


Het hoofddoel van Patroni is om hoge beschikbaarheid voor PostgreSQL te bieden. Maar Patroni is slechts een sjabloon, geen kant-en-klare tool (wat in principe wel in de documentatie staat). Als je Patroni in een testlab installeert, zie je meteen hoe geweldig het is en hoe makkelijk het onze pogingen om het cluster te doorbreken afhandelt. In de praktijk, in een productieomgeving, gebeuren de zaken echter niet altijd zo mooi en elegant als in een testlab.

Ik wil je graag wat over mezelf vertellen. Ik begon als systeembeheerder. Werkte in webontwikkeling. Ik werk sinds 2014 bij Data Egret. Het bedrijf houdt zich bezig met consultancy op het gebied van Postgres. Omdat we specifiek met Postgres werken en dagelijks met Postgres werken, beschikken we over specifieke expertise op het gebied van de exploitatie.
En eind 2018 zijn we Patroni langzaam gaan gebruiken. En er is een bepaalde ervaring opgedaan. Op de een of andere manier hebben we het gediagnosticeerd, aangepast en onze beste werkwijzen bepaald. En in dit rapport wil ik daarover vertellen.
Naast PostgreSQL vind ik het volgende ook leuk LinuxIk vind het heerlijk om ermee te experimenteren en dingen te ontdekken, en ik ben dol op het bouwen van kernels. Ik ben gek op virtualisatie, containers, Docker en Kubernetes. Ik ben hierin geïnteresseerd omdat mijn oude beheerdersgewoonten me weer parten spelen. Ik ben dol op het testen van monitoring. Ik houd ook van alles wat met PostgreSQL te maken heeft op het gebied van beheer, zoals replicatie en back-ups. En in mijn vrije tijd programmeer ik in Go. Ik ben geen software engineer, ik programmeer gewoon in Go voor mezelf. En ik geniet ervan.

- Ik denk dat velen van jullie weten dat Postgres niet standaard over HA (High Availability) beschikt. Om HA te krijgen, moet je iets installeren, configureren, er moeite in steken en het krijgen.
- Er zijn verschillende tools en Patroni is er één van die HA heel goed en cool oplost. Maar door alles in een testlab te zetten en uit te voeren, kunnen we zien dat het allemaal werkt. We kunnen een aantal problemen reproduceren en bekijken hoe Patroni die aanpakt. En we zullen zien dat het allemaal perfect werkt.
- Maar in de praktijk liepen we tegen andere problemen aan. En ik zal over deze problemen praten.
- Ik zal je vertellen hoe we het hebben gediagnosticeerd, welke aanpassingen we hebben gedaan en of het ons geholpen heeft of niet.

- Ik ga je niet vertellen hoe je Patroni moet installeren, want dat kun je zelf op internet opzoeken. Je kunt de configuratiebestanden bekijken om te zien hoe het allemaal begint en hoe het geconfigureerd is. U kunt de schema's en architecturen begrijpen door er informatie over te zoeken op internet.
- Ik zal niet over de ervaringen van anderen praten. Ik wil alleen vertellen over de problemen die wij tegenkwamen.
- En ik zal het niet hebben over de problemen die buiten Patroni en PostgreSQL vallen. Als er bijvoorbeeld problemen zijn met de balans, bijvoorbeeld als onze cluster instort, zal ik er niet over praten.

En nog een kleine waarschuwing voordat we met ons verslag beginnen.
Al deze problemen die we tegenkwamen, hadden we in de eerste 6-7-8 maanden van de exploitatie. In de loop van de tijd kwamen we tot onze eigen interne best practices. En onze problemen verdwenen. Daarom werd het rapport zo’n zes maanden geleden aangekondigd, toen het nog allemaal vers in mijn geheugen zat en ik het mij nog perfect kon herinneren.
Terwijl ik het rapport voorbereidde, haalde ik al oude autopsierapporten tevoorschijn en bestudeerde ik de logboeken. Bovendien kan het zijn dat sommige details zijn vergeten, of dat sommige details niet volledig zijn onderzocht tijdens de analyse van de problemen. Hierdoor lijkt het soms alsof de problemen niet volledig zijn overwogen, of dat er sprake is van een gebrek aan informatie. En daarom vraag ik u om mij te vergeven voor dit moment.

Wat is Patroni?
- Dit is een sjabloon voor het bouwen van HA. Dit staat in de documentatie. En vanuit mijn standpunt is dit een zeer juiste verduidelijking. Patroni is geen wondermiddel dat al je problemen oplost. Je moet er zelf wat moeite voor doen om het te laten werken en nuttig te maken.
- Dit is een agent-service die op elke service met een database wordt geïnstalleerd en die een soort init-systeem is voor uw Postgres. Het start Postgres, stopt het, start het opnieuw, wijzigt de configuratie en verandert de topologie van uw cluster.
- Om de status van het cluster, de huidige weergave ervan en hoe het eruitziet op te slaan, is dus een soort opslag nodig. Vanuit dit oogpunt ging Patroni over tot het opslaan van de toestand in een extern systeem. Het is een gedistribueerd configuratieopslagsysteem. Het zou Etcd, Consul, ZooKeeper of Kubernetes' Etcd kunnen zijn, kortom, een van deze opties.
- Eén van de functies van Patroni is dat u autofileover standaard krijgt, maar dat u het pas krijgt nadat u het hebt geconfigureerd. Als we Repmgr ter vergelijking nemen, is de bestandsbeheerder erbij inbegrepen. Met Repmgr krijgen we omschakeling, maar als we autofileover willen, moeten we dit extra configureren. Patroni beschikt standaard over autofileover.
- En er zijn nog veel meer dingen. Bijvoorbeeld configuratieonderhoud, het toevoegen van nieuwe replica's, back-ups, etc. Maar dit valt buiten het bestek van dit rapport, ik ga hier niet op in.

Kort samengevat is de hoofdtaak van Patroni om autofileover goed en betrouwbaar uit te voeren, zodat ons cluster operationeel blijft en de toepassing geen wijzigingen in de clustertopologie opmerkt.

Maar wanneer we Patroni gaan gebruiken, wordt ons systeem iets ingewikkelder. Als we al eerder Postgres hadden, dan krijgen we bij gebruik van Patroni Patroni zelf en DCS, waar de status wordt opgeslagen. En dit moet allemaal op de een of andere manier werken. Wat kan er dan kapot gaan?
Het kan kapot gaan:
- Postgres kan kapot gaan. Het kan een origineel of een replica zijn, één van de twee kan kapotgaan.
- De Patroni zelf kan kapot gaan.
- DCS, waar de status wordt opgeslagen, kan kapot gaan.
- En het netwerk kan kapot gaan.
Ik zal al deze punten in het rapport bespreken.

