezen is dit een startup: nieuw, ambitieus en snelgroeiend. En toen ik voor het eerst bij het bedrijf kwam, rees er een klassieke vraag: “Wat moet een jonge startup nu meenemen van de DBMS- en databasemarkt?”
In dit artikel, gebaseerd op mijn rapport op , Ik zal deze vraag beantwoorden. Een videoversie van het rapport is beschikbaar op .
Algemeen bekende databases 2020
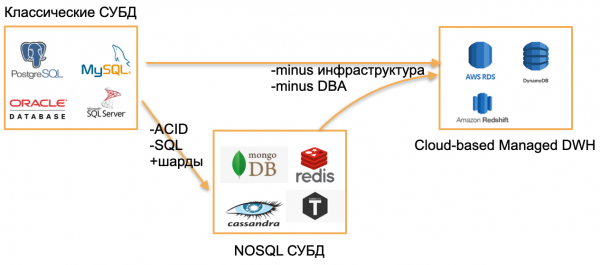
Het is 2020, ik keek rond en zag drie soorten databases.
Eerste soort - klassieke OLTP-databases: PostgreSQL, SQL Server, Oracle, MySQL. Ze zijn lang geleden geschreven, maar zijn nog steeds relevant omdat ze zo bekend zijn bij de ontwikkelaarsgemeenschap.
Het tweede type is basissen vanaf "nul". Ze probeerden afstand te nemen van klassieke patronen door SQL, traditionele structuren en ACID achterwege te laten, door ingebouwde sharding en andere aantrekkelijke functies toe te voegen. Dit is bijvoorbeeld Cassandra, MongoDB, Redis of Tarantool. Al deze oplossingen wilden de markt iets fundamenteel nieuws bieden en bezetten hun niche omdat ze voor bepaalde taken uiterst handig bleken te zijn. Ik zal deze databases aanduiden met de overkoepelende term NOSQL.
De ‘nullen’ zijn voorbij, we zijn gewend geraakt aan NOSQL-databases en de wereld heeft, vanuit mijn standpunt, de volgende stap gezet: beheerde databases. Deze databases hebben dezelfde kern als klassieke OLTP-databases of nieuwe NoSQL-databases. Maar ze hebben geen behoefte aan DBA en DevOps en draaien op beheerde hardware in de cloud. Voor een ontwikkelaar is dit “slechts een basis” die ergens werkt, maar het maakt niemand uit hoe het op de server wordt geïnstalleerd, wie de server heeft geconfigureerd en wie deze bijwerkt.
Voorbeelden van dergelijke databases:
- AWS RDS is een beheerde wrapper voor PostgreSQL/MySQL.
- DynamoDB is een AWS-analoog van een documentgebaseerde database, vergelijkbaar met Redis en MongoDB.
- Amazon Redshift is een beheerde analytische database.
Dit zijn feitelijk oude databases, maar opgegroeid in een beheerde omgeving, zonder dat er met hardware hoeft te worden gewerkt.
Opmerking. De voorbeelden zijn genomen voor de AWS-omgeving, maar hun analogen bestaan ook in Microsoft Azure, Google Cloud of Yandex.Cloud.
Wat is hier nieuw aan? Anno 2020 niets van dit alles.
Serverloos concept
Wat in 2020 echt nieuw op de markt is, zijn serverloze of serverloze oplossingen.
Ik zal proberen uit te leggen wat dit betekent aan de hand van het voorbeeld van een reguliere service of backend-applicatie.
Om een reguliere backend-applicatie in te zetten, kopen of huren we een server, kopiëren we de code erop, publiceren we het endpoint buiten en betalen we regelmatig voor huur, elektriciteit en datacenterdiensten. Dit is het standaardschema.
Is er een andere manier? Met serverloze services is dat mogelijk.
Wat is de focus van deze aanpak: er is geen server, er wordt zelfs geen virtuele instance in de cloud gehuurd. Om de service te implementeren, kopieert u de code (functies) naar de repository en publiceert u deze naar het eindpunt. Vervolgens betalen we eenvoudigweg voor elke aanroep van deze functie, waarbij we de hardware waarop deze wordt uitgevoerd volledig negeren.
Ik zal proberen deze aanpak met foto's te illustreren.
