

Tot voor kort bewaarde Odnoklassniki ongeveer 50 TB aan realtime verwerkte data in SQL Server. Het is vrijwel onmogelijk om met behulp van SQL DBMS snelle en betrouwbare toegang tot zo'n volume te bieden, en bovendien bestand te zijn tegen datacenterstoringen. Meestal wordt in dergelijke gevallen een van de NoSQL-opslagmedia gebruikt, maar niet alles kan naar NoSQL worden overgezet: sommige entiteiten vereisen ACID-transactiegaranties.
Dit bracht ons tot de keuze voor NewSQL-opslag, een DBMS dat fouttolerantie, schaalbaarheid en prestaties van NoSQL-systemen biedt, maar tegelijkertijd de ACID-garanties behoudt die klassieke systemen bieden. Er zijn weinig werkende industriële systemen van deze nieuwe klasse, dus hebben we een dergelijk systeem zelf geïmplementeerd en in gebruik genomen.
Hoe het werkt en wat er gebeurt, leest u hieronder.
Tegenwoordig telt Odnoklassniki maandelijks meer dan 70 miljoen unieke bezoekers. grootste sociale netwerken ter wereld en een van de twintig sites waar gebruikers de meeste tijd doorbrengen. De infrastructuur van OK verwerkt zeer hoge belastingen: meer dan een miljoen HTTP-verzoeken per seconde naar de front-ends. Delen van het serverpark, meer dan 8000 stuks, bevinden zich dicht bij elkaar – in vier datacenters in Moskou – wat een netwerkvertraging van minder dan 1 ms tussen de servers mogelijk maakt.
We gebruiken Cassandra sinds 2010, te beginnen met versie 0.6. Momenteel zijn er enkele tientallen clusters in gebruik. Het snelste cluster verwerkt meer dan 4 miljoen bewerkingen per seconde en het grootste cluster heeft een opslagcapaciteit van 260 TB.
Dit zijn echter allemaal gewone NoSQL-clusters die voor opslag worden gebruikt Gegevens. We wilden de belangrijkste consistente opslag, Microsoft SQL Server, vervangen, die al sinds de oprichting van Odnoklassniki werd gebruikt. De opslag bestond uit meer dan 300 SQL Server Standard Edition-machines, die 50 TB aan gegevens bevatten - bedrijfsentiteiten. Deze gegevens worden gewijzigd in het kader van ACID-transacties en vereisen .
Om gegevens over SQL Server-knooppunten te distribueren, hebben we zowel verticale als horizontale (sharding). Historisch gezien gebruikten we een eenvoudig datashardingschema: aan elke entiteit werd een token toegewezen – een functie van de entiteits-ID. Entiteiten met hetzelfde token werden op één SQL-server geplaatst. De master-detailrelatie werd zo geïmplementeerd dat de tokens van de hoofd- en gegenereerde records altijd overeenkwamen en zich op dezelfde server bevonden. In een sociaal netwerk worden bijna alle records namens de gebruiker gegenereerd – dit betekent dat alle gebruikersgegevens binnen één functioneel subsysteem op één server worden opgeslagen. Dat wil zeggen, een zakelijke transactie betrof bijna altijd tabellen van één SQL-server, wat het mogelijk maakte om dataconsistentie te garanderen met behulp van lokale ACID-transacties, zonder dat er gedistribueerde ACID-transacties.
Dankzij sharding en om SQL te versnellen:
- Wij maken geen gebruik van buitenlandse sleutelbeperkingen, aangezien de entiteits-ID zich bij sharding op een andere server kan bevinden.
- We maken geen gebruik van stored procedures en triggers vanwege de extra belasting van de DBMS CPU.
- We gebruiken geen JOINs vanwege alle bovenstaande redenen en de vele willekeurige leesbewerkingen van de schijf.
- Buiten een transactie gebruiken we het isolatieniveau Read Uncommitted om deadlocks te verminderen.
- Wij voeren alleen korte transacties uit (gemiddeld korter dan 100 ms).
- We maken geen gebruik van UPDATE en DELETE voor meerdere rijen vanwege het grote aantal deadlocks. We werken telkens slechts één record bij.
- Wij voeren query's altijd alleen uit op indexen. Een query met een volledig tabelscanplan overbelast de database en resulteert in fouten voor ons.
Met deze stappen konden we bijna de maximale prestaties uit SQL-servers halen. Er kwamen echter steeds meer problemen. Laten we ze eens bekijken.
Problemen met SQL
- Omdat we zelfgeschreven sharding gebruikten, werd het toevoegen van nieuwe shards handmatig door beheerders gedaan. Gedurende deze tijd konden schaalbare datareplica's geen verzoeken verwerken.
- Naarmate het aantal records in een tabel toeneemt, neemt de snelheid van het invoegen en wijzigen af. Wanneer u indexen toevoegt aan een bestaande tabel, neemt de snelheid enkele malen af. Het aanmaken en opnieuw aanmaken van indexen gaat gepaard met downtime.
- Beschikbaarheid in productie van kleine hoeveelheden Windows Voor SQL Server maakt dit het beheer van de infrastructuur lastig.
