

aankondiging
Collega's, halverwege de zomer ben ik van plan nog een reeks artikelen uit te brengen over het ontwerp van wachtrijsystemen: "The VTrade Experiment" - een poging om een raamwerk voor handelssystemen te schrijven. De serie onderzoekt de theorie en praktijk van het bouwen van een beurs, veiling en winkel. Aan het einde van het artikel nodig ik u uit om te stemmen op de onderwerpen die u het meest interesseren.

Dit is het laatste artikel in de serie over gedistribueerde reactieve toepassingen in Erlang/Elixir. IN je kunt de theoretische grondslagen van reactieve architectuur vinden. illustreert de basispatronen en mechanismen voor het construeren van dergelijke systemen.
Vandaag zullen we kwesties aan de orde stellen met betrekking tot de ontwikkeling van de codebasis en projecten in het algemeen.
Organisatie van diensten
In de praktijk moet je bij het ontwikkelen van een dienst vaak meerdere interactiepatronen in één controller combineren. De gebruikersservice, die het probleem van het beheren van projectgebruikersprofielen oplost, moet bijvoorbeeld reageren op req-resp-verzoeken en profielupdates rapporteren via pub-sub. Dit geval is vrij eenvoudig: achter de berichtenuitwisseling zit één controller die de servicelogica implementeert en updates publiceert.
De situatie wordt ingewikkelder als we een fouttolerante gedistribueerde service moeten implementeren. Laten we ons voorstellen dat de vereisten voor gebruikers zijn veranderd:
- nu zou de service verzoeken op 5 clusterknooppunten moeten verwerken,
- in staat zijn om achtergrondverwerkingstaken uit te voeren,
- en ook in staat zijn om abonnementslijsten voor profielupdates dynamisch te beheren.
Commentaar: We houden geen rekening met de kwestie van consistente opslag en gegevensreplicatie. Laten we aannemen dat deze problemen eerder zijn opgelost en dat het systeem al over een betrouwbare en schaalbare opslaglaag beschikt, en dat handlers mechanismen hebben om ermee te communiceren.
De formele beschrijving van de gebruikersdienst is ingewikkelder geworden. Vanuit het oogpunt van een programmeur zijn de veranderingen minimaal vanwege het gebruik van berichtenuitwisseling. Om aan de eerste vereiste te voldoen, moeten we de balancering configureren op het req-resp-uitwisselingspunt.
De vereiste om achtergrondtaken te verwerken komt vaak voor. Bij gebruikers kan dit het controleren van gebruikersdocumenten zijn, het verwerken van gedownloade multimedia of het synchroniseren van gegevens met sociale media. netwerken. Deze taken moeten op de een of andere manier binnen het cluster worden verdeeld en de voortgang van de uitvoering moet worden bewaakt. Daarom hebben we twee oplossingsopties: gebruik de taakverdelingssjabloon uit het vorige artikel, of, als dit niet bevalt, schrijf een aangepaste taakplanner die de pool van processors beheert op de manier die we nodig hebben.
Voor punt 3 is de pub-sub-sjabloonextensie vereist. En voor implementatie moeten we, na het creëren van een pub-sub-wisselpunt, bovendien de controller van dit punt binnen onze service lanceren. Het is dus alsof we de logica voor het verwerken van aanmeldingen en afmeldingen van de berichtenlaag naar de implementatie van gebruikers verplaatsen.
Als gevolg hiervan bleek uit de ontleding van het probleem dat we, om aan de vereisten te voldoen, 5 exemplaren van de service op verschillende knooppunten moeten lanceren en een extra entiteit moeten creëren: een pub-subcontroller, verantwoordelijk voor het abonnement.
Om 5 handlers uit te voeren, hoeft u de servicecode niet te wijzigen. De enige aanvullende actie is het instellen van balanceringsregels op het uitwisselingspunt, waar we het later over zullen hebben.
