


Netflix is marktleider op het gebied van internettelevisie. Het bedrijf heeft dit segment gecreëerd en is er nog steeds mee bezig. Netflix staat niet alleen bekend om zijn enorme aanbod aan films en tv-series, die beschikbaar zijn in vrijwel alle uithoeken van de wereld en op elk apparaat met een beeldscherm, maar ook om zijn robuuste infrastructuur en unieke technische cultuur.
Het illustratieve voorbeeld van Netflix's aanpak voor het ontwikkelen en ondersteunen van complexe systemen werd gepresenteerd op DevOops 2019 — Directeur ontwikkeling bij Netflix. Afgestudeerd aan de faculteit computerwiskunde en cybernetica van de Staatsuniversiteit van Nizjni Novgorod. Lobachevsky, Sergey is een van de eerste engineers in het Open Connect - CDN-team bij Netflix. Hij bouwde systemen voor het monitoren en analyseren van videodata, lanceerde de populaire internetsnelheidstestdienst FAST.com en hield zich de afgelopen jaren bezig met het optimaliseren van internetaanvragen om de Netflix-app zo snel mogelijk te laten werken voor gebruikers.
Het rapport werd door de conferentiedeelnemers uitstekend ontvangen. We hebben een tekstversie voor u voorbereid.

In zijn rapport sprak Sergei uitgebreid
- over wat de vertraging van internetaanvragen tussen de client en de server beïnvloedt;
- hoe deze vertraging kan worden beperkt;
- hoe u fouttolerante systemen ontwerpt, onderhoudt en bewaakt;
- hoe je in een kort tijdsbestek en met minimale risico's voor het bedrijf resultaten kunt behalen;
- hoe je resultaten analyseert en van fouten leert.
Antwoorden op deze vragen zijn niet alleen nodig voor mensen die in grote ondernemingen werken.
De gepresenteerde principes en technieken zouden bekend en in de praktijk gebracht moeten worden door iedereen die internetproducten ontwikkelt en ondersteunt.
Hieronder volgt een verhaal vanuit het perspectief van de spreker.
Het belang van internetsnelheid
De snelheid van internetverzoeken houdt rechtstreeks verband met zakendoen. Denk aan de winkelwereld: Amazon in 2009 dat een vertraging van 100 ms resulteert in een omzetverlies van 1%.
Er zijn steeds meer mobiele apparaten en mobiele sites en applicaties volgen snel. Als uw pagina langer dan 3 seconden nodig heeft om te laden, verliest u ongeveer de helft van uw gebruikers. MET Google houdt rekening met de snelheid waarmee uw pagina laadt in de zoekresultaten: hoe sneller de pagina, hoe hoger de positie in Google.
De verbindingssnelheid is ook belangrijk in financiële instellingen, waar latentie van cruciaal belang is. In 2015 heeft Hibernia Networks een kabel van 400 miljoen dollar tussen New York en Londen om de latentie tussen de steden met 6 ms te verminderen. Stel je $66 miljoen voor voor een latentiereductie van 1 ms!
Volgens hebben verbindingssnelheden boven de 5 Mbps geen directe invloed meer op de laadsnelheid van een typische website. Er bestaat echter een lineair verband tussen verbindingslatentie en de snelheid waarmee pagina's worden geladen:
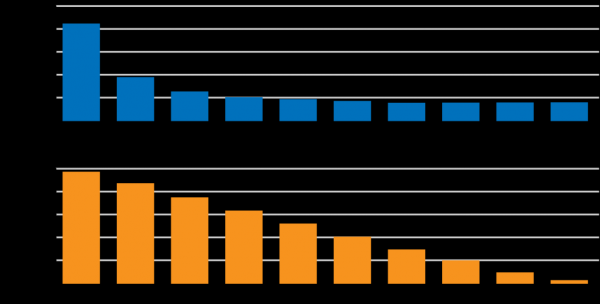
Netflix is echter geen typisch product. De impact van latentie en snelheid op de gebruiker is een gebied waar actief onderzoek en ontwikkeling aan wordt gedaan. Er zijn apps die laden en content selecteren die worden beïnvloed door latentie, maar het laden van statische items en streaming worden ook beïnvloed door de verbindingssnelheid. Het analyseren en optimaliseren van de belangrijkste factoren die de gebruikerservaring beïnvloeden, is een actief ontwikkelingsgebied voor verschillende teams bij Netflix. Een van de doelen is om de latentie van verzoeken tussen Netflix-apparaten en de cloudinfrastructuur te verminderen.
In deze presentatie richten we ons specifiek op het verminderen van latentie, waarbij we de infrastructuur van Netflix als voorbeeld gebruiken. Laten we eens praktisch kijken naar de aanpak van het ontwerp, de ontwikkeling en de bediening van complexe gedistribueerde systemen. Laten we tijd besteden aan innovatie en resultaten, in plaats van aan het diagnosticeren van operationele problemen en storingen.
Binnen Netflix
Duizenden verschillende apparaten ondersteunen Netflix-apps. Deze worden ontwikkeld door vier verschillende teams, die elk aparte clientversies maken voor elk apparaat. Android, iOS, tv en webbrowsers. We werken er ook hard aan om de gebruikerservaring te verbeteren en te personaliseren. Om dit te bereiken, voeren we honderden A/B-tests parallel uit.
Personalisatie wordt ondersteund door honderden microservices in de AWS-cloud die gepersonaliseerde gegevens voor de gebruiker, verzoekverzending, telemetrie, Big Data en codering bieden. De verkeersvisualisatie ziet er als volgt uit:
Links ziet u het toegangspunt. Vervolgens wordt het verkeer verdeeld over enkele honderden microservices die door verschillende backendteams worden ondersteund.
Een ander belangrijk onderdeel van onze infrastructuur is Open Connect CDN, dat statische content levert aan de eindgebruiker, zoals video's, afbeeldingen, code voor clients, enzovoort. CDN bevindt zich op aangepaste servers (OCA - Open Connect Appliance). Binnenin bevinden zich arrays van SSD- en HDD-schijven waarop geoptimaliseerd FreeBSD draait, met NGINX en een reeks services. Wij ontwerpen en optimaliseren hardware- en softwarecomponenten zodanig dat zo’n CDN-server zoveel mogelijk data naar de gebruikers kan sturen.