Maar het grootste probleem is
fout tolerantie
Klassieke SQL Server heeft een slechte fouttolerantie. Stel dat u slechts één databaseserver hebt en deze eens in de drie jaar uitvalt. Gedurende deze periode is de site 20 minuten down, wat acceptabel is. Als u 64 servers hebt, is de site eens in de drie weken down. En als u 200 servers hebt, is de site elke week down. Dit is een probleem.
Wat kan er gedaan worden om de fouttolerantie van SQL Server te verbeteren? Wikipedia suggereert dat we : waarbij er een back-up is voor het geval dat een van de componenten uitvalt.
Hiervoor is een vloot aan dure apparatuur nodig: meerdere duplicaties, glasvezel, openbare opslag en de inschakeling van een reserveknooppunt werkt onbetrouwbaar: ongeveer 10% van de inschakelingen eindigt met het uitvallen van het reserveknooppunt in een trein achter het hoofdknooppunt.
Maar het grootste nadeel van zo'n cluster met hoge beschikbaarheid is de nulbeschikbaarheid bij uitval van het datacenter waarin het zich bevindt. Odnoklassniki heeft vier datacenters en we moeten de werking garanderen bij een volledige uitval van één ervan.
Voor dit doel zou men kunnen gebruikmaken van Replicatie ingebouwd in SQL Server. Deze oplossing is veel duurder vanwege de softwarekosten en heeft last van bekende problemen met replicatie: onvoorspelbare transactievertragingen bij synchrone replicatie en vertragingen bij het toepassen van replicaties (en daardoor verloren wijzigingen) bij asynchrone replicatie. De impliciete maakt deze optie voor ons volkomen onbruikbaar.
Al deze problemen vereisten een radicale oplossing en we zijn ze in detail gaan analyseren. Hier moeten we eerst kennismaken met wat SQL Server voornamelijk doet: transacties.
Eenvoudige transactie
Laten we de eenvoudigste transactie bekijken, vanuit het perspectief van een SQL-programmeur: het toevoegen van een foto aan een album. Albums en foto's worden in verschillende tabellen opgeslagen. Het album bevat een teller met openbare foto's. Zo'n transactie wordt vervolgens onderverdeeld in de volgende stappen:
- We blokkeren het album op toonsoort.
- Maak een record in de fototabel.
- Als de foto een openbare status heeft, dan ronden we de teller van openbare foto's in het album af, werken de invoer bij en bevestigen de transactie.
Of in pseudocode:
TX.start("Albums", id);
Album album = albums.lock(id);
Photo photo = photos.create(…);
if (photo.status == PUBLIC ) {
album.incPublicPhotosCount();
}
album.update();
TX.commit();We zien dat het meest voorkomende scenario voor een zakelijke transactie is om gegevens uit de database in het geheugen van de applicatieserver te lezen, iets te wijzigen en de nieuwe waarden weer in de database op te slaan. Meestal werken we bij zo'n transactie meerdere entiteiten en tabellen bij.
Bij het uitvoeren van een transactie kan een concurrerende wijziging van dezelfde gegevens uit een ander systeem plaatsvinden. Antispam kan bijvoorbeeld besluiten dat de gebruiker verdacht is en dat daarom alle foto's van de gebruiker niet langer openbaar zouden moeten zijn. Deze moeten ter moderatie worden verzonden, wat betekent dat photo.status naar een andere waarde wordt gewijzigd en de bijbehorende tellers worden teruggedraaid. Indien deze bewerking plaatsvindt zonder garanties voor atomaire toepassing en isolatie van concurrerende wijzigingen, zoals in , dan is het resultaat niet wat u wenst: de fototeller geeft dan een onjuiste waarde aan of niet alle foto's worden ter beoordeling verzonden.
Gedurende het bestaan van Odnoklassniki is er veel vergelijkbare code geschreven, waarmee verschillende bedrijfsentiteiten binnen één transactie worden gemanipuleerd. Gebaseerd op de ervaring met migraties naar NoSQL van We weten dat de grootste uitdagingen (en tijdsinvesteringen) voortkomen uit het ontwikkelen van code om de dataconsistentie te behouden. Daarom hebben we de belangrijkste vereiste voor de nieuwe opslag beschouwd als het leveren van echte ACID-transacties voor de applicatielogica.
Andere, niet minder belangrijke, vereisten waren:
- In het geval van een storing in het datacenter moet zowel lezen als schrijven naar de nieuwe opslag mogelijk zijn.
- Behoud van de huidige ontwikkelsnelheid. Dat wil zeggen dat bij het werken met een nieuwe repository de hoeveelheid code ongeveer gelijk moet blijven, er geen noodzaak is om iets aan de repository toe te voegen, algoritmen voor conflictoplossing te ontwikkelen, secundaire indexen te onderhouden, enz.
- De nieuwe opslag moet snel genoeg zijn om gegevens te lezen en transacties te verwerken, wat in feite betekende dat academisch strenge, algemene, maar trage oplossingen zoals .
