

In het artikel zal ik je vertellen hoe we het probleem van PostgreSQL-fouttolerantie hebben aangepakt, waarom het belangrijk voor ons werd en wat er uiteindelijk gebeurde.
We hebben een zeer geladen service: 2,5 miljoen gebruikers wereldwijd, 50+ actieve gebruikers elke dag. De servers staan in Amazone in één regio van Ierland: er zijn constant meer dan 100 verschillende servers in bedrijf, waarvan bijna 50 met databases.
De volledige backend is een grote monolithische stateful Java-applicatie die een constante websocketverbinding met de client onderhoudt. Wanneer meerdere gebruikers tegelijkertijd aan hetzelfde bord werken, zien ze allemaal de wijzigingen in realtime, omdat we elke wijziging naar de database schrijven. We hebben ongeveer 10 verzoeken per seconde aan onze databases. Bij piekbelasting in Redis schrijven we 80-100 verzoeken per seconde.
Waarom we zijn overgestapt van Redis naar PostgreSQL
Aanvankelijk werkte onze service met Redis, een key-value store die alle data in het RAM-geheugen opslaat. server.
Voordelen van Redis:
- Hoge reactiesnelheid, omdat alles wordt in het geheugen opgeslagen;
- Gemak van back-up en replicatie.
Nadelen van Redis voor ons:
- Er zijn geen echte transacties. We hebben geprobeerd ze te simuleren op het niveau van onze applicatie. Helaas werkte dit niet altijd goed en vereiste het schrijven van zeer complexe code.
- De hoeveelheid data wordt beperkt door de hoeveelheid geheugen. Naarmate de hoeveelheid gegevens toeneemt, zal het geheugen groeien en zullen we uiteindelijk de kenmerken van de geselecteerde instantie tegenkomen, waarvoor in AWS onze service moet worden gestopt om het type instantie te wijzigen.
- Het is noodzakelijk om constant een laag latentieniveau te handhaven, omdat. we hebben een zeer groot aantal aanvragen. Het optimale vertragingsniveau voor ons is 17-20 ms. Op een niveau van 30-40 ms krijgen we lange reacties op verzoeken van onze applicatie en verslechtering van de service. Helaas overkwam ons dit in september 2018, toen een van de instanties met Redis om de een of andere reden 2 keer meer latentie kreeg dan normaal. Om het probleem op te lossen, stopten we de service halverwege de dag voor ongepland onderhoud en vervingen we de problematische Redis-instantie.
- Het is gemakkelijk om gegevensinconsistentie te krijgen, zelfs met kleine fouten in de code, en vervolgens veel tijd te besteden aan het schrijven van code om deze gegevens te corrigeren.
We hielden rekening met de nadelen en realiseerden ons dat we moesten overstappen naar iets handigers, met normale transacties en minder afhankelijkheid van latentie. Onderzoek gedaan, veel opties geanalyseerd en gekozen voor PostgreSQL.
We zijn al 1,5 jaar bezig met een nieuwe database en hebben slechts een klein deel van de data verplaatst, dus nu werken we tegelijkertijd met Redis en PostgreSQL. Meer informatie over de stadia van het verplaatsen en schakelen van gegevens tussen databases is in geschreven het artikel van mijn collega.
