

Laten we niet vergeten dat de Elastic Stack gebaseerd is op de niet-relationele Elasticsearch-database, de Kibana-webinterface en gegevensverzamelaars en -processors (de beroemdste Logstash, verschillende Beats, APM en andere). Een van de leuke toevoegingen aan de gehele genoemde productstapel is data-analyse met behulp van machine learning-algoritmen. In het artikel begrijpen we wat deze algoritmen zijn. Graag onder cat.
Machine learning is een betaalde functie van de shareware Elastic Stack en is opgenomen in het X-Pack. Om het te gebruiken, activeert u gewoon de proefperiode van 30 dagen na de installatie. Nadat de proefperiode is verstreken, kunt u ondersteuning aanvragen om deze te verlengen of een abonnement aanschaffen. De kosten van een abonnement worden niet berekend op basis van het datavolume, maar op basis van het aantal gebruikte knooppunten. Nee, de hoeveelheid gegevens heeft uiteraard invloed op het aantal vereiste knooppunten, maar toch is deze benadering van licentieverlening menselijker in verhouding tot het budget van het bedrijf. Als er geen hoge productiviteit nodig is, kunt u geld besparen.
ML in de Elastic Stack is geschreven in C++ en draait buiten de JVM, waarin Elasticsearch zelf draait. Dat wil zeggen, het proces (het heet trouwens autodetect) verbruikt alles wat de JVM niet inslikt. Op een demostand is dit niet zo belangrijk, maar in een productieomgeving is het belangrijk om aparte knooppunten toe te wijzen voor ML-taken.
Machine learning-algoritmen vallen in twee categorieën: и . In de Elastic Stack bevindt het algoritme zich in de categorie ‘niet-gecontroleerd’. Door Je kunt het wiskundige apparaat van machine learning-algoritmen zien.
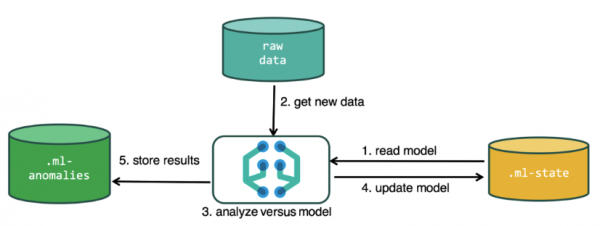
Om de analyse uit te voeren, maakt het machine learning-algoritme gebruik van gegevens die zijn opgeslagen in Elasticsearch-indexen. U kunt taken voor analyse creëren, zowel vanuit de Kibana-interface als via de API. Als je dit via Kibana doet, hoef je een aantal dingen niet te weten. Bijvoorbeeld extra indexen die het algoritme gebruikt tijdens de werking ervan.
Aanvullende indices die worden gebruikt in het analyseproces.ml-state — informatie over statistische modellen (analyse-instellingen);
.ml-anomalies-* — resultaten van ML-algoritmen;
.ml-meldingen — instellingen voor meldingen op basis van analyseresultaten.
De datastructuur in de Elasticsearch-database bestaat uit indexen en documenten die daarin zijn opgeslagen. In vergelijking met een relationele database kan een index worden vergeleken met een databaseschema, en een document met een record in een tabel. Deze vergelijking is voorwaardelijk en wordt gegeven om het begrip van verder materiaal te vereenvoudigen voor degenen die alleen van Elasticsearch hebben gehoord.
Dezelfde functionaliteit is beschikbaar via de API als via de webinterface, dus voor de duidelijkheid en het begrip van de concepten zullen we laten zien hoe u deze via Kibana kunt configureren. In het menu aan de linkerkant bevindt zich een Machine Learning-sectie waar u een nieuwe taak kunt aanmaken. In de Kibana-interface ziet het eruit als de afbeelding hieronder. Nu zullen we elk type taak analyseren en laten zien welke soorten analyses hier kunnen worden gemaakt.