- Automatische schaling onderweg.
- U maakt gebruik van goedkope servers, zonder dat u speciale hardware hoeft aan te schaffen.
- Mogelijkheid om de opslag te ontwikkelen door de ontwikkelaars van het bedrijf. Met andere woorden, er werd prioriteit gegeven aan interne of open-sourceoplossingen, bij voorkeur in Java.
Oplossingen, oplossingen
Na het analyseren van mogelijke oplossingen kwamen we tot twee mogelijke architectuurkeuzes:
De eerste is om elke SQL-server te nemen en de vereiste fouttolerantie, schaalbaarheidsmechanisme, fouttolerant cluster, conflictoplossing en gedistribueerde, betrouwbare en snelle ACID-transacties te implementeren. We beoordeelden deze optie als niet triviaal en arbeidsintensief.
De tweede optie is om een kant-en-klare NoSQL-opslag te nemen met geïmplementeerde schaalbaarheid, een failovercluster, conflictoplossing en zelf transacties en SQL te implementeren. Op het eerste gezicht lijkt zelfs de implementatie van SQL, om nog maar te zwijgen van ACID-transacties, een taak die jaren in beslag zal nemen. Maar toen realiseerden we ons dat de set SQL-functies die we in de praktijk gebruiken, net zo ver verwijderd is van ANSI SQL als is ver verwijderd van ANSI SQL. Nadat we CQL nader hadden bekeken, beseften we dat het dicht genoeg in de buurt kwam van wat we nodig hadden.
Cassandra en CQL
Wat is er zo interessant aan Cassandra? Welke mogelijkheden heeft het?
Ten eerste kunt u hier tabellen aanmaken met ondersteuning voor verschillende gegevenstypen. U kunt SELECT of UPDATE uitvoeren op basis van de primaire sleutel.
CREATE TABLE photos (id bigint KEY, owner bigint,…);
SELECT * FROM photos WHERE id=?;
UPDATE photos SET … WHERE id=?;Om de consistentie van de replicagegevens te garanderen, gebruikt Cassandra In het eenvoudigste geval betekent dit dat wanneer drie replica's van dezelfde rij op verschillende clusterknooppunten worden geplaatst, een schrijfbewerking als succesvol wordt beschouwd als de meerderheid van de knooppunten (d.w.z. twee van de drie) het succes van deze schrijfbewerking hebben bevestigd. De gegevens van een rij worden als consistent beschouwd als tijdens het lezen de meerderheid van de knooppunten is gepolled en bevestigd. Met drie replica's is dus volledige en onmiddellijke gegevensconsistentie gegarandeerd als één knooppunt uitvalt. Deze aanpak stelde ons in staat een nog betrouwbaarder schema te implementeren: stuur altijd verzoeken naar alle drie de replica's en wacht op een reactie van de twee snelste. Een late reactie van de derde replica wordt vervolgens verwijderd. Het knooppunt dat te laat reageert, kan ernstige problemen ondervinden - vertragingen, garbage collection in de JVM, direct memory reclaim in de Linux-kernel, hardwarestoringen, verbreking van de verbinding met het netwerk. Dit heeft echter geen invloed op de werking of gegevens van de client.
De aanpak waarbij we contact maken met drie knooppunten en een reactie van twee krijgen, wordt genoemd : het verzoek voor extra replica's wordt verzonden nog voordat het "eraf valt".
Een ander voordeel van Cassandra is Batchlog, een mechanisme dat ervoor zorgt dat een batch wijzigingen die je aanbrengt, volledig of helemaal niet wordt toegepast. Dit stelt ons in staat om de A in ACID – atomiciteit – direct op te lossen.
Het dichtst bij transacties in Cassandra komen de zogenaamde ""Maar het zijn verre van 'echte' ACID-transacties: in feite is dit een kans om op de gegevens van slechts één record, gebruikmakend van consensus over het robuuste Paxos-protocol. De snelheid van dergelijke transacties is daarom laag.
Wat we misten in Cassandra
We moesten dus echte ACID-transacties in Cassandra implementeren. Daarmee konden we eenvoudig twee andere handige functies van klassieke DBMS'en implementeren: consistente, snelle indexen, waarmee we gegevens niet alleen op basis van de primaire sleutel konden selecteren, en een regelmatige generator van monotone, automatisch oplopende ID's.
Kegel
Zo ontstond een nieuw DBMS Kegel, bestaande uit drie typen serverknooppunten:
- Opslagruimten zijn (bijna) standaard Cassandra-servers die verantwoordelijk zijn voor het opslaan van gegevens op lokale schijven. Naarmate de belasting en het datavolume toenemen, kan het aantal eenvoudig worden opgeschaald naar tientallen en honderden.
- Transactiecoördinatoren - zorgen voor de uitvoering van transacties.
- Clients zijn applicatieservers die bedrijfsprocessen implementeren en transacties initiëren. Er kunnen duizenden van dergelijke clients zijn.
