

Introductie
 "Je moet zo snel mogelijk rennen om op je plek te blijven,
"Je moet zo snel mogelijk rennen om op je plek te blijven,
en om ergens te komen, moet je minstens twee keer zo snel rennen!”
(c) Alice in Wonderland
Een tijdje geleden werd mij gevraagd om een lezing te geven analisten ons bedrijf op het gebied van het ontwerpen van datamodellen, omdat we door langdurig (soms jarenlang) te werken aan projecten, uit het oog verliezen wat er om ons heen gebeurt op het gebied van IT-technologieën. Bij ons bedrijf worden (toevallig) veel projecten niet met NoSQL-databases uitgevoerd (althans nog niet). Daarom heb ik in mijn lezing hier speciaal aandacht aan besteed, waarbij ik HBase als voorbeeld gebruikte. Ik heb geprobeerd de stof zo toe te spitsen op degenen die er nog nooit mee hebben gewerkt. Ik heb met name een aantal kenmerken van het ontwerpen van een datamodel geïllustreerd aan de hand van een voorbeeld dat ik een aantal jaar geleden heb gelezen. . Bij het analyseren van voorbeelden vergeleek ik verschillende oplossingen voor hetzelfde probleem om de hoofdgedachten beter over te brengen aan het publiek.
Onlangs vroeg ik mij, “uit verveling”, af (de lange meivakantie in quarantainemodus is hier vooral bevorderlijk voor): in hoeverre zullen theoretische berekeningen overeenkomen met de praktijk? Eigenlijk is zo het idee voor dit artikel ontstaan. Een ontwikkelaar die al een tijdje met NoSQL werkt, leert er misschien niets nieuws van (en slaat daarom misschien de helft van het artikel over). Maar voor analisten, die nog niet nauw met NoSQL hebben gewerkt, denk ik dat het nuttig zal zijn om een basiskennis te krijgen van de specifieke aspecten van het ontwerpen van datamodellen voor HBase.
Voorbeeldanalyse
Ik ben van mening dat u, voordat u NoSQL-databases gaat gebruiken, goed moet nadenken en de voor- en nadelen moet afwegen. Vaak kan het probleem worden opgelost met behulp van een traditioneel relationeel DBMS. Daarom is het beter om NoSQL niet te gebruiken zonder goede redenen. Als er besloten is om een NoSQL-database te gebruiken, moet er rekening mee gehouden worden dat de ontwerpbenaderingen hier enigszins verschillen. Sommige daarvan zijn mogelijk nog onbekend voor mensen die tot nu toe alleen met relationele DBMS hebben gewerkt (volgens mijn observaties). In de ‘relationele’ wereld beginnen we dus meestal met het modelleren van het onderwerpgebied, en pas daarna, indien nodig, denormaliseren we het model. In NoSQL gebruiken we moet onmiddellijk rekening houden met de verwachte scenario's voor het werken met gegevens en de gegevens in eerste instantie denormaliseren. Daarnaast zijn er nog een aantal andere verschillen, die hieronder worden beschreven.
Laten we het volgende "synthetische" probleem eens bekijken, waar we verder mee aan de slag gaan:
Het is noodzakelijk om een structuur te ontwerpen voor het opslaan van een lijst met vrienden van gebruikers van een abstract sociaal netwerk. Voor de eenvoud gaan we ervan uit dat al onze verbindingen gericht zijn (zoals op Instagram, niet op Linkedin). De structuur moet het volgende effectief mogelijk maken:
- Beantwoord de vraag of gebruiker A gebruiker B leest (leespatroon)
- Toestaan dat links worden toegevoegd/verwijderd wanneer gebruiker A zich abonneert/afmeldt bij gebruiker B (sjabloon voor gegevenswijziging)
Er zijn uiteraard meerdere mogelijkheden om dit probleem op te lossen. In een normale relationele database zouden we waarschijnlijk alleen een tabel met koppelingen maken (eventueel getypt, als we bijvoorbeeld een gebruikersgroep moeten opslaan: familie, werk, enz., waartoe een bepaalde 'vriend' behoort). Om de toegangssnelheid te optimaliseren, zouden we indexen/partitionering toevoegen. Waarschijnlijk ziet de finaletafel er ongeveer zo uit:
user_id
vriend_id
Vasya
Petya
Vasya
Оля
hier en verder voor de duidelijkheid en beter begrip zal ik in plaats van ID namen aangeven
In het geval van HBase weten we dat:
- efficiënte zoekopdracht die niet resulteert in een volledige tabelscan is mogelijk uitsluitend op sleutel
- Dit is in feite de reden waarom het schrijven van de SQL-query's die veel mensen gewend zijn voor dergelijke databases een slecht idee is; Technisch gezien kun je natuurlijk een SQL-query met Joins en andere logica naar HBase sturen vanuit dezelfde Impala, maar hoe effectief zal dat zijn...