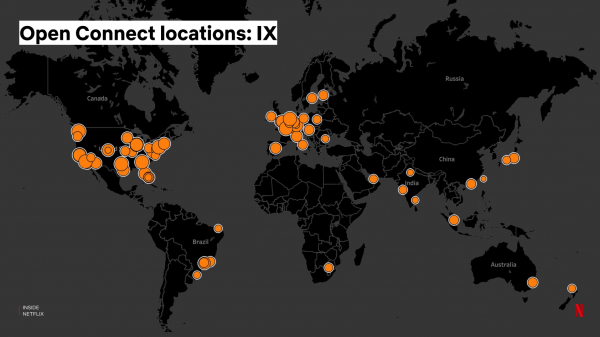
De "muur" van deze servers op de Internet eXchange (IX) ziet er als volgt uit:

Via Internet Exchange kunnen internetproviders en contentproviders met elkaar 'verbinding maken', zodat ze directer gegevens op internet kunnen uitwisselen. Wereldwijd zijn er ongeveer 70-80 Internet Exchange-punten waar onze servers zijn geïnstalleerd. Wij verzorgen de installatie en het onderhoud ervan zelf:
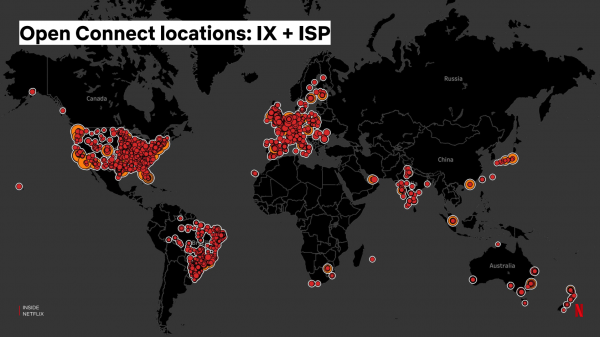
Daarnaast leveren we ook rechtstreeks servers aan internetproviders, die zij in hun netwerk installeren. Hierdoor wordt de lokalisatie van Netflix-verkeer en de kwaliteit van de streaming voor gebruikers verbeterd:
De AWS-services zijn verantwoordelijk voor het verzenden van videoverzoeken van clients naar CDN-servers en voor het configureren van de servers zelf, zoals het bijwerken van inhoud, programmacode, instellingen, enzovoort. Voor dat laatste hebben we ook een backbone-netwerk gebouwd dat servers op Internet Exchange-locaties verbindt met AWS. Het backbonenetwerk is een wereldwijd netwerk van glasvezelkabels en routers die we naar onze behoeften kunnen ontwerpen en configureren.
Op Onze CDN-infrastructuur verzorgt ongeveer ⅛ van het wereldwijde internetverkeer tijdens piektijden en ⅓ van het verkeer in Noord-Amerika, waar Netflix al het langst actief is. Indrukwekkende cijfers, maar voor mij is één van de meest verbazingwekkende prestaties dat het gehele CDN-systeem wordt ontwikkeld en onderhouden door een team van nog geen 150 mensen.
Oorspronkelijk was de CDN-infrastructuur ontworpen om videodata te leveren. Na verloop van tijd kwamen we erachter dat we het ook konden gebruiken om dynamische verzoeken van klanten in de AWS-cloud te optimaliseren.
Over internetsnelheid verhogen
Momenteel heeft Netflix 3 AWS-regio's en de latentie van verzoeken naar de cloud is afhankelijk van de afstand van de klant tot de dichtstbijzijnde regio. Tegelijkertijd hebben we veel CDN-servers die worden gebruikt om statische content te leveren. Bestaat er een manier om deze infrastructuur te gebruiken om dynamische query's te versnellen? Helaas is het niet mogelijk om deze verzoeken te cachen: de API's zijn gepersonaliseerd en elk resultaat is uniek.
Laten we een proxy op de CDN-server maken en het verkeer erdoorheen sturen. Zal het sneller zijn?
Materieel deel
Laten we nog eens kijken hoe netwerkprotocollen werken. Tegenwoordig verloopt het meeste internetverkeer via HTTPS, dat afhankelijk is van de lager gelegen protocollen TCP en TLS. Om verbinding te maken met een server, maakt een client een handdruk. Om een beveiligde verbinding tot stand te brengen, moet de client drie keer berichten uitwisselen met de server en nog minimaal één keer om gegevens over te dragen. Met een round trip latency (RTT) van 100 ms duurt het 400 ms om de eerste bit aan gegevens te ontvangen:
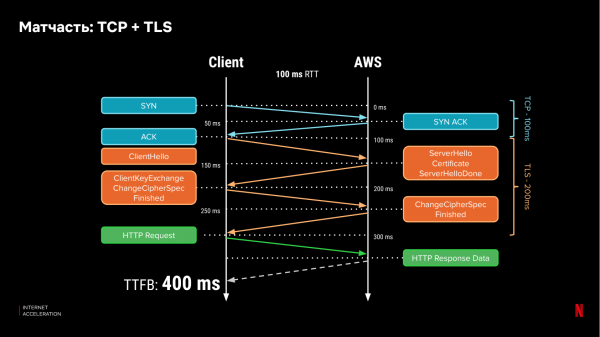
Als we de certificaten op een CDN-server plaatsen, kunnen we de 'handshake'-tijd tussen de client en de server aanzienlijk verkorten als het CDN dichterbij is. Laten we aannemen dat de latentie naar de CDN-server 30 ms is. Dan duurt het 220 ms voordat het eerste bit ontvangen wordt:
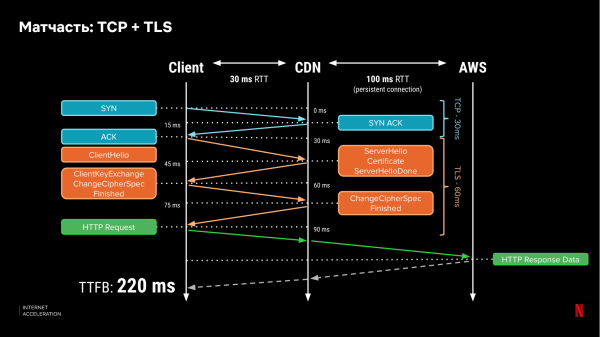
Maar de voordelen eindigen daar niet. Zodra een verbinding tot stand is gebracht, vergroot TCP het congestievenster (de hoeveelheid informatie die parallel via die verbinding kan worden verzonden). Als een datapakket verloren gaat, verkleinen klassieke TCP-protocolimplementaties (zoals TCP New Reno) het open "venster" met de helft. De groei van het congestievenster en de snelheid waarmee het verlies wordt hersteld, zijn afhankelijk van de vertraging (RTT) naar de server. Als deze verbinding alleen naar de CDN-server gaat, zal dit herstel sneller verlopen. Pakketverlies komt echter vaak voor, vooral in draadloze netwerken.