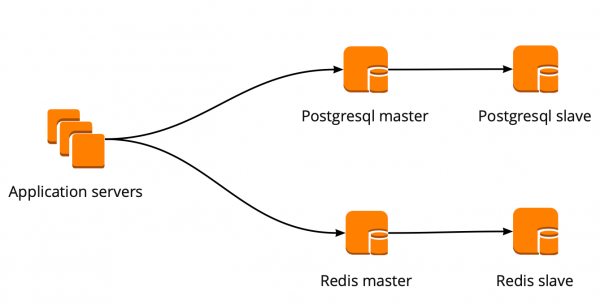
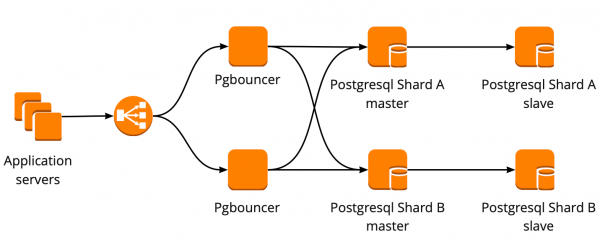
Toen we net begonnen te verhuizen, werkte onze applicatie rechtstreeks met de database en had toegang tot de master Redis en PostgreSQL. Het PostgreSQL-cluster bestond uit een master en een replica met asynchrone replicatie. Zo zag het databaseschema eruit:
PgBouncer implementeren
Terwijl we verhuisden, ontwikkelde het product zich ook: het aantal gebruikers en het aantal servers dat met PostgreSQL werkte, nam toe en we begonnen verbindingen te missen. PostgreSQL creëert een afzonderlijk proces voor elke verbinding en verbruikt bronnen. U kunt het aantal verbindingen tot een bepaald punt verhogen, anders bestaat de kans op suboptimale databaseprestaties. De ideale optie in zo'n situatie zou zijn om een verbindingsbeheerder te kiezen die voor de basis zal staan.
We hadden twee opties voor de verbindingsbeheerder: Pgpool en PgBouncer. Maar de eerste ondersteunt de transactionele manier van werken met de database niet, dus kozen we voor PgBouncer.
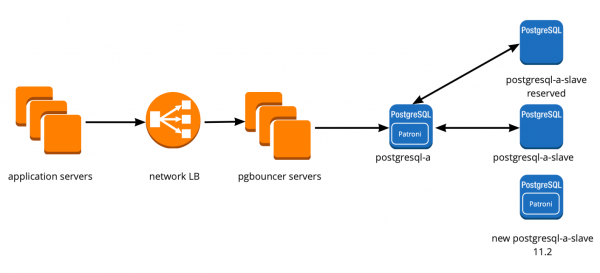
We hebben het volgende werkschema opgesteld: onze applicatie heeft toegang tot één PgBouncer, waarachter PostgreSQL-masters staan, en achter elke master bevindt zich één replica met asynchrone replicatie.
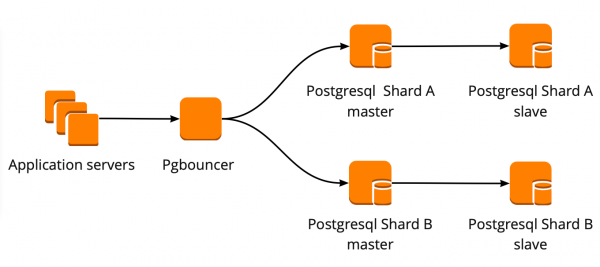
Tegelijkertijd konden we niet de volledige hoeveelheid gegevens in PostgreSQL opslaan en was de snelheid van het werken met de database belangrijk voor ons, dus begonnen we PostgreSQL op applicatieniveau te sharden. Het hierboven beschreven schema is hiervoor relatief handig: bij het toevoegen van een nieuwe PostgreSQL-shard volstaat het om de PgBouncer-configuratie bij te werken en de applicatie kan onmiddellijk met de nieuwe shard werken.
PgBouncer-failover
Dit schema werkte tot het moment waarop de enige PgBouncer-instantie stierf. We bevinden ons in AWS, waar alle instances draaien op hardware die periodiek uitvalt. In dergelijke gevallen gaat de instantie gewoon naar nieuwe hardware en werkt weer. Dit gebeurde met PgBouncer, maar het werd niet meer beschikbaar. Het gevolg van deze daling was de onbeschikbaarheid van onze dienst gedurende 25 minuten. AWS raadt aan om voor dergelijke situaties gebruik te maken van redundantie aan de gebruikerszijde, wat op dat moment in ons land nog niet was geïmplementeerd.
Daarna hebben we serieus nagedacht over de fouttolerantie van PgBouncer- en PostgreSQL-clusters, omdat een vergelijkbare situatie zich zou kunnen voordoen met elke instantie in ons AWS-account.