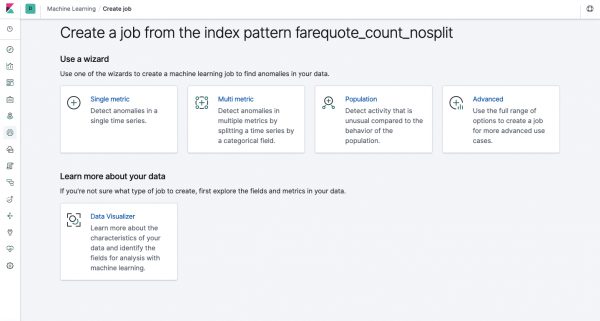
Single Metric - analyse van één metriek, Multi Metric - analyse van twee of meer metrieken. In beide gevallen wordt elke metriek geanalyseerd in een geïsoleerde omgeving, d.w.z. het algoritme houdt geen rekening met het gedrag van parallel geanalyseerde metrieken, zoals het lijkt in het geval van Multi Metric. Om berekeningen uit te voeren waarbij rekening wordt gehouden met de correlatie van verschillende statistieken, kunt u Populatieanalyse gebruiken. En Advanced verfijnt de algoritmen met extra opties voor bepaalde taken.
Enkele statistiek
Het analyseren van veranderingen in één enkele metriek is het eenvoudigste wat hier kan worden gedaan. Nadat u op Taak maken hebt geklikt, zoekt het algoritme naar afwijkingen.
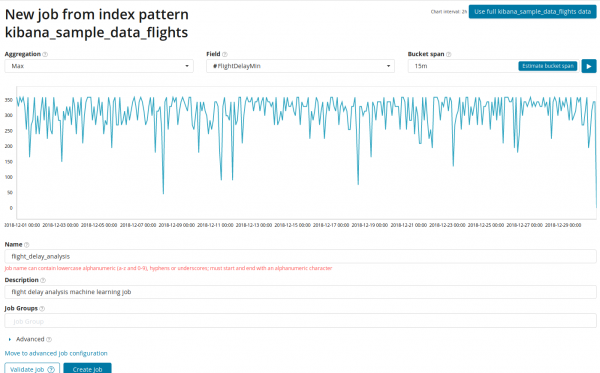
In het veld Aggregatie u kunt een aanpak kiezen voor het zoeken naar afwijkingen. Wanneer bijvoorbeeld min waarden onder de typische waarden worden als afwijkend beschouwd. Eten Max, Hoog Gemiddeld, Laag, Gemiddeld, Onderscheidend en anderen. Beschrijvingen van alle functies zijn te vinden .
In het veld Veld geeft het numerieke veld aan in het document waarop we de analyse zullen uitvoeren.
In het veld — granulariteit van de intervallen op de tijdlijn waarlangs de analyse zal worden uitgevoerd. U kunt op de automatisering vertrouwen of handmatig kiezen. De onderstaande afbeelding is een voorbeeld van een te lage granulariteit. Het kan zijn dat u de anomalie over het hoofd ziet. Met deze instelling kunt u de gevoeligheid van het algoritme voor afwijkingen wijzigen.
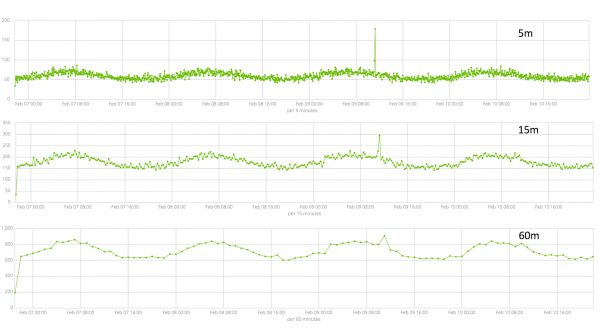