De internetbandbreedte kan afnemen, vooral tijdens piekuren vanwege het grote aantal gebruikers, wat tot verkeersopstoppingen kan leiden. Er is echter op internet geen mogelijkheid om bepaalde zoekopdrachten voorrang te geven boven andere. Geef bijvoorbeeld prioriteit aan kleine, latentiegevoelige verzoeken boven 'zware' gegevensstromen die het netwerk belasten. In ons geval is het echter zo dat we over een eigen backbone-netwerk beschikken, waardoor we dit op een deel van het aanvraagpad kunnen doen: tussen het CDN en de cloud. Bovendien kunnen we dit volledig configureren. Het is mogelijk om kleine en latentiegevoelige pakketten voorrang te geven, terwijl grotere gegevensstromen iets later aankomen. Hoe dichter het CDN bij de client staat, hoe efficiënter het is.
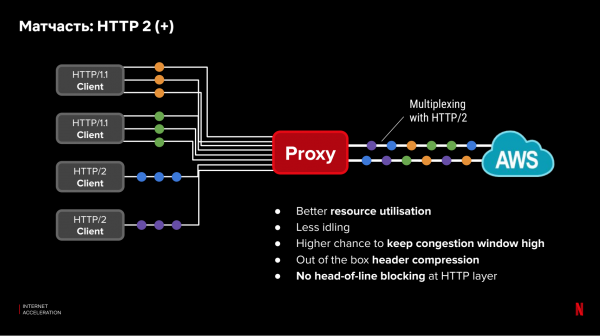
Protocollen op applicatieniveau (OSI-niveau 7) hebben ook invloed op de vertraging. Nieuwe protocollen zoals HTTP/2 maken het mogelijk de prestaties van parallelle verzoeken te optimaliseren. Er zijn echter Netflix-clients met oudere apparaten die de nieuwe protocollen niet ondersteunen. Niet alle clients kunnen worden bijgewerkt of optimaal worden geconfigureerd. Tegelijkertijd heeft u tussen de CDN-proxy en de cloud volledige controle en de mogelijkheid om nieuwe, optimale protocollen en instellingen te gebruiken. Het inefficiënte deel van oude protocollen werkt alleen tussen de client en de CDN-server. Bovendien kunnen we verzoeken multiplexen op een reeds bestaande verbinding tussen het CDN en de cloud, waardoor het verbindingsgebruik op TCP-niveau wordt verbeterd:
Wij meten
Hoewel de theorie verbeteringen belooft, gaan we niet meteen over tot de productie van het systeem. In plaats daarvan moeten we eerst bewijzen dat het idee in de praktijk werkt. Om dit te doen, moet u een aantal vragen beantwoorden:
- snelheid: Zal een proxy sneller zijn?
- Betrouwbaarheid: Gaat het vaker kapot?
- Ingewikkeldheid: hoe integreren met applicaties?
- kostenHoeveel kost het om extra infrastructuur te implementeren?
Laten we onze aanpak voor de beoordeling van het eerste punt eens nader bekijken. De rest wordt op een vergelijkbare manier behandeld.
Om de verzoeksnelheid te analyseren, willen we gegevens van alle gebruikers verzamelen, niet te veel tijd besteden aan ontwikkeling en de productie niet onderbreken. Er zijn verschillende benaderingen hiervoor:
- RUM, of passieve querymeting. Wij meten de uitvoeringstijd van actuele verzoeken van gebruikers en zorgen ervoor dat alle gebruikers gedekt zijn. Nadeel: signaal is niet erg stabiel vanwege meerdere factoren, zoals verschillende aanvraaggroottes en verwerkingstijd op de server en de client. Bovendien is het niet mogelijk om een nieuwe configuratie te testen zonder dat dit gevolgen heeft voor de productie.
- Laboratoriumtests. Speciale servers en infrastructuur die clients simuleren. Met hun hulp voeren wij de nodige testen uit. Zo krijgen we volledige controle over de meetresultaten en een duidelijk signaal. Maar er is geen volledige dekking van apparaten en gebruikerslocaties (vooral niet met een wereldwijde service en ondersteuning voor duizenden apparaatmodellen).
Hoe kunnen we de voordelen van beide methoden combineren?
Ons team heeft een oplossing gevonden. We schreven een klein stukje code - een voorbeeld - dat we in onze applicatie integreerden. Met probes kunnen we volledig gecontroleerd netwerktesten uitvoeren vanaf onze apparaten. Het werkt als volgt:
- Kort nadat we de app hebben gedownload en de eerste activiteit hebben voltooid, starten we met onze tests.
- De cliënt doet een verzoek aan de server en ontvangt een testrecept. Een recept is een lijst met URL's waarnaar een HTTP(s)-verzoek moet worden verzonden. Bovendien configureert het recept de aanvraagparameters: vertragingen tussen aanvragen, de hoeveelheid opgevraagde gegevens, HTTP(s)-headers, enz. Tegelijkertijd kunnen we verschillende recepten parallel testen: wanneer er een configuratieaanvraag wordt gedaan, bepalen we willekeurig welk recept we uitgeven.