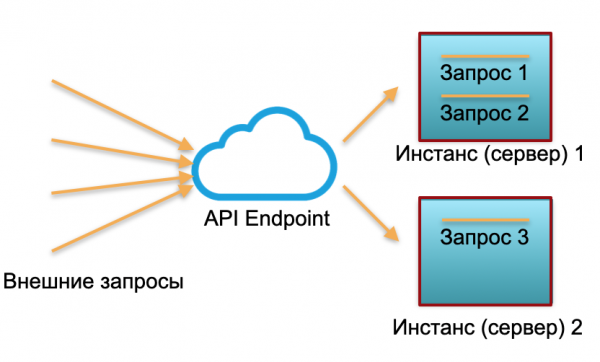
Klassieke implementatie. Wij hebben een dienst met een bepaalde lading. We verhogen twee instanties: fysieke servers of instanties in AWS. Externe verzoeken worden naar deze instanties verzonden en daar verwerkt.
Zoals u op de afbeelding kunt zien, worden de servers niet gelijkmatig afgevoerd. Eén is voor 100% benut, er zijn twee verzoeken en één is slechts 50% - gedeeltelijk inactief. Als er niet drie verzoeken binnenkomen, maar 30, zal het hele systeem de belasting niet aankunnen en begint het te vertragen.
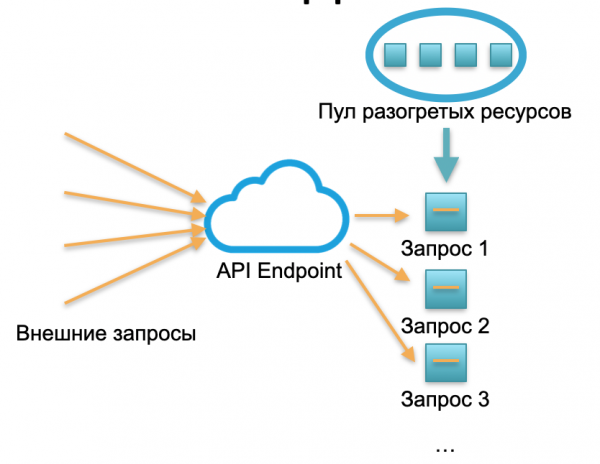
Serverloze implementatie. In een serverloze omgeving heeft zo’n dienst geen instances of servers. Er is een bepaalde pool van verwarmde bronnen: kleine voorbereide Docker-containers met geïmplementeerde functiecode. Het systeem ontvangt externe verzoeken en voor elk daarvan genereert het serverloze raamwerk een kleine container met code: het verwerkt dit specifieke verzoek en doodt de container.
Eén aanvraag - één opgehaalde container, 1000 aanvragen - 1000 containers. En de implementatie op hardwareservers is al het werk van de cloudprovider. Het is volledig verborgen door het serverloze raamwerk. In dit concept betalen wij voor ieder gesprek. Er kwam bijvoorbeeld één oproep per dag - we betaalden voor één oproep, er kwam een miljoen per minuut - we betaalden voor een miljoen. Of in een seconde gebeurt dit ook.
Het concept van het publiceren van een serverloze functie is geschikt voor een staatloze service. En als u een (staats)statefull dienst nodig heeft, dan voegen wij een database toe aan de dienst. In dit geval, als het gaat om het werken met state, schrijft en leest elke statefull-functie eenvoudigweg uit de database. Bovendien uit een database van een van de drie typen die aan het begin van het artikel worden beschreven.
Wat is de gemeenschappelijke beperking van al deze databases? Dit zijn de kosten van een continu gebruikte cloud- of hardwareserver (of meerdere servers). Het maakt niet uit of we een klassieke of beheerde database gebruiken, of we Devops en een admin hebben of niet, we betalen nog steeds 24/7 voor hardware, elektriciteit en datacenterhuur. Als we een klassieke basis hebben, betalen we voor master en slave. Als het een zwaarbelaste sharded-database is, betalen we voor 10, 20 of 30 servers, en we betalen constant.
De aanwezigheid van permanent gereserveerde servers in de kostenstructuur werd voorheen gezien als een noodzakelijk kwaad. Conventionele databases hebben ook andere problemen, zoals limieten op het aantal verbindingen, schaalbeperkingen, geogedistribueerde consensus - ze kunnen op de een of andere manier in bepaalde databases worden opgelost, maar niet allemaal tegelijk en niet ideaal.
