

Voorwoord
Heel vaak komen gebruikers, ontwikkelaars en beheerders van het MS SQL Server DBMS prestatieproblemen tegen van de database of het DBMS als geheel, dus MS SQL Server-monitoring is zeer relevant.
Dit artikel is een aanvulling op het artikel en het behandelt enkele aspecten van het monitoren van MS SQL Server, in het bijzonder: hoe snel te bepalen welke bronnen ontbreken, evenals aanbevelingen voor het instellen van traceervlaggen.
Om de volgende scripts te laten werken, moet u als volgt een inf-schema in de gewenste database maken:
Een inf-schema maken
use <имя_БД>;
go
create schema inf;
Methode voor het detecteren van gebrek aan RAM
De eerste indicatie van het ontbreken van RAM is het geval wanneer een instantie van MS SQL Server alle RAM opeet die eraan is toegewezen.
Om dit te doen, maken we de volgende weergave van inf.vRAM:
De weergave inf.vRAM maken
CREATE view [inf].[vRAM] as
select a.[TotalAvailOSRam_Mb] --сколько свободно ОЗУ на сервере в МБ
, a.[RAM_Avail_Percent] --процент свободного ОЗУ на сервере
, a.[Server_physical_memory_Mb] --сколько всего ОЗУ на сервере в МБ
, a.[SQL_server_committed_target_Mb] --сколько всего ОЗУ выделено под MS SQL Server в МБ
, a.[SQL_server_physical_memory_in_use_Mb] --сколько всего ОЗУ потребляет MS SQL Server в данный момент времени в МБ
, a.[SQL_RAM_Avail_Percent] --поцент свободного ОЗУ для MS SQL Server относительно всего выделенного ОЗУ для MS SQL Server
, a.[StateMemorySQL] --достаточно ли ОЗУ для MS SQL Server
, a.[SQL_RAM_Reserve_Percent] --процент выделенной ОЗУ для MS SQL Server относительно всего ОЗУ сервера
--достаточно ли ОЗУ для сервера
, (case when a.[RAM_Avail_Percent]<10 and a.[RAM_Avail_Percent]>5 and a.[TotalAvailOSRam_Mb]<8192 then 'Warning' when a.[RAM_Avail_Percent]<=5 and a.[TotalAvailOSRam_Mb]<2048 then 'Danger' else 'Normal' end) as [StateMemoryServer]
from
(
select cast(a0.available_physical_memory_kb/1024.0 as int) as TotalAvailOSRam_Mb
, cast((a0.available_physical_memory_kb/casT(a0.total_physical_memory_kb as float))*100 as numeric(5,2)) as [RAM_Avail_Percent]
, a0.system_low_memory_signal_state
, ceiling(b.physical_memory_kb/1024.0) as [Server_physical_memory_Mb]
, ceiling(b.committed_target_kb/1024.0) as [SQL_server_committed_target_Mb]
, ceiling(a.physical_memory_in_use_kb/1024.0) as [SQL_server_physical_memory_in_use_Mb]
, cast(((b.committed_target_kb-a.physical_memory_in_use_kb)/casT(b.committed_target_kb as float))*100 as numeric(5,2)) as [SQL_RAM_Avail_Percent]
, cast((b.committed_target_kb/casT(a0.total_physical_memory_kb as float))*100 as numeric(5,2)) as [SQL_RAM_Reserve_Percent]
, (case when (ceiling(b.committed_target_kb/1024.0)-1024)<ceiling(a.physical_memory_in_use_kb/1024.0) then 'Warning' else 'Normal' end) as [StateMemorySQL]
from sys.dm_os_sys_memory as a0
cross join sys.dm_os_process_memory as a
cross join sys.dm_os_sys_info as b
cross join sys.dm_os_sys_memory as v
) as a;
Vervolgens kunt u met de volgende query vaststellen dat een exemplaar van MS SQL Server al het geheugen verbruikt dat eraan is toegewezen:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb
from [inf].[vRAM];
Als SQL_server_physical_memory_in_use_Mb consistent groter is dan of gelijk is aan SQL_server_committed_target_Mb, moeten de wachtstatistieken worden gecontroleerd.