- Het tijdstip waarop de test wordt gestart, wordt zo gekozen dat er geen conflict ontstaat met het actieve gebruik van netwerkbronnen op de client. In principe wordt er een tijdstip geselecteerd waarop de client niet actief is.
- Nadat de client het recept heeft ontvangen, stuurt hij parallel verzoeken naar elk van de URL's. Het verzoek aan elk van de adressen kan worden herhaald - de zogenaamde "pulsen". Bij de eerste puls meten we hoe lang het duurt om een verbinding tot stand te brengen en gegevens te downloaden. Bij de tweede puls meten we de tijd die nodig is om gegevens te downloaden via een reeds bestaande verbinding. Vóór de derde kunnen we een vertraging instellen en de snelheid meten waarmee de verbinding tot stand wordt gebracht, etc.
Tijdens de test meten we alle parameters die het apparaat kan verkrijgen:
- DNS-querytijd;
- Tijd voor het tot stand brengen van de TCP-verbinding;
- Tijd voor het tot stand brengen van de TLS-verbinding;
- tijd om de eerste byte aan gegevens te ontvangen;
- totale laadtijd;
- statusresultaatcode.
- Nadat alle pulsen zijn voltooid, downloadt het monster de resultaten van alle metingen voor analyse.
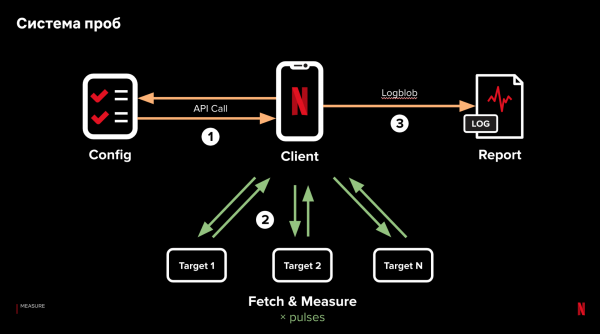
De belangrijkste punten zijn minimale afhankelijkheid van client-side logica, server-side gegevensverwerking en meting van parallelle verzoeken. Op deze manier kunnen we de impact van verschillende factoren die de queryprestaties beïnvloeden isoleren en testen, ze binnen één recept variëren en resultaten van echte klanten krijgen.
Deze infrastructuur blijkt niet alleen nuttig voor queryprestatieanalyses. Momenteel hebben we 14 actieve recepten, meer dan 6000 samples per seconde, ontvangen we gegevens uit alle hoeken van de wereld en hebben we een volledige apparaatdekking. Als Netflix een vergelijkbare dienst van een derde partij zou kopen, zou dat miljoenen dollars per jaar kosten en de dekking zou veel slechter zijn.
Theorie testen in de praktijk: prototype
Met een dergelijk systeem konden we de efficiëntie van CDN-proxy's evalueren op het gebied van aanvraaglatentie. Nu moet je het volgende doen:
- een proxy-prototype maken;
- een prototype hosten op een CDN;
- bepalen hoe clients naar een proxy op een specifieke CDN-server moeten worden geleid;
- prestaties vergelijken met AWS-query's zonder proxy.
Het is de bedoeling om zo snel mogelijk de effectiviteit van de voorgestelde oplossing te evalueren. Wij kozen voor Go om het prototype te implementeren vanwege de goede netwerkbibliotheken. Op elke CDN-server hebben we het proxyprototype geïnstalleerd als een statisch binair bestand om afhankelijkheden te minimaliseren en integratie te vereenvoudigen. Bij de eerste implementatie hebben we zoveel mogelijk gebruikgemaakt van standaardcomponenten en kleine aanpassingen gedaan voor HTTP/2-verbindingspooling en aanvraagmultiplexing.
Om de load balancing over de verschillende AWS-regio's te regelen, maakten we gebruik van een geografische DNS-database. Dit is dezelfde database die we gebruiken om de load balancing van clients te regelen. Om een CDN-server voor een client te selecteren, gebruiken we TCP Anycast voor servers in Internet Exchange (IX). Bij deze optie gebruiken we één IP-adres voor alle CDN-servers. De client wordt doorgestuurd naar de CDN-server met het minste aantal IP-hops. In CDN-servers die door internetproviders (ISP's) zijn geïnstalleerd, hebben we geen controle over de router om TCP Anycast te configureren, dus gebruiken we , die klanten doorverwijst naar internetproviders voor videostreaming.
Er zijn dus drie soorten paden voor de aanvraag: naar de cloud via het open internet, via een CDN-server op de IX of via een CDN-server bij de ISP. Ons doel is om te begrijpen welk pad beter is en wat het voordeel is van proxyservers vergeleken met de manier waarop verzoeken in productie worden gerouteerd. Om dit te doen, gebruiken we het volgende testsysteem:
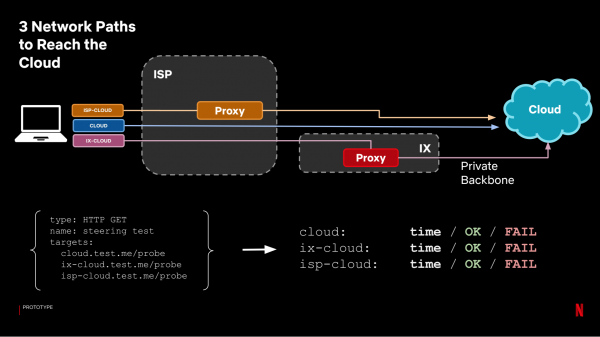
Elk pad wordt een apart doel en we kijken naar de tijd die we krijgen. Voor analyse combineren we proxyresultaten in één groep (we selecteren de beste tijd tussen IX en ISP-proxy) en vergelijken deze met de tijd van verzoeken aan de cloud zonder proxy:
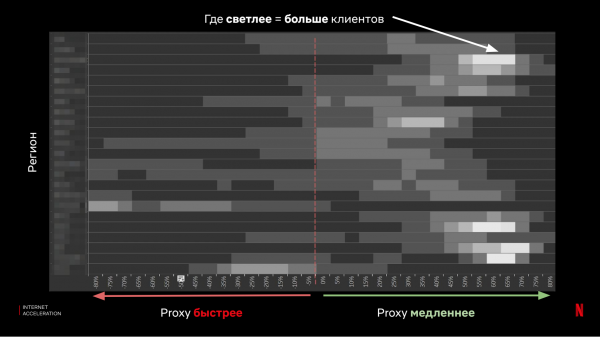
Zoals u kunt zien, waren de resultaten wisselend: in de meeste gevallen zorgt de proxy voor een goede versnelling, maar er zijn ook voldoende cliënten voor wie de situatie aanzienlijk zal verslechteren.