Daarom zijn we gedwongen om de gebruikers-ID als sleutel te gebruiken. En de eerste gedachte over het onderwerp “waar en hoe bewaar ik de ID’s van vrienden?” misschien een idee om ze in kolommen op te slaan. Deze meest voor de hand liggende en “naïeve” optie zal er ongeveer zo uitzien (laten we het zo noemen) Optie 1 (standaard), voor toekomstige referentie):
Rijsleutel
Sprekers
Vasya
1: Petja
2: Olja
3: Dasha
Petya
1: Masja
2: Vasja
Hier komt elke regel overeen met één netwerkgebruiker. De kolommen hebben namen: 1, 2, … — afhankelijk van het aantal vrienden, en de kolommen slaan de ID's van de vrienden op. Houd er rekening mee dat elke rij een verschillend aantal kolommen heeft. In het voorbeeld in de afbeelding hierboven heeft één rij drie kolommen (1, 2 en 3), en de tweede slechts twee (1 en 2). Hier hebben we zelf gebruikgemaakt van twee eigenschappen van HBase die relationele databases niet hebben:
- de mogelijkheid om de samenstelling van kolommen dynamisch te wijzigen (vriend toevoegen -> kolom toevoegen, vriend verwijderen -> kolom verwijderen)
- Verschillende rijen kunnen verschillende kolomcomposities hebben
Laten we controleren of onze structuur voldoet aan de taakvereisten:
- Gegevens lezen: om te begrijpen of Vasya geabonneerd is op Olya, moeten we lezen de hele lijn door de sleutel RowKey = "Vasya" en door de kolomwaarden itereren totdat we Olya erin "tegenkomen". Of itereer over de waarden van alle kolommen, "niet voldoen aan" Olya en retourneer het antwoord False;
- Gegevens bewerken: een vriend toevoegen: voor een soortgelijk probleem zullen we ook moeten aftrekken de hele lijn met de sleutel RowKey = "Vasya" om het totale aantal van zijn vrienden te tellen. Dit totale aantal vrienden hebben we nodig om het kolomnummer te bepalen waarin we de ID van de nieuwe vriend moeten schrijven.
- Gegevens bewerken: een vriend verwijderen:
- Het is noodzakelijk om af te trekken de hele lijn met de sleutel RowKey = "Vasya" en ga door de kolommen om de kolom te vinden waarin de vriend staat die wordt verwijderd;
- Vervolgens moeten we, nadat we een vriend hebben verwijderd, alle gegevens naar één kolom 'verplaatsen' om te voorkomen dat er 'gaten' in de nummering ontstaan.
Laten we nu eens evalueren hoe productief deze algoritmen zullen zijn, die we zullen moeten implementeren aan de kant van de "voorwaardelijke toepassing". . Laten we de grootte van ons hypothetische sociale netwerk aanduiden als n. Het maximale aantal vrienden dat een gebruiker kan hebben is dan (n-1). We kunnen deze (-1) voor onze doeleinden in het vervolg verwaarlozen, omdat deze niet essentieel is in het kader van het gebruik van O-symbolen.