Serverloze database - theorie
Vraag van 2020: is het mogelijk om een database ook serverloos te maken? Iedereen heeft gehoord van de serverloze backend... laten we proberen de database serverloos te maken?
Dit klinkt vreemd, omdat de database een statefull service is, niet erg geschikt voor serverloze infrastructuur. Tegelijkertijd is de staat van de database erg groot: gigabytes, terabytes en in analytische databases zelfs petabytes. Het is niet zo eenvoudig om het op te voeden in lichtgewicht Docker-containers.
Aan de andere kant bevatten vrijwel alle moderne databases een enorme hoeveelheid logica en componenten: transacties, integriteitscoördinatie, procedures, relationele afhankelijkheden en veel logica. Voor heel wat databaselogica is een kleine status voldoende. Gigabytes en Terabytes worden rechtstreeks gebruikt door slechts een klein deel van de databaselogica die betrokken is bij het rechtstreeks uitvoeren van zoekopdrachten.
Dienovereenkomstig is het idee: als een deel van de logica staatloze uitvoering toestaat, waarom splitst u de basis dan niet in Stateful en Stateless delen.
Serverloos voor OLAP-oplossingen
Laten we eens kijken hoe het opdelen van een database in Stateful en Stateless delen eruit zou kunnen zien aan de hand van praktische voorbeelden.
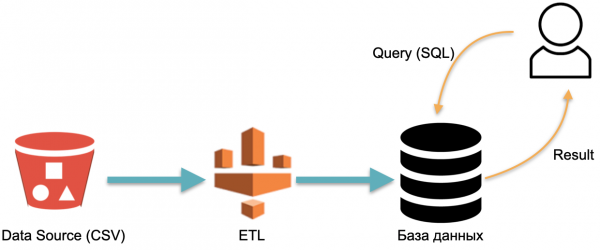
We hebben bijvoorbeeld een analytische database: externe gegevens (rode cilinder aan de linkerkant), een ETL-proces dat gegevens in de database laadt, en een analist die SQL-query's naar de database verzendt. Dit is een klassiek datawarehouse-bewerkingsschema.
In dit schema wordt ETL één keer voorwaardelijk uitgevoerd. Dan moet je constant betalen voor de servers waarop de database draait met data gevuld met ETL, zodat er iets is om queries naar toe te sturen.
Laten we eens kijken naar een alternatieve aanpak geïmplementeerd in AWS Athena Serverless. Er is geen permanent speciale hardware waarop gedownloade gegevens worden opgeslagen. In plaats van dit:
- De gebruiker dient een SQL-query in bij Athena. De Athena-optimalisatie analyseert de SQL-query en doorzoekt de metadata-opslag (Metadata) naar de specifieke gegevens die nodig zijn om de query uit te voeren.
- De optimizer downloadt op basis van de verzamelde gegevens de benodigde gegevens uit externe bronnen naar tijdelijke opslag (tijdelijke database).
- Een SQL-query van de gebruiker wordt uitgevoerd in tijdelijke opslag en het resultaat wordt teruggestuurd naar de gebruiker.
- Tijdelijke opslag wordt gewist en bronnen worden vrijgegeven.
In deze architectuur betalen we alleen voor het proces van het uitvoeren van het verzoek. Geen verzoeken - geen kosten.
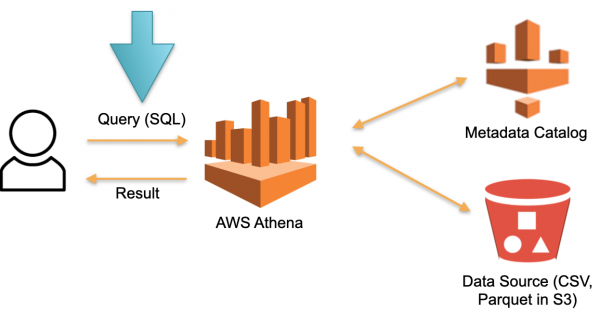
Dit is een werkende aanpak en wordt niet alleen geïmplementeerd in Athena Serverless, maar ook in Redshift Spectrum (in AWS).