Ik bekijk de zaken op volgorde van complexiteit, en niet vanuit het oogpunt dat de zaak meerdere componenten beïnvloedt. En vanuit het standpunt van subjectieve gevoelens was deze zaak moeilijk voor mij, het was moeilijk om uit elkaar te halen... en omgekeerd waren sommige zaken licht en gemakkelijk uit elkaar te halen.

En het eerste geval is het eenvoudigst. Dit is het geval toen we een databasecluster namen en onze DCS-opslag op hetzelfde cluster implementeerden. Dit is de meest voorkomende fout. Dit is een fout in het architectuurontwerp, d.w.z. het combineren van verschillende componenten op één plek.
Er is dus iets misgegaan. Laten we uitzoeken wat er is gebeurd.

En hier zijn we geïnteresseerd in het moment waarop de filer plaatsvond. Dat wil zeggen dat we geïnteresseerd zijn in het moment waarop de verandering in de toestand van de cluster plaatsvond.
Maar het indienen gebeurt niet altijd onmiddellijk, dat wil zeggen dat het niet een bepaalde tijd duurt, het kan lang duren. Het kan langdurig zijn.
Er is dus sprake van een begintijd en een eindtijd, het is dus een doorlopende gebeurtenis. En we verdelen alle gebeurtenissen in drie intervallen: we hebben tijd vóór het filter, tijdens het filter en ná het filter. Dat wil zeggen dat we alle gebeurtenissen in deze tijdlijn in ogenschouw nemen.

En het eerste wat we doen als er een filer optreedt, is zoeken naar de reden: wat is er gebeurd, wat heeft geleid tot de filer?
Als we naar de logs kijken, zien we dat dit klassieke Patroni-logs zijn. Daarin vertelt hij ons dat de server een master is geworden en dat de rol van master is overgedragen aan dit knooppunt. Hier is het gemarkeerd.

Vervolgens moeten we begrijpen waarom het bestand is verplaatst, dat wil zeggen, welke gebeurtenissen hebben ervoor gezorgd dat de masterrol van het ene knooppunt naar het andere is verplaatst. En in dit geval is alles eenvoudig. Er is een fout opgetreden bij de interactie met het opslagsysteem. De meester besefte dat hij niet met DCS kon werken, er was namelijk een probleem met de interactie. En hij zegt dat hij niet langer meester kan zijn en neemt ontslag. Deze zin "degraded self" zegt precies dat.

Als we kijken naar de gebeurtenissen die aan de inzending voorafgingen, kunnen we daarin de oorzaken vinden die een probleem vormden voor de voortzetting van het werk van de meester.
Als we de Patroni-logs bekijken, zien we dat er veel fouten en time-outs voorkomen, d.w.z. dat de Patroni-agent niet met DCS kan werken. In dit geval is dat een Consul-agent, waarmee de communicatie via poort 8500 verloopt.
Het probleem hier is dat Patroni en de database op dezelfde host draaien. Ook de Consul-servers draaiden op diezelfde host. Door de server te belasten, hebben we problemen veroorzaakt voor servers Consul. Ze konden niet normaal met elkaar communiceren.

Na enige tijd, toen de belasting afnam, kon onze Patroni weer communiceren met de agenten. De normale werkzaamheden zijn hervat. En dezelfde Pgdb-2 server werd opnieuw de master. Dat wil zeggen dat er een kleine omkering plaatsvond, waarbij de knoop zijn macht als meester afstond en deze vervolgens weer op zich nam, dat wil zeggen dat alles weer werd zoals het was.

En dat kan worden beschouwd als vals alarm, maar het kan ook worden beschouwd als het feit dat Patroni alles goed doet. Dat wil zeggen dat hij besefte dat hij de toestand van de cluster niet kon handhaven en hij ontnam hem zijn bevoegdheden.
En hier ontstond het probleem, omdat de Consul-servers zich op dezelfde hardware bevinden als de databases. Elke belasting, of het nu de belasting van schijven of processoren betreft, heeft invloed op de interactie met het Consul-cluster.

Wij hebben besloten dat dit niet samen kon gaan, we hebben een apart cluster voor Consul ingericht. En Patroni werkte al met een aparte Consul, dat wil zeggen, er was een apart Postgres-cluster, een apart Consul-cluster. Dit zijn de basisinstructies voor het verdelen en opslaan van al deze spullen, zodat ze niet door elkaar heen hoeven te leven.
Optioneel kunt u de parameters ttl, loop_wait en retry_timeout aanpassen, d.w.z. proberen deze kortdurende piekbelasting te overleven door deze parameters te verhogen. Maar dit is niet de meest geschikte optie, omdat de belasting langdurig kan zijn. En we zullen eenvoudigweg verder gaan dan de grenzen van deze parameters. En dat helpt misschien helemaal niet.
Het eerste probleem is, zoals u begrijpt, eenvoudig. We hebben DCS samen met de basis in elkaar gezet en kwamen op een probleem uit.

Het tweede probleem lijkt op het eerste. Een vergelijkbare situatie doet zich voor in de zin dat we opnieuw problemen ondervinden bij de interactie met het DCS-systeem.

Als we de logs bekijken, zien we dat er opnieuw een communicatiefout is opgetreden. En Patroni zegt dat ik niet met DCS kan communiceren, dus de huidige master gaat in de replicamodus.
De oude meester wordt een replica, hier werkt Patroni zoals het hoort. Vervolgens wordt pg_rewind uitgevoerd om het transactielogboek terug te draaien en vervolgens verbinding te maken met de nieuwe master, om vervolgens de verbinding met de nieuwe master tot stand te brengen. Hier functioneert Patroni zoals het hoort.

Hier moeten we de plaats vinden die voorafging aan de filer, dat wil zeggen de fouten die ervoor zorgden dat de filer optrad. En in dat opzicht is het heel handig om met Patroni-logs te werken. Hij schrijft dezelfde berichten met bepaalde tussenpozen. Als we snel door deze logs scrollen, zien we dat er wijzigingen in de logs zijn aangebracht. Dat betekent dat er problemen zijn ontstaan. We gaan snel terug naar deze plek en kijken wat er gebeurt.
Normaal gesproken zien de logs er ongeveer zo uit. De eigenaar van het slot wordt gecontroleerd. En als de eigenaar bijvoorbeeld verandert, dan kunnen er gebeurtenissen plaatsvinden waarop Patroni moet reageren. Maar in dit geval is alles prima voor ons. Wij zoeken naar de plek waar de fouten begonnen.

En als we naar de plek scrollen waar de fouten begonnen te verschijnen, zien we dat er een autofileover was. En omdat onze fouten verband hielden met de interactie met DCS en we in ons geval Consul gebruikten, keken we ook naar de Consul-logs om te zien wat daar gebeurde.
Nadat we de tijd van de indieners globaal hebben vergeleken met de tijd in de Consul-logboeken, zien we dat onze buren in het Consul-cluster zijn gaan twijfelen aan het bestaan van andere Consul-clusterdeelnemers.