Uiteindelijk hebben we een paar belangrijke dingen gedaan:
- We hebben de verwachte prestaties van verzoeken van clients naar de cloud via een CDN-proxy geschat.
- We ontvingen gegevens van echte klanten, via allerlei soorten apparaten.
- We kwamen erachter dat de theorie niet 100% bevestigd was en dat het oorspronkelijke aanbod met CDN-proxy niet voor ons zou werken.
- We namen geen risico's - we veranderden de productieconfiguraties van klanten niet.
- Er was niets kapot.
Prototype 2.0
Dus gaan we terug naar de tekentafel en herhalen we het proces opnieuw.
Het idee is dat we in plaats van een 100% proxy, het snelste pad voor elke client bepalen en daarheen verzoeken sturen. We voeren dus client steering uit.
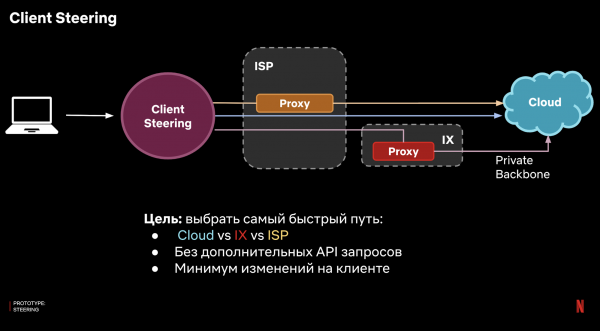
Hoe kunnen we dit implementeren? We kunnen geen logica gebruiken aan de serverkant, omdat het doel is om verbinding te maken met deze server. We moeten dit op de een of andere manier op de client doen. Idealiter gebeurt dit met zo min mogelijk complexe logica, zodat u zich geen zorgen hoeft te maken over de integratie met een groot aantal clientplatforms.
Het antwoord is om DNS te gebruiken. In ons geval beschikken we over onze eigen DNS-infrastructuur en kunnen we een domeinzone instellen waarvoor onze servers gezaghebbend zijn. Het werkt als volgt:
- De client doet een verzoek aan de DNS-server via een host, bijvoorbeeld api.netflix.xom.
- Het verzoek wordt verzonden naar onze DNS-server.
- De DNS-server weet welk pad voor deze client het snelste is en geeft het bijbehorende IP-adres uit.
De oplossing kent nog een extra complicatie: autoritaire DNS-providers zien het IP-adres van de client niet en kunnen alleen het IP-adres lezen van de recursieve resolver die de client gebruikt.
Hierdoor moet onze autoritaire resolver geen beslissingen nemen voor een individuele client, maar voor een groep clients op basis van de recursieve resolver.
Om dit op te lossen, gebruiken we dezelfde probes, voegen we de meetresultaten van clients samen voor elk van de recursieve resolvers en beslissen we waar we deze groep naartoe sturen: via een proxy via IX met TCP Anycast, via een ISP-proxy of rechtstreeks naar de cloud.
We krijgen het volgende systeem:
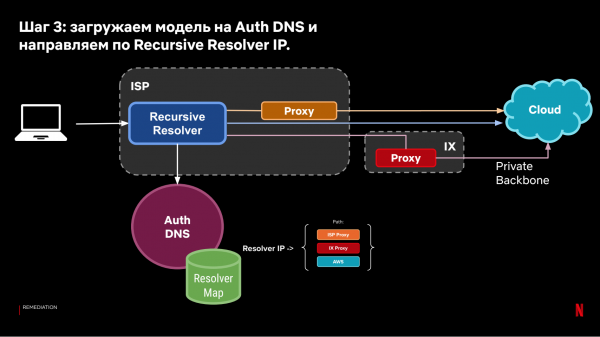
Met het resulterende DNS-stuurmodel kunnen clients worden aangestuurd op basis van historische observaties van verbindingssnelheden van clients naar de cloud.
De vraag is echter: hoe effectief zal deze aanpak zijn? Om deze vraag te beantwoorden, maken we opnieuw gebruik van ons proefsysteem. Daarom hebben we een recentieconfiguratie opgezet waarbij één van de doelen de richting van DNS-sturing volgt en het andere doel direct naar de cloud gaat (huidige productie).
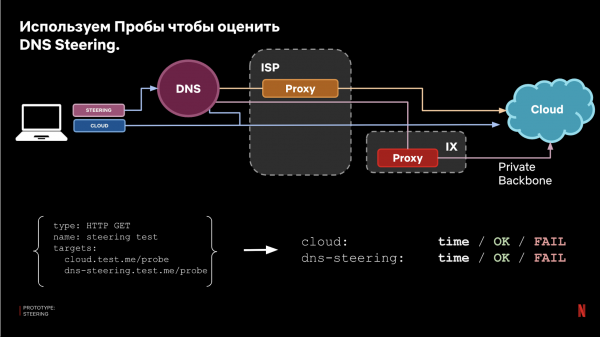
Naar aanleiding hiervan vergelijken we de resultaten en verkrijgen we een beoordeling van de effectiviteit:
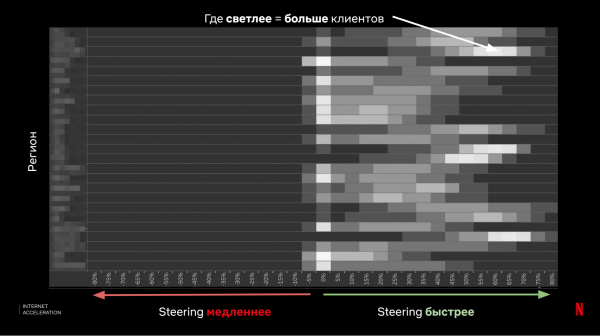
Uiteindelijk hebben we een paar belangrijke dingen geleerd:
- Met behulp van DNS Steering hebben we de verwachte prestaties van verzoeken van clients naar de cloud geschat.
