

Goedemiddag, mijn naam is Danil Lipovoy. Ons team bij Sbertech is begonnen met het gebruiken van HBase als operationele gegevensopslag. Tijdens het onderzoek heb ik ervaringen opgedaan die ik wilde systematiseren en beschrijven (ik hoop dat het voor velen nuttig zal zijn). Alle onderstaande experimenten werden uitgevoerd met HBase-versies 1.2.0-cdh5.14.2 en 2.0.0-cdh6.0.0-beta1.
- Algemene architectuur
- Gegevens naar HBASE schrijven
- Gegevens lezen van HBASE
- Gegevenscaching
- MultiGet/MultiPut batchgegevensverwerking
- Strategie van het opsplitsen van de tabel in regio's (morsen)
- Fouttolerantie, compactificatie en datalokaliteit
- Instellingen en prestaties
- Stress testen
- Bevindingen
1. Algemene architectuur
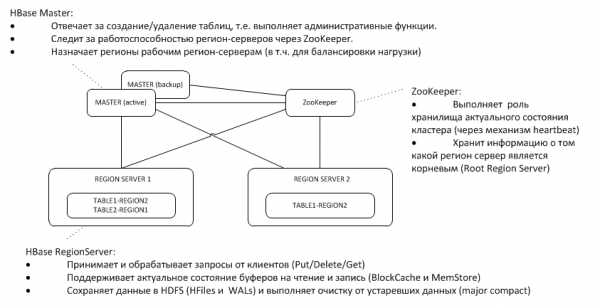
De back-up Master luistert naar de hartslag van de actieve ZooKeeper op het knooppunt en neemt de functies van de master over als deze verdwijnt.
2. Gegevens naar HBASE schrijven
Laten we eerst het eenvoudigste geval bekijken: het schrijven van een sleutel-waardeobject naar een tabel met behulp van put(rowkey). De client moet eerst uitzoeken waar de Root Region Server (RRS) zich bevindt, waar de tabel hbase:meta is opgeslagen. Deze informatie krijgt hij van ZooKeeper. Vervolgens opent het RRS en leest de hbase:meta-tabel. Hieruit wordt informatie gehaald over welke RegionServer (RS) verantwoordelijk is voor het opslaan van gegevens voor een bepaalde rowkey in de tabel waarin het geïnteresseerd is. Voor toekomstig gebruik wordt de metatabel door de client gecached, zodat volgende verzoeken sneller en rechtstreeks naar RS kunnen worden verzonden.
Vervolgens schrijft RS, nadat het een aanvraag heeft ontvangen, deze eerst naar WriteAheadLog (WAL). Dit is nodig voor herstel in het geval van een crash. Vervolgens worden de gegevens opgeslagen in MemStore. Het is een buffer in het geheugen die een gesorteerde set sleutels voor een bepaalde regio bevat. Een tabel kan worden verdeeld in regio's (partities), die elk een eigen set sleutels bevatten. Hiermee kunt u betere prestaties bereiken door regio's op verschillende servers te plaatsen. Maar hoe voor de hand liggend deze uitspraak ook is, later zullen we zien dat dit niet in alle gevallen werkt.
Nadat het record in MemStore is geplaatst, wordt er een bericht naar de client gestuurd dat het record succesvol is opgeslagen. In werkelijkheid worden de gegevens alleen in de buffer opgeslagen en worden ze pas naar de schijf geschreven nadat een bepaalde tijd is verstreken of wanneer deze is gevuld met nieuwe gegevens.
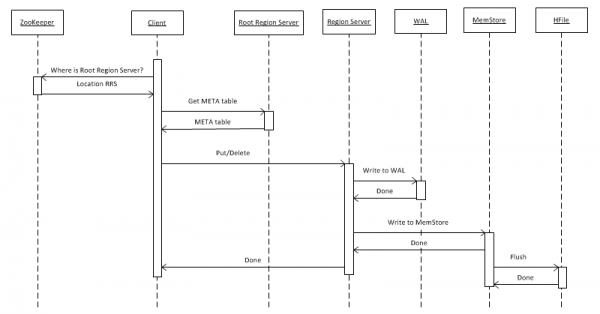
Wanneer u de bewerking 'Verwijderen' uitvoert, worden er geen fysieke gegevens verwijderd. Ze worden eenvoudigweg als verwijderd gemarkeerd en de vernietiging zelf vindt plaats op het moment dat de belangrijke compacte functie wordt aangeroepen. Dit wordt in meer detail beschreven in paragraaf 7.