En als je kijkt naar de logs van andere Consul-agenten, zie je ook dat daar een soort netwerkstoring plaatsvindt. En alle deelnemers van het Consul-cluster twijfelen aan elkaars bestaan. En dat was de aanleiding voor de indiener.
Als je kijkt naar wat er gebeurde vóór deze fouten, dan zie je dat er allerlei fouten waren, bijvoorbeeld een deadline of een mislukte RPC-procedure. Er is duidelijk sprake van een probleem in de interactie tussen de deelnemers van het Consul-cluster.

De eenvoudigste oplossing is om het netwerk te repareren. Maar ik heb gemakkelijk praten vanaf het podium. Maar de omstandigheden zijn zodanig dat de klant het zich niet altijd kan veroorloven om het netwerk te repareren. Het kan zijn dat hij in het distributiecentrum woont en niet in staat is het netwerk te repareren of de apparatuur te beïnvloeden. Daarom zijn er andere opties nodig.

Er zijn opties:
- De eenvoudigste optie, die naar mijn mening ook in de documentatie staat, is om de Consul-controles uit te schakelen, d.w.z. gewoon een lege array door te geven. En we vertellen de consulaire agent dat hij geen cheques moet gebruiken. Met deze controles kunnen we de netwerkstormen negeren en de filer niet starten.
- Een andere optie is om raft_multiplier opnieuw te controleren. Dit is een parameter van de Consul-server zelf. Standaard staat deze op 5. Deze waarde wordt aanbevolen in de documentatie voor staging-omgevingen. Dit heeft in principe invloed op de frequentie van de berichtenuitwisseling tussen deelnemers aan het Consul-netwerk. Deze parameter heeft in essentie invloed op de snelheid van de servicecommunicatie tussen deelnemers aan het Consul-cluster. En voor de productieomgeving wordt al aanbevolen om dit te verlagen, zodat knooppunten vaker berichten uitwisselen.
- Een andere optie die we zijn gaan gebruiken, is het verhogen van de prioriteit van Consul-processen boven andere processen voor de procesplanner van het besturingssysteem. Er bestaat zo'n parameter "nice", die de prioriteit van processen bepaalt waarmee rekening wordt gehouden door de OS-scheduler tijdens het plannen. We hebben ook de nice-waarde voor Consul-agenten verlaagd, dat wil zeggen de prioriteit verhoogd, zodat het besturingssysteem Consul-processen meer tijd geeft om te werken en hun code uit te voeren. In ons geval was het probleem hiermee opgelost.
- Een andere optie is om geen Consul te gebruiken. Ik heb een vriend die een groot voorstander is van Etcd. En we discussiëren regelmatig met hem over wie beter is, Etcd of Consul. Maar wat betreft wat beter is, zijn we het er over het algemeen over eens dat Consul een agent heeft die op elk knooppunt met een database moet draaien. Dat wil zeggen dat de interactie tussen Patroni en het Consul-cluster via deze agent plaatsvindt. En dit middel wordt een knelpunt. Als er iets met de agent gebeurt, kan Patroni niet meer met het Consul-cluster werken. En dat is een probleem. Er is geen agent in het Etcd-plan. Patroni kan direct met de lijst van Etcd-servers werken en er al mee communiceren. Als u Etcd binnen uw bedrijf gebruikt, is Etcd waarschijnlijk een betere keuze dan Consul. Maar wij, als klant, worden altijd beperkt door wat de klant heeft gekozen en gebruikt. En in de meeste gevallen hebben al onze klanten een consul.
- En als laatste moeten de parameterwaarden nog eens bekeken worden. We kunnen deze parameters naar een hogere waarde verhogen in de hoop dat onze netwerkproblemen op de korte termijn van korte duur zullen zijn en niet buiten het bereik van deze parameters zullen vallen. Op deze manier kunnen we de agressiviteit van Patroni bij het uitvoeren van autofileover verminderen als er netwerkproblemen optreden.
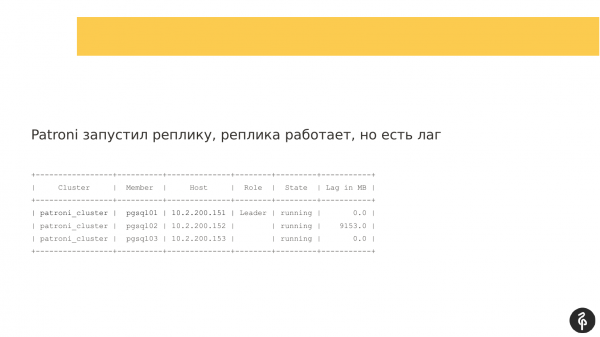
Ik denk dat veel gebruikers van Patroni bekend zijn met dit commando.
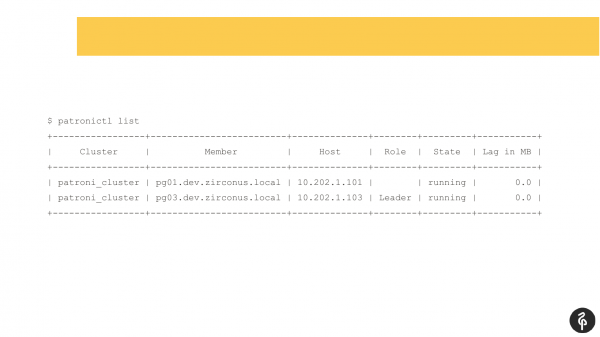
Met deze opdracht wordt de huidige status van het cluster weergegeven. En op het eerste gezicht lijkt dit plaatje normaal. We hebben een master, we hebben een replica, en er is geen replicatievertraging. Maar dit beeld is normaal totdat we weten dat er drie knooppunten in dit cluster moeten zijn, en niet twee.

Er vond vervolgens een autofileover plaats. En na deze autofileover verdween onze replica. We moeten uitzoeken waarom ze verdween, haar terughalen en haar restaureren. En we gaan nog eens naar de logs om te zien waarom er een autofileover was.

In dit geval werd de tweede replica de master. Hier is alles prima.

En we moeten kijken naar de replica die eraf is gevallen en die niet in de cluster zit. We openen de Patroni-logs en zien dat er een probleem is in de pg_rewind-fase tijdens het verbinding maken met het cluster. Om verbinding te maken met het cluster moet u het transactielogboek terugdraaien, het vereiste transactielogboek opvragen bij de master en dit gebruiken om de verbinding met de master tot stand te brengen.
In dit geval hebben we geen transactielogboek en kan de replica niet starten. Daarom stoppen we Postgres met een foutmelding. En daarom zit het niet in de cluster.