De duur van de verzamelde gegevens is van cruciaal belang voor de effectiviteit van de analyse. Tijdens de analyse identificeert het algoritme herhalende intervallen, berekent het betrouwbaarheidsintervallen (basislijnen) en identificeert het afwijkingen: atypische afwijkingen van het gebruikelijke gedrag van de metriek. Gewoon bijvoorbeeld:
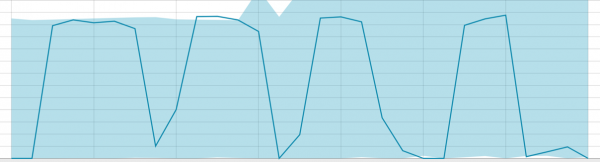
Basislijnen met een klein stukje data:
Wanneer het algoritme iets heeft om van te leren, ziet de basislijn er als volgt uit:
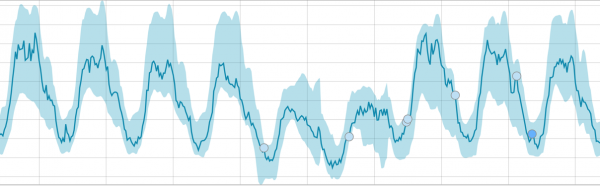
Na het starten van de taak bepaalt het algoritme afwijkende afwijkingen van de norm en rangschikt deze op basis van de waarschijnlijkheid van een afwijking (de kleur van het bijbehorende label wordt tussen haakjes aangegeven):
Waarschuwing (blauw): minder dan 25
Klein (geel): 25-50
Majoor (oranje): 50-75
Kritiek (rood): 75-100
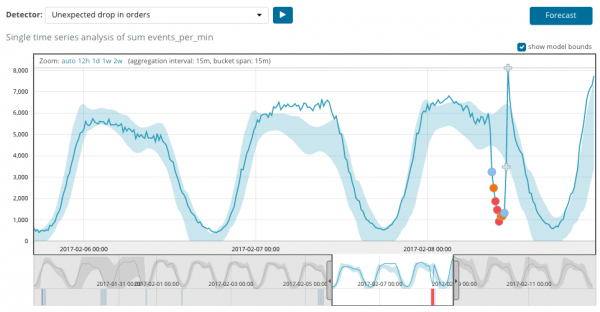
Onderstaande grafiek toont een voorbeeld van de gevonden afwijkingen.
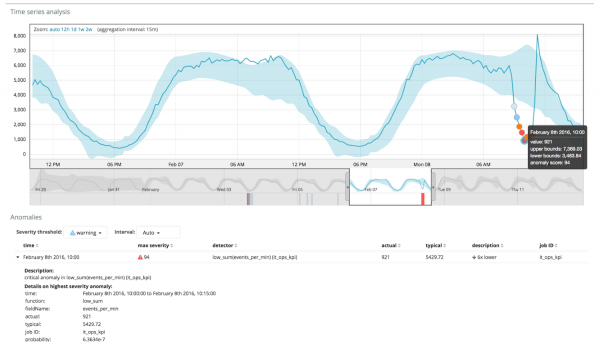
Hier ziet u het getal 94, dat de waarschijnlijkheid van een afwijking aangeeft. Het is duidelijk dat, aangezien de waarde dichtbij de 100 ligt, dit betekent dat er sprake is van een anomalie. De kolom onder de grafiek toont de pejoratief kleine waarschijnlijkheid dat 0.000063634% van de metriekwaarde daar voorkomt.
Naast het zoeken naar afwijkingen kunt u in Kibana ook prognoses uitvoeren. Dit gebeurt eenvoudig en vanuit dezelfde weergave met afwijkingen - knop Voorspelling in de rechterbovenhoek.
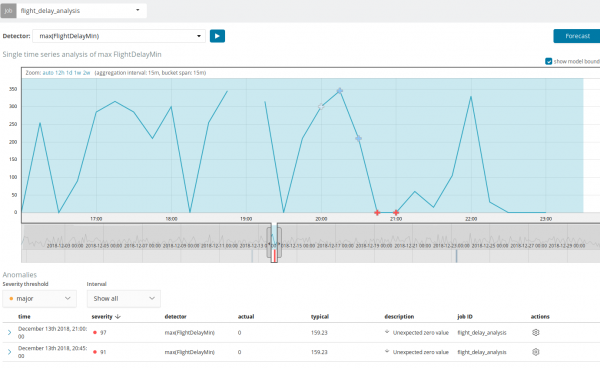
De voorspelling wordt maximaal 8 weken van tevoren gemaakt. Zelfs als je dat heel graag zou willen, is het ontwerp niet meer mogelijk.