HFile-bestanden worden opgeslagen in HDFS en van tijd tot tijd wordt er een klein compact proces uitgevoerd, waarbij kleine bestanden aan grotere bestanden worden toegevoegd, zonder dat er iets wordt verwijderd. Na verloop van tijd ontstaat dit probleem alleen nog bij het lezen van de gegevens (hier komen we later op terug).
Naast het hierboven beschreven laadproces bestaat er een veel efficiëntere procedure. Misschien is dit wel het sterkste punt van deze database: BulkLoad. Het houdt in dat we HFiles zelfstandig vormen en op de schijf zetten, waardoor we perfect kunnen schalen en heel behoorlijke snelheden kunnen behalen. Eigenlijk is de beperking hier niet HBase, maar de mogelijkheden van de hardware. Hieronder ziet u de resultaten van het laden op een cluster bestaande uit 16 RegionServers en 16 NodeManagers YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads), HBase versie 1.2.0-cdh5.14.2.
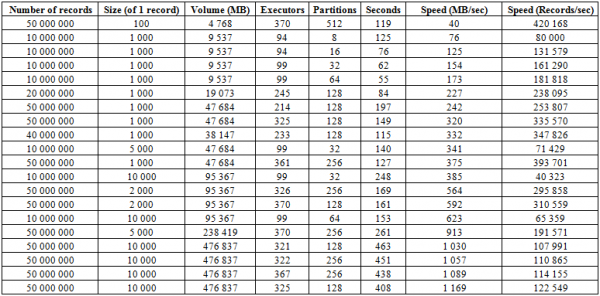
Hier ziet u dat de laadsnelheid toeneemt als u het aantal partities (regio's) in de tabel en het aantal Spark-uitvoerders vergroot. De snelheid is ook afhankelijk van het opnamevolume. Grote blokken zorgen voor een toename in de MB/sec-meting, kleine blokken voor een toename in het aantal ingevoegde records per tijdseenheid, als alle andere zaken gelijk blijven.
Je kunt ook twee tabellen tegelijk laden en zo de snelheid verdubbelen. Hieronder ziet u dat het schrijven van blokken van 10 KB naar twee tabellen tegelijk gebeurt met een snelheid van ongeveer 600 MB/sec per tabel (1275 MB/sec in totaal), wat gelijk is aan de schrijfsnelheid van 623 MB/sec naar één tabel (zie #11 hierboven).

Maar de tweede lancering met records van 50 KB laat zien dat de downloadsnelheid slechts lichtjes toeneemt, wat aangeeft dat deze de grenswaarden nadert. Houd er rekening mee dat HBASE zelf hier praktisch niet wordt belast. Het enige dat van HBASE wordt verlangd, is dat eerst de gegevens uit hbase:meta worden doorgegeven. Na de HFiles-backup worden de BlockCache-gegevens opnieuw ingesteld en de MemStore-buffer op schijf opgeslagen, als deze niet leeg is.
3. Gegevens uit HBASE lezen
Als we ervan uitgaan dat alle informatie uit hbase:meta al in de client aanwezig is (zie punt 2), dan gaat de aanvraag rechtstreeks naar de RS, waar de vereiste sleutel is opgeslagen. De zoekopdracht wordt eerst uitgevoerd in MemCache. Ongeacht of er wel of geen gegevens aanwezig zijn, wordt er ook gezocht in de BlockCache-buffer en indien nodig in HFiles. Als er gegevens in het bestand worden gevonden, worden deze in BlockCache geplaatst en bij de volgende aanvraag sneller teruggestuurd. Zoeken in HFile gaat relatief snel dankzij het gebruik van het Bloom-filter. Na het lezen van een kleine hoeveelheid gegevens wordt direct bepaald of dit bestand de vereiste sleutel bevat. Zo niet, dan wordt doorgegaan naar het volgende bestand.
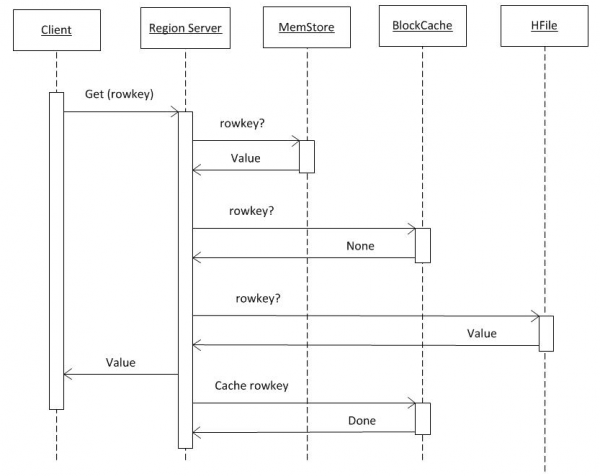
Nadat RS gegevens van deze drie bronnen heeft ontvangen, genereert hij een respons. Het is met name mogelijk om meerdere gevonden versies van een object tegelijk over te dragen als de klant versiebeheer heeft aangevraagd.