Het Athena-voorbeeld laat zien dat de Serverless-database werkt op echte zoekopdrachten met tientallen en honderden terabytes aan gegevens. Voor honderden terabytes zijn honderden servers nodig, maar we hoeven er niet voor te betalen: we betalen voor de verzoeken. De snelheid van elk verzoek is (zeer) laag in vergelijking met gespecialiseerde analytische databases zoals Vertica, maar we betalen niet voor downtime.
Een dergelijke database is toepasbaar voor zeldzame analytische ad-hocquery's. Bijvoorbeeld wanneer we spontaan besluiten een hypothese te testen op een gigantische hoeveelheid gegevens. Athena is perfect voor deze gevallen. Voor reguliere aanvragen is een dergelijk systeem duur. In dit geval slaat u de gegevens op in een gespecialiseerde oplossing.
Serverloos voor OLTP-oplossingen
In het vorige voorbeeld werd gekeken naar OLAP (analytische) taken. Laten we nu eens kijken naar OLTP-taken.
Laten we ons schaalbare PostgreSQL of MySQL voorstellen. Laten we een regulier beheerd exemplaar PostgreSQL of MySQL opzetten met minimale middelen. Wanneer de instantie meer belasting krijgt, zullen we extra replica's koppelen waaraan we een deel van de leesbelasting zullen verdelen. Als er geen verzoeken of belasting zijn, schakelen we de replica's uit. Het eerste exemplaar is de master en de rest zijn replica's.
Dit idee is geïmplementeerd in een database genaamd Aurora Serverless AWS. Het principe is eenvoudig: verzoeken van externe applicaties worden geaccepteerd door de proxyvloot. Het ziet de belasting toenemen en wijst computerbronnen toe van voorverwarmde minimale instanties - de verbinding wordt zo snel mogelijk tot stand gebracht. Het uitschakelen van instanties gebeurt op dezelfde manier.
Binnen Aurora bestaat het concept van Aurora Capacity Unit, ACU. Dit is (voorwaardelijk) een instance (server). Elke specifieke ACU kan een master of een slave zijn. Elke Capacity Unit heeft zijn eigen RAM, processor en minimale schijf. Dienovereenkomstig is één de meester, de rest zijn alleen-lezen replica's.
Het aantal actieve Aurora Capacity Units is een configureerbare parameter. Het minimumaantal kan één of nul zijn (in dit geval werkt de database niet als er geen aanvragen zijn).
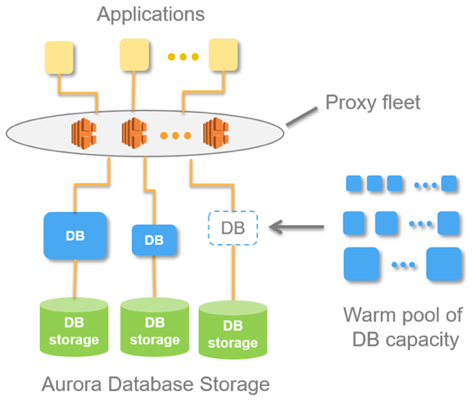
Wanneer de basis verzoeken ontvangt, verhoogt de proxyvloot Aurora CapacityUnits, waardoor de prestatiebronnen van het systeem toenemen. Dankzij de mogelijkheid om bronnen te vergroten en te verkleinen, kan het systeem met bronnen ‘jongleren’: automatisch individuele ACU’s weergeven (ze vervangen door nieuwe) en alle huidige updates voor de ingetrokken bronnen uitrollen.
De Aurora Serverless-basis kan de leesbelasting schalen. Maar de documentatie zegt dit niet direct. Het voelt misschien alsof ze een multi-master kunnen optillen. Er is geen magie.
Deze database is zeer geschikt om te voorkomen dat er grote hoeveelheden geld worden uitgegeven aan systemen met onvoorspelbare toegang. Bij het maken van MVP- of marketingsites voor visitekaartjes verwachten we bijvoorbeeld meestal geen stabiele belasting. Als er geen toegang is, betalen wij dus niet voor instances. Wanneer er onverwachte belasting optreedt, bijvoorbeeld na een conferentie of reclamecampagne, grote aantallen mensen de site bezoeken en de belasting dramatisch toeneemt, neemt Aurora Serverless deze belasting automatisch op en verbindt snel de ontbrekende bronnen (ACU). Dan gaat de conferentie voorbij, iedereen vergeet het prototype, de servers (ACU) worden donker en de kosten dalen tot nul - handig.