- Gegevens lezen: het is noodzakelijk om de hele regel af te trekken en alle kolommen in de limiet te doorlopen. Dit betekent dat de bovenste kostenraming ongeveer O(n) zal zijn
- Gegevens bewerken: een vriend toevoegen: om het aantal vrienden te bepalen, moet u door alle kolommen van de rij itereren en vervolgens een nieuwe kolom invoegen => O(n)
- Gegevens bewerken: een vriend verwijderen:
- Vergelijkbaar met optellen: het is vereist om alle kolommen in de limiet te doorlopen => O(n)
- Nadat we de kolommen hebben verwijderd, moeten we ze 'verplaatsen'. Als we dit “frontaal” implementeren, dan hebben we uiteindelijk maximaal (n-1) extra bewerkingen nodig. Maar hier en verderop in het praktische gedeelte zullen we een andere aanpak toepassen, die de “pseudo-shift” zal implementeren in een vast aantal bewerkingen – dat wil zeggen, het zal een constante tijd duren, ongeacht n. Deze constante tijd (om precies te zijn, O(2)) kan worden verwaarloosd vergeleken met O(n). De aanpak wordt geïllustreerd in de onderstaande afbeelding: we kopiëren eenvoudigweg de gegevens uit de 'laatste' kolom naar de kolom waaruit we gegevens willen verwijderen, en verwijderen vervolgens de laatste kolom:

Als resultaat verkregen we in alle scenario's een asymptotische rekencomplexiteit van O(n).
U heeft waarschijnlijk al gemerkt dat we bijna altijd de hele regel uit de database moeten lezen. In twee van de drie gevallen moeten we zelfs alle kolommen doornemen en het totale aantal vrienden tellen. U kunt daarom, als poging tot optimalisatie, een kolom 'aantal' toevoegen waarin u het totale aantal vrienden van elke netwerkgebruiker kunt opslaan. In dit geval kunnen we voorkomen dat we de hele regel moeten lezen om het totale aantal vrienden te berekenen, en alleen één kolom lezen, “count”. Het belangrijkste is om niet te vergeten het aantal bij te werken wanneer u gegevens manipuleert. Dat. we krijgen een verbeterde Optie 2 (aantal):
Rijsleutel
Sprekers
Vasya
1: Petja
2: Olja
3: Dasha
aantal: 3
Petya
1: Masja
2: Vasja
aantal: 2
Vergeleken met de eerste optie:
- Gegevens lezen: om antwoord te krijgen op de vraag "Leest Vasya Olya?" er is niets veranderd => O(n)
- Gegevens bewerken: een vriend toevoegen:We hebben het invoegen van een nieuwe vriend vereenvoudigd, omdat we nu niet de hele regel hoeven te lezen en door de kolommen hoeven te itereren, maar alleen de waarde van de kolom "count" kunnen ophalen, enz. We kunnen onmiddellijk het kolomnummer bepalen voor het invoegen van een nieuwe vriend. Dit resulteert in een reductie van de rekencomplexiteit tot O(1)
- Gegevens bewerken: een vriend verwijderen: Wanneer u een vriend verwijdert, kunt u deze kolom ook gebruiken om het aantal I/O-bewerkingen te verminderen wanneer u gegevens één cel naar links 'verschuift'. Maar de noodzaak om door de kolommen te itereren om de kolom te vinden die verwijderd moet worden, blijft bestaan, dus => O(n)
- Aan de andere kant moeten we nu bij het bijwerken van gegevens elke keer de kolom 'aantal' bijwerken, maar dit kost een constante tijd, die binnen het O-symbolische raamwerk kan worden verwaarloosd.
Over het geheel genomen lijkt optie 2 iets optimaler, maar het lijkt meer op ‘evolutie in plaats van revolutie’. Om een "revolutie" teweeg te brengen, zullen we nodig hebben Optie 3 (kolom).