4. Gegevenscaching
MemStore- en BlockCache-buffers nemen tot 80% van het toegewezen RS-geheugen op de heap in beslag (de rest is gereserveerd voor RS-servicetaken). Als de typische gebruiksmodus zodanig is dat processen dezelfde gegevens schrijven en direct daarna lezen, dan is het zinvol om BlockCache te verkleinen en MemStore te vergroten. Wanneer gegevens naar de cache worden geschreven om te worden gelezen, komen ze daar namelijk niet aan en zal BlockCache minder vaak worden gebruikt. De BlockCache-buffer bestaat uit twee delen: LruBlockCache (altijd on-heap) en BucketCache (meestal off-heap of op SSD). BucketCache moet worden gebruikt als er veel leesverzoeken zijn en deze niet in LruBlockCache passen, wat leidt tot actief werk van Garbage Collector. Tegelijkertijd moet je geen radicale prestatieverbetering verwachten van het gebruik van de leescache, maar daar komen we bij punt 8 op terug.
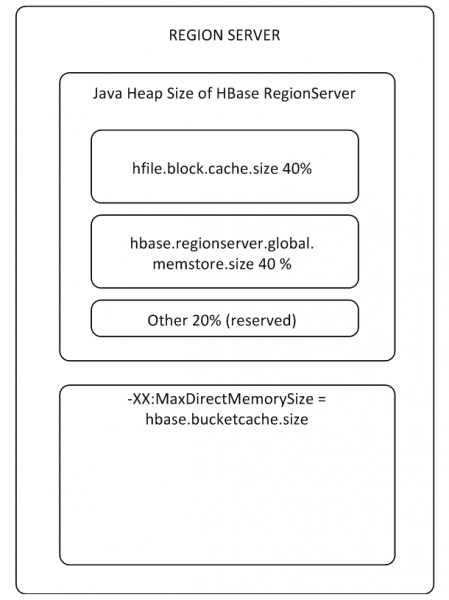
Er is één BlockCache voor de gehele RS en elke tabel heeft zijn eigen MemStore (één voor elke kolomfamilie).
Als In theorie komen gegevens die naar de cache worden geschreven daar niet aan. Parameters als CACHE_DATA_ON_WRITE voor de tabel en “Cache DATA on Write” voor RS zijn dan ook op false gezet. In de praktijk zal het echter zo zijn dat als we gegevens naar MemStore schrijven, deze vervolgens naar schijf flushen (en dus wissen), en vervolgens het resulterende bestand verwijderen, we de gegevens succesvol zullen ontvangen door een get-aanvraag uit te voeren. Bovendien, zelfs als u BlockCache volledig uitschakelt, de tabel vult met nieuwe gegevens, vervolgens de MemStore op schijf reset, de gegevens verwijdert en ze opvraagt vanuit een andere sessie, worden ze nog steeds ergens vandaan opgehaald. HBase slaat dus niet alleen gegevens op, maar ook mysterieuze mysteries.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
De parameter "Cache DATA on Read" is ingesteld op false. Als u ideeën heeft, kunt u deze gerust in de reacties bespreken.
5. Batchgegevensverwerking MultiGet/MultiPut
Het verwerken van afzonderlijke verzoeken (Get/Put/Delete) is een vrij dure bewerking. Combineer ze daarom indien mogelijk tot een lijst of list. Daarmee verkrijgt u een aanzienlijke prestatieverbetering. Dit geldt vooral voor de schrijfbewerking, maar bij het lezen doemen de volgende valkuilen op. De onderstaande grafiek toont de tijd die nodig is om 50 records uit MemStore te lezen. Het lezen is in één thread gedaan en de horizontale as geeft het aantal sleutels in de query weer. Hier ziet u dat wanneer het aantal sleutels in één aanvraag toeneemt, de uitvoeringstijd afneemt, d.w.z. de snelheid toeneemt. Wanneer de MSLAB-modus echter standaard is ingeschakeld, beginnen de prestaties na deze drempelwaarde aanzienlijk af te nemen. Bovendien duurt het langer naarmate de hoeveelheid gegevens in het record groter is.