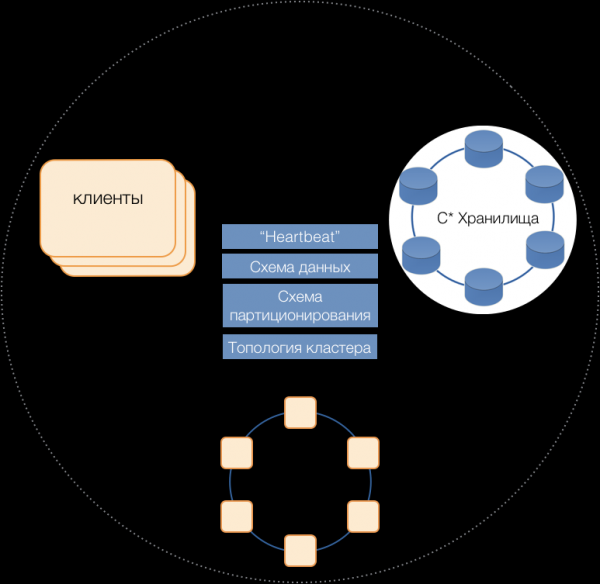
Servers van alle typen maken deel uit van een gemeenschappelijk cluster, gebruiken het interne berichtenprotocol van Cassandra om met elkaar te communiceren en voor het uitwisselen van clusterinformatie. Met behulp van Heartbeat leren servers over wederzijdse storingen en ondersteunen ze één enkel gegevensschema - tabellen, hun structuur en replicatie; partitioneringsschema, clustertopologie, enzovoort.
Cliënten
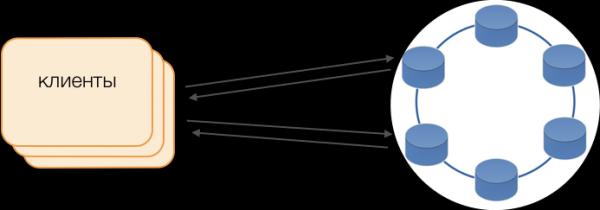
In plaats van standaarddrivers wordt de Fat Client-modus gebruikt. Een dergelijk knooppunt slaat geen gegevens op, maar kan fungeren als coördinator van de uitvoering van verzoeken. De client zelf fungeert als coördinator van zijn verzoeken: hij peilt opslagreplica's en lost conflicten op. Dit is niet alleen betrouwbaarder en sneller dan de standaarddriver, die communicatie met een externe coördinator vereist, maar stelt u ook in staat de overdracht van verzoeken te beheren. Buiten een openstaande transactie op de client worden verzoeken naar opslaglocaties verzonden. Als de client een transactie heeft geopend, worden alle verzoeken binnen de transactie naar de transactiecoördinator verzonden.
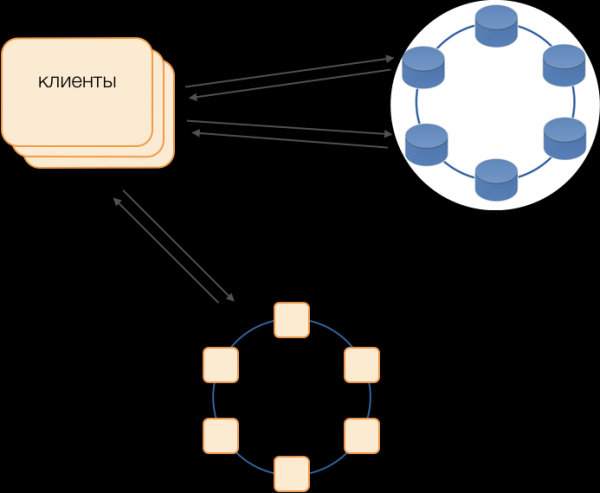
C*One Transactiecoördinator
De coördinator is wat we voor C*One vanaf nul hebben geïmplementeerd. Deze is verantwoordelijk voor het beheer van transacties, vergrendelingen en de volgorde waarin transacties worden toegepast.
Voor elke transactie die wordt afgehandeld, genereert de coördinator een tijdstempel: elke volgende is groter dan die van de vorige transactie. Omdat Cassandra's conflictoplossingssysteem gebaseerd is op tijdstempels (van twee conflicterende records wordt degene met de laatste tijdstempel als relevant beschouwd), wordt het conflict altijd opgelost ten gunste van de volgende transactie. Op deze manier hebben we geïmplementeerd — een goedkope manier om conflicten in een gedistribueerd systeem op te lossen.
Sloten
Om isolatie te garanderen, besloten we de eenvoudigste methode te gebruiken: pessimistische vergrendelingen op de primaire sleutel van het record. Met andere woorden: bij een transactie moet het record eerst worden vergrendeld, en pas daarna worden gelezen, gewijzigd en opgeslagen. Pas na een succesvolle commit kan het record worden ontgrendeld, zodat concurrerende transacties het kunnen gebruiken.
Het implementeren van een dergelijke vergrendeling is eenvoudig in een niet-gedistribueerde omgeving. In een gedistribueerd systeem zijn er twee hoofdopties: ofwel implementeer je gedistribueerde vergrendeling op een cluster, ofwel distribueer je transacties zodat transacties met één record altijd door dezelfde coördinator worden afgehandeld.