We moeten begrijpen waarom het niet in het cluster voorkomt en waarom er geen logs zijn. We gaan naar de nieuwe meester en kijken wat er in de logs staat. Het bleek dat er een controlepunt ontstond toen pg_rewind werd uitgevoerd. En een aantal van de oude transactielogboeken werden simpelweg hernoemd. Toen de oude master verbinding wilde maken met de nieuwe master en deze logs wilde opvragen, bleken ze al een nieuwe naam te hebben gekregen. Ze bestonden simpelweg nog niet.

Ik heb de tijdstempels vergeleken waarop deze gebeurtenissen plaatsvonden. En er is een verschil van letterlijk 150 milliseconden, dat wil zeggen dat het controlepunt in 369 milliseconden was voltooid en de WAL-segmenten werden hernoemd. En letterlijk bij 517, na 150 milliseconden, begon het terugspoelen op de oude replica. Dat wil zeggen dat letterlijk 150 milliseconden voldoende waren om te voorkomen dat de replica verbinding maakte en werkte.

Wat zijn de opties?
In eerste instantie gebruikten we replicatieslots. Wij vonden het goed. Hoewel we in de eerste fase van de operatie de slots hebben uitgeschakeld. Wij dachten dat als er te veel WAL-segmenten in de slots zouden komen, de master zou kunnen crashen. Hij zal vallen. We hebben een tijdje zonder slots gezeten. Toen we beseften dat we slots nodig hadden, hebben we de slots teruggegeven.
Maar hier is een probleem: als de master in replica gaat, verwijdert hij slots en verwijdert hij ook WAL-segmenten samen met de slots. Om te voorkomen dat dit probleem zich voordoet, hebben we besloten de parameter wal_keep_segments te verhogen. Standaard heeft het 8 segmenten. We verhoogden het naar 1 en keken hoeveel vrije ruimte we hadden. En we hebben 000 gigabyte gedoneerd aan wal_keep_segments. Dat wil zeggen dat we bij het overschakelen altijd een reserve van 16 gigabyte aan transactielogboeken op alle knooppunten hebben.
En het voordeel is dat het ook relevant is voor onderhoudstaken op de lange termijn. Stel dat we een van de replica's moeten bijwerken. En die willen we uitschakelen. We moeten de software updaten, misschien het besturingssysteem, of iets anders. En als we een replica uitschakelen, wordt de sleuf voor die replica ook verwijderd. En als we een kleine wal_keep_segments gebruiken, dan zullen de transactielogboeken verloren gaan als er gedurende langere tijd geen replica beschikbaar is. We starten een replica op en vragen de transactielogboeken op waar we gebleven waren. Deze staan mogelijk niet op de master. En de replica kan ook geen verbinding maken. Daarom hebben wij een grote voorraad tijdschriften.

Wij hebben een productiebasis. Er lopen daar al projecten.
Er is een filer opgetreden. We gingen naar binnen en keken. Alles was in orde. De replica's stonden op hun plaats en er was geen replicatievertraging. Er staan ook geen fouten in de logs, alles is in orde.
Het productteam zegt dat er wel wat gegevens zouden moeten zijn, maar we zien ze uit één bron, maar ze staan niet in de database. En we moeten begrijpen wat er met hen is gebeurd.

Het is duidelijk dat pg_rewind ze heeft gewist. Wij begrepen het meteen, maar gingen toch even kijken wat er aan de hand was.

In de logs kunnen we altijd vinden wanneer de filer optrad, wie de master werd en we kunnen bepalen wie de oude master was en wanneer hij een replica wilde worden. Dat wil zeggen dat we deze logs nodig hebben om de omvang van de transactielogs te achterhalen die verloren zijn gegaan.
Onze oude meester is opnieuw opgestart. En Patroni werd geregistreerd in autostart. Patroni is gelanceerd. Vervolgens lanceerde hij Postgres. Preciezer gezegd, vóórdat Postgres werd gestart en voordat er een replica van werd gemaakt, startte Patroni het proces pg_rewind. Hij verwijderde een aantal transactielogboeken, downloadde nieuwe en maakte verbinding. Patroni heeft hier uitstekend werk geleverd, zoals het hoort. Ons cluster is hersteld. Wij hadden 3 knooppunten, na het bestand 3 knooppunten - alles is cool.

Er zijn wat gegevens verloren gegaan. En we moeten beseffen hoeveel we verloren hebben. Wij zoeken precies naar het moment waarop we terug in de tijd gingen. Dit kunnen we opmaken uit dergelijke dagboeknotities. Terugdraaien gestart, daar iets gedaan en afgemaakt.

We moeten de positie in het transactielogboek vinden waar de oude meester stopte. In dit geval is het dit merkteken. En we hebben het tweede kenmerk nodig: de afstand waarin de oude meester verschilt van de nieuwe.
We nemen een gewone pg_wal_lsn_diff en vergelijken deze twee markeringen. En in dit geval krijgen we 17 megabyte. Of dat veel of weinig is, bepaalt iedereen voor zichzelf. Want voor sommigen is 17 megabyte niet veel, voor anderen is het veel en onacceptabel. Hierbij bepaalt iedereen voor zichzelf wat de bedrijfsbehoeften zijn.

Maar wat hebben we nu zelf ontdekt?
Ten eerste moeten we voor onszelf beslissen: moeten we Patroni altijd automatisch laten opstarten na het opnieuw opstarten van het systeem? Meestal moeten we teruggaan naar de oude meester en zien hoe ver hij is gereisd. Misschien kunt u de transactielogboeksegmenten eens bekijken en zien wat er staat. En probeer te begrijpen of we deze gegevens kunnen verliezen of dat we de oude master in de stand-alone-modus moeten laten draaien om de gegevens te extraheren.
Pas daarna mogen we beslissen of we deze gegevens verwijderen of dat we ze kunnen herstellen en dit knooppunt als replica kunnen verbinden met ons cluster.
Daarnaast is er een parameter "maximum_lag_on_failover". Als ik me goed herinner, heeft deze parameter standaard de waarde 1 megabyte.
Hoe werkt het? Als onze replica qua replicatievertraging 1 megabyte aan data achterloopt, dan doet deze replica niet mee aan de verkiezingen. En als er ineens een filer opduikt, kijkt Patroni welke replica’s achterblijven. Als ze een groot aantal transactielogs achterlopen, kunnen ze geen master worden. Dit is een zeer goede beveiligingsfunctie die voorkomt dat u veel gegevens verliest.
Er is hier echter een probleem: de replicatievertraging in het Patroni-cluster en DCS wordt met een bepaald interval bijgewerkt. Ik denk dat 30 seconden de standaard TTL-waarde is.
Daarom kan het voorkomen dat de replicatievertraging voor replica's in DCS één is, terwijl er in werkelijkheid sprake kan zijn van een heel andere vertraging of zelfs helemaal geen vertraging. Het is dan niet realtime. En dat geeft niet altijd het werkelijke beeld weer. En het heeft geen zin om er ingewikkelde logica over te maken.
En het risico op verlies blijft bestaan. En in het slechtste geval één formule, en in het gemiddelde geval een andere formule. Dat wil zeggen dat we bij het plannen van de implementatie van Patroni en het inschatten van de hoeveelheid data die we kunnen verliezen, op deze formules moeten vertrouwen en een globaal idee moeten hebben van de hoeveelheid data die we kunnen verliezen.
En er is goed nieuws. Als de oude meester is vertrokken, kan hij zijn gang gaan dankzij een aantal achterliggende processen. Dat wil zeggen dat er een soort autovacuüm was, dat de gegevens wegschreef en opsloeg in het transactielogboek. En deze gegevens kunnen we gemakkelijk negeren en kwijtraken. Dat is geen probleem.