Deze oplossing is niet geschikt voor stabiele hoge belasting, omdat de schrijfbelasting niet wordt geschaald. Al deze verbindingen en ontkoppelingen van bronnen vinden plaats op het zogenaamde “schaalpunt” – een punt in de tijd waarop de database niet wordt ondersteund door een transactie of tijdelijke tabellen. Binnen een week kan het schaalpunt bijvoorbeeld niet plaatsvinden en werkt de basis op dezelfde bronnen en kan eenvoudigweg niet uitbreiden of inkrimpen.
Er bestaat geen magie: het is gewone PostgreSQL. Maar het proces van het toevoegen van machines en het loskoppelen ervan is gedeeltelijk geautomatiseerd.
Serverloos door ontwerp
Aurora Serverless is een oude database die is herschreven voor de cloud om te profiteren van enkele voordelen van Serverless. En nu zal ik je vertellen over de basis, die oorspronkelijk voor de cloud is geschreven, voor de serverloze aanpak: Serverless-by-design. Het werd onmiddellijk ontwikkeld zonder de veronderstelling dat het op fysieke servers zou draaien.
Deze basis heet Sneeuwvlok. Het heeft drie sleutelblokken.
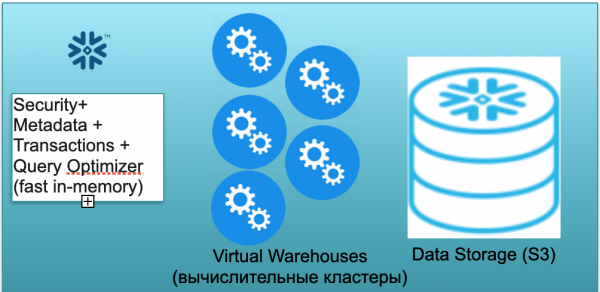
De eerste is een metadatablok. Dit is een snelle service in het geheugen die problemen met beveiliging, metagegevens, transacties en zoekoptimalisatie oplost (weergegeven in de afbeelding aan de linkerkant).
Het tweede blok is een set virtuele rekenclusters voor berekeningen (in de afbeelding is er een set blauwe cirkels).
Het derde blok is een gegevensopslagsysteem gebaseerd op S3. S3 is dimensieloze objectopslag in AWS, een soort dimensieloze Dropbox voor bedrijven.
Laten we eens kijken hoe Snowflake werkt, uitgaande van een koude start. Dat wil zeggen, er is een database, de gegevens worden erin geladen, er zijn geen actieve query's. Als er dus geen verzoeken aan de database zijn, hebben we de snelle in-memory Metadata-service (eerste blok) geactiveerd. En we hebben S3-opslag, waar tabelgegevens worden opgeslagen, onderverdeeld in zogenaamde micropartities. Voor de eenvoud: als de tabel transacties bevat, dan zijn micropartities de dagen van transacties. Elke dag is een aparte micropartitie, een apart bestand. En wanneer de database in deze modus werkt, betaalt u alleen voor de ruimte die door de gegevens wordt ingenomen. Bovendien is het tarief per stoel zeer laag (zeker gezien de aanzienlijke compressie). De metadataservice werkt ook constant, maar je hebt niet veel bronnen nodig om zoekopdrachten te optimaliseren, en de service kan als shareware worden beschouwd.
Laten we ons nu voorstellen dat een gebruiker naar onze database komt en een SQL-query verzendt. De SQL-query wordt onmiddellijk ter verwerking naar de Metadata-service gestuurd. Dienovereenkomstig analyseert deze dienst bij ontvangst van een verzoek het verzoek, de beschikbare gegevens, de gebruikersrechten en stelt, als alles goed is, een plan op voor de verwerking van het verzoek.
Vervolgens initieert de service de lancering van het rekencluster. Een rekencluster is een cluster van servers die berekeningen uitvoeren. Dat wil zeggen, dit is een cluster dat 1 server, 2 servers, 4, 8, 16, 32 kan bevatten - zoveel als u wilt. Je gooit een verzoek en de lancering van dit cluster begint onmiddellijk. Het duurt echt seconden.