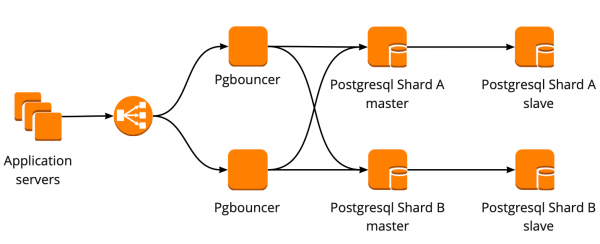
We hebben het PgBouncer-fouttolerantieschema als volgt opgebouwd: alle applicatieservers hebben toegang tot de Network Load Balancer, waarachter zich twee PgBouncers bevinden. Elke PgBouncer kijkt naar dezelfde PostgreSQL-master van elke shard. Als er opnieuw een AWS-instance crasht, wordt al het verkeer omgeleid via een andere PgBouncer. Network Load Balancer-failover wordt verzorgd door AWS.
Dit schema maakt het gemakkelijk om nieuwe PgBouncer-servers toe te voegen.
Maak een PostgreSQL-failovercluster
Bij het oplossen van dit probleem hebben we verschillende opties overwogen: zelfgeschreven failover, repmgr, AWS RDS, Patroni.
Zelfgeschreven scripts
Ze kunnen het werk van de master volgen en, als het mislukt, de replica naar de master promoveren en de PgBouncer-configuratie bijwerken.
De voordelen van deze aanpak zijn maximale eenvoud, omdat je zelf scripts schrijft en precies begrijpt hoe ze werken.
Tegens:
- De master is mogelijk niet overleden, maar er is mogelijk een netwerkfout opgetreden. Failover, zich hiervan niet bewust, promoveert de replica naar de master, terwijl de oude master blijft werken. Hierdoor krijgen we twee servers in de rol van master en weten we niet welke van hen de laatste up-to-date data heeft. Deze situatie wordt ook wel split-brain genoemd;
- We bleven achter zonder antwoord. In onze configuratie, de master en één replica, gaat de replica na het overschakelen naar de master en hebben we geen replica's meer, dus moeten we handmatig een nieuwe replica toevoegen;
- We hebben extra monitoring van de failover-operatie nodig, terwijl we 12 PostgreSQL-shards hebben, wat betekent dat we 12 clusters moeten monitoren. Met een toename van het aantal shards, moet u ook onthouden om de failover bij te werken.
Zelfgeschreven failover ziet er erg ingewikkeld uit en vereist niet-triviale ondersteuning. Met een enkel PostgreSQL-cluster zou dit de gemakkelijkste optie zijn, maar het schaalt niet, dus het is niet geschikt voor ons.
Repgr
Replication Manager voor PostgreSQL-clusters, waarmee de werking van een PostgreSQL-cluster kan worden beheerd. Tegelijkertijd heeft het geen automatische failover out of the box, dus voor werk moet je je eigen "wrapper" bovenop de voltooide oplossing schrijven. Alles kan dus nog ingewikkelder worden dan met zelfgeschreven scripts, dus we hebben Repmgr niet eens geprobeerd.
AWS-RDS
Ondersteunt alles wat we nodig hebben, weet back-ups te maken en onderhoudt een pool van verbindingen. Het heeft automatische omschakeling: wanneer de master sterft, wordt de replica de nieuwe master en verandert AWS het dns-record in de nieuwe master, terwijl de replica's zich in verschillende AZ's kunnen bevinden.
De nadelen zijn onder meer het ontbreken van fijne aanpassingen. Als voorbeeld van finetuning: onze instanties hebben beperkingen voor tcp-verbindingen, wat helaas niet kan in RDS:
net.ipv4.tcp_keepalive_time=10
net.ipv4.tcp_keepalive_intvl=1
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_retries2=3
Bovendien is AWS RDS bijna twee keer zo duur als de reguliere instantieprijs, wat de belangrijkste reden was om van deze oplossing af te zien.
patroon
Dit is een python-sjabloon voor het beheer van PostgreSQL met goede documentatie, automatische failover en broncode op github.