Laten we alles op zijn kop zetten: laten we benoemen kolomnaam gebruikers-id! Wat er in de kolom zelf geschreven wordt, is voor ons niet belangrijk, laat het het cijfer 1 zijn (over het algemeen kunnen daar nuttige dingen worden opgeslagen, bijvoorbeeld de groep “familie/vrienden/enz.”). Deze aanpak zal een onvoorbereide “leek” die geen ervaring heeft met het werken met NoSQL-databases misschien verbazen, maar het is deze aanpak die het mogelijk maakt om het potentieel van HBase in deze taak veel effectiever te gebruiken:
Rijsleutel
Sprekers
Vasya
Petje: 1
Oud: 1
Dasja: 1
Petya
Masja: 1
Vasja: 1
Hier krijgen we in één klap meerdere voordelen. Om ze te begrijpen, analyseren we de nieuwe structuur en schatten we de rekenkundige complexiteit:
- Gegevens lezen: om de vraag te beantwoorden of Vasya geabonneerd is op Olya, is het voldoende om één kolom “Olya” te lezen: als dat zo is, dan is het antwoord Waar, als dat niet zo is – Onwaar => O(1)
- Gegevens bewerken: een vriend toevoegen: Een vriend toevoegen: voeg gewoon een nieuwe kolom toe "vriend-ID" => O(1)
- Gegevens bewerken: een vriend verwijderen: verwijder gewoon de kolom "vriend-ID" => O(1)
Zoals u kunt zien, is een belangrijk voordeel van dit opslagmodel dat u in alle scenario's met slechts één kolom werkt. Hierdoor hoeft u niet de hele rij uit de database te lezen en hoeft u niet alle kolommen van deze rij te doorlopen. We zouden hier kunnen stoppen, maar...
U kunt in de war raken en nog een stapje verder gaan met het optimaliseren van de prestaties en het verminderen van I/O-bewerkingen bij het benaderen van de database. Wat als we de volledige relatie-informatie rechtstreeks in de rijsleutel zelf zouden opslaan? Dat wil zeggen, maak de sleutel samengesteld als userID.friendID? In dit geval hoeven we de kolommen van de rij niet eens te lezen (Optie 4(rij)):
Rijsleutel
Sprekers
Vasya.Petya
Petje: 1
Vasya Olya
Oud: 1
Vasya.Dasha
Dasja: 1
Petya Masha
Masja: 1
Petya.Vasya
Vasja: 1
Uiteraard zal de evaluatie van alle datamanipulatiescenario's in een dergelijke structuur, net als in de vorige versie, O(1) zijn. Het verschil met optie 3 zit uitsluitend in de efficiëntie van de invoer-/uitvoerbewerkingen in de database.
Nou, en de laatste "buiging". Het is duidelijk dat bij optie 4 de rijsleutel een variabele lengte heeft, wat mogelijk van invloed kan zijn op de prestaties (bedenk dat HBase gegevens opslaat als een set bytes en dat de rijen in de tabellen op sleutel worden gesorteerd). Bovendien hebben we een scheidingsteken dat in sommige gevallen gebruikt moet worden. Om deze invloed te elimineren, kunt u hashes van userID en friendID gebruiken. Aangezien beide hashes een constante lengte hebben, kunt u ze eenvoudig aan elkaar koppelen, zonder scheidingsteken. Dan zien de gegevens in de tabel er als volgt uit (Optie 5 (hash)):
Rijsleutel
Sprekers
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Petje: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
Oud: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
Dasja: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Masja: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Vasja: 1
Het is duidelijk dat de algoritmische complexiteit van het werken met een dergelijke structuur volgens de scenario's die we overwegen, dezelfde zal zijn als voor optie 4, dat wil zeggen O(1).
Laten we al onze schattingen van de rekenkundige complexiteit in één tabel plaatsen:
Een vriend toevoegen
Een vriend controleren
Een vriend verwijderen
Optie 1 (standaard)
O (n)
O (n)
O (n)
Optie 2 (aantal)
O (1)
O (n)
O (n)
Optie 3 (kolom)
O (1)
O (1)
O (1)
Optie 4 (rij)
O (1)
O (1)
O (1)
Optie 5 (hash)
O (1)
O (1)
O (1)
Zoals u kunt zien, lijken opties 3-5 het meest wenselijk en garanderen ze theoretisch gezien de uitvoering van alle noodzakelijke scenario's voor gegevensmanipulatie in constante tijd. In de omstandigheden van ons probleem is er geen expliciete vereiste om een lijst te verkrijgen van alle vrienden van de gebruiker, maar in echte projectactiviteiten zouden wij, als goede analisten, er goed aan doen om te “anticiperen” dat een dergelijke taak zich kan voordoen en “strohalmen neer te leggen”. Daarom heb ik sympathie voor optie 3. Maar het is goed mogelijk dat dit verzoek in een echt project al op een andere manier had kunnen worden opgelost. Zonder een algemeen beeld van de hele opgave is het dus beter om geen definitieve conclusies te trekken.