Omdat de gegevens in ons geval al over lokale transactiegroepen in SQL zijn verdeeld, is besloten om lokale transactiegroepen aan coördinatoren toe te wijzen: de ene coördinator voert alle transacties met een token van 0 tot en met 9 uit, de tweede met een token van 10 tot en met 19, enzovoort. Hierdoor wordt elke instantie van de coördinator de master van de transactiegroep.
Vervolgens kunnen de vergrendelingen worden geïmplementeerd als een eenvoudige HashMap in het geheugen van de coördinator.
Weigeringen van coördinatoren
Omdat één coördinator exclusief een groep transacties bedient, is het erg belangrijk om de mislukking ervan snel te detecteren, zodat de transactie binnen de time-out opnieuw kan worden geprobeerd. Om dit snel en betrouwbaar te maken, hebben we een volledig gemaasd quorum-hearbeatprotocol gebruikt:
Elk datacenter heeft ten minste twee coördinatorknooppunten. Periodiek stuurt elke coördinator een heartbeatbericht naar de andere coördinatoren, waarin hij hen informeert over de werking van het datacenter en de coördinatoren in het cluster waarvan het de laatste heartbeatberichten heeft ontvangen.
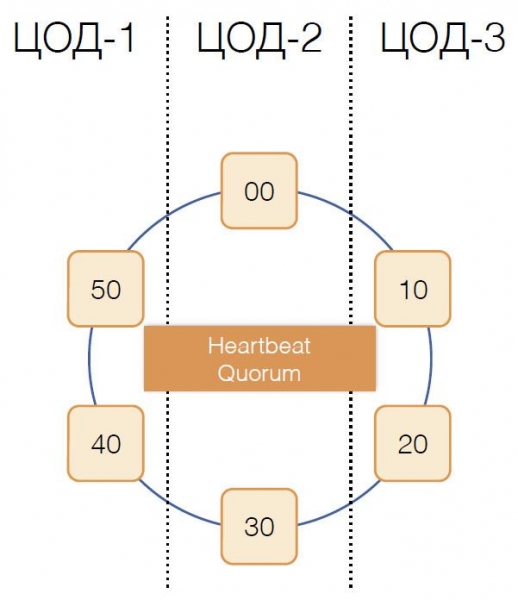
Elke coördinator ontvangt vergelijkbare informatie van de anderen als onderdeel van hun heartbeat-berichten en bepaalt zelf welke knooppunten van het cluster functioneren en welke niet, aan de hand van het quorumprincipe: als knooppunt X van de meerderheid van de knooppunten in het cluster informatie heeft ontvangen over de normale ontvangst van berichten van knooppunt Y, dan functioneert Y. En omgekeerd: zodra de meerderheid het verlies van berichten van knooppunt Y meldt, is Y uitgevallen. Interessant is dat als het quorum knooppunt X laat weten dat het geen berichten meer van hem ontvangt, knooppunt X zichzelf als uitgevallen beschouwt.
Heartbeat-berichten worden met een hoge frequentie verzonden, ongeveer 20 keer per seconde, met een periode van 50 ms. In Java is het moeilijk om een applicatierespons binnen 50 ms te garanderen vanwege de vergelijkbare duur van pauzes die door de garbage collector worden veroorzaakt. We zijn erin geslaagd een dergelijke responstijd te bereiken met de G1-garbage collector, waarmee u een doel kunt specificeren voor de duur van GC-pauzes. Soms, en dat is vrij zeldzaam, duren de pauzes van de collector echter langer dan 50 ms, wat kan leiden tot een onjuiste detectie van een storing. Om dit te voorkomen, meldt de coordinator het uitvallen van een extern knooppunt niet wanneer het eerste heartbeat-bericht daarvan verloren gaat, maar alleen als er meerdere berichten achter elkaar verloren gaan. Op deze manier zijn we erin geslaagd het uitvallen van het coordinator-knooppunt binnen 200 ms te detecteren.
Maar het is niet voldoende om snel te achterhalen welk knooppunt niet meer functioneert. Je moet er iets aan doen.
