

KDB+, bedriftsprodukt er en viden kjent i trange sirkler, ekstremt rask, kolonneformet database designet for lagring av tidsserier og analytiske beregninger basert på dem. Opprinnelig var (og er) det veldig populært i finansbransjen - alle topp 10 investeringsbanker og mange kjente hedgefond, børser og andre organisasjoner bruker det. Nylig bestemte KX seg for å utvide sin kundebase og tilbyr nå løsninger på andre områder der det er store mengder data, organisert etter tid eller på annen måte - telekom, bioinformatikk, produksjon, etc. De ble også partner for Aston Martin Red Bull Racing-teamet i Formel 1, hvor de hjelper til med å samle inn og behandle data fra bilsensorer og analysere vindtunneltester. I denne artikkelen vil jeg fortelle deg hvilke funksjoner i KDB+ som gjør det superytende, hvorfor selskaper er villige til å bruke mye penger på det, og til slutt hvorfor det egentlig ikke er en database.

I denne artikkelen vil jeg prøve å fortelle deg generelt hva KDB+ er, hvilke muligheter og begrensninger den har, og hvilke fordeler den har for selskaper som ønsker å behandle store datamengder. Jeg vil ikke gå inn på detaljene rundt implementeringen av KDB+ eller detaljene i programmeringsspråket Q. Begge disse emnene er veldig brede og fortjener separate artikler. Mye informasjon om disse emnene kan finnes på code.kx.com, inkludert en bok om Q - Q For Mortals (se lenken nedenfor).
Noen vilkår
- Database i minnet. En database som lagrer data i RAM for raskere tilgang. Fordelene med en slik database er klare, men ulempene er muligheten for tap av data og behovet for å ha mye minne på serveren.
- Kolonnedatabase. En database der data lagres kolonne for kolonne i stedet for post for post. Hovedfordelen med en slik database er at data fra én kolonne lagres sammen på disk og i minne, noe som øker tilgangen til den betydelig. Det er ikke nødvendig å laste inn kolonner som ikke brukes i spørringen. Den største ulempen er at det er vanskelig å endre og slette poster.
- Tidsserier. Data med en dato- eller klokkeslettkolonne. Vanligvis er tidsrekkefølge viktig for slike data, slik at du enkelt kan bestemme hvilken post som går foran eller etter den gjeldende, eller å bruke funksjoner hvis resultater avhenger av rekkefølgen på postene. Klassiske databaser er bygget på et helt annet prinsipp – som representerer en samling poster som et sett, hvor rekkefølgen på postene i prinsippet ikke er definert.
- Vektor. I sammenheng med KDB+ er dette en liste over elementer av samme atomtype, for eksempel tall. Med andre ord, en rekke elementer. Arrays, i motsetning til lister, kan lagres kompakt og behandles ved hjelp av vektorprosessorinstruksjoner.
Historisk informasjon
KX ble grunnlagt i 1993 av Arthur Whitney, som tidligere jobbet i Morgan Stanley Bank på A+-språket, etterfølgeren til APL – et veldig originalt og en gang populært språk i finansverdenen. Selvfølgelig fortsatte Arthur i KX i samme ånd og skapte det vektorfunksjonelle språket K, styrt av ideene om radikal minimalisme. K-programmer ser ut som et virvar av tegnsetting og spesialtegn, betydningen av tegn og funksjoner avhenger av konteksten, og hver operasjon har mye mer mening enn den gjør i konvensjonelle programmeringsspråk. På grunn av dette tar et K-program minimalt med plass – noen få linjer kan erstatte sider med tekst på et ordspråk som Java – og er en superkonsentrert implementering av algoritmen.
En funksjon i K som implementerer det meste av LL1-parsergeneratoren i henhold til en gitt grammatikk:
1. pp:{q:{(x;p3(),y)};r:$[-11=@x;$x;11=@x;q[`N;$*x];10=abs@@x;q[`N;x]
2. ($)~*x;(`P;p3 x 1);(1=#x)&11=@*x;pp[{(1#x;$[2=#x;;,:]1_x)}@*x]
3. (?)~*x;(`Q;pp[x 1]);(*)~*x;(`M;pp[x 1]);(+)~*x;(`MP;pp[x 1]);(!)~*x;(`Y;p3 x 1)
4. (2=#x)&(@x 1)in 100 101 107 7 -7h;($[(@x 1)in 100 101 107h;`Ff;`Fi];p3 x 1;pp[*x])
5. (|)~*x;`S,(pp'1_x);2=#x;`C,{@[@[x;-1+#x;{x,")"}];0;"(",]}({$[".s.C"~4#x;6_-2_x;x]}'pp'x);'`pp];
6. $[@r;r;($[1<#r;".s.";""],$*r),$[1<#r;"[",(";"/:1_r),"]";""]]}
Arthur legemliggjorde denne filosofien om ekstrem effektivitet med et minimum av kroppsbevegelser i KDB+, som dukket opp i 2003 (jeg tror det nå er klart hvor bokstaven K i navnet kommer fra) og er ikke annet enn en tolker av den fjerde versjonen av K. En mer brukervennlig versjon er lagt på toppen av K K kalt Q. Q har også lagt til støtte for en spesifikk dialekt av SQL - QSQL, og tolken - støtte for tabeller som systemdatatype, verktøy for arbeid med tabeller i minne og på disk osv.