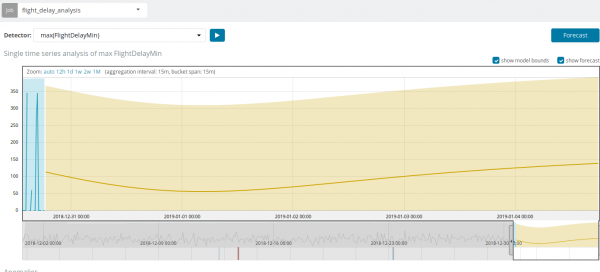
In sommige situaties zal de voorspelling zeer nuttig zijn, bijvoorbeeld bij het monitoren van de gebruikersbelasting op de infrastructuur.
Multi-metrisch
Laten we verder gaan met de volgende ML-functie in de Elastic Stack: het analyseren van verschillende statistieken in één batch. Maar dit betekent niet dat de afhankelijkheid van de ene metriek ten opzichte van de andere zal worden geanalyseerd. Dit is hetzelfde als Single Metric, maar met meerdere statistieken op één scherm, zodat u eenvoudig de impact van de ene met de andere kunt vergelijken. In het gedeelte Bevolking zullen we het hebben over het analyseren van de afhankelijkheid van de ene metriek ten opzichte van de andere.
Nadat u met Multi Metric op het vierkantje heeft geklikt, verschijnt een venster met instellingen. Laten we ze in meer detail bekijken.
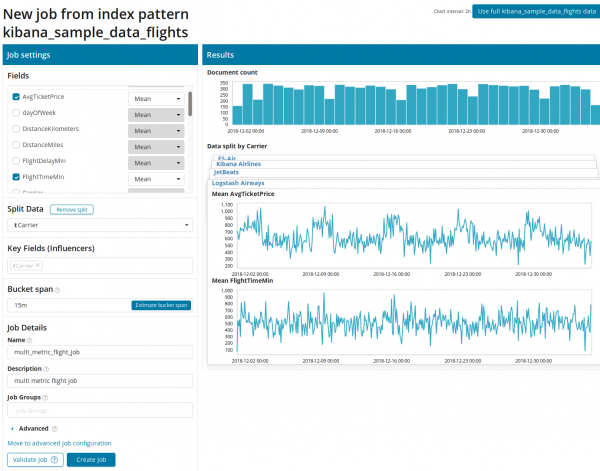
Eerst moet u de velden selecteren voor analyse en gegevensaggregatie daarop. De aggregatieopties zijn hier hetzelfde als voor Single Metric (Max, Hoog Gemiddeld, Laag, Gemiddeld, Onderscheidend en anderen). Verder worden de gegevens, indien gewenst, verdeeld in een van de velden (field Gegevens splitsen). In het voorbeeld hebben we dit per veld gedaan HerkomstLuchthavenID. Merk op dat de statistische grafiek aan de rechterkant nu wordt weergegeven als meerdere grafieken.
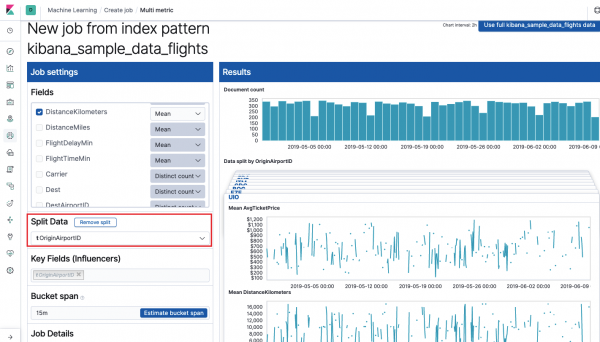
Veld Sleutelvelden (beïnvloeders) heeft rechtstreeks invloed op de gedetecteerde afwijkingen. Standaard staat hier altijd minimaal één waarde, en u kunt er nog meer toevoegen. Het algoritme zal bij de analyse rekening houden met de invloed van deze velden en de meest “invloedrijke” waarden tonen.
Na de lancering zal zoiets als dit verschijnen in de Kibana-interface.