- We ontvingen gegevens van echte klanten, via allerlei soorten apparaten.
- De effectiviteit van het voorgestelde idee is bewezen.
- We namen geen risico's - we veranderden de productieconfiguraties van klanten niet.
- Er was niets kapot.
Nu komen de moeilijke dingen: de productie starten
Het makkelijkste gedeelte hebben we nu achter de rug: we hebben een werkend prototype. Nu komt het moeilijkste gedeelte: het lanceren van de oplossing voor al het verkeer van Netflix, het implementeren ervan voor 150 miljoen gebruikers, duizenden apparaten, honderden microservices en een voortdurend veranderend product en infrastructuur. De servers van Netflix ontvangen miljoenen verzoeken per seconde en het is gemakkelijk om de service te verstoren door een onzorgvuldige actie. Tegelijkertijd willen we het verkeer dynamisch routeren via duizenden CDN-servers op internet, waar de zaken voortdurend veranderen en op de meest ongelegen momenten kapotgaan.
Het team bestaat uit 3 engineers die verantwoordelijk zijn voor de ontwikkeling, implementatie en volledige ondersteuning van het systeem.
Daarom gaan we verder in op een rustige en gezonde slaap.
Hoe kun je doorgaan met ontwikkelen zonder al je tijd te besteden aan ondersteuning? Onze aanpak is gebaseerd op 3 principes:
- Wij verkleinen de potentiële omvang van de storing (explosieradius).
- Wees voorbereid op verrassingen: wees ervan bewust dat er altijd wel iets kapot kan gaan, ondanks alle testen en persoonlijke ervaringen.
- Elegante degradatie: als iets kapot gaat, moet het zichzelf automatisch repareren, ook al is dat niet op de meest efficiënte manier.
Het bleek dat we met deze aanpak van het probleem een eenvoudige en effectieve oplossing konden vinden en de systeemondersteuning aanzienlijk konden vereenvoudigen. We realiseerden ons dat we een klein stukje code aan de client konden toevoegen en zo netwerkverzoekfouten konden monitoren die werden veroorzaakt door verbindingsproblemen. Bij netwerkfouten schakelen wij direct over naar de cloud. Deze oplossing vergt geen grote inspanning van de klantenteams, maar verkleint voor ons het risico op onverwachte storingen en verrassingen.
Natuurlijk hanteren we, ondanks deze terugval, nog steeds een strikte discipline tijdens de ontwikkeling:
- Voorbeeldtest.
- A/B-testen of Canaries.
- Geleidelijke uitrol.
De testaanpak werd beschreven: wijzigingen worden eerst getest met behulp van een aangepast recept.
Voor de Canary-test hebben we vergelijkbare paren servers nodig, zodat we kunnen vergelijken hoe het systeem vóór en na de wijzigingen werkt. Om dit te doen, selecteren we paren servers uit onze vele CDN-sites die vergelijkbaar verkeer ontvangen:
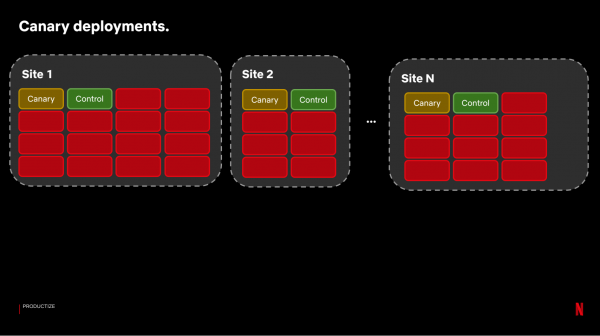
Vervolgens zetten we de build met de wijzigingen op de Canary-server. Om de resultaten te evalueren, gebruiken we een systeem dat ongeveer 100-150 statistieken vergelijkt met een steekproef van Control-servers:
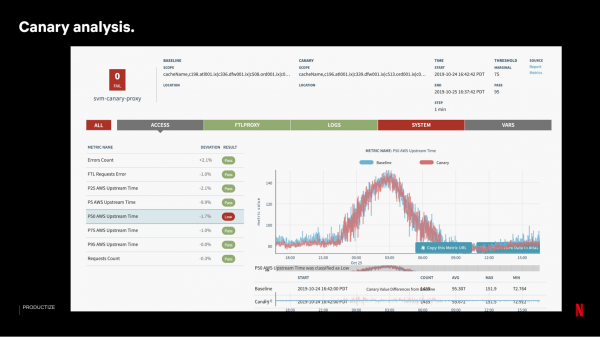
Als de tests met Canary succesvol zijn, brengen we het geleidelijk en in fases uit. We upgraden de servers niet op hetzelfde moment op elke site. Als een hele site door problemen uitvalt, heeft dat een grotere impact op de service voor gebruikers dan wanneer hetzelfde aantal servers op verschillende locaties uitvalt.
Over het algemeen hangen de effectiviteit en veiligheid van deze aanpak af van de kwantiteit en kwaliteit van de verzamelde gegevens. Voor ons queryversnellingssysteem verzamelen we statistieken van alle mogelijke componenten:
- van cliënten - aantal sessies en verzoeken, terugvalpercentages;
- proxy - statistieken over het aantal en de tijd van verzoeken;
- DNS - aantal en resultaten van verzoeken;
- cloud edge — het aantal en de tijd voor het verwerken van verzoeken in de cloud.