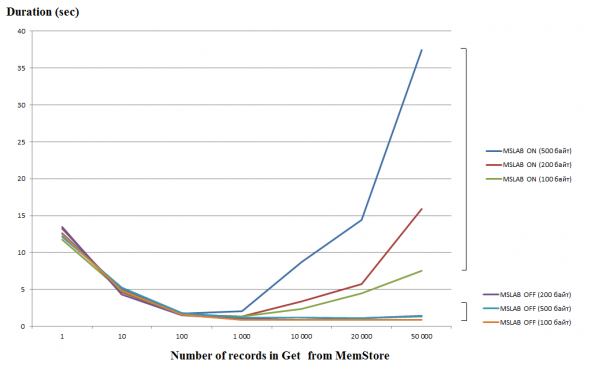
De tests werden uitgevoerd op een virtuele machine, 8 cores, HBase versie 2.0.0-cdh6.0.0-beta1.
De MSLAB-modus is ontworpen om heapfragmentatie te verminderen die ontstaat door het mengen van gegevens van nieuwe en oude generaties. Om dit probleem op te lossen, worden gegevens, wanneer MSLAB is ingeschakeld, in relatief kleine cellen (brokken) geplaatst en in delen verwerkt. Als gevolg hiervan nemen de prestaties sterk af wanneer het volume van het aangevraagde datapakket de toegewezen grootte overschrijdt. Aan de andere kant is het ook niet wenselijk om deze modus uit te schakelen, omdat dit tijdens periodes van intensief werken met data tot stops vanwege GC zal leiden. Een goede oplossing is om bij actief schrijven het celvolume te vergroten door het gelijktijdig te plaatsen met lezen. Het is belangrijk om op te merken dat het probleem zich niet voordoet als u na het opnemen de flush-opdracht uitvoert, waarmee MemStore naar schijf wordt leeggemaakt, of als u laadt met behulp van BulkLoad. Uit onderstaande tabel blijkt dat query's vanuit MemStore voor grotere (en dezelfde hoeveelheid) gegevens tot vertragingen leiden. Door de stukgrootte te vergroten, wordt de verwerkingstijd echter weer normaal.
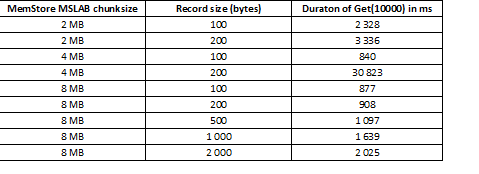
Naast het vergroten van de chunkgrootte helpt het ook om gegevens te splitsen per regio (tabelsplitsing). Hierdoor komen er minder verzoeken per regio binnen en als deze in de cel passen, blijft de respons goed.
6. Strategie voor het verdelen van tabellen in regio's (spilling)
Omdat HBase een sleutel-waardeopslag is en partitionering op sleutel plaatsvindt, is het uiterst belangrijk om gegevens gelijkmatig over alle regio's te verdelen. Wanneer u een dergelijke tabel bijvoorbeeld in drie delen opsplitst, worden de gegevens in drie regio's verdeeld:
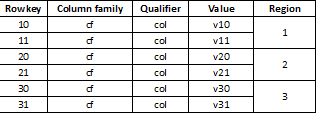
Dit kan soms leiden tot een scherpe vertraging als de later geladen gegevens bijvoorbeeld lange waarden zijn die grotendeels met hetzelfde nummer beginnen, bijvoorbeeld:
1000001
1000002
...
1100003
Omdat de sleutels worden opgeslagen als een byte-array, beginnen ze allemaal hetzelfde en behoren ze tot dezelfde regio #1 waarin dat sleutelbereik is opgeslagen. Er zijn verschillende partitioneringsstrategieën:
HexStringSplit – Converteert een sleutel naar een tekenreeks met hexadecimale codering in het bereik "00000000" => "FFFFFFFF" en opvulling met nullen aan de linkerkant.
UniformSplit – Verandert de sleutel in een byte-array met hexadecimale codering in het bereik "00" => "FF" en opvulling met nullen aan de rechterkant.
Bovendien kunt u een bereik of set sleutels voor splitsing opgeven en automatisch splitsen configureren. Een van de eenvoudigste en meest effectieve benaderingen is echter UniformSplit en het gebruik van hash-samenvoeging, bijvoorbeeld het senior paar bytes van het uitvoeren van de sleutel via de CRC32(rowkey)-functie en de rowkey zelf:
hash + rijtoets
Dan worden alle gegevens gelijkmatig over de regio's verdeeld. Bij het lezen worden de eerste twee bytes simpelweg weggegooid en blijft de originele sleutel behouden. RS beheert bovendien de hoeveelheid gegevens en sleutels in de regio en splitst deze automatisch in delen als de limieten worden overschreden.