езервирование
Het klassieke schema gaat ervan uit dat in het geval van het falen van een meester de verkiezing van een nieuwe meester wordt gestart met behulp van een van de volgende opties: algoritmen. Dergelijke algoritmen hebben echter bekende problemen met tijdsconvergentie en de duur van het verkiezingsproces zelf. We zijn erin geslaagd dergelijke extra vertragingen te voorkomen door gebruik te maken van een coördinatorvervangingsschema in een volledig verbonden netwerk:
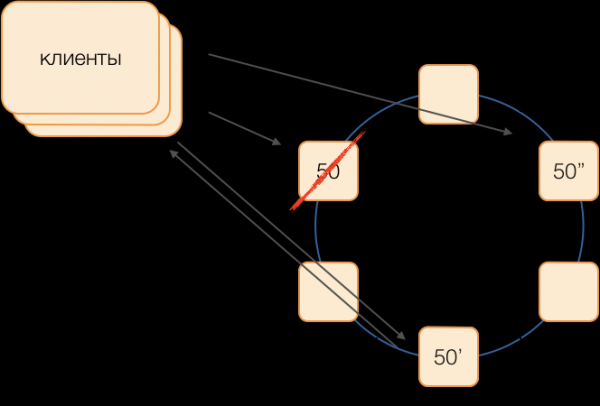
Stel dat we een transactie in groep 50 willen uitvoeren. We definiëren vooraf het vervangingsschema, d.w.z. welke knooppunten groep 50-transacties zullen uitvoeren in geval van uitval van de primaire coördinator. Ons doel is om de bruikbaarheid van het systeem te behouden in geval van een uitval van het datacenter. We definiëren dat de eerste reserve een knooppunt van een ander datacenter zal zijn en de tweede reserve een knooppunt van een derde. Dit schema wordt één keer geselecteerd en verandert niet totdat de clustertopologie verandert, d.w.z. totdat er nieuwe knooppunten bijkomen (wat zeer zelden gebeurt). De volgorde voor het selecteren van een nieuwe actieve master in geval van uitval van de oude is altijd als volgt: de eerste reserve wordt de actieve master en als deze niet meer functioneert, de tweede reserve.
Dit schema is betrouwbaarder dan het universele algoritme, omdat om een nieuwe master te activeren, het voldoende is om het feit van de storing van de oude master vast te stellen.
Maar hoe weten clients welke master momenteel actief is? Het is onmogelijk om in 50 ms informatie naar duizenden clients te sturen. Het is mogelijk dat een client een verzoek stuurt om een transactie te openen, zonder te weten dat deze master niet meer functioneert, en dat het verzoek vastloopt op een time-out. Om dit te voorkomen, sturen clients speculatief een verzoek om een transactie te openen naar de groepsmaster en beide reserves tegelijk, maar alleen degene die op dat moment de actieve master is, zal op dit verzoek reageren. De client zal alle verdere communicatie binnen de transactie uitsluitend met de actieve master uitvoeren.
Back-up masters plaatsen ontvangen verzoeken voor transacties die niet van hen zijn in de wachtrij met onvoltooide transacties, waar ze enige tijd worden opgeslagen. Als de actieve master uitvalt, verwerkt de nieuwe master verzoeken om transacties te openen vanuit zijn wachtrij en reageert deze op de client. Als de client er al in is geslaagd een transactie te openen met de oude master, wordt het tweede antwoord genegeerd (en uiteraard wordt zo'n transactie niet voltooid en door de client herhaald).
Hoe werkt een transactie?
Stel dat de client de coördinator een verzoek stuurt om een transactie te openen voor een bepaalde entiteit met een bepaalde primaire sleutel. De coördinator vergrendelt deze entiteit en plaatst deze in de in-memory lock-tabel. Indien nodig leest de coördinator deze entiteit uit de opslag en slaat de ontvangen gegevens op in de transactiestatus in het geheugen van de coördinator.
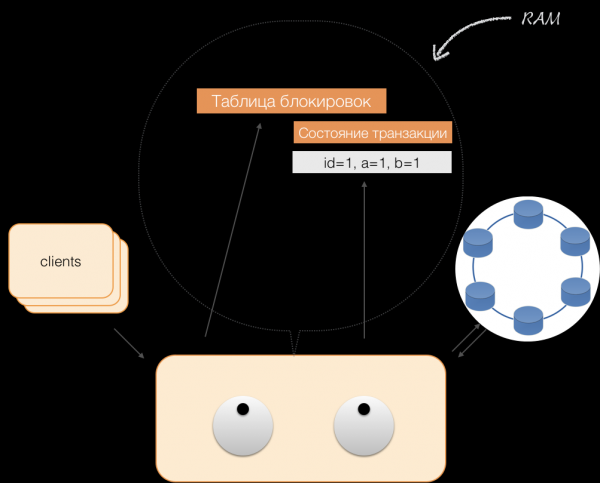
Wanneer een client gegevens in een transactie wil wijzigen, stuurt hij een verzoek naar de coördinator om de entiteit te wijzigen. De coördinator plaatst de nieuwe gegevens vervolgens in de transactiestatustabel in het geheugen. Op dat moment is de schrijfbewerking voltooid; er wordt niets naar de opslag geschreven.
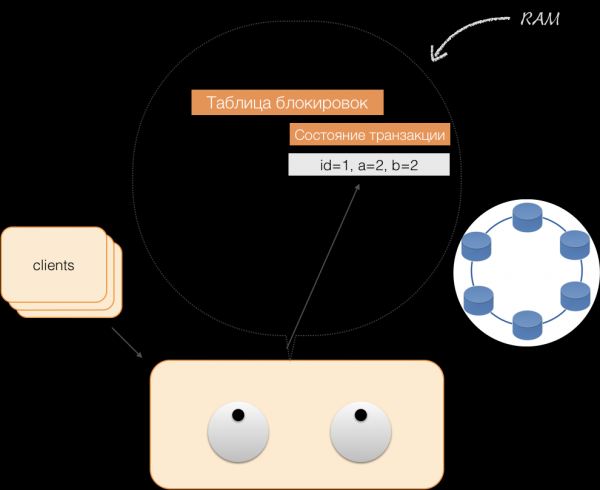
Wanneer een cliënt eigen gewijzigde gegevens opvraagt binnen een actieve transactie, handelt de coördinator als volgt:
- Als de ID al in de transactie bestaat, worden de gegevens uit het geheugen gehaald;
- Als de ID niet in het geheugen staat, worden de ontbrekende gegevens uit de node-opslag gelezen en gecombineerd met de gegevens die al in het geheugen staan. Het resultaat wordt vervolgens aan de client gegeven.