Voordelen van Patroni:
- Elke configuratieparameter wordt beschreven, het is duidelijk hoe het werkt;
- Automatische failover werkt out of the box;
- Geschreven in python, en aangezien we zelf veel in python schrijven, zal het voor ons gemakkelijker zijn om met problemen om te gaan en misschien zelfs de ontwikkeling van het project te helpen;
- Beheert PostgreSQL volledig, stelt u in staat om de configuratie op alle knooppunten van het cluster in één keer te wijzigen, en als het cluster opnieuw moet worden opgestart om de nieuwe configuratie toe te passen, dan kan dit opnieuw worden gedaan met Patroni.
Tegens:
- Het is niet duidelijk uit de documentatie hoe correct met PgBouncer te werken. Hoewel het moeilijk is om het een minpuntje te noemen, omdat het de taak van Patroni is om PostgreSQL te beheren, en hoe verbindingen met Patroni zullen verlopen, is al ons probleem;
- Er zijn weinig voorbeelden van implementatie van Patroni op grote volumes, terwijl er veel voorbeelden zijn van implementatie vanaf nul.
Als gevolg hiervan hebben we Patroni gekozen om een failover-cluster te maken.
Patroni-implementatieproces
Vóór Patroni hadden we 12 PostgreSQL-shards in een configuratie van één master en één replica met asynchrone replicatie. De applicatieservers hadden toegang tot de databases via de Network Load Balancer, waarachter zich twee instanties met PgBouncer bevonden, en daarachter alle PostgreSQL-servers.
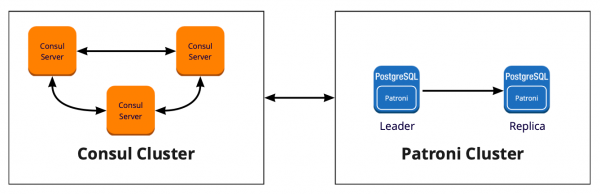
Om Patroni te implementeren, moesten we een gedistribueerde opslagclusterconfiguratie selecteren. Patroni werkt met gedistribueerde configuratieopslagsystemen zoals etcd, Zookeeper, Consul. We hebben net een volwaardig Consul-cluster op de markt, dat werkt in combinatie met Vault en we gebruiken het niet meer. Een goede reden om Consul te gaan gebruiken waarvoor het bedoeld is.
Hoe Patroni samenwerkt met Consul
We hebben een Consul-cluster, dat uit drie knooppunten bestaat, en een Patroni-cluster, dat uit een leider en een replica bestaat (in Patroni wordt de master de clusterleider genoemd en de slaven replica's). Elk exemplaar van het Patroni-cluster stuurt voortdurend informatie over de status van het cluster naar Consul. Daarom kunt u bij Consul altijd de huidige configuratie van het Patroni-cluster vinden en wie op dit moment de leider is.
Om Patroni met Consul te verbinden, volstaat het om de officiële documentatie te bestuderen, waarin staat dat u een host moet specificeren in het http- of https-formaat, afhankelijk van hoe we met Consul werken, en het verbindingsschema, optioneel:
host: the host:port for the Consul endpoint, in format: http(s)://host:port
scheme: (optional) http or https, defaults to httpHet lijkt eenvoudig, maar hier beginnen de valkuilen. Met Consul werken we via een beveiligde verbinding via https en onze verbindingsconfiguratie ziet er als volgt uit:
consul:
host: https://server.production.consul:8080
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Maar dat werkt niet. Bij het opstarten kan Patroni geen verbinding maken met Consul, omdat het toch via http probeert te gaan.