7. Fouttolerantie en datalokaliteit
Omdat elke sleutelset slechts verantwoordelijk is voor één regio, is de oplossing voor problemen die samenhangen met RS-crashes of -uitschakeling, het opslaan van alle benodigde gegevens in HDFS. Wanneer RS faalt, detecteert de master dit doordat er geen heartbeat is op het ZooKeeper-knooppunt. Vervolgens wordt het bediende gebied toegewezen aan een andere RS en aangezien de HFiles zijn opgeslagen in een gedistribueerd bestandssysteem, kan de nieuwe eigenaar ze lezen en de gegevens blijven serveren. Omdat sommige gegevens zich echter in MemStore bevinden en geen tijd hebben gehad om naar HFiles te gaan, wordt WAL, dat ook in HDFS is opgeslagen, gebruikt om de geschiedenis van de bewerkingen te herstellen. Nadat de wijzigingen zijn doorgevoerd, kan RS op verzoeken reageren, maar de verhuizing heeft tot gevolg dat een deel van de gegevens en de processen die deze bedienen, zich op andere knooppunten bevinden. De lokaliteit neemt dus af.
De oplossing voor dit probleem is grote compactie: bij deze procedure worden bestanden verplaatst naar de knooppunten die er verantwoordelijk voor zijn (waar hun regio's zich bevinden). Als gevolg hiervan neemt de belasting van het netwerk en de schijven tijdens deze procedure sterk toe. In de toekomst zal de toegang tot gegevens echter merkbaar sneller worden. Bovendien voert major_compaction een samenvoeging uit van alle HFiles tot één bestand binnen een regio en schoont de gegevens op, afhankelijk van de tabelinstellingen. U kunt bijvoorbeeld opgeven hoeveel versies van een object bewaard moeten blijven, of wat de levensduur is waarna het object fysiek wordt verwijderd.
Deze procedure kan een zeer positieve invloed hebben op de prestaties van HBase. De onderstaande afbeelding laat zien hoe de prestaties zijn afgenomen als gevolg van het veelvuldig schrijven van gegevens. Hier ziet u hoe 40 threads gegevens naar één tabel schreven en 40 threads tegelijkertijd gegevens lazen. Schrijfthreads genereren steeds meer HFiles, die door andere threads worden gelezen. Hierdoor moeten er steeds meer gegevens uit het geheugen worden verwijderd, totdat de GC op een gegeven moment begint te werken en al het werk praktisch lamlegt. Door een grote verdichtingsoperatie uit te voeren, werden de opgebouwde blokkades opgeruimd en werd de productiviteit hersteld.
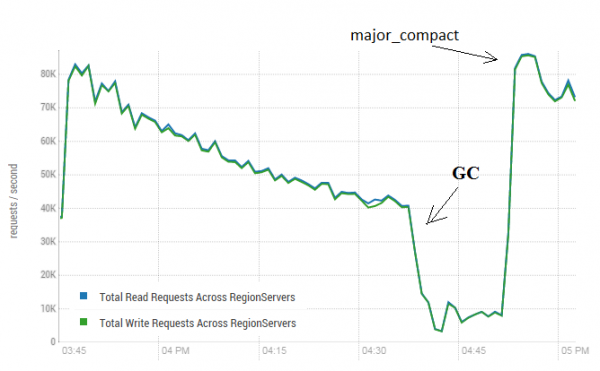
De test werd uitgevoerd op 3 DataNodes en 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads). HBase-versie 1.2.0-cdh5.14.2
Het is opmerkelijk dat de grote verdichting werd gestart op een ‘live’ tabel, waarin actief gegevens werden geschreven en gelezen. Er werd online beweerd dat dit tot een onjuiste respons zou kunnen leiden bij het lezen van de gegevens. Om dit te testen, werd een proces gestart dat nieuwe gegevens genereerde en naar de tabel schreef. Hierna heb ik het meteen gelezen en gecontroleerd of de ontvangen waarde overeenkomt met wat er geschreven stond. Tijdens de uitvoering van dit proces werd een grote verdichting ongeveer 200 keer uitgevoerd en er werd geen enkele mislukking geregistreerd. Mogelijk doet het probleem zich zelden voor en alleen tijdens een hoge belasting. In dat geval is het veiliger om de schrijf- en leesprocessen routinematig te stoppen en een reiniging uit te voeren om dergelijke GC-uitval te voorkomen.