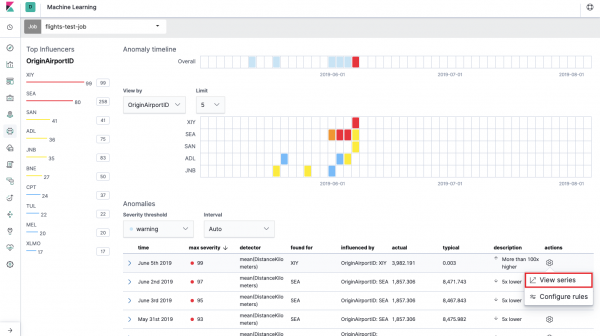
Dit is de zgn heatmap van afwijkingen voor elke veldwaarde HerkomstLuchthavenID, die wij hebben aangegeven Gegevens splitsen. Net als bij Single Metric geeft kleur de mate van abnormale afwijking aan. Het is handig om een soortgelijke analyse uit te voeren, bijvoorbeeld op werkstations om die met een verdacht groot aantal autorisaties te volgen, enz. Wij schreven al , die hier ook kunnen worden verzameld en geanalyseerd.
Onder de heatmap staat een lijst met afwijkingen. Van elke afwijking kunt u overschakelen naar de Single Metric-weergave voor gedetailleerde analyse.
Bevolking
Om afwijkingen tussen correlaties tussen verschillende statistieken te zoeken, beschikt de Elastic Stack over een gespecialiseerde populatieanalyse. Met zijn hulp kunt u zoeken naar afwijkende waarden in de prestaties van een server in vergelijking met andere wanneer bijvoorbeeld het aantal verzoeken aan het doelsysteem toeneemt.
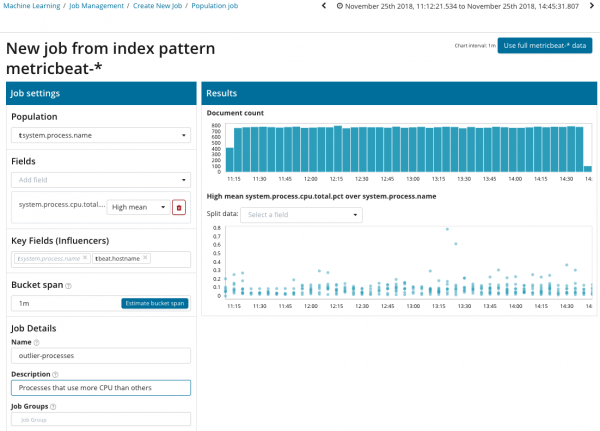
In deze illustratie geeft het veld Bevolking de waarde aan waarop de geanalyseerde metriek betrekking heeft. In dit geval is dit de naam van het proces. Als resultaat zullen we zien hoe de processorbelasting van elk proces elkaar beïnvloedde.
Houd er rekening mee dat de grafiek van de geanalyseerde gegevens afwijkt van de gevallen met Single Metric en Multi Metric. Dit is in Kibana by design gedaan voor een betere perceptie van de verdeling van waarden van de geanalyseerde data.
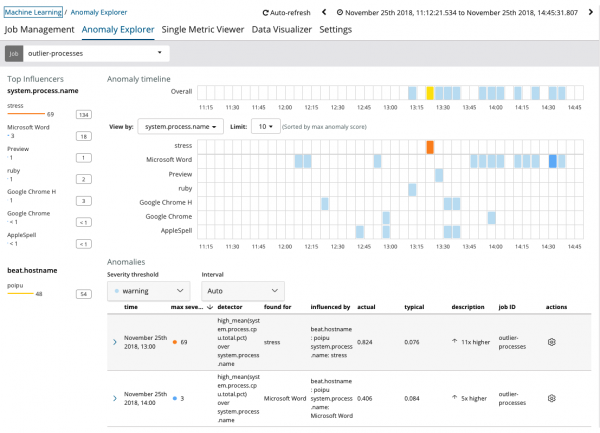
De grafiek laat zien dat het proces zich abnormaal gedroeg spanning (trouwens, gegenereerd door een speciaal hulpprogramma) op de server poipu, die het optreden van deze anomalie heeft beïnvloed (of een beïnvloeder bleek te zijn).