En zo zien de logs eruit als maximum_lag_on_failover is ingesteld, er een filter is opgetreden en er een nieuwe master moet worden geselecteerd. De replica acht zichzelf niet in staat om deel te nemen aan verkiezingen. En ze weigert deel te nemen aan de race om de leiderspositie. En ze wacht totdat er een nieuwe meester is uitgekozen, zodat ze zich met hem kan verbinden. Dit is een extra maatregel tegen gegevensverlies.

Hier hebben we een productteam dat schreef dat hun product problemen ondervindt bij het werken met Postgres. U hebt echter geen toegang tot de master zelf, omdat deze niet via SSH toegankelijk is. En autofileover gebeurt ook niet.
Deze host is gedwongen opnieuw op te starten. Door het opnieuw opstarten vond er een automatische bestandsovername plaats, maar voor zover ik weet was het ook mogelijk om handmatig een automatische bestandsovername uit te voeren. En na het opnieuw opstarten gaan we al kijken wat we met de huidige master hadden.
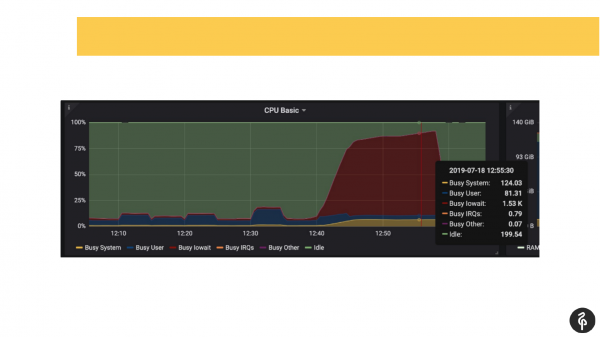
Tegelijkertijd wisten we al vooraf dat er problemen waren met de schijven, d.w.z. we wisten door de monitoring al waar we moesten graven en waar we op moesten letten.

We gingen naar het postgres-logboek en begonnen te kijken wat daar gebeurde. We zagen daar commits die één, twee, drie seconden duurden, wat helemaal niet normaal is. Wij merkten dat onze automatische stofzuiger heel langzaam en vreemd opstartte. En we zagen tijdelijke bestanden op de schijf. Dit zijn dus allemaal indicatoren voor problemen met de schijven.

We hebben gekeken naar het dmesg-systeem (nucleair berichtenlogboek). En we zagen dat er een probleem was met één van de schijven. Het schijfsubsysteem was een software-RAID. We keken naar /proc/mdstat en zagen dat er een schijf ontbrak. Dat wil zeggen dat er een Raid is van 8 schijven, er ontbreekt er één. Als u goed naar de dia kijkt, ziet u in de uitvoer dat sde ontbreekt. We zijn als het ware een schijf kwijt. Dit veroorzaakte schijfproblemen en ook toepassingen ondervonden problemen bij het werken met het Postgres-cluster.

En in dit geval zou Patroni ons op geen enkele manier hebben kunnen helpen, omdat Patroni niet de taak heeft om de status van de server of de status van de schijf te controleren. En dergelijke situaties moeten we via externe monitoring in de gaten houden. We hebben snel schijfbewaking toegevoegd aan externe bewaking.
En toen kwam de gedachte: kan fencing- of watchdog-software ons helpen? Wij dachten dat het ons in dit geval niet zou helpen, omdat Patroni tijdens de problemen nog steeds met het DCS-cluster communiceerde en geen problemen zag. Dat wil zeggen dat vanuit het oogpunt van DCS en Patroni alles in orde was met het cluster, hoewel er daadwerkelijk problemen waren met de schijf en met de beschikbaarheid van de database.
Naar mijn mening is dit een van de vreemdste problemen waar ik al heel lang onderzoek naar doe. Ik heb veel logs opnieuw gelezen en doorgespit, en ik noem het een clustersimulator.

Het probleem was dat de oude meester geen normale replica kon worden. Patroni zou het uitvoeren en Patroni zou aantonen dat dit knooppunt aanwezig was als replica, maar tegelijkertijd was het geen normale replica. Nu zult u begrijpen waarom. Dit heb ik afgeleid uit de analyse van dat probleem.

En hoe is het allemaal begonnen? Het begon, net als bij het vorige probleem, met schijfremmen. We hadden commits van één seconde en twee seconden.

Er waren verbindingsbreuken, dat wil zeggen dat de cliënten uit elkaar gingen.

Er waren blokkades van verschillende ernst.

Het schijfsubsysteem reageert dan ook niet erg goed.

En het meest raadselachtige voor mij is het verzoek tot onmiddellijke uitschakeling dat binnenkwam. Postgres heeft drie afsluitmodi:
- Het is een kwestie van wachten tot alle klanten vanzelf de verbinding verbreken.
- Er is een periode waarin we klanten dwingen de verbinding te verbreken omdat we gaan afsluiten.
- En onmiddellijk. In dit geval geeft immediate niet eens aan dat klanten de verbinding moeten verbreken. Het verbreekt de verbinding gewoon zonder waarschuwing. En het besturingssysteem stuurt een RST-bericht naar alle clients (een TCP-bericht dat de verbinding is verbroken en dat de client niets meer te melden heeft).
Wie heeft dit signaal verzonden? Postgres-achtergrondprocessen sturen dergelijke signalen niet naar elkaar; dit is kill-9. Ze sturen dit niet naar elkaar, ze reageren er alleen op: dit is een noodherstart van Postgres. Ik weet niet wie hem gestuurd heeft.
Ik keek naar het "laatste" commando en zag dat er nog iemand was die ook op deze server was ingelogd, maar ik durfde de vraag niet te stellen. Het had een kill -9 kunnen zijn. Ik zag kill -9 in de logs staan, omdat Postgres zegt dat het kill -9 accepteert. Ik heb het echter niet in de logs gezien.