De broncode van Patroni hielp bij het oplossen van het probleem. Gelukkig is het in python geschreven. Het blijkt dat de hostparameter op geen enkele manier wordt geparseerd en dat het protocol in het schema moet worden gespecificeerd. Zo ziet het werkende configuratieblok voor het werken met Consul er voor ons uit:
consul:
host: server.production.consul:8080
scheme: https
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}consul-sjabloon
We hebben dus de opslag gekozen voor de configuratie. Nu moeten we begrijpen hoe PgBouncer van configuratie verandert wanneer de leider in het Patroni-cluster verandert. Er is geen antwoord op deze vraag in de documentatie, omdat. daar wordt het werken met PgBouncer in principe niet beschreven.
Op zoek naar een oplossing vonden we een artikel (ik weet helaas de titel niet meer) waarin stond dat Сonsul-template veel heeft geholpen bij het koppelen van PgBouncer en Patroni. Dit was voor ons aanleiding om te onderzoeken hoe Consul-template werkt.
Het bleek dat Consul-template constant de configuratie van het PostgreSQL-cluster in Consul monitort. Wanneer de leider verandert, wordt de PgBouncer-configuratie bijgewerkt en wordt een opdracht verzonden om deze opnieuw te laden.
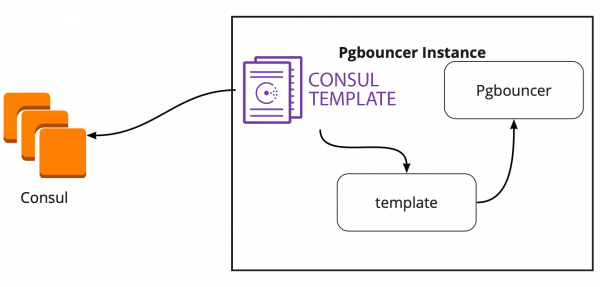
Een groot pluspunt van een sjabloon is dat het wordt opgeslagen als code, dus bij het toevoegen van een nieuwe shard volstaat het om een nieuwe commit te maken en de sjabloon automatisch bij te werken, waarbij het Infrastructuur als code-principe wordt ondersteund.
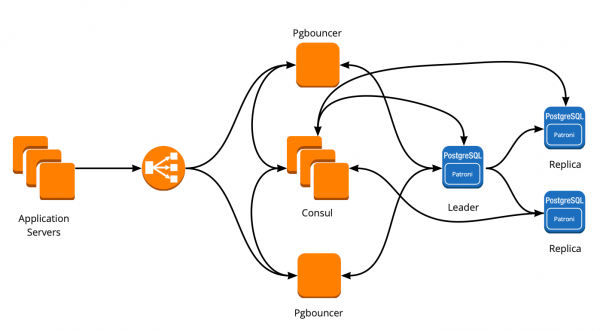
Nieuwe architectuur met Patroni
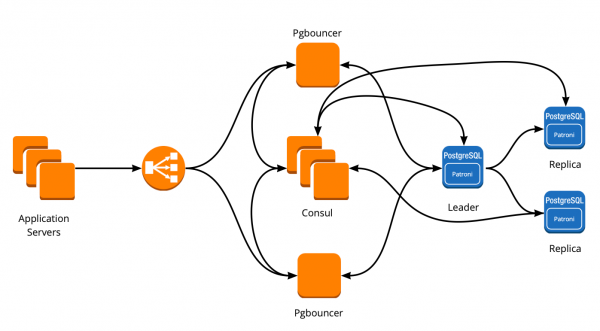
Als resultaat kregen we het volgende werkschema:
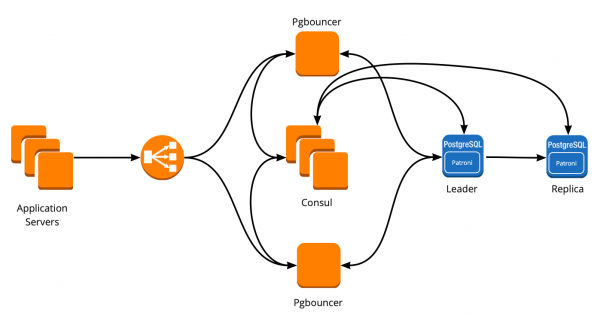
Alle applicatieservers hebben toegang tot de balancer → er zitten twee instanties van PgBouncer achter → op elke instantie wordt Consul-template gelanceerd, die de status van elk Patroni-cluster bewaakt en de relevantie van de PgBouncer-configuratie bewaakt, die verzoeken naar de huidige leider stuurt van elk cluster.