Het experiment voorbereiden
Ik wil de bovenstaande theoretische overwegingen in de praktijk testen – dat was het doel van het idee dat tijdens het lange weekend ontstond. Om dit te doen, is het noodzakelijk om de snelheid van onze “voorwaardelijke toepassing” te evalueren in alle beschreven scenario’s van het gebruik van de database, evenals de groei van deze tijd met de groei van de omvang van het sociale netwerk (n). De doelparameter die ons interesseert en die we tijdens het experiment zullen meten, is de tijd die de “voorwaardelijke toepassing” besteedt aan het uitvoeren van één “bedrijfsoperatie”. Met "zakelijke transactie" bedoelen we een van de volgende:
- Eén nieuwe vriend toevoegen
- Controleer of gebruiker A een vriend is van gebruiker B
- Eén vriend verwijderen
Rekening houdend met de in de initiële verklaring gespecificeerde vereisten, is het verificatiescenario als volgt:
- Gegevensregistratie. Genereer een willekeurig initieel netwerk van grootte n. Om het dichter bij de 'echte wereld' te laten lijken, is het aantal vrienden dat elke gebruiker heeft ook een willekeurige waarde. Meet de tijd die onze “voorwaardelijke toepassing” nodig heeft om alle gegenereerde gegevens naar HBase te schrijven. Deel vervolgens de resulterende tijd door het totale aantal toegevoegde vrienden. Dit geeft ons de gemiddelde tijd voor één "zakelijke operatie".
- Gegevens lezen. Maak voor elke gebruiker een lijst met 'persoonlijkheden' waarvoor u antwoord moet krijgen op de vraag of de gebruiker op hen is geabonneerd of niet. De lengte van de lijst is ongeveer gelijk aan het aantal vrienden van de gebruiker. Voor de helft van de aangevinkte vrienden moet het antwoord 'Ja' zijn, en voor de andere helft 'Nee'. De controle wordt zo uitgevoerd dat de antwoorden “Ja” en “Nee” afwisselend zijn (dat wil zeggen dat we in elk tweede geval alle kolommen van de rij voor optie 1 en 2 moeten doorlopen). De totale verificatietijd wordt vervolgens gedeeld door het aantal vrienden dat geverifieerd wordt. Zo krijgt u de gemiddelde tijd die nodig is om één onderwerp te verifiëren.
- Gegevens verwijderen. Alle vrienden van een gebruiker verwijderen. Bovendien is de volgorde van het verwijderen willekeurig (dat wil zeggen dat we de oorspronkelijke lijst die is gebruikt om de gegevens vast te leggen, ‘schudden’). De totale verificatietijd wordt vervolgens gedeeld door het aantal vrienden dat wordt verwijderd. Zo krijgt u de gemiddelde tijd per verificatie.
De scenario's moeten worden uitgevoerd voor elk van de vijf varianten van het datamodel en voor verschillende groottes van het sociale netwerk om te zien hoe de tijd verandert naarmate de tijd groeit. Binnen één n verbindingen in het netwerk en de lijst met te controleren gebruikers moet uiteraard voor alle 5 opties hetzelfde zijn.
Voor een beter begrip staat hieronder een voorbeeld van gegenereerde gegevens voor n= 5. De geschreven "generator" produceert drie ID-woordenboeken bij de uitvoer:
- de eerste is voor invoeging
- de tweede is voor controle
- de derde is voor verwijdering
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Zoals u kunt zien, zijn alle ID's groter dan 10 in het woordenboek voor verificatie precies die welke duidelijk een 'Onwaar'-antwoord opleveren. Het invoegen, controleren en verwijderen van 'vrienden' gebeurt in de exacte volgorde die in het woordenboek is aangegeven.
Het experiment werd uitgevoerd op een laptop die draaide op Windows 10waarbij HBase in één Docker-container draaide en Python met Jupyter Notebook in een andere. Docker kreeg 2 CPU-cores en 2 GB RAM toegewezen. Alle logica, inclusief de simulatie van de "dummy-applicatie" en het framework voor het genereren van testgegevens en het meten van de tijd, was geschreven in Python. De bibliotheek , om hashes (MD5) te berekenen voor optie 5 - hashlib
Rekening houdend met de rekenkracht van een bepaalde laptop werd experimenteel een lancering voor n = 10, 30, … geselecteerd. 170 – toen de totale looptijd van de volledige testcyclus (alle scenario’s voor alle opties voor alle n) nog min of meer redelijk was en in één theekransje kon worden afgerond (gemiddeld 15 minuten).