Dit alles wordt in één pijplijn verzameld en afhankelijk van de behoeften beslissen we welke statistieken we naar realtime-analyses sturen en welke naar Elasticsearch of Big Data voor meer gedetailleerde diagnostiek.
Wij monitoren

In ons geval brengen we wijzigingen aan in het kritieke pad van de verzoeken tussen de client en de server. Tegelijkertijd is het aantal verschillende componenten op de client, op de server en onderweg via internet enorm. Er vinden voortdurend wijzigingen plaats op de client en de server, omdat tientallen teams samenwerken en er natuurlijke veranderingen in het ecosysteem plaatsvinden. Wij bevinden ons in het midden: zodra er problemen worden vastgesteld, is de kans groot dat wij erbij betrokken worden. Daarom moeten we een goed begrip hebben van hoe we statistieken definiëren, verzamelen en analyseren om problemen snel te kunnen lokaliseren.
Ideaal: volledige toegang tot alle soorten statistieken en filters in realtime. Maar er zijn zoveel meetmethoden, dat de vraag naar de kosten rijst. In ons geval scheiden we metrische gegevens en ontwikkeltools als volgt:

Wij gebruiken ons eigen open source real-time systeem om problemen te detecteren en te beoordelen. и — voor visualisatie. Het slaat samengevoegde statistieken op in het geheugen, is betrouwbaar en integreert met het waarschuwingssysteem. Voor lokalisatie en diagnostiek hebben we toegang tot logs van Elasticsearch en Kibana. Voor statistische analyses en modellen gebruiken we big data en visualisatie in Tableau.
Het lijkt erop dat deze aanpak heel moeilijk is om mee te werken. Door statistieken en hulpmiddelen hiërarchisch te organiseren, kunnen we een probleem snel analyseren, het type probleem bepalen en vervolgens dieper ingaan op gedetailleerde statistieken. Over het algemeen besteden we 1 à 2 minuten aan het achterhalen van de oorzaak van de storing. Daarna werken we met een specifiek team aan de diagnostiek, van enkele tientallen minuten tot meerdere uren.
Ook al wordt de diagnose snel gesteld, toch willen we niet dat het te vaak gebeurt. Idealiter ontvangen we alleen een kritieke melding als er sprake is van een aanzienlijke impact op de dienstverlening. Voor ons queryversnellingssysteem zijn er slechts twee waarschuwingen die u op de hoogte stellen:
- Client Fallback percentage - beoordeling van klantgedrag;
- Percentage testfouten: gegevens over de stabiliteit van netwerkcomponenten.
Met deze belangrijke meldingen wordt gecontroleerd of het systeem voor de meeste gebruikers werkt. We kijken naar hoeveel klanten gebruik hebben gemaakt van fallback als ze geen aanvraagversnelling konden krijgen. Gemiddeld ontvangen we minder dan één kritieke waarschuwing per week, ondanks het feit dat het systeem enorm veel veranderingen ondergaat. Waarom is dit genoeg voor ons?
- Er is een terugvaloptie voor de client als onze proxy niet werkt.
- Er is een automatisch stuursysteem dat reageert op problemen.
Laten we daar eens wat dieper op ingaan. Dankzij ons peilsysteem en het systeem voor het automatisch bepalen van het optimale pad voor verzoeken van de klant naar de cloud, kunnen we bepaalde problemen automatisch oplossen.
Laten we teruggaan naar onze voorbeeldconfiguratie en de drie categorieën paden. Naast de laadtijd kunnen we ook kijken naar de bezorging zelf. Als het laden van de gegevens mislukt, kunnen we door naar de resultaten voor verschillende paden te kijken, bepalen waar en wat er kapot is gegaan. Ook kunnen we bepalen of we het probleem automatisch kunnen oplossen door het aanvraagpad te wijzigen.
Voorbeelden:
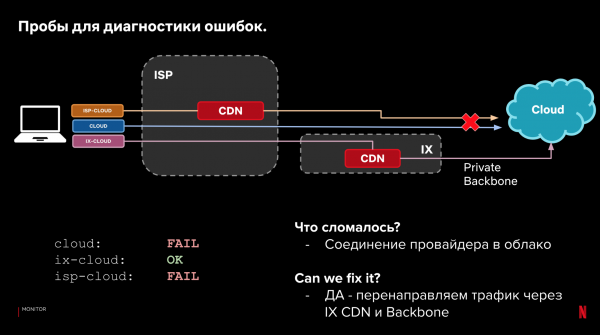
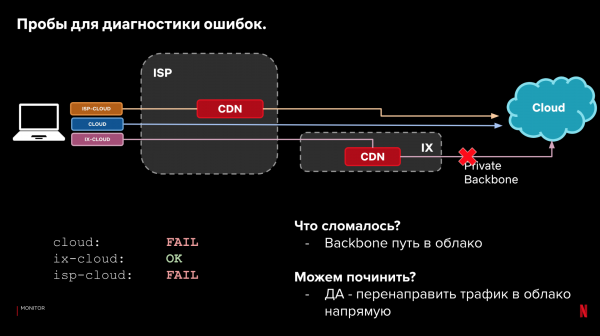
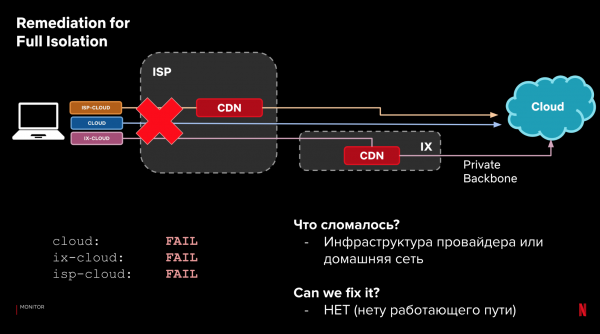
Dit proces kan geautomatiseerd worden. Neem het op in het stuursysteem. En leer het te reageren op prestatie- en betrouwbaarheidsproblemen. Als er iets kapot gaat, reageer dan als er een betere optie is. Tegelijkertijd is de onmiddellijke reactie niet kritisch, dankzij de terugvaloptie op klanten.