Bij nader onderzoek zag ik dat Patroni al geruime tijd niets meer in het logboek had geschreven: 54 seconden. En als je de twee tijdstempels vergelijkt, waren er gedurende ongeveer 54 seconden geen berichten.
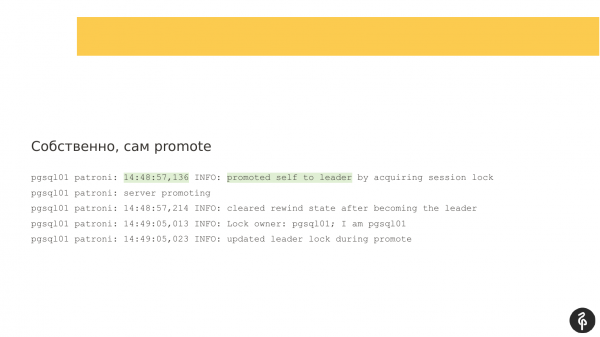
En gedurende deze tijd vond autofileover plaats. Patroni heeft het hier weer geweldig gedaan. Onze oude meester was niet beschikbaar, er was iets met hem aan de hand. En de verkiezing van een nieuwe meester begon. Hier is alles goed gegaan. We hebben pgsql01 als de nieuwe leider.

Wij hebben een replica die een meesterwerk is geworden. En dan nog een tweede opmerking. En er waren problemen met de tweede lijn. Ze probeerde het opnieuw te configureren. Voor zover ik weet probeerde ze recovery.conf te wijzigen, Postgres opnieuw te starten en verbinding te maken met de nieuwe master. Ze stuurt elke 10 seconden een berichtje dat ze het probeert, maar dat het niet lukt.

En tijdens deze pogingen krijgt de oude meester het signaal om het systeem onmiddellijk uit te schakelen. De master start opnieuw op. En ook het herstel stopt, omdat de oude meester opnieuw opstart. Dat wil zeggen dat de replica er geen verbinding mee kan maken omdat deze zich in de afsluitmodus bevindt.

Op een gegeven moment begon het te werken, maar de replicatie startte niet.
De enige hypothese die ik heb, is dat recovery.conf het adres van de oude meester bevatte. En toen de nieuwe meester verscheen, probeerde de tweede replica nog steeds verbinding te maken met de oude meester.
Toen Patroni met de tweede replica begon, startte het knooppunt wel, maar kon het geen verbinding maken via replicatie. Er ontstond een replicatievertraging die er ongeveer zo uitzag. Dat wil zeggen dat alle drie knooppunten op hun plaats waren, maar dat het tweede knooppunt achterbleef.
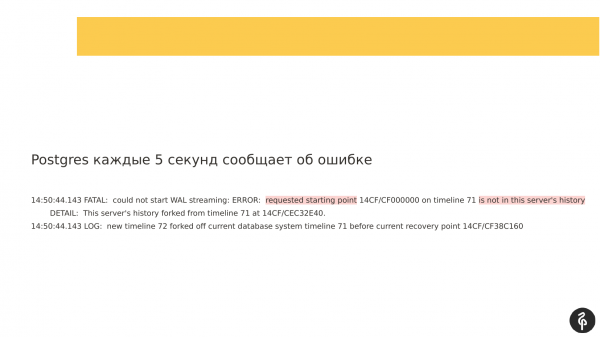
Als u echter naar de geschreven logs kijkt, ziet u dat de replicatie niet kon starten omdat de transactielogs verschillend waren. En de transactielogboeken die de master aanbiedt en die gespecificeerd zijn in recovery.conf, passen eenvoudigweg niet op ons huidige knooppunt.

En hier heb ik een fout gemaakt. Ik moest kijken wat er in recovery.conf stond om mijn hypothese te testen dat we verbinding maakten met de verkeerde master. Maar ik was er op dat moment gewoon mee bezig en het kwam niet bij me op, of ik zag dat de lijn achterliep en opnieuw gegoten moest worden, kortom, ik deed het halfslachtig. Het was mijn schuld.

Na 30 minuten arriveerde de beheerder, d.w.z. ik heb Patroni opnieuw opgestart op de replica. Ik had het al opgegeven, ik dacht dat ik het moest bijvullen. En ik dacht – ik begin Patroni opnieuw, misschien komt er wel iets goeds uit. Het herstel is begonnen. En zelfs de basis ging open, hij was klaar om verbindingen te accepteren.
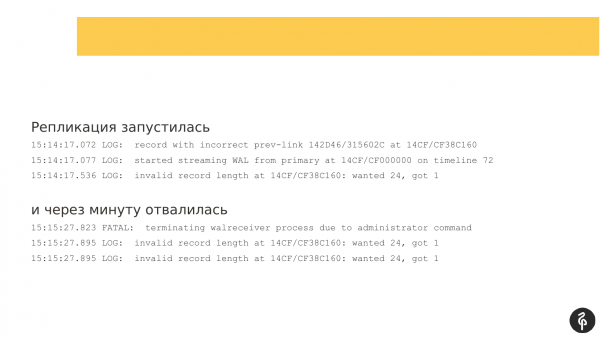
Replicatie is gestart. Maar na een minuut crashte het programma en verscheen de foutmelding dat de transactielogboeken niet geschikt waren.

Ik dacht dat ik maar weer eens opnieuw zou beginnen. Ik heb Patroni opnieuw opgestart. Ik heb niet Postgres opnieuw opgestart, maar Patroni opnieuw opgestart in de hoop dat de database op magische wijze zou opstarten.

De replicatie werd opnieuw gestart, maar de transactielogboekmarkeringen waren anders dan bij de vorige poging. De replicatie is opnieuw gestopt. En de boodschap was al een beetje anders. Voor mij was het niet bepaald informatief.

En dan bedenk ik me: wat als ik Postgres opnieuw opstart en op dit moment een controlepunt maak op de huidige master om het punt in het transactielogboek een klein beetje naar voren te verplaatsen, zodat het herstel vanaf een ander punt begint? Bovendien hadden we daar nog WAL-reserves.

Ik heb Patroni opnieuw opgestart, een paar controlepunten op de master uitgevoerd en een paar herstartpunten op de replica toen deze opende. En het hielp. Ik heb lang nagedacht over waarom het hielp en hoe het werkte. En de replica begon. En de replicatie was niet langer verbroken.

Dit is voor mij een van de meest mysterieuze vraagstukken en ik blijf me afvragen wat er nu werkelijk is gebeurd.
Wat zijn hieruit de conclusies? Patroni kan werken zoals bedoeld en zonder fouten. Maar tegelijkertijd is dit geen 100% garantie dat alles goed met ons gaat. De replica start wel op, maar bevindt zich mogelijk in een semi-werkende staat. De toepassing kan niet met een dergelijke replica werken, omdat deze oude gegevens bevat.
En na het bestand moeten we altijd controleren of alles in orde is met het cluster, dat wil zeggen of het vereiste aantal replica's aanwezig is en er geen replicatievertraging is.
Terwijl wij deze kwesties overwegen, zal ik aanbevelingen formuleren. Ik heb geprobeerd ze in twee dia's te combineren. Misschien hadden alle verhalen in twee dia's gecombineerd kunnen worden en hadden alleen die verteld kunnen worden.