Er is ook een extra complexiteit: de pub-subcontroller en de aangepaste taakplanner moeten in één exemplaar werken. Ook hier moet de berichtendienst, als fundamentele dienst, een mechanisme bieden voor het selecteren van een leider.
Selectie van leiders
In gedistribueerde systemen is leiderverkiezing de procedure voor het aanwijzen van één enkel proces dat verantwoordelijk is voor het plannen van de gedistribueerde verwerking van een bepaalde lading.
In systemen die niet gevoelig zijn voor centralisatie, worden universele en op consensus gebaseerde algoritmen, zoals paxos of raft, gebruikt.
Omdat messaging een makelaar en een centraal element is, kent het alle servicecontrollers – kandidaat-leiders. Berichten kunnen een leider benoemen zonder te stemmen.
Na het starten en verbinden met het wisselpunt ontvangen alle diensten een systeembericht #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers}. Als LeaderPid valt samen met pid huidige proces, wordt aangesteld als leider, en de lijst Servers omvat alle knooppunten en hun parameters.
Op het moment dat er een nieuwe verschijnt en een werkend clusterknooppunt wordt losgekoppeld, ontvangen alle servicecontrollers #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} и #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} respectievelijk.
Zo zijn alle onderdelen op de hoogte van alle veranderingen en heeft het cluster gegarandeerd altijd één leider.
Tussenpersonen
Om complexe gedistribueerde verwerkingsprocessen te implementeren, maar ook bij problemen met het optimaliseren van een bestaande architectuur, is het handig om tussenpersonen te gebruiken.
Om de servicecode niet te wijzigen en bijvoorbeeld problemen met het extra verwerken, routeren of loggen van berichten op te lossen, kunt u vóór de service een proxy-handler inschakelen, die al het extra werk zal uitvoeren.
Een klassiek voorbeeld van pub-sub-optimalisatie is een gedistribueerde applicatie met een zakelijke kern die update-gebeurtenissen genereert, zoals prijsveranderingen op de markt, en een toegangslaag - N-servers die een websocket-API voor webclients bieden.
Als u frontaal beslist, ziet de klantenservice er als volgt uit:
- de klant brengt verbindingen tot stand met het platform. Aan de kant van de server die het verkeer beëindigt, wordt een proces gestart om deze verbinding te onderhouden.
- In het kader van het serviceproces vinden autorisatie en abonnement op updates plaats. Het proces roept de abonneermethode voor onderwerpen aan.
- Zodra een gebeurtenis in de kernel is gegenereerd, wordt deze afgeleverd bij de processen die de verbindingen onderhouden.
Laten we ons voorstellen dat we 50000 abonnees hebben op het onderwerp ‘nieuws’. Abonnees worden gelijkmatig verdeeld over 5 servers. Als gevolg hiervan wordt elke update die op het uitwisselingspunt aankomt, 50000 keer gerepliceerd: 10000 keer op elke server, afhankelijk van het aantal abonnees erop. Geen erg effectief plan, toch?
Om de situatie te verbeteren, introduceren we een proxy die dezelfde naam heeft als het uitwisselingspunt. De globale naamregistrar moet het dichtstbijzijnde proces op naam kunnen retourneren, dit is belangrijk.
Laten we deze proxy op de toegangslaagservers lanceren, en al onze processen die de websocket-api bedienen, zullen zich erop abonneren, en niet op het oorspronkelijke pub-sub-uitwisselingspunt in de kernel. Proxy abonneert zich alleen op de core als er sprake is van een uniek abonnement en repliceert het inkomende bericht naar al zijn abonnees.
Als gevolg hiervan zullen er 5 berichten worden verzonden tussen de kernel en de toegangsservers, in plaats van 50000.