Hierbij moet wel de kanttekening worden gemaakt dat het bij dit experiment niet primair om absolute prestatiecijfers gaat. Zelfs een relatieve vergelijking van twee verschillende opties is mogelijk niet helemaal correct. Nu zijn we geïnteresseerd in de aard van de verandering in tijd afhankelijk van n, aangezien het, rekening houdend met de hierboven genoemde configuratie van de "testbank", erg moeilijk is om tijdschattingen te verkrijgen die "gewist" zijn van de invloed van willekeurige en andere factoren (en een dergelijke taak was niet ingesteld).
Het resultaat van het experiment
De eerste test is hoe de tijd die nodig is om de vriendenlijst in te vullen, verandert. Het resultaat ziet u in de onderstaande grafiek.
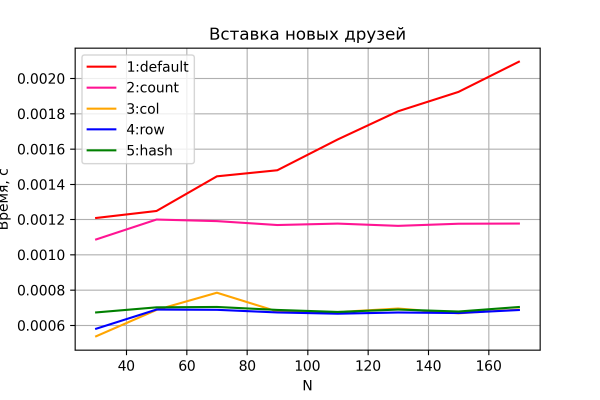
Van opties 3 t/m 5 wordt verwacht dat ze een vrijwel constante "bedrijfsvoeringstijd" laten zien die niet afhankelijk is van de groei van de netwerkomvang en dat er geen duidelijk verschil is in prestaties.
Optie 2 laat ook constante, maar iets slechtere prestaties zien, bijna exact 2 keer vergeleken met opties 3-5. En dat kan niet anders dan prettig zijn, want het komt overeen met de theorie: in deze versie is het aantal input-outputbewerkingen van/naar HBase precies 2 keer zo groot. Dit kan als indirect bewijs dienen dat onze testbank in principe een goede nauwkeurigheid levert.
Optie 1 zal naar verwachting ook het langzaamst zijn en laat een lineaire toename zien in de tijd die nodig is om één vriend toe te voegen, afhankelijk van de grootte van het netwerk.
Laten we nu eens kijken naar de resultaten van de tweede test.
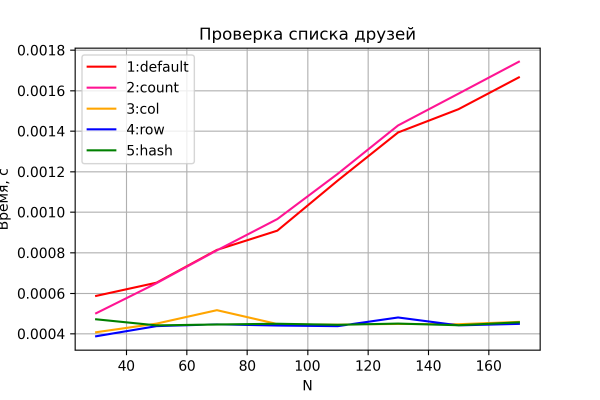
Opties 3-5 gedragen zich weer zoals verwacht: constante tijd, onafhankelijk van de netwerkgrootte. Opties 1 en 2 laten een lineaire groei van de tijd zien bij toenemende netwerkgrootte en vergelijkbare prestaties. Bovendien blijkt optie 2 iets langzamer te zijn – kennelijk vanwege de noodzaak om de extra kolom ‘aantal’ na te lezen en te verwerken, die duidelijker zichtbaar wordt naarmate n groeit. Ik zal echter nog steeds geen conclusies trekken, omdat de nauwkeurigheid van deze vergelijking relatief laag is. Bovendien veranderden deze verhoudingen (welke optie, 1 of 2, is sneller) van lancering tot lancering (terwijl de aard van de afhankelijkheid behouden bleef en er sprake was van een ‘nek-aan-nek-relatie’).