Bovendien heeft een grote verdichting geen invloed op de status van MemStore; om het naar schijf te wissen en te comprimeren, moet u flush(connection.getAdmin().flush(TableName.valueOf(tblName))) gebruiken.
8. Instellingen en prestaties
Zoals gezegd is HBase het meest succesvol wanneer het niets hoeft te doen, zoals bij BulkLoad. Dit geldt echter voor de meeste systemen en mensen. Deze tool is echter meer geschikt voor het plaatsen van grote hoeveelheden gegevens in grote blokken. Als het proces meerdere gelijktijdige lees- en schrijfverzoeken vereist, worden de hierboven beschreven opdrachten Get en Put gebruikt. Om de optimale parameters te bepalen, werden runs uitgevoerd met verschillende combinaties van tabelparameters en instellingen:
- Er zijn 10 threads tegelijkertijd 3 keer achter elkaar gestart (laten we dit een thread block noemen).
- De looptijd van alle threads in een blok werd gemiddeld en was het uiteindelijke resultaat van de bewerking van het blok.
- Alle threads werkten met dezelfde tabel.
- Vóór de lancering van elk draadblok werd een grote verdichting uitgevoerd.
- Elk blok voerde slechts één van de volgende bewerkingen uit:
- Neerzetten
-Krijgen
— Krijgen+Zet
- Elk blok voerde 50 herhalingen van zijn bewerking uit.
- De recordgrootte in een blok is 100 bytes, 1000 bytes of 10000 bytes (willekeurig).
- De blokken werden gelanceerd met verschillende aantallen aangevraagde sleutels (één sleutel of 10).
- De blokken werden gespeeld met verschillende tafelopstellingen. De parameters zijn gewijzigd:
— BlockCache = aan of uit
— Blokgrootte = 65 KB of 16 KB
— Partities = 1, 5 of 30
— MSLAB = ingeschakeld of uitgeschakeld
Het blok ziet er dus zo uit:
A. MSLAB-modus is in-/uitgeschakeld.
B. Er werd een tabel gemaakt met de volgende parameters: BlockCache = true/none, BlockSize = 65/16 Kb, Partitions = 1/5/30.
C. GZ-compressie is ingesteld.
D. Er zijn 10 threads gelijktijdig gestart die 1/10 put/get/get+put-bewerkingen in deze tabel uitvoeren met records van 100/1000/10000 bytes en 50 verzoeken achter elkaar uitvoeren (willekeurige sleutels).
e. Punt d werd drie keer herhaald.
F. De looptijd van alle threads werd gemiddeld.
Alle mogelijke combinaties werden getest. Het is te verwachten dat de snelheid afneemt naarmate de recordgrootte toeneemt, of dat het uitschakelen van de caching voor vertragingen zorgt. Het doel was echter om de mate en het belang van de invloed van elke parameter te begrijpen. Daarom werden de verzamelde gegevens ingevoerd als invoer voor een lineaire regressiefunctie, waardoor het mogelijk is om de betrouwbaarheid te beoordelen met behulp van t-statistieken. Hieronder ziet u de resultaten van de blokken die Put-bewerkingen uitvoeren. De volledige set combinaties is 2*2*3*2*3 = 144 opties + 72 omdat sommige combinaties twee keer zijn uitgevoerd. In totaal zijn er dus 216 lanceringen:
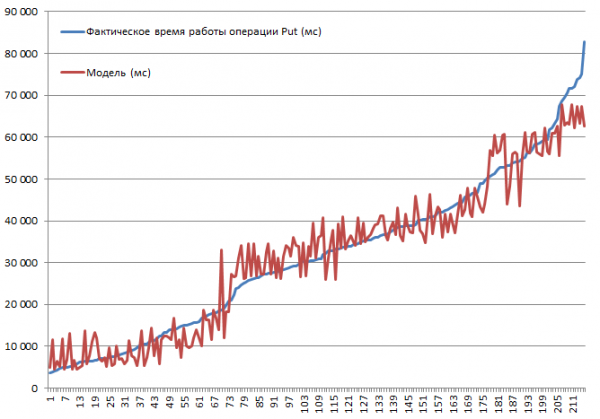
De tests werden uitgevoerd op een minicluster bestaande uit 3 DataNodes en 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads). HBase versie 1.2.0-cdh5.14.2.