Routing en balancering
Verzoek-Resp
In de huidige berichtenimplementatie zijn er zeven verzoekdistributiestrategieën:
default. Het verzoek wordt naar alle controllers verzonden.round-robin. Verzoeken worden opgesomd en cyclisch verdeeld tussen controllers.consensus. De controleurs die de dienst bedienen zijn verdeeld in leiders en slaven. Verzoeken worden alleen naar de leider gestuurd.consensus & round-robin. De groep heeft een leider, maar verzoeken worden onder alle leden verdeeld.sticky. De hashfunctie wordt berekend en toegewezen aan een specifieke handler. Volgende verzoeken met deze handtekening gaan naar dezelfde afhandelaar.sticky-fun. Bij het initialiseren van het uitwisselingspunt wordt de hashberekeningsfunctie voorstickybalanceren.fun. Net als bij sticky-fun, kun je het alleen doorsturen, afwijzen of voorbewerken.
De distributiestrategie wordt bepaald wanneer het uitwisselingspunt wordt geïnitialiseerd.
Naast het balanceren kunt u met berichten ook entiteiten taggen. Laten we eens kijken naar de soorten tags in het systeem:
- Verbindingslabel. Hiermee kunt u begrijpen via welk verband de gebeurtenissen tot stand zijn gekomen. Wordt gebruikt wanneer een controllerproces verbinding maakt met hetzelfde uitwisselingspunt, maar met verschillende routeringssleutels.
- Servicelabel. Hiermee kunt u handlers in groepen voor één service combineren en de routerings- en balanceringsmogelijkheden uitbreiden. Voor het req-resp-patroon is de routering lineair. Wij sturen een verzoek naar het uitwisselingspunt, dat het vervolgens doorgeeft aan de dienst. Maar als we de handlers in logische groepen moeten splitsen, gebeurt het splitsen met behulp van tags. Bij het opgeven van een tag wordt het verzoek naar een specifieke groep controllers gestuurd.
- Label aanvragen. Hiermee kunt u onderscheid maken tussen antwoorden. Omdat ons systeem asynchroon is, moeten we, om servicereacties te kunnen verwerken, een RequestTag kunnen opgeven bij het verzenden van een verzoek. Hieruit zullen we het antwoord kunnen begrijpen waarop het verzoek bij ons is binnengekomen.
Pub-sub
Voor pub-sub is alles iets eenvoudiger. We hebben een uitwisselingspunt waar berichten worden gepubliceerd. Het uitwisselingspunt verdeelt berichten onder abonnees die zich hebben geabonneerd op de routeringssleutels die ze nodig hebben (we kunnen zeggen dat dit analoog is aan onderwerpen).
Schaalbaarheid en fouttolerantie
De schaalbaarheid van het systeem als geheel hangt af van de mate van schaalbaarheid van de lagen en componenten van het systeem:
- Services worden geschaald door extra knooppunten aan het cluster toe te voegen met handlers voor deze service. Tijdens het proefdraaien kunt u het optimale balanceringsbeleid kiezen.
- De berichtenservice zelf binnen een afzonderlijk cluster wordt over het algemeen geschaald door bijzonder belaste uitwisselingspunten naar afzonderlijke clusterknooppunten te verplaatsen, of door proxyprocessen toe te voegen aan bijzonder belaste gebieden van het cluster.
- De schaalbaarheid van het gehele systeem als kenmerk hangt af van de flexibiliteit van de architectuur en het vermogen om individuele clusters te combineren tot een gemeenschappelijke logische entiteit.
Het succes van een project hangt vaak af van de eenvoud en snelheid van opschalen. Messaging in de huidige versie groeit mee met de applicatie. Zelfs als we geen cluster van 50-60 machines hebben, kunnen we onze toevlucht nemen tot federatie. Helaas valt het onderwerp federatie buiten het bestek van dit artikel.
езервирование
Bij het analyseren van de taakverdeling hebben we de redundantie van servicecontrollers al besproken. Berichten moeten echter ook worden gereserveerd. In het geval van een knooppunt- of machinecrash zou de berichtgeving automatisch moeten herstellen, en wel in de kortst mogelijke tijd.