Om het gebrek aan RAM te bepalen door middel van wachtstatistieken, maken we de weergave inf.vWaits:
De weergave inf.vWaits maken
CREATE view [inf].[vWaits] as
WITH [Waits] AS
(SELECT
[wait_type], --имя типа ожидания
[wait_time_ms] / 1000.0 AS [WaitS],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
[signal_wait_time_ms] / 1000.0 AS [SignalS],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[waiting_tasks_count] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [waiting_tasks_count]>0
and [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
)
, ress as (
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[W1].[WaitCount] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95 -- percentage threshold
)
SELECT [WaitType]
,MAX([Wait_S]) as [Wait_S]
,MAX([Resource_S]) as [Resource_S]
,MAX([Signal_S]) as [Signal_S]
,MAX([WaitCount]) as [WaitCount]
,MAX([Percentage]) as [Percentage]
,MAX([AvgWait_S]) as [AvgWait_S]
,MAX([AvgRes_S]) as [AvgRes_S]
,MAX([AvgSig_S]) as [AvgSig_S]
FROM ress
group by [WaitType];
In dit geval kunt u het gebrek aan RAM bepalen met de volgende vraag:
SELECT [Percentage]
,[AvgWait_S]
FROM [inf].[vWaits]
where [WaitType] in (
'PAGEIOLATCH_XX',
'RESOURCE_SEMAPHORE',
'RESOURCE_SEMAPHORE_QUERY_COMPILE'
);
Hier moet u letten op de indicatoren Percentage en AvgWait_S. Als ze in hun totaliteit significant zijn, is de kans zeer groot dat er niet genoeg RAM is voor de MS SQL Server-instantie. Significante waarden worden voor elk systeem afzonderlijk bepaald. U kunt echter beginnen met het volgende: Percentage>=1 en AvgWait_S>=0.005.
Om indicatoren uit te voeren naar een monitoringsysteem (bijvoorbeeld Zabbix), kunt u de volgende twee query's maken:
- hoeveel soorten wachttijden worden bezet door RAM in procenten (de som van al dergelijke soorten wachttijden):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' ); - hoeveel RAM-wachttypen duren in milliseconden (de maximale waarde van alle gemiddelde vertragingen voor al dergelijke wachttypen):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Op basis van de dynamiek van de verkregen waarden voor deze twee indicatoren kunnen we concluderen of er voldoende RAM is voor een instantie van MS SQL Server.
Detectiemethode CPU-overbelasting
Om het gebrek aan processortijd te identificeren, volstaat het om de systeemweergave sys.dm_os_schedulers te gebruiken. Hier, als de runnable_tasks_count constant groter is dan 1, is de kans groot dat het aantal cores niet genoeg is voor de MS SQL Server-instantie.
Om een indicator uit te voeren naar een monitoringsysteem (bijvoorbeeld Zabbix), kunt u de volgende query maken:
select max([runnable_tasks_count]) as [runnable_tasks_count]
from sys.dm_os_schedulers
where scheduler_id<255;
Op basis van de dynamiek van de verkregen waarden voor deze indicator kunnen we concluderen of er voldoende processortijd (het aantal CPU-cores) is voor een instantie van MS SQL Server.
Het is echter belangrijk om in gedachten te houden dat verzoeken zelf meerdere threads tegelijk kunnen aanvragen. En soms kan de optimizer de complexiteit van de query zelf niet correct inschatten. Dan kan het verzoek te veel threads toegewezen krijgen die niet tegelijkertijd op het gegeven moment kunnen worden verwerkt. En dit veroorzaakt ook een soort wachten geassocieerd met een gebrek aan processortijd en groei van de wachtrij voor planners die specifieke CPU-kernen gebruiken, d.w.z. de indicator runnable_tasks_count zal onder dergelijke omstandigheden groeien.