Så fra en brukers perspektiv er KDB+ ganske enkelt en Q-språktolk med støtte for tabeller og SQL-lignende LINQ-stil-uttrykk fra C#. Dette er den viktigste forskjellen mellom KDB+ og andre databaser og dens viktigste konkurransefortrinn, som ofte blir oversett. Dette er ikke en database + deaktivert hjelpespråk, men et fullverdig kraftig programmeringsspråk + innebygd støtte for databasefunksjoner. Denne forskjellen vil spille en avgjørende rolle når det gjelder å liste opp alle fordelene med KDB+. For eksempel…
Størrelse
Etter moderne standarder er KDB+ ganske enkelt mikroskopisk i størrelse. Det er bokstavelig talt en sub-megabyte kjørbar fil og en liten tekstfil med noen systemfunksjoner. I virkeligheten - mindre enn én megabyte, og for dette programmet betaler selskaper titusenvis av dollar i året for én prosessor på serveren.
- Denne størrelsen gjør at KDB+ kan føles bra på all maskinvare – fra en Pi-mikrodatamaskin til servere med terabyte minne. Dette påvirker ikke funksjonaliteten på noen måte, dessuten starter Q umiddelbart, noe som gjør at den kan brukes blant annet som skriptspråk.
- I denne størrelsen passer Q-tolken helt inn i prosessorbufferen, noe som øker hastigheten på programkjøringen.
- Med denne størrelsen på den kjørbare filen tar Q-prosessen opp ubetydelig plass i minnet; du kan kjøre hundrevis av dem. Om nødvendig kan Q dessuten operere med titalls eller hundrevis av gigabyte minne i en enkelt prosess.
allsidighet
Q er flott for et bredt spekter av bruksområder. Process Q kan fungere som en historisk database og gi rask tilgang til terabyte med informasjon. For eksempel har vi dusinvis av historiske databaser, hvorav en ukomprimert dag med data tar opp mer enn 100 gigabyte. Under rimelige begrensninger vil imidlertid en spørring til databasen bli fullført i løpet av titalls til hundrevis av millisekunder. Generelt har vi en universell tidsavbrudd for brukerforespørsler – 30 sekunder – og det fungerer svært sjelden.
Q kan like gjerne være en database i minnet. Nye data legges til i minnetabeller så raskt at brukerforespørsler er den begrensende faktoren. Data i tabeller er lagret i kolonner, noe som betyr at enhver operasjon på en kolonne vil bruke prosessorbufferen med full kapasitet. I tillegg til dette prøvde KX å implementere alle grunnleggende operasjoner som aritmetikk gjennom vektorinstruksjoner fra prosessoren, og maksimerte deres hastighet. Q kan også utføre oppgaver som ikke er typiske for databaser - for eksempel behandle strømmedata og beregne i "sanntid" (med en forsinkelse fra titalls millisekunder til flere sekunder avhengig av oppgaven) ulike aggregeringsfunksjoner for finansielle instrumenter for forskjellig tid intervaller eller bygge en modell for påvirkningen av perfekte transaksjoner til markedet og utfør profileringen nesten umiddelbart etter at den er fullført. I slike oppgaver er hovedtidsforsinkelsen oftest ikke Q, men behovet for å synkronisere data fra forskjellige kilder. Høy hastighet oppnås på grunn av at dataene og funksjonene som behandler dem er i én prosess, og behandlingen reduseres til å utføre flere QSQL-uttrykk og joins, som ikke tolkes, men utføres av binær kode.
Til slutt kan du skrive alle tjenesteprosesser i Q. For eksempel Gateway-prosesser som automatisk distribuerer brukerforespørsler til nødvendige databaser og servere. Programmereren har full frihet til å implementere enhver algoritme for balansering, prioritering, feiltoleranse, tilgangsrettigheter, kvoter og i bunn og grunn alt annet hans hjerte begjærer. Hovedproblemet her er at du må implementere alt dette selv.
Som et eksempel vil jeg liste opp hvilke typer prosesser vi har. Alle brukes aktivt og fungerer sammen, og kombinerer dusinvis av forskjellige databaser til én, behandler data fra flere kilder og betjener hundrevis av brukere og applikasjoner.
- Koblinger (feedhandler) til datakilder. Disse prosessene bruker vanligvis eksterne biblioteker som lastes inn i Q. C-grensesnittet i Q er ekstremt enkelt og lar deg enkelt lage proxy-funksjoner for ethvert C/C++-bibliotek. Q er rask nok til å håndtere for eksempel å behandle en flom av FIX-meldinger fra alle europeiske børser samtidig.
- Datadistributører (tickerplant), som fungerer som et mellomledd mellom kontakter og forbrukere. Samtidig skriver de innkommende data til en spesiell binær logg, noe som gir robusthet for forbrukere mot tilkoblingstap eller omstart.