Handmatig testen
We hebben dit schema uitgevoerd voordat we het op een kleine testomgeving lanceerden en de werking van automatisch schakelen gecontroleerd. Ze openden het bord, verplaatsten de sticker en op dat moment 'doodden' ze de leider van de cluster. In AWS is dit net zo eenvoudig als het afsluiten van de instantie via de console.
De sticker keerde binnen 10-20 seconden terug en begon toen weer normaal te bewegen. Dit betekent dat het Patroni-cluster correct werkte: het veranderde de leider, stuurde de informatie naar Сonsul en Сonsul-template pikte deze informatie onmiddellijk op, verving de PgBouncer-configuratie en stuurde het commando om opnieuw te laden.
Hoe overleef je onder hoge belasting en houd je de downtime minimaal?
Alles werkt perfect! Maar er zijn nieuwe vragen: hoe werkt het onder hoge belasting? Hoe snel en veilig alles in productie uitrollen?
De testomgeving waarop we loadtesten uitvoeren, helpt ons bij het beantwoorden van de eerste vraag. Het is qua architectuur volledig identiek aan de productie en heeft testdata gegenereerd die qua volume ongeveer gelijk is aan de productie. We besluiten om tijdens de test een van de PostgreSQL-masters gewoon te "doden" en te kijken wat er gebeurt. Maar daarvoor is het belangrijk om het automatisch rollen te controleren, omdat we in deze omgeving verschillende PostgreSQL-shards hebben, dus we krijgen uitstekende tests van configuratiescripts vóór productie.
Beide taken zien er ambitieus uit, maar we hebben PostgreSQL 9.6. Kunnen we meteen upgraden naar 11.2?
We besluiten het in 2 stappen te doen: eerst upgraden naar 11.2, dan Patroni lanceren.
PostgreSQL-update
Gebruik de optie om de PostgreSQL-versie snel bij te werken -k, waarin harde koppelingen op schijf worden gemaakt en het niet nodig is om uw gegevens te kopiëren. Op basis van 300-400 GB duurt de update 1 seconde.
We hebben veel scherven, dus de update moet automatisch worden uitgevoerd. Om dit te doen, hebben we een Ansible-playbook geschreven dat het hele updateproces voor ons afhandelt:
/usr/lib/postgresql/11/bin/pg_upgrade
<b>--link </b>
--old-datadir='' --new-datadir=''
--old-bindir='' --new-bindir=''
--old-options=' -c config_file='
--new-options=' -c config_file='Het is belangrijk om hier op te merken dat voordat u de upgrade start, u deze moet uitvoeren met de parameter --rekeningom er zeker van te zijn dat u kunt upgraden. Ons script zorgt ook voor de vervanging van configuraties voor de duur van de upgrade. Ons script was in 30 seconden voltooid, wat een uitstekend resultaat is.
Lanceer Patroni
Om het tweede probleem op te lossen, hoeft u alleen maar naar de Patroni-configuratie te kijken. De officiële repository heeft een voorbeeldconfiguratie met initdb, die verantwoordelijk is voor het initialiseren van een nieuwe database wanneer u Patroni voor het eerst start. Maar aangezien we al een kant-en-klare database hebben, hebben we deze sectie gewoon uit de configuratie verwijderd.
Toen we begonnen Patroni op een reeds bestaand PostgreSQL-cluster te installeren en uit te voeren, liepen we tegen een nieuw probleem aan: beide servers begonnen als leider. Patroni weet niets over de vroege status van het cluster en probeert beide servers te starten als twee afzonderlijke clusters met dezelfde naam. Om dit probleem op te lossen, moet u de map met gegevens op de slaaf verwijderen:
rm -rf /var/lib/postgresql/Dit hoeft alleen op de slave te worden gedaan!