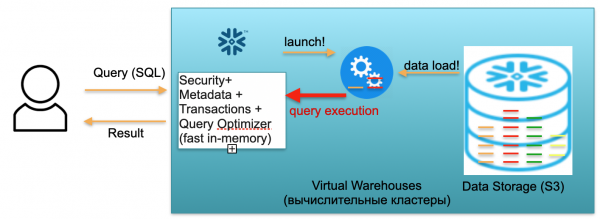
Nadat het cluster is gestart, worden vervolgens de micropartities die nodig zijn om uw verzoek te verwerken vanuit S3 naar het cluster gekopieerd. Dat wil zeggen, laten we ons voorstellen dat u voor het uitvoeren van een SQL-query twee partities uit de ene tabel en één uit de tweede tabel nodig heeft. In dit geval worden alleen de drie noodzakelijke partities naar het cluster gekopieerd, en niet alle tabellen volledig. Dat is de reden waarom, en juist omdat alles zich binnen één datacenter bevindt en verbonden is via zeer snelle kanalen, het hele overdrachtsproces zeer snel plaatsvindt: in seconden, zeer zelden in minuten, tenzij we het hebben over enkele monsterlijke verzoeken. Dienovereenkomstig worden micropartities gekopieerd naar het rekencluster, en na voltooiing wordt de SQL-query uitgevoerd op dit rekencluster. Het resultaat van dit verzoek kan één regel, meerdere regels of een tabel zijn. Ze worden extern naar de gebruiker verzonden, zodat hij deze kan downloaden, weergeven in zijn BI-tool of op een andere manier kan gebruiken.
Elke SQL-query kan niet alleen aggregaten van eerder geladen gegevens lezen, maar ook nieuwe gegevens in de database laden/genereren. Dat wil zeggen, het kan een query zijn die bijvoorbeeld nieuwe records in een andere tabel invoegt, wat leidt tot het verschijnen van een nieuwe partitie op het computercluster, die op zijn beurt automatisch wordt opgeslagen in een enkele S3-opslag.
Het hierboven beschreven scenario, vanaf de aankomst van de gebruiker tot het opzetten van het cluster, het laden van gegevens, het uitvoeren van zoekopdrachten en het verkrijgen van resultaten, wordt betaald tegen het tarief voor minuten gebruik van het verhoogde virtuele computercluster, het virtuele magazijn. Het tarief varieert afhankelijk van de AWS-zone en clustergrootte, maar bedraagt gemiddeld een paar dollar per uur. Een cluster van vier machines is twee keer zo duur als een cluster van twee machines, en een cluster van acht machines is nog steeds twee keer zo duur. Opties van 16, 32 machines zijn beschikbaar, afhankelijk van de complexiteit van de verzoeken. Maar u betaalt alleen voor de minuten dat het cluster daadwerkelijk actief is, want als er geen verzoeken zijn, neemt u uw handen eraf en na 5-10 minuten wachten (een configureerbare parameter) gaat het vanzelf uit, Maak hulpbronnen vrij en word vrij.
Een volledig realistisch scenario is dat wanneer je een verzoek verzendt, het cluster relatief gezien binnen een minuut opduikt, het nog een minuut telt, dan vijf minuten om af te sluiten, en je uiteindelijk betaalt voor zeven minuten werking van dit cluster, en niet voor maanden en jaren.
Het eerste scenario dat wordt beschreven met behulp van Snowflake in een situatie voor één gebruiker. Laten we ons nu voorstellen dat er veel gebruikers zijn, wat dichter bij het echte scenario ligt.
Laten we zeggen dat we veel analisten en Tableau-rapporten hebben die onze database voortdurend bombarderen met een groot aantal eenvoudige analytische SQL-query's.
Laten we daarnaast zeggen dat we inventieve datawetenschappers hebben die monsterlijke dingen proberen te doen met data, met tientallen terabytes werken, miljarden en biljoenen rijen data analyseren.
Voor de twee hierboven beschreven soorten werkbelasting kunt u met Snowflake verschillende onafhankelijke computerclusters met verschillende capaciteiten creëren. Bovendien werken deze computerclusters onafhankelijk, maar met gemeenschappelijke, consistente gegevens.