In dit geval is het, voordat het aantal CPU-kernen wordt verhoogd, noodzakelijk om de parallelliteitseigenschappen van de MS SQL Server-instantie zelf correct te configureren en vanaf de 2016-versie de parallelliteitseigenschappen van de vereiste databases correct te configureren:
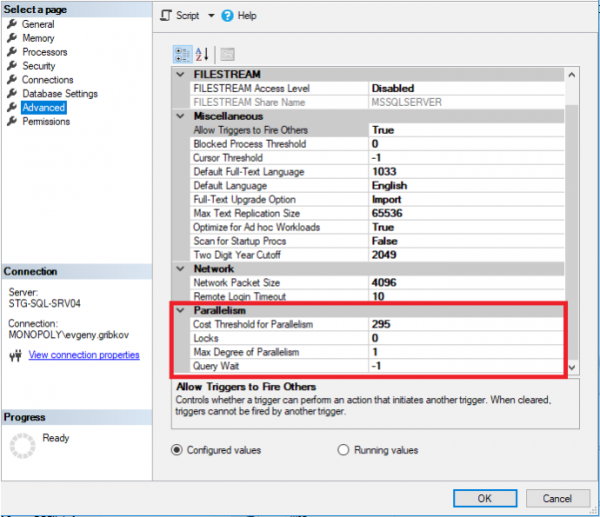
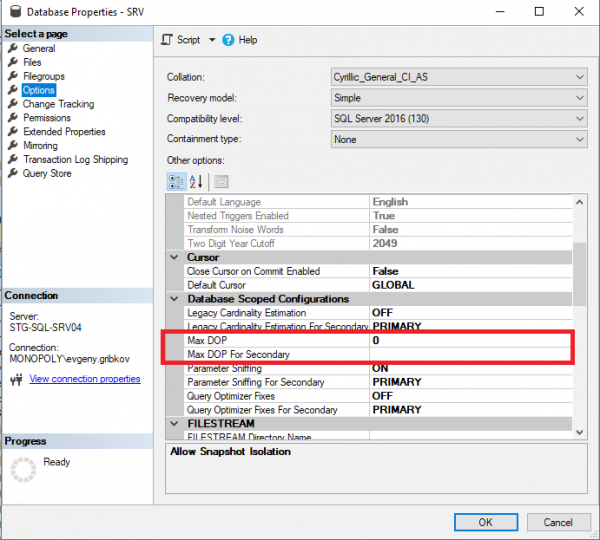
Hier moet u op de volgende parameters letten:
- Max. mate van parallellisme - stelt het maximale aantal threads in dat aan elk verzoek kan worden toegewezen (de standaardwaarde is 0 - alleen beperkt door het besturingssysteem zelf en de editie van MS SQL Server)
- Kostendrempel voor parallellisme - geschatte kosten van parallellisme (standaard is 5)
- Max DOP - stelt het maximale aantal threads in dat kan worden toegewezen aan elke query op databaseniveau (maar niet meer dan de waarde van de eigenschap "Max Mate of Parallelism") (standaard is 0 - alleen beperkt door het besturingssysteem zelf en de editie van MS SQL Server, evenals de beperking van de eigenschap "Max Degree of Parallelism" van de volledige instantie van MS SQL Server)
Hier is het onmogelijk om voor alle gevallen een even goed recept te geven, d.w.z. u moet zware zoekopdrachten analyseren.
Uit eigen ervaring raad ik het volgende algoritme van acties aan voor OLTP-systemen voor het instellen van parallellisme-eigenschappen:
- schakel parallellisme eerst uit door de instantiebrede Max. mate van parallellisme in te stellen op 1
- analyseer de zwaarste verzoeken en selecteer het optimale aantal threads ervoor
- stel de maximale mate van parallelliteit in op het geselecteerde optimale aantal threads verkregen uit stap 2, en stel voor specifieke databases de maximale DOP-waarde in verkregen uit stap 2 voor elke database
- analyseer de zwaarste verzoeken en identificeer het negatieve effect van multithreading. Zo ja, verhoog dan de kostendrempel voor parallellisme.
Voor systemen als 1C, Microsoft CRM en Microsoft NAV is het verbieden van multithreading in de meeste gevallen geschikt
Ook als er een Standard-editie is, is het verbod op multithreading in de meeste gevallen geschikt vanwege het feit dat deze editie beperkt is in het aantal CPU-cores.
Voor OLAP-systemen is het hierboven beschreven algoritme niet geschikt.
Uit eigen ervaring raad ik het volgende algoritme van acties aan voor OLAP-systemen voor het instellen van parallellisme-eigenschappen:
- analyseer de zwaarste verzoeken en selecteer het optimale aantal threads ervoor
- stel de maximale mate van parallelliteit in op het geselecteerde optimale aantal threads verkregen uit stap 1, en stel voor specifieke databases de maximale DOP-waarde in verkregen uit stap 1 voor elke database
- analyseer de zwaarste vragen en identificeer het negatieve effect van het beperken van gelijktijdigheid. Als dit het geval is, verlaag dan de waarde van de kostendrempel voor parallellisme of herhaal stap 1-2 van dit algoritme
Dat wil zeggen, voor OLTP-systemen gaan we van single-threading naar multi-threading, en voor OLAP-systemen gaan we daarentegen van multi-threading naar single-threading. Zo kunt u de optimale instellingen voor parallellisme kiezen voor zowel een specifieke database als de volledige instantie van MS SQL Server.
Het is ook belangrijk om te begrijpen dat de instellingen van de parallellisme-eigenschappen in de loop van de tijd moeten worden gewijzigd, op basis van de resultaten van het bewaken van de prestaties van MS SQL Server.