Wanneer een schone replica is aangesloten, maakt Patroni een basebackup-leider en herstelt deze naar de replica, en haalt vervolgens de huidige status in volgens de muurlogboeken.
Een andere moeilijkheid die we tegenkwamen, is dat alle PostgreSQL-clusters standaard main worden genoemd. Wanneer elk cluster niets over het andere weet, is dit normaal. Maar wanneer je Patroni wilt gebruiken, dan moeten alle clusters een unieke naam hebben. De oplossing is om de clusternaam in de PostgreSQL-configuratie te wijzigen.
belasting testen
We hebben een test gelanceerd die de gebruikerservaring op boards simuleert. Toen de belasting onze gemiddelde dagelijkse waarde bereikte, herhaalden we precies dezelfde test, we schakelden één instantie uit met de PostgreSQL-leider. De automatische failover werkte zoals we hadden verwacht: Patroni veranderde de leider, Consul-template werkte de PgBouncer-configuratie bij en stuurde een commando om opnieuw te laden. Volgens onze grafieken in Grafana was het duidelijk dat er vertragingen van 20-30 seconden zijn en een klein aantal fouten van de servers die verband houden met de verbinding met de database. Dit is een normale situatie, dergelijke waarden zijn acceptabel voor onze failover en zijn zeker beter dan de downtime van de service.
Patroni in productie nemen
Hierdoor zijn we tot het volgende plan gekomen:
- Implementeer Consul-template op PgBouncer-servers en start;
- PostgreSQL-updates naar versie 11.2;
- Wijzig de naam van het cluster;
- Het Patroni-cluster starten.
Tegelijkertijd stelt ons schema ons in staat om het eerste punt bijna op elk moment te maken, we kunnen elke PgBouncer beurtelings van het werk verwijderen en er consul-template op inzetten en uitvoeren. Dus dat deden we.
Voor een snelle implementatie hebben we Ansible gebruikt, omdat we alle playbooks al in een testomgeving hebben getest, en de uitvoeringstijd van het volledige script was 1,5 tot 2 minuten voor elke shard. We zouden alles achtereenvolgens naar elke shard kunnen uitrollen zonder onze service te stoppen, maar we zouden elke PostgreSQL enkele minuten moeten uitschakelen. In dit geval kunnen gebruikers wiens gegevens zich op deze scherf bevinden op dit moment niet volledig werken, en dit is onaanvaardbaar voor ons.
De uitweg uit deze situatie was het geplande onderhoud, dat elke 3 maanden plaatsvindt. Dit is een venster voor gepland werk, wanneer we onze service volledig afsluiten en onze database-instanties upgraden. Er was nog een week te gaan tot het volgende venster en we besloten om gewoon af te wachten en ons verder voor te bereiden. Tijdens de wachttijd hebben we onszelf extra beveiligd: voor elke PostgreSQL-shard hebben we een reservereplica opgehaald voor het geval de laatste gegevens niet konden worden bewaard, en een nieuwe instantie toegevoegd voor elke shard, die een nieuwe replica zou moeten worden in het Patroni-cluster, om geen opdracht uit te voeren om gegevens te verwijderen. Dit alles hielp om het risico op fouten te minimaliseren.
We hebben onze service opnieuw opgestart, alles werkte zoals het hoort, gebruikers bleven werken, maar op de grafieken zagen we een abnormaal hoge belasting van de Consul-servers.