In mijn projecten gebruik ik extra knooppunten die de last opvangen bij een val. Erlang heeft een standaard gedistribueerde modusimplementatie voor OTP-applicaties. De gedistribueerde modus voert herstel uit in geval van een fout door de mislukte applicatie op een ander eerder gelanceerd knooppunt te starten. Het proces is transparant; na een storing verplaatst de applicatie zich automatisch naar het failoverknooppunt. Over deze functionaliteit kunt u meer lezen .
Производительность
Laten we proberen op zijn minst grofweg de prestaties van RabbitMQ en onze aangepaste berichtenuitwisseling te vergelijken.
ik vond konijnmq-testen van het openstack-team.
In paragraaf 6.14.1.2.1.2.2. Het originele document toont het resultaat van de RPC CAST:
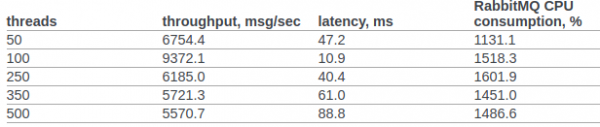
We zullen vooraf geen aanvullende instellingen voor de OS-kernel of erlang VM maken. Voorwaarden voor testen:
- erl kiest: +A1 +sbtu.
- De test binnen een enkel erlang-knooppunt wordt uitgevoerd op een laptop met een oude i7 in mobiele versie.
- Clustertests worden uitgevoerd op servers met een 10G-netwerk.
- De code wordt uitgevoerd in docker-containers. Netwerk in NAT-modus.
Testcode:
req_resp_bench(_) ->
W = perftest:comprehensive(10000,
fun() ->
messaging:request(?EXCHANGE, default, ping, self()),
receive
#'$msg'{message = pong} -> ok
after 5000 ->
throw(timeout)
end
end
),
true = lists:any(fun(E) -> E >= 30000 end, W),
ok.Scenario 1: De test wordt uitgevoerd op een laptop met een oude i7 mobiele versie. De test, berichtgeving en service worden uitgevoerd op één knooppunt in één Docker-container:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s)
Sequential 20000 cycles in ~1 seconds (26915 cycles/s)
Sequential 100000 cycles in ~4 seconds (26957 cycles/s)
Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s)
Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s)
Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)Scenario 2: 3 knooppunten die op verschillende machines draaien onder docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s)
Sequential 20000 cycles in ~2 seconds (8424 cycles/s)
Sequential 100000 cycles in ~12 seconds (8655 cycles/s)
Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s)
Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s)
Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)In alle gevallen kwam het CPU-gebruik niet boven de 250% uit
Resultaten van
Ik hoop dat deze cyclus niet op een minddump lijkt en dat mijn ervaring van groot nut zal zijn voor zowel onderzoekers van gedistribueerde systemen als praktijkmensen die nog maar aan het begin staan van het bouwen van gedistribueerde architecturen voor hun bedrijfssystemen en met belangstelling naar Erlang/Elixir kijken. , maar twijfel of het de moeite waard is...
foto
Alleen geregistreerde gebruikers kunnen deelnemen aan het onderzoek. , Alsjeblieft.
Welke onderwerpen moet ik gedetailleerder behandelen als onderdeel van de VTrade Experiment-serie?
Theorie: markten, orders en hun timing: DAY, GTD, GTC, IOC, FOK, MOO, MOC, LOO, LOC
Boek met bestellingen. Theorie en praktijk van het implementeren van een boek met groeperingen
Visualisatie van handelen: teken, balken, resoluties. Hoe op te slaan en hoe te lijmen
Backoffice. Plannen en ontwikkelen. Medewerker monitoring en incidentonderzoek
API. Laten we eens kijken welke interfaces nodig zijn en hoe we deze kunnen implementeren
Informatieopslag: PostgreSQL, Timescale, Tarantool in handelssystemen
Reactiviteit in handelssystemen
Ander. Ik zal in de reacties schrijven
6 gebruikers hebben gestemd. 4 gebruikers onthielden zich van stemming.
Bron: www.habr.com