De laatste grafiek is het resultaat van de verwijderingstest.
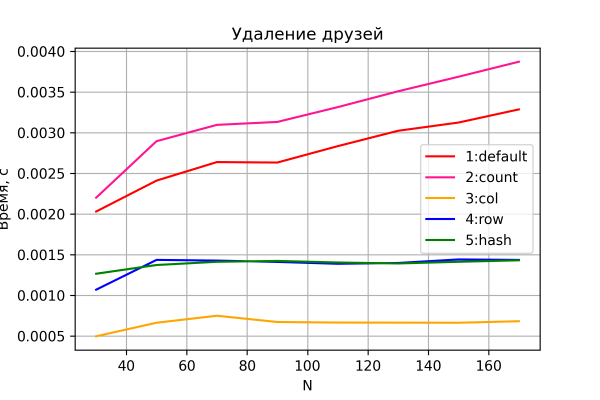
Ook hier geen verrassingen. Opties 3-5 voeren verwijdering in constante tijd uit.
Interessant is bovendien dat opties 4 en 5, in tegenstelling tot de vorige scenario's, merkbaar iets slechtere prestaties laten zien dan optie 3. Blijkbaar is de bewerking voor het verwijderen van rijen duurder dan de bewerking voor het verwijderen van kolommen, wat over het algemeen logisch is.
Opties 1 en 2 laten, zoals verwacht, een lineaire toename in de tijd zien. Tegelijkertijd is optie 2 consequent langzamer dan optie 1 – vanwege de extra invoer-/uitvoerbewerking om de telkolom te “bedienen”.
Algemene conclusies van het experiment:
- Opties 3-5 zijn efficiënter, omdat ze gebruikmaken van HBase; Bovendien verschillen hun prestaties constant van elkaar en zijn ze niet afhankelijk van de grootte van het netwerk.
- Er werd geen verschil vastgesteld tussen optie 4 en 5. Dit betekent echter niet dat optie 5 niet gebruikt zou moeten worden. Het is goed mogelijk dat het gebruikte experimentele scenario, rekening houdend met de prestatiekenmerken van de testbank, het niet mogelijk maakte om deze te identificeren.
- De aard van de toename van de tijd die nodig is om “zakelijke operaties” met data uit te voeren, bevestigde over het algemeen de eerder verkregen theoretische berekeningen voor alle opties.
epiloog
Deze ruwe experimenten moeten niet als absolute waarheid worden beschouwd. Er zijn veel factoren die niet in aanmerking zijn genomen en de resultaten hebben vertekend (deze schommelingen zijn vooral zichtbaar in de grafieken voor kleine netwerkgroottes). Denk bijvoorbeeld aan de snelheid van Thrift, dat door Happybase wordt gebruikt, de omvang en implementatiemethode van de logica die ik in Python heb geschreven (ik kan niet beweren dat de code optimaal is geschreven of effectief gebruikmaakt van alle componenten), mogelijk de cachingfuncties van HBase en achtergrondactiviteit. Windows 10 Op mijn laptop, enzovoort. Al met al kan worden geconcludeerd dat alle theoretische aannames experimenteel zijn bewezen. Of in ieder geval was het niet mogelijk om ze met zo'n frontale aanval te weerleggen.
Tot slot volgen hier enkele aanbevelingen voor iedereen die net begint met het ontwerpen van datamodellen in HBase: laat uw eerdere ervaring met het werken met relationele databases varen en onthoud de “geboden”:
- Bij het ontwerpen gaan we uit van de taak- en datamanipulatiepatronen, en niet van het onderwerpgebiedmodel
- Efficiënte toegang (zonder volledige tabelscan) - alleen via sleutel
- Denormalisatie
- Verschillende rijen kunnen verschillende kolommen bevatten.
- Dynamische samenstelling van kolommen
Bron: www.habr.com