Zo kan de client zijn eigen wijzigingen lezen, maar andere clients zien deze wijzigingen niet, omdat deze alleen in het geheugen van de coördinator zijn opgeslagen en nog niet in de Cassandra-knooppunten.
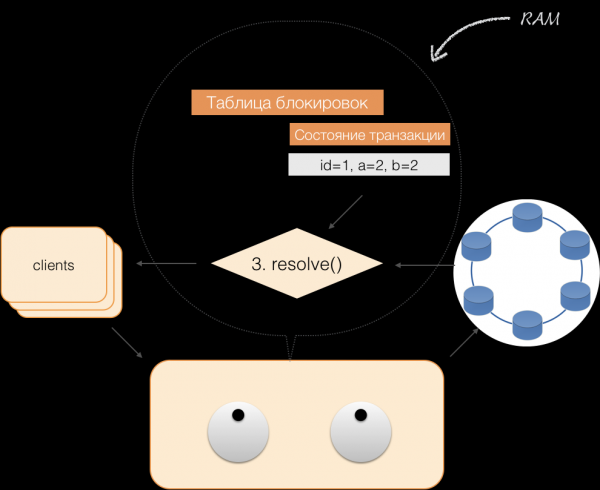
Wanneer de client een commit verzendt, wordt de status die zich in het geheugen van de service bevond door de coördinator opgeslagen in een gelogde batch. Deze batch wordt vervolgens naar de Cassandra-opslag gestuurd. De opslag doet er alles aan om ervoor te zorgen dat deze batch atomisch (volledig) wordt toegepast en stuurt de respons terug naar de coördinator, die vervolgens de vergrendelingen vrijgeeft en het succes van de transactie aan de client bevestigt.
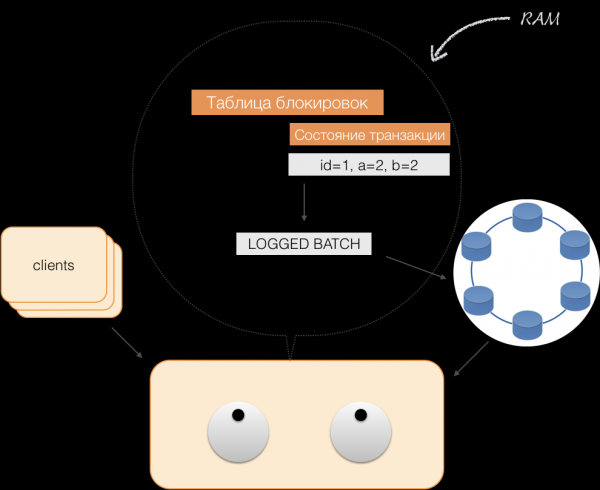
En om terug te draaien, hoeft de coördinator alleen het geheugen vrij te maken dat door de transactiestatus wordt ingenomen.
Als resultaat van bovenstaande verbeteringen hebben we de ACID-principes geïmplementeerd:
- AtomiciteitDit garandeert dat geen enkele transactie gedeeltelijk in het systeem wordt vastgelegd; ofwel worden alle subbewerkingen uitgevoerd, ofwel wordt er geen enkele uitgevoerd. We hanteren dit principe door gebruik te maken van gelogde batchverwerking in Cassandra.
- ConsistentieElke succesvolle transactie registreert per definitie alleen geldige resultaten. Als na het openen van een transactie en het uitvoeren van enkele bewerkingen blijkt dat het resultaat ongeldig is, wordt een rollback uitgevoerd.
- IsolatieBij het uitvoeren van een transactie mogen gelijktijdige transacties de uitkomst ervan niet beïnvloeden. Gelijktijdige transacties worden geïsoleerd met behulp van pessimistische vergrendelingen op de coördinator. Voor reads buiten een transactie wordt het isolatieprincipe toegepast op het Read Committed-niveau.
- stabiliteitOngeacht problemen op de lagere niveaus - een stroomstoring of een hardwarestoring - moeten de wijzigingen die zijn aangebracht door een succesvol voltooide transactie bewaard blijven nadat de bewerking is hervat.
Lezen met behulp van indexen
Laten we een eenvoudige tabel nemen:
CREATE TABLE photos (
id bigint primary key,
owner bigint,
modified timestamp,
…)Het heeft een ID (primaire sleutel), eigenaar en wijzigingsdatum. U hoeft alleen maar een eenvoudige query uit te voeren: selecteer gegevens op eigenaar met de wijzigingsdatum "in de afgelopen 24 uur".