Richtlijnen voor het instellen van traceervlaggen
Vanuit mijn eigen ervaring en de ervaring van mijn collega's, raad ik voor optimale prestaties aan om de volgende traceervlaggen in te stellen op het runniveau van de MS SQL Server-service voor versies 2008-2016:
- 610 - Minder loggen van invoegingen in geïndexeerde tabellen. Kan helpen met invoegen in tabellen met veel records en veel transacties, waarbij WRITELOG vaak lang wacht op wijzigingen in indexen
- 1117 - Als een bestand in een bestandsgroep voldoet aan de vereisten voor autogrowth-drempels, groeien alle bestanden in de bestandsgroep
- 1118 - Dwingt alle objecten om zich in verschillende gebieden te bevinden (verbod op gemengde gebieden), wat de noodzaak minimaliseert om de SGAM-pagina te scannen, die wordt gebruikt om gemengde gebieden te volgen
- 1224 - Schakelt slotescalatie uit op basis van het aantal vergrendelingen. Overmatig geheugengebruik kan echter leiden tot escalatie van het slot
- 2371 - Wijzigt de vaste drempel voor het automatisch bijwerken van statistieken in de dynamische automatische drempel voor het bijwerken van statistieken. Belangrijk voor het bijwerken van queryplannen voor grote tabellen, waarbij een onjuist aantal records resulteert in foutieve uitvoeringsplannen
- 3226 - Onderdrukt back-up succesberichten in het foutenlogboek
- 4199 - Bevat wijzigingen in de query-optimizer die is uitgebracht in CU's en SQL Server Service Packs
- 6532-6534 - Bevat prestatieverbeteringen voor querybewerkingen op ruimtelijke gegevenstypen
- 8048 - Converteert NUMA-gepartitioneerde geheugenobjecten naar CPU-gepartitioneerde objecten
- 8780 - Maakt extra tijdsbesteding mogelijk voor queryplanning. Sommige verzoeken zonder deze vlag kunnen worden afgewezen omdat ze geen queryplan hebben (zeer zeldzame bug)
- 8780 - 9389 - Schakelt aanvullende dynamische geheugenbuffer in voor instructies in batchmodus, waardoor de operator in batchmodus extra geheugen kan aanvragen en het verplaatsen van gegevens naar tempdb kan voorkomen als er extra geheugen beschikbaar is
Ook vóór 2016 is het handig om traceringsvlag 2301 in te schakelen, waardoor verbeterde besluitvormingsondersteunende optimalisaties mogelijk zijn en dus helpt bij het kiezen van meer correcte queryplannen. Vanaf versie 2016 heeft het echter vaak een negatief effect op vrij lange algehele uitvoeringstijden van query's.
Voor systemen met veel indexen (bijvoorbeeld voor 1C-databases) raad ik ook aan om traceervlag 2330 in te schakelen, waardoor het verzamelen van indexgebruik wordt uitgeschakeld, wat over het algemeen een positief effect heeft op het systeem.
Zie voor meer informatie over traceringsvlaggen
Vanaf de bovenstaande link is het ook belangrijk om rekening te houden met versies en builds van MS SQL Server, aangezien voor nieuwere versies sommige traceervlaggen standaard zijn ingeschakeld of geen effect hebben.
U kunt de traceervlag in- en uitschakelen met respectievelijk de opdrachten DBCC TRACEON en DBCC TRACEOFF. Voor meer details zie
U kunt de status van de traceervlaggen opvragen met de opdracht DBCC TRACESTATUS:
Om ervoor te zorgen dat traceervlaggen worden opgenomen in de autostart van de MS SQL Server-service, moet u naar SQL Server Configuration Manager gaan en deze traceervlaggen toevoegen via -T in de service-eigenschappen:
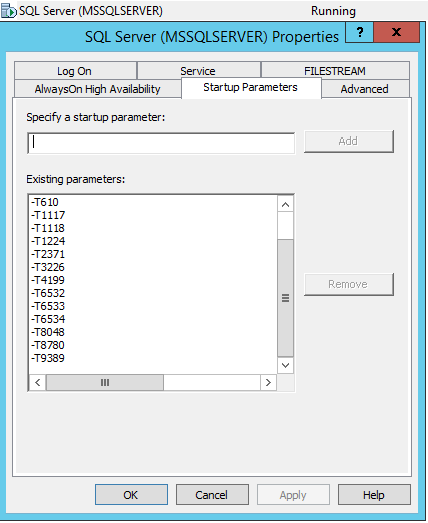
Resultaten van
In dit artikel zijn enkele aspecten van het monitoren van MS SQL Server geanalyseerd, met behulp waarvan u snel het gebrek aan RAM en vrije CPU-tijd kunt identificeren, evenals een aantal andere, minder voor de hand liggende problemen. De meest gebruikte traceervlaggen zijn beoordeeld.
Bronnen:
»
»
»
»
»
»
»
Bron: www.habr.com