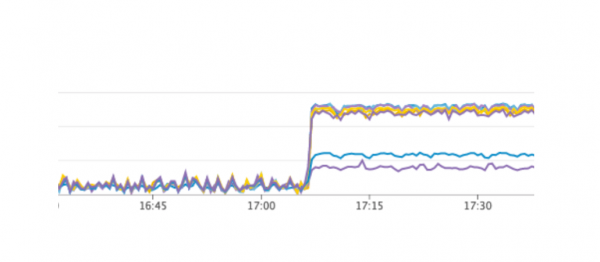
Waarom zagen we dit niet in de testomgeving? Dit probleem illustreert heel goed dat het noodzakelijk is om het Infrastructuur als code principe te volgen en de gehele infrastructuur te verfijnen, van testomgevingen tot productie. Anders is het heel gemakkelijk om het probleem te krijgen dat we hebben. Wat is er gebeurd? Consul verscheen voor het eerst in productie en vervolgens in testomgevingen, met als resultaat dat de versie van Consul in testomgevingen hoger was dan in productie. Slechts in een van de releases werd een CPU-lek opgelost bij het werken met consul-template. Daarom hebben we Consul gewoon geüpdatet, waarmee het probleem is opgelost.
Herstart Patroni-cluster
We kregen echter een nieuw probleem, dat we niet eens vermoedden. Bij het updaten van Consul verwijderen we eenvoudigweg het Consul-knooppunt uit het cluster met behulp van de opdracht consul leave → Patroni maakt verbinding met een andere Consul-server → alles werkt. Maar toen we de laatste instantie van het Consul-cluster bereikten en het consul leave-commando ernaar stuurden, startten alle Patroni-clusters gewoon opnieuw op en in de logboeken zagen we de volgende fout:
ERROR: get_cluster
Traceback (most recent call last):
...
RetryFailedError: 'Exceeded retry deadline'
ERROR: Error communicating with DCS
<b>LOG: database system is shut down</b>Het Patroni-cluster kon geen informatie over zijn cluster ophalen en werd opnieuw opgestart.
Om een oplossing te vinden, hebben we contact opgenomen met de Patroni-auteurs via een probleem op github. Ze stelden verbeteringen voor aan onze configuratiebestanden:
consul:
consul.checks: []
bootstrap:
dcs:
retry_timeout: 8We hebben het probleem kunnen repliceren in een testomgeving en deze opties daar getest, maar helaas werkten ze niet.
Het probleem is nog steeds niet opgelost. We zijn van plan de volgende oplossingen te proberen:
- Gebruik Consul-agent op elke Patroni-clusterinstantie;
- Los het probleem op in de code.
We begrijpen waar de fout is opgetreden: het probleem is waarschijnlijk het gebruik van de standaardtime-out, die niet wordt opgeheven via het configuratiebestand. Wanneer de laatste Consul-server uit het cluster wordt verwijderd, blijft het hele Consul-cluster langer dan een seconde hangen, hierdoor kan Patroni de status van het cluster niet achterhalen en start het hele cluster volledig opnieuw op.
Gelukkig zijn we geen fouten meer tegengekomen.
Resultaten van het gebruik van Patroni
Na de succesvolle lancering van Patroni hebben we in elk cluster een extra replica toegevoegd. Nu is er in elk cluster een schijn van een quorum: één leider en twee replica's, voor het vangnet in het geval van split-brain bij het wisselen.
Patroni werkt al meer dan drie maanden aan de productie. Gedurende deze tijd heeft hij ons al weten te helpen. Onlangs stierf de leider van een van de clusters in AWS, automatische failover werkte en gebruikers bleven werken. Patroni vervulde zijn hoofdtaak.
Een kleine samenvatting van het gebruik van Patroni:
- Gemak van configuratiewijzigingen. Het is voldoende om de configuratie op één instantie te wijzigen en deze wordt naar het hele cluster getrokken. Als opnieuw opstarten nodig is om de nieuwe configuratie toe te passen, zal Patroni u dit laten weten. Patroni kan de hele cluster herstarten met een enkele opdracht, wat ook erg handig is.
- Automatische failover werkt en heeft ons al kunnen helpen.
- PostgreSQL-update zonder downtime van applicaties. U moet eerst de replica's bijwerken naar de nieuwe versie, vervolgens de leider in het Patroni-cluster wijzigen en de oude leider bijwerken. In dit geval vindt het noodzakelijke testen van automatische failover plaats.
Bron: www.habr.com