Wanneer u Patroni gebruikt, is monitoring noodzakelijk. U moet altijd weten wanneer er een autofileover heeft plaatsgevonden. Als u niet weet dat er een autofileover heeft plaatsgevonden, heeft u geen controle over het cluster. En dat is slecht.
Na elk bestand moeten we het cluster altijd handmatig controleren. We moeten ervoor zorgen dat het aantal replica's altijd up-to-date is, dat er geen replicatievertraging optreedt en dat er geen fouten in de logs staan met betrekking tot streamingreplicatie, naar Patroni of naar het DCS-systeem.
Automatische machines kunnen goed werken, Patroni is een heel goed hulpmiddel. Het kan wel werken, maar het brengt het cluster niet in de gewenste staat. En als we dat niet weten, krijgen we problemen.
En Patroni is geen wondermiddel. We moeten nog steeds inzicht hebben in hoe Postgres werkt, hoe replicatie werkt, hoe Patroni met Postgres werkt en hoe communicatie tussen knooppunten tot stand komt. Dit is noodzakelijk om de problemen die zich voordoen zelf te kunnen oplossen.

Hoe benader ik het probleem van de diagnose? Het kwam zo uit dat we met verschillende klanten werken en niemand een ELK-stack heeft. We moesten de logs sorteren door 6 consoles en 2 tabbladen te openen. In het ene tabblad staan de Patroni-logs voor elk knooppunt, in het andere tabblad staan de Consul-logs of, indien nodig, Postgres-logs. Het is erg moeilijk te diagnosticeren.
Welke benaderingen heb ik ontwikkeld? Ik kijk altijd eerst wanneer de indiener arriveert. En voor mij is dat een soort keerpunt. Ik kijk naar wat er vóór, tijdens en na de filer is gebeurd. De fileover heeft twee markeringen: de starttijd en de eindtijd.
Vervolgens kijk ik in de logboeken naar gebeurtenissen die voorafgingen aan de filer, oftewel ik zoek naar de redenen waarom de filer plaatsvond.
En dit geeft inzicht in wat er is gebeurd en wat er in de toekomst gedaan kan worden zodat dergelijke omstandigheden zich niet meer voordoen (en als gevolg daarvan geen aangifte wordt gedaan).
En waar kijken wij meestal? Ik kijk:
- Eerste in de Patroni-logs.
- Vervolgens bekijk ik de Postgres-logs of de DCS-logs, afhankelijk van wat er in de Patroni-logs is gevonden.
- Systeemlogboeken geven soms ook inzicht in de oorzaak van het probleem.

Wat vind ik van Patroni? Ik heb een zeer positieve houding ten opzichte van Patroni. Wat mij betreft is dit het beste wat er momenteel bestaat. Ik ken nog veel meer producten. Dit zijn Stolon, Repmgr, Pg_auto_failover, PAF. 4 instrumenten. Ik heb ze allemaal geprobeerd. Patroni vond ik het leukst.
Als mij gevraagd wordt: “Beveel ik Patroni aan?” Ik zeg ja, omdat ik Patroni leuk vind. En ik denk dat ik heb geleerd hoe ik het moet koken.
Als u geïnteresseerd bent in welke andere problemen er zijn met Patroni, naast de problemen die ik heb genoemd, kunt u altijd naar de pagina gaan op GitHub. Er staan veel verschillende verhalen in en er worden veel interessante onderwerpen besproken. En als gevolg daarvan zijn er enkele bugs geïntroduceerd en opgelost, kortom, het is een interessant leesstuk.
Er zijn een aantal interessante verhalen over mensen die zichzelf in de voet schieten. Zeer informatief. Je leest en begrijpt dat je dat niet moet doen. Ik heb het vakje voor mezelf aangevinkt.
En ik wil Zalando hartelijk bedanken voor het ontwikkelen van dit project, in het bijzonder Alexander Kukushkin en Alexey Klyukin. Alexey Klyukin is een van de co-auteurs. Hij werkt niet meer bij Zalando, maar dit zijn twee mensen die met dit product aan de slag zijn gegaan.
En ik vind Patroni echt heel cool. Ik ben blij dat ze bestaat. Het is interessant met haar. En een grote dank aan iedereen die patches schrijft in Patroni. Ik hoop dat Patroni met de jaren volwassener, cooler en efficiënter wordt. Het werkt al, maar ik hoop dat het nog beter wordt. Dus als u van plan bent Patroni te gebruiken, wees dan niet bang. Dit is een goede oplossing, die geïmplementeerd en gebruikt kan worden.
Dat is alles. Als u vragen heeft, stel ze gerust.