Voor een groot aantal lichte zoekopdrachten kunt u twee tot drie kleine clusters maken, elk ongeveer twee machines. Dit gedrag kan onder meer worden geïmplementeerd met behulp van automatische instellingen. Dus jij zegt: “Sneeuwvlok, breng een kleine tros groot. Als de belasting erop boven een bepaalde parameter toeneemt, verhoog dan een vergelijkbare tweede, derde. Wanneer de last begint af te nemen, doof dan het overtollige.” Zodat ongeacht hoeveel analisten naar rapporten komen kijken, iedereen over voldoende middelen beschikt.
Tegelijkertijd, als analisten slapen en niemand naar de rapporten kijkt, kunnen de clusters volledig donker worden en stopt u ermee te betalen.
Tegelijkertijd kun je voor zware queries (van Data Scientists) één heel groot cluster voor 32 machines opzetten. Dit cluster wordt ook alleen betaald voor de minuten en uren waarop uw gigantische verzoek daar actief is.
Met de hierboven beschreven mogelijkheid kunt u niet alleen 2, maar ook meer soorten werklast in clusters verdelen (ETL, monitoring, rapportmaterialisatie,...).
Laten we Sneeuwvlok samenvatten. De basis combineert een mooi idee en een werkbare uitvoering. Bij ManyChat gebruiken we Snowflake om alle gegevens die we hebben te analyseren. We hebben geen drie clusters, zoals in het voorbeeld, maar van 5 tot en met 9, van verschillende grootte. Voor sommige taken hebben we conventionele machines met 16 machines, 2 machines en ook superkleine machines met 1 machine. Ze verdelen de lading met succes en stellen ons in staat veel te besparen.
De database schaalt de lees- en schrijfbelasting met succes. Dit is een enorm verschil en een enorme doorbraak vergeleken met dezelfde "Aurora", die alleen de leeslast droeg. Met Snowflake kunt u uw schrijfwerklast schalen met deze computerclusters. Dat wil zeggen, zoals ik al zei, we gebruiken verschillende clusters in ManyChat, kleine en superkleine clusters worden voornamelijk gebruikt voor ETL, voor het laden van gegevens. En analisten leven al op middelgrote clusters, die absoluut niet worden beïnvloed door de ETL-belasting, dus ze werken erg snel.
Dienovereenkomstig is de database zeer geschikt voor OLAP-taken. Helaas is dit nog niet van toepassing op OLTP-workloads. Ten eerste is deze database zuilvormig, met alle gevolgen van dien. Ten tweede is de aanpak zelf, waarbij je voor elk verzoek, indien nodig, een rekencluster opricht en deze overspoelt met gegevens, helaas nog niet snel genoeg voor OLTP-belastingen. Seconden wachten voor OLAP-taken is normaal, maar voor OLTP-taken is dit onaanvaardbaar; 100 ms zou beter zijn, of 10 ms zou zelfs nog beter zijn.
Totaal
Een serverloze database is mogelijk door de database op te delen in Stateless en Stateful delen. Het is je misschien opgevallen dat in alle bovenstaande voorbeelden het Stateful-gedeelte, relatief gezien, micropartities in S3 opslaat, en Stateless de optimalisatie is, die met metadata werkt en beveiligingsproblemen afhandelt die kunnen worden opgeworpen als onafhankelijke lichtgewicht Stateless-services.
Het uitvoeren van SQL-query's kan ook worden gezien als light-state services die in serverloze modus kunnen verschijnen, zoals Snowflake-computerclusters, alleen de noodzakelijke gegevens downloaden, de query uitvoeren en 'uitgaan'.
Er zijn al serverloze databases op productieniveau beschikbaar voor gebruik, ze werken. Deze serverloze databases zijn al klaar om OLAP-taken uit te voeren. Helaas worden ze voor OLTP-taken gebruikt... met nuances, aangezien er beperkingen zijn. Aan de ene kant is dit een minpunt. Maar aan de andere kant is dit een kans. Misschien vindt een van de lezers een manier om een OLTP-database volledig serverloos te maken, zonder de beperkingen van Aurora.
Ik hoop dat je het interessant vond. Serverloos is de toekomst :)
Bron: www.habr.com