De principes van systeemondersteuning kunnen dus als volgt worden geformuleerd:
- wij verkleinen de omvang van storingen;
- wij verzamelen statistieken;
- wij verhelpen storingen automatisch als we dat kunnen;
- als dat niet kan, melden wij dat;
- We werken aan dashboards en een triagetoolset voor een snelle reactie.
Les geleerd
Het kost niet veel tijd om een prototype te schrijven. In ons geval was het binnen 4 maanden klaar. Daarmee ontvingen we nieuwe statistieken en 10 maanden na de start van de ontwikkeling ontvingen we het eerste productieverkeer. Toen begon het vervelende en zeer moeilijke werk: het geleidelijk productief maken en opschalen van het systeem, het migreren van het belangrijkste verkeer en het leren van fouten. Maar dit effectieve proces zal niet lineair verlopen: ondanks alle inspanningen is het onmogelijk om alles te voorspellen. Veel efficiënter is een snelle herhaling en reactie op nieuwe gegevens.
Op basis van onze ervaring kunnen wij het volgende adviseren:
- Vertrouw niet op je intuïtie.
Ondanks de ruime ervaring van onze teamleden, lieten we onze intuïtie steeds in de steek. Zo hebben we bijvoorbeeld de verwachte snelheidsverhoging bij gebruik van een CDN-proxy of het gedrag van TCP Anycast onjuist voorspeld.
- Gegevens uit productie halen.
Het is belangrijk om zo snel mogelijk toegang te krijgen tot ten minste een kleine hoeveelheid productiegegevens. Het is praktisch onmogelijk om het aantal unieke gevallen, configuraties en instellingen onder laboratoriumomstandigheden te bepalen. Snelle toegang tot de resultaten zorgt ervoor dat u snel potentiële problemen kunt identificeren en hiermee rekening kunt houden in de systeemarchitectuur.
- Volg niet de adviezen en resultaten van anderen, maar verzamel uw eigen gegevens.
Volg de principes van gegevensverzameling en -analyse, maar neem niet klakkeloos de resultaten en uitspraken van anderen over. Alleen u weet precies wat voor uw gebruikers werkt. Uw systemen en klanten verschillen mogelijk sterk van die van andere bedrijven. Gelukkig zijn er tegenwoordig analysehulpmiddelen beschikbaar die eenvoudig te gebruiken zijn. De resultaten die u ontvangt, komen mogelijk niet overeen met wat Netflix, Facebook, Akamai en andere bedrijven beweren. In ons geval verschillen de prestaties van TLS-, HTTP2- of DNS-querystatistieken van de resultaten van Facebook, Uber en Akamai, omdat we verschillende apparaten, clients en gegevensstromen hebben.
- Volg geen modetrends zonder noodzaak en zonder hun effectiviteit te beoordelen.
Begin eenvoudig. Het is beter om in korte tijd een eenvoudig werkend systeem te maken, dan veel tijd te besteden aan de ontwikkeling van componenten die je helemaal niet nodig hebt. Los problemen en kwesties op die van belang zijn op basis van uw metingen en resultaten.
- Wees voorbereid op nieuwe toepassingen.
Net zoals het moeilijk is om alle problemen te voorspellen, is het ook moeilijk om de voordelen en toepassingen van tevoren te voorspellen. Neem een voorbeeld aan startups: hun vermogen om zich aan te passen aan de behoeften van klanten. In uw geval ontdekt u misschien nieuwe problemen en hun oplossingen. In ons project hebben we ons ten doel gesteld om de aanvraaglatentie te verminderen. Tijdens de analyse en discussie kwamen we er echter achter dat we ook proxyservers kunnen gebruiken:
- om het verkeer over AWS-regio's te verdelen en de kosten te verlagen;
- om de stabiliteit van CDN te modelleren;
- om DNS te configureren;
- om TLS/TCP te configureren.
Conclusie
In mijn presentatie beschreef ik hoe Netflix het probleem van het versnellen van internetaanvragen tussen clients en de cloud oplost. Hoe we gegevens verzamelen via een bemonsteringssysteem voor klanten en de historische gegevens die we hebben verzameld, gebruiken om productieaanvragen van klanten via het snelste pad op internet te sturen. Hoe we netwerkprotocolprincipes, onze CDN-infrastructuur, backbone-netwerk en DNS-servers gebruiken om dit doel te bereiken.
Onze oplossing is echter slechts een voorbeeld van hoe wij bij Netflix een dergelijk systeem hebben geïmplementeerd. Wat voor ons werkte. Het praktische deel van mijn rapport voor u betreft de principes van ontwikkeling en ondersteuning die wij volgen en waarmee wij goede resultaten behalen.
Het is mogelijk dat onze oplossing voor uw probleem niet voor u werkt. De theorie en principes van ontwikkeling blijven echter hetzelfde, zelfs als u geen eigen CDN-infrastructuur hebt of als deze wezenlijk verschilt van de onze.
Ook de snelheid van zakelijke aanvragen blijft belangrijk. En zelfs voor een eenvoudige dienst moet u een keuze maken: tussen cloudproviders, serverlocaties, CDN- en DNS-providers. Uw keuze heeft invloed op de effectiviteit van internetzoekopdrachten voor uw klanten. Het is belangrijk dat u deze invloed kunt meten en begrijpen.
Begin met eenvoudige oplossingen en denk goed na over hoe u het product verandert. Leer terwijl u bezig bent en verbeter het systeem op basis van gegevens van uw klanten, uw infrastructuur en uw bedrijf. Houd rekening met de mogelijkheid van onverwachte storingen tijdens het ontwerpproces. En dan kunt u uw ontwikkelingsproces versnellen, de efficiëntie van uw oplossing verbeteren, onnodige ondersteuningslasten vermijden en met een gerust hart slapen.
Dit jaar in online-formaat. U kunt vragen stellen aan een van de grondleggers van DevOps, John Willis zelf!
Bron: www.habr.com