vragen
Bedankt voor het melden! Als we na de filer nog heel goed moeten zoeken, waarom hebben we dan een automatische filer nodig?
Omdat het iets nieuws is. We werken pas een jaar met haar samen. Voorkomen is beter dan genezen. Wij willen binnengaan en zien dat alles daadwerkelijk werkt zoals het hoort. Dit is het niveau van wantrouwen bij volwassenen. Het is beter om het nog eens te controleren.
Wij zijn vanochtend even wezen kijken, toch?
Niet 's ochtends, meestal ontdekken we het meteen over autofileover. We ontvangen meldingen en zien dat er een autofileover heeft plaatsgevonden. We gaan er meteen naar binnen en nemen een kijkje. Maar al deze controles moeten op het niveau van monitoring plaatsvinden. Als u Patroni via de REST API benadert, is er geschiedenis. Met behulp van de geschiedenis kunt u tijdstempels bekijken waarop het bestand is uitgevoerd. Op basis hiervan kan monitoring plaatsvinden. Je kunt naar de geschiedenis kijken om te zien hoeveel gebeurtenissen er hebben plaatsgevonden. Als er meer gebeurtenissen zijn, betekent dit dat er een autofileover heeft plaatsgevonden. Je kan het gaan bekijken. Of ons automatische controlesysteem controleert of alle replica's op hun plaats staan, of er geen vertraging is en of alles in orde is.
Dank je wel!
Hartelijk dank voor een geweldig verhaal! Als we het DCS-cluster naar een locatie ver van het Postgres-cluster verplaatsen, moet dit cluster dan ook periodiek worden onderhouden? Wat zijn de beste werkwijzen voor het uitschakelen van bepaalde delen van het DCS-cluster, wat kunt u ermee doen, etc.? Hoe leeft dit hele bouwwerk? En hoe doe je dat dan?
Één bedrijf moest een probleemmatrix maken met daarin wat er gebeurt als een of meer componenten defect raken. Met behulp van deze matrix doorlopen we sequentieel alle componenten en bouwen we scenario's voor het geval dat deze componenten falen. Voor elk scenario waarin iets fout gaat, kunt u een actieplan voor herstel opstellen. En in het geval van DCS is dit onderdeel van de standaardinfrastructuur. En het is de beheerder die het beheert, en we vertrouwen al op de beheerders die het beheren en op hun vermogen om het te repareren in geval van ongelukken. Als er helemaal geen DCS is, implementeren we het wel, maar we monitoren het niet specifiek, omdat we niet verantwoordelijk zijn voor de infrastructuur. We geven echter wel aanbevelingen over hoe en wat er gemonitord moet worden.
Heb ik het goed begrepen dat ik Patroni, de filer en alles moet uitschakelen voordat ik iets met de hosts doe?
Het hangt ervan af hoeveel knooppunten er in het DCS-cluster zitten. Als er veel knooppunten zijn en we slechts één van de knooppunten (de replica) uitschakelen, dan blijft het quorum in het cluster behouden. En Patroni blijft functioneel. En er wordt niets getriggerd. Als we complexe bewerkingen hebben die meerdere knooppunten beïnvloeden, en als deze bewerkingen het quorum zouden kunnen verstoren, dan kan het zinvol zijn om Patroni te pauzeren. Hij heeft een bijbehorend commando: patronictl pause, patronictl resume. We pauzeren het programma gewoon en gedurende die tijd werkt de automatische bestandsoverdracht niet. We voeren onderhoud uit op het DCS-cluster, verwijderen de pauze en gaan verder met leven.
Thank you very much!
Hartelijk dank voor het melden! Wat vindt het productteam van het verlies van gegevens?
Productteams kan het niets schelen, maar teamleiders maken zich zorgen.
Welke garanties zijn er?
Het is heel moeilijk met garanties. Er is een rapport van Alexander Kukushkin "Hoe bereken je RPO en RTO", d.w.z. hersteltijd en hoeveel data we kunnen verliezen. Ik denk dat we deze dia's moeten vinden en bestuderen. Voor zover ik me kan herinneren, zijn er specifieke stappen voor het berekenen van deze dingen. Hoeveel transacties kunnen we verliezen, hoeveel data kunnen we verliezen? Optioneel kunnen we synchrone replicatie op Patroni-niveau gebruiken, maar dit is een tweesnijdend zwaard: of we hebben betrouwbaarheid van de gegevens, of we verliezen snelheid. Er is sprake van synchrone replicatie, maar ook dit garandeert geen 100% bescherming tegen gegevensverlies.
Alexey, bedankt voor het geweldige rapport! Heeft u ervaring met het gebruik van Patroni voor zero-level bescherming? Dat wil zeggen in combinatie met synchrone standby? Dit is de eerste vraag. En de tweede vraag. Je hebt verschillende oplossingen gebruikt. We hebben Repmgr gebruikt, maar zonder autofileover. Nu zijn we van plan om autofileover te koppelen. En wij overwegen Patroni als een alternatieve oplossing. Wat zijn volgens u de voordelen ten opzichte van Repmgr?
De eerste vraag ging over synchrone opmerkingen. Niemand gebruikt hier synchrone replicatie omdat iedereen bang is (verschillende clients gebruiken het al, en we hebben in principe geen prestatieproblemen opgemerkt — Opmerking van de spreker). We hebben echter een regel voor onszelf ontwikkeld dat er minimaal drie knooppunten in een synchroon replicatiecluster moeten zijn. Als we namelijk twee knooppunten hebben en de master of replica uitvalt, dan schakelt Patroni dit knooppunt over naar de Standalone-modus, zodat de applicatie blijft werken. In dat geval bestaat het risico op gegevensverlies.
Wat de tweede vraag betreft: we gebruikten Repmgr en gebruiken het om historische redenen nog steeds bij sommige klanten. Wat valt er te zeggen? In Patroni is autofileover standaard aanwezig, in Repmgr is autofileover een extra functie die ingeschakeld moet worden. We moeten de Repmgr-daemon op elk knooppunt uitvoeren en vervolgens kunnen we autofileover configureren.
Repmgr controleert of Postgres-knooppunten actief zijn. Repmgr-processen controleren elkaars bestaan. Dit is geen efficiënte aanpak omdat er complexe gevallen van netwerkisolatie kunnen optreden, waarbij een groot Repmgr-cluster opsplitst in meerdere kleinere clusters en toch blijft functioneren. Ik volg Repmgr al een tijdje niet meer. Misschien is het inmiddels opgelost... of misschien ook niet. Maar het exporteren van informatie over de clusterstatus naar DCS, zoals Stolon en Patroni doen, is de meest haalbare optie.
Alexey, ik heb een vraag, misschien een flauwe. In een van de eerste voorbeelden verplaatste u DCS van de lokale machine naar een extern knooppunt. Wij begrijpen dat het netwerk een geheel is met eigen karakteristieken; het leeft zelfstandig. En wat gebeurt er als het DCS-cluster om welke reden dan ook niet meer beschikbaar is? Ik zal de redenen niet noemen, er kunnen er veel zijn: van de oneerlijke handen van netwerkers tot echte problemen.
Ik heb dit niet hardop gezegd, maar een DCS-cluster moet ook fouttolerant zijn. Dit betekent dat er een oneven aantal knooppunten nodig is om een quorum te kunnen bereiken. Wat gebeurt er als het DCS-cluster niet meer beschikbaar is of het quorum niet kan bereiken, bijvoorbeeld als er een netwerksplitsing is of een knooppunt uitvalt? In dit geval schakelt het Patroni-cluster over naar de alleen-lezen-modus. Het Patroni-cluster kan niet bepalen wat de status van het cluster is en wat er moet gebeuren. Er kan geen contact worden gemaakt met DCS en de nieuwe clusterstatus daar worden opgeslagen. Het hele cluster wordt dus alleen-lezen. En wacht óf op een handmatige interventie van de operator óf tot DCS hersteld is.
Stel je eens voor dat DCS voor ons een service wordt die net zo belangrijk is als de database zelf.
Ja, ja. In veel moderne bedrijven is Service Discovery een integraal onderdeel van de infrastructuur. De implementatie vindt plaats nog voordat er een database in de infrastructuur aanwezig is. Normaal gesproken wordt de infrastructuur opgestart, geïmplementeerd in het datacenter en hebben we direct Service Discovery. Als het Consul is, kan er ook DNS op gebouwd worden. Als het Etcd is, kan het onderdeel zijn van een Kubernetes-cluster, waarin al het andere wordt geïmplementeerd. Het lijkt mij dat Service Discovery inmiddels een integraal onderdeel is van moderne infrastructuren. En ze denken er veel eerder over na dan over databases.
Dank je wel!
Bron: www.habr.com