SELECT *
WHERE owner=?
AND modified>?Om een dergelijke query snel te kunnen verwerken, is het in een klassieke SQL-database noodzakelijk om een index op de kolommen te bouwen (eigenaar, gewijzigd). Dit is vrij eenvoudig, omdat we nu ACID-garanties hebben!
Indexen in C*One
Er is een brontabel met foto's, waarin de record-ID de primaire sleutel is.

Voor een index maakt C*One een nieuwe tabel aan die een kopie is van de originele tabel. De sleutel komt overeen met de indexexpressie, maar bevat ook de primaire sleutel van de record uit de originele tabel:
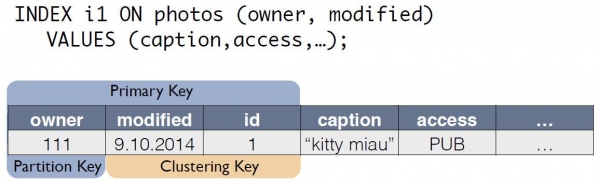
De query voor "eigenaar voor de laatste dag" kan nu worden herschreven als een selectie uit een andere tabel:
SELECT * FROM i1_test
WHERE owner=?
AND modified>?De consistentie van de gegevens in de originele fototabel en index i1 wordt automatisch gehandhaafd door de coördinator. Alleen al op basis van het dataschema genereert en onthoudt de coördinator, wanneer een wijziging wordt ontvangen, niet alleen de wijziging in de hoofdtabel, maar ook de wijzigingen in de kopieën. Er worden geen aanvullende acties uitgevoerd met de indextabel, logs worden niet gelezen en vergrendelingen worden niet gebruikt. Dat wil zeggen dat het toevoegen van indexen vrijwel geen resources verbruikt en vrijwel geen invloed heeft op de snelheid van het doorvoeren van wijzigingen.
Met ACID konden we indexen implementeren "zoals SQL". Ze zijn consistent, schaalbaar, snel, kunnen samengesteld worden en zijn ingebouwd in de CQL-querytaal. Er zijn geen wijzigingen in de applicatiecode nodig om indexen te ondersteunen. Alles is zo eenvoudig als SQL. En belangrijker nog, indexen hebben geen invloed op de snelheid van wijzigingen in de oorspronkelijke transactietabel.
Wat is er gebeurd
Drie jaar geleden hebben we C*One ontwikkeld en commercieel in gebruik genomen.
Wat hebben we als resultaat gekregen? Laten we dit evalueren aan de hand van het voorbeeld van het subsysteem voor het verwerken en opslaan van foto's, een van de belangrijkste soorten data in het sociale netwerk. We hebben het hierbij niet over de foto's zelf, maar over allerlei meta-informatie. Momenteel heeft Odnoklassniki ongeveer 20 miljard van dergelijke records, verwerkt het systeem 80 leesverzoeken per seconde en tot 8 ACID-transacties per seconde met betrekking tot datawijziging.
Bij gebruik van SQL met replicatiefactor = 1 (maar in RAID 10) werden de metadata van de foto's opgeslagen op een cluster van 32 machines met hoge beschikbaarheid en Microsoft SQL Server (plus 11 back-ups). Daarnaast waren er 10 servers toegewezen voor het opslaan van back-ups. In totaal 50 dure machines. Tegelijkertijd werkte het systeem op de nominale belasting, zonder reserve.
Na de migratie naar het nieuwe systeem behaalden we een replicatiefactor van 3 – een kopie in elk datacenter. Het systeem bestaat uit 63 Cassandra-opslagknooppunten en 6 coördinatormachines, in totaal 69 servers. Deze machines zijn echter veel goedkoper: hun totale kosten bedragen ongeveer 30% van de kosten van het SQL-systeem. Tegelijkertijd blijft de belasting op 30%.
Met de introductie van C*One zijn ook de latenties afgenomen: in SQL duurde een schrijfbewerking ongeveer 4,5 ms. In C*One was dit ongeveer 1,6 ms. De transactieduur is gemiddeld minder dan 40 ms, een commit wordt uitgevoerd in 2 ms, de lees- en schrijftijd is gemiddeld 2 ms. Het 99e percentiel ligt op slechts 3-3,1 ms, en het aantal time-outs is verhonderdvoudigd – allemaal dankzij het wijdverbreide gebruik van speculatie.
Inmiddels zijn de meeste SQL Server-knooppunten buiten gebruik gesteld en worden nieuwe producten uitsluitend met C*One ontwikkeld. We hebben C*One aangepast om in onze cloud te werken. , waardoor we de implementatie van nieuwe clusters konden versnellen, de configuratie konden vereenvoudigen en de werking konden automatiseren. Zonder de broncode zou dit veel moeilijker en omslachtiger zijn geweest.
We zijn momenteel bezig om onze andere opslagfaciliteiten naar de cloud te verplaatsen, maar dat is een heel ander verhaal.
Bron: www.habr.com