De hoogste invoegsnelheid van 3.7 sec werd behaald met de MSLAB-modus uitgeschakeld, op een tabel met één partitie, met BlockCache ingeschakeld, BlockSize = 16, met records van 100 bytes en 10 stuks per batch.
De laagste invoegsnelheid van 82.8 sec werd verkregen met de MSLAB-modus ingeschakeld, op een tabel met één partitie, met BlockCache ingeschakeld, BlockSize = 16 en met records van 10000 bytes, 1 per record.
Laten we nu eens naar het model kijken. We zien dat de kwaliteit van het model volgens R2 goed is, maar het is duidelijk dat extrapolatie hier gecontra-indiceerd is. Het werkelijke gedrag van het systeem bij het wijzigen van parameters zal niet lineair zijn; Dit model is niet nodig voor voorspellingen, maar om te begrijpen wat er binnen de gegeven parameters is gebeurd. Hier zien we bijvoorbeeld uit het criterium van de student dat de parameters BlockSize en BlockCache er niet toe doen voor de Put-bewerking (die over het algemeen behoorlijk voorspelbaar is):

Maar dat het verhogen van het aantal partities leidt tot een afname van de prestaties, komt enigszins onverwacht (we hebben al het positieve effect gezien van het verhogen van het aantal partities tijdens BulkLoad), maar is wel begrijpelijk. Ten eerste is het voor de verwerking noodzakelijk om verzoeken te richten aan 30 regio's in plaats van aan één regio. De hoeveelheid gegevens is echter niet zodanig dat dit enig voordeel zou opleveren. Ten tweede wordt de totale looptijd bepaald door de langzaamste RS. Omdat het aantal DataNodes kleiner is dan het aantal RS, hebben sommige regio's een nullokaliteit. Laten we eens naar de top vijf kijken:

Laten we nu de resultaten van het uitvoeren van Get-blokken evalueren:

Het aantal partities heeft zijn betekenis verloren, wat waarschijnlijk te verklaren is doordat de gegevens goed in de cache zijn opgeslagen en de leescache de (statistisch gezien) meest significante parameter is. Het verhogen van het aantal berichten in een aanvraag heeft uiteraard ook een positief effect op de prestaties. Beste resultaten:

Laten we tot slot eens kijken naar het model van het blok dat eerst 'get' en vervolgens 'put' uitvoerde:

Alle parameters zijn hier van belang. En de resultaten van de leiders:

9. Belastingstesten
Nou, uiteindelijk lanceren we een min of meer behoorlijke lading, maar het is altijd interessanter als er iets is om mee te vergelijken. Op de website van DataStax, de belangrijkste ontwikkelaar van Cassandra, staat NT van een aantal NoSQL-opslaglocaties, waaronder HBase versie 0.98.6-1. Het downloaden werd uitgevoerd in 40 threads, datagrootte 100 bytes, SSD-schijven. De resultaten van de tests met Read-Modify-Write-bewerkingen lieten de volgende resultaten zien.
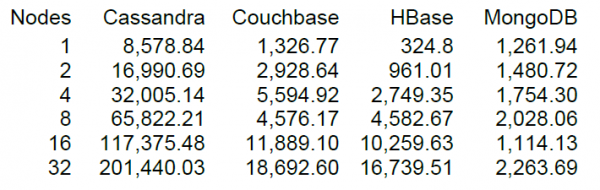
Voor zover ik weet, werd het lezen gedaan in blokken van 100 records en voor 16 HBase-knooppunten liet de DataStax-test een prestatie zien van 10 bewerkingen per seconde.
Het is een geluk dat ons cluster ook 16 knooppunten heeft, maar het is niet zo "gelukkig" dat elk 64 cores (threads) heeft, terwijl er in de DataStax-test maar 4 zijn. Aan de andere kant hebben ze SSD-schijven, en wij hebben HDD en een nieuwere versie van HBase, en het CPU-gebruik tijdens belasting nam praktisch niet significant toe (visueel met 5-10 procent). Laten we het eens op deze configuratie proberen. De standaard tabelinstellingen zijn dat het lezen willekeurig plaatsvindt binnen een bereik van sleutels van 0 tot 50 miljoen (d.w.z. in feite elke keer een nieuwe sleutel). De tabel bevat 50 miljoen records, verdeeld over 64 partities. Sleutels worden gehasht met behulp van crc32. De tabelinstellingen zijn standaard, MSLAB is ingeschakeld. Start 40 threads, elke thread leest een set van 100 willekeurige sleutels en schrijft de gegenereerde 100 bytes onmiddellijk terug naar deze sleutels.