Geavanceerd
Analyse met fijnafstemming. Met Geavanceerde analyse verschijnen aanvullende instellingen in Kibana. Nadat u op de tegel Geavanceerd in het creatiemenu hebt geklikt, verschijnt dit venster met tabbladen. Tab Job Details We hebben dit met opzet overgeslagen, er zijn basisinstellingen die niet direct verband houden met het opzetten van de analyse.
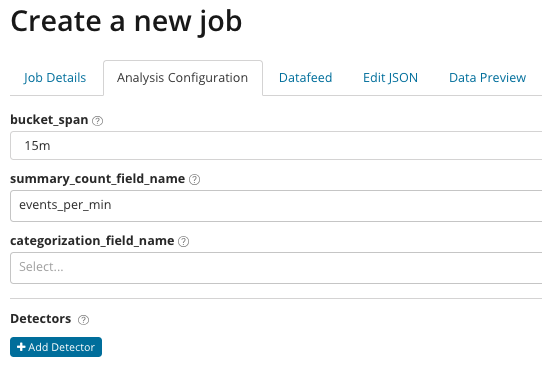
В samenvatting_telling_veldnaam Optioneel kunt u de naam van een veld opgeven uit documenten die geaggregeerde waarden bevatten. In dit voorbeeld het aantal gebeurtenissen per minuut. IN geeft de naam en waarde aan van een veld uit het document dat een variabele waarde bevat. Met behulp van het masker in dit veld kunt u de geanalyseerde gegevens in subsets opsplitsen. Let op de knop Detector toevoegen in de vorige afbeelding. Hieronder ziet u het resultaat van het klikken op deze knop.
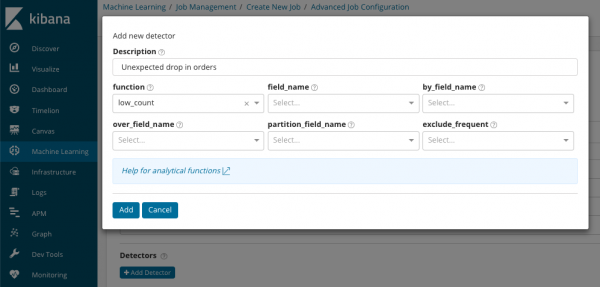
Hier vindt u een extra blok met instellingen voor het configureren van de anomaliedetector voor een specifieke taak. We zijn van plan specifieke gebruiksscenario's (vooral beveiligingsscenario's) te bespreken in de volgende artikelen. Bijvoorbeeld, een van de gedemonteerde koffers. Het wordt geassocieerd met het zoeken naar zelden voorkomende waarden en wordt geïmplementeerd .
In het veld functie U kunt een specifieke functie selecteren om naar afwijkingen te zoeken. Behalve zeldzaam, zijn er nog een paar interessante functies - . Ze identificeren afwijkingen in het gedrag van statistieken gedurende de dag of week, respectievelijk. Andere analysefuncties .
В veldnaam geeft het veld van het document aan waarop de analyse zal worden uitgevoerd. Bij_veldnaam kan worden gebruikt om de analyseresultaten te scheiden voor elke individuele waarde van het hier gespecificeerde documentveld. Als je vult over_veldnaam je krijgt de populatieanalyse die we hierboven hebben besproken. Als u een waarde opgeeft in partitie_veldnaam, dan worden voor dit veld van het document voor elke waarde aparte basislijnen berekend (de waarde kan bijvoorbeeld de naam van de server of het proces op de server zijn). IN uitsluiten_frequent kan kiezen allen of geen, wat betekent dat vaak voorkomende documentveldwaarden worden uitgesloten (of opgenomen).
In dit artikel hebben we geprobeerd een zo beknopt mogelijk beeld te geven van de mogelijkheden van machine learning in de Elastic Stack; er zijn nog veel details achter de schermen. Vertel ons in de reacties welke gevallen je hebt kunnen oplossen met Elastic Stack en voor welke taken je het gebruikt. Om contact met ons op te nemen kunt u gebruik maken van persoonlijke berichten op Habré of .
Bron: www.habr.com