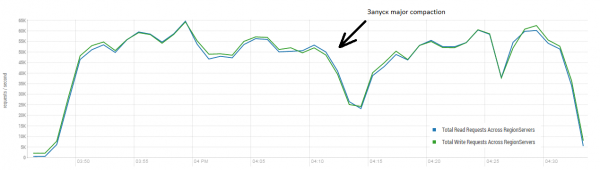
Standaard: 16 DataNodes en 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads). HBase versie 1.2.0-cdh5.14.2.
Het gemiddelde resultaat ligt dichter bij de 40 bewerkingen per seconde, wat aanzienlijk beter is dan in de DataStax-test. Voor experimentele doeleinden kunnen de omstandigheden echter enigszins worden gewijzigd. Het is zeer onwaarschijnlijk dat alle werkzaamheden uitsluitend met één tabel en ook alleen met unieke sleutels worden uitgevoerd. Laten we aannemen dat er een set 'hete' sleutels is die de hoofdbelasting genereert. Laten we daarom proberen om een lading grotere records (10 KB) te creëren, eveneens in batches van 100, in 4 verschillende tabellen en het bereik van de gevraagde sleutels te beperken tot 50 duizend. De grafiek hieronder toont de lancering van 40 threads. Elke thread leest een set van 100 sleutels en schrijft onmiddellijk willekeurig 10 KB terug voor deze sleutels.
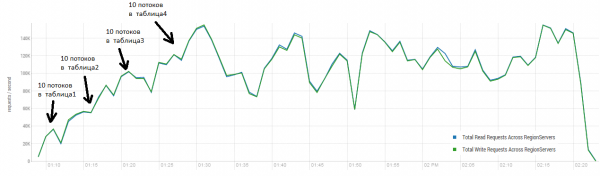
Standaard: 16 DataNodes en 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads). HBase versie 1.2.0-cdh5.14.2.
Tijdens het laden werd de grote verdichting meerdere malen uitgevoerd, zoals hierboven weergegeven. Zonder deze procedure zouden de prestaties geleidelijk afnemen, maar tijdens de uitvoering vindt er ook extra belasting plaats. Terugval kan om verschillende redenen voorkomen. Soms werden threads beëindigd en was er een pauze terwijl ze opnieuw werden opgestart. Soms werd het cluster belast door applicaties van derden.
Direct lezen en schrijven is een van de meest veeleisende workflows voor HBase. Als u alleen kleine put-verzoeken maakt, bijvoorbeeld van 100 bytes per verzoek, en deze combineert in batches van 10-50 stuks, kunt u honderdduizenden bewerkingen per seconde uitvoeren. Voor read-only verzoeken geldt een vergelijkbare situatie. Het is opmerkelijk dat de resultaten aanzienlijk beter zijn dan die van DataStax. Dit is voornamelijk te danken aan query's in 50 blokken.
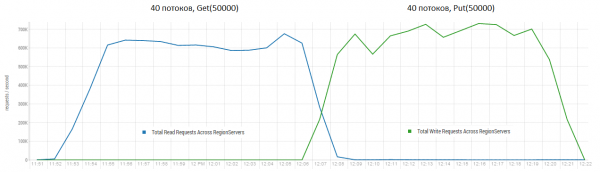
Standaard: 16 DataNodes en 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 threads). HBase versie 1.2.0-cdh5.14.2.
10. Conclusies
Dit systeem is behoorlijk flexibel te configureren, maar de invloed van een groot aantal parameters is nog onbekend. Een aantal daarvan werd getest, maar maakte geen deel uit van de definitieve testset. Uit voorlopige experimenten bleek bijvoorbeeld dat een parameter als DATA_BLOCK_ENCODING weinig betekenis heeft. Deze parameter codeert informatie met behulp van waarden uit aangrenzende cellen, wat begrijpelijk is voor willekeurig gegenereerde gegevens. Bij gebruik van een groot aantal herhalende objecten kunnen de voordelen aanzienlijk zijn. Over het algemeen kan gezegd worden dat HBase de indruk wekt een behoorlijk serieuze en goed doordachte database te zijn, die behoorlijk productief kan zijn bij het werken met grote hoeveelheden data. Vooral als er een mogelijkheid is om het lees- en schrijfproces in de tijd te scheiden.
Als u vindt dat iets niet voldoende beschreven is, vertel ik u er graag meer over. Wij nodigen u uit om uw ervaringen te delen of om in discussie te gaan als u het ergens niet mee eens bent.
Bron: www.habr.com