- In-memory database (rdb). Disse databasene gir raskest mulig tilgang til rå, fersk data ved å lagre dem i minnet. Vanligvis samler de data i tabeller om dagen og tilbakestiller dem om natten.
- Vedvarende database (pdb). Disse databasene sørger for at data for i dag lagres i en historisk database. Som regel, i motsetning til rdb, lagrer de ikke data i minnet, men bruker en spesiell cache på disk på dagtid og kopierer dataene ved midnatt til den historiske databasen.
- Historiske databaser (hdb). Disse databasene gir tilgang til data for tidligere dager, måneder og år. Størrelsen deres (i dager) er bare begrenset av størrelsen på harddiskene. Data kan lokaliseres hvor som helst, spesielt på forskjellige disker for å øke tilgangen. Det er mulig å komprimere data ved hjelp av flere algoritmer å velge mellom. Strukturen i databasen er godt dokumentert og enkel, dataene lagres kolonne for kolonne i vanlige filer, slik at de kan behandles, blant annet ved hjelp av operativsystemet.
- Databaser med aggregert informasjon. De lagrer ulike aggregasjoner, vanligvis med, gruppert etter instrumentnavn og tidsintervall. In-memory-databaser oppdaterer status med hver innkommende melding, og historiske databaser lagrer forhåndsberegnet data for å øke hastigheten på tilgangen til historiske data.
- Til slutt, den gateway-prosesserbetjene applikasjoner og brukere. Q lar deg implementere fullstendig asynkron behandling av innkommende meldinger, distribuere dem på tvers av databaser, sjekke tilgangsrettigheter, etc. Merk at meldinger ikke er begrenset og som oftest ikke er SQL-uttrykk, slik tilfellet er i andre databaser. Oftest er SQL-uttrykket skjult i en spesiell funksjon og er konstruert basert på parametrene brukeren ber om - tiden konverteres, filtreres, data normaliseres (for eksempel utjevnes aksjekursen hvis det ble utbetalt utbytte), etc.
Typisk arkitektur for én datatype:
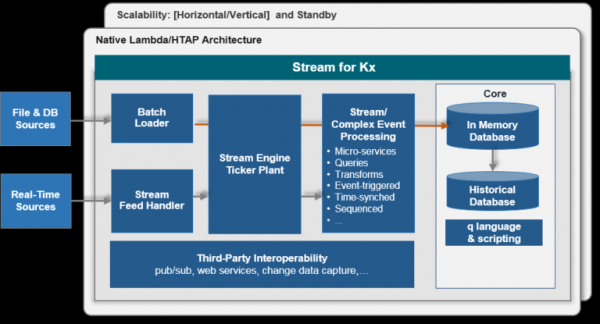
Fart
Selv om Q er et tolket språk, er det også et vektorspråk. Dette betyr at mange innebygde funksjoner, spesielt aritmetiske, tar argumenter av enhver form - tall, vektorer, matriser, lister - og programmereren forventes å implementere programmet som matriseoperasjoner. I et slikt språk, hvis du legger til to vektorer av en million elementer, spiller det ingen rolle at språket tolkes, tillegget vil bli utført av en superoptimalisert binær funksjon. Siden brorparten av tiden i Q-programmer brukes på operasjoner med tabeller som bruker disse grunnleggende vektoriserte funksjonene, er utgangen en veldig anstendig driftshastighet, som lar oss behandle en enorm mengde data selv i én prosess. Dette ligner på matematiske biblioteker i Python - selv om Python i seg selv er et veldig tregt språk, har det mange utmerkede biblioteker som numpy som lar deg behandle numeriske data med hastigheten til et kompilert språk (forresten, numpy er ideologisk nær Q ).
I tillegg tok KX en svært forsiktig tilnærming til å designe tabeller og optimalisere arbeidet med dem. For det første støttes flere typer indekser, som støttes av innebygde funksjoner og kan brukes ikke bare på tabellkolonner, men også på alle vektorer - gruppering, sortering, unikhetsattributt og spesiell gruppering for historiske databaser. Indeksen brukes enkelt og justeres automatisk når elementer legges til kolonnen/vektoren. Indekser kan like vellykket brukes på tabellkolonner både i minnet og på disken. Når du utfører en QSQL-spørring, brukes indekser automatisk hvis mulig. For det andre gjøres arbeidet med historiske data gjennom mekanismen for visning av OS-filer (minnekart). Store tabeller blir aldri lastet inn i minnet, i stedet blir de nødvendige kolonnene kartlagt direkte inn i minnet og bare den delen av dem blir faktisk lastet (indekser hjelper også her) som er nødvendig. Det spiller ingen rolle for programmereren om dataene er i minnet eller ikke; mekanismen for å jobbe med mmap er fullstendig skjult i dypet av Q.
KDB+ er ikke en relasjonsdatabase; tabeller kan inneholde vilkårlige data, mens rekkefølgen på rader i tabellen ikke endres når nye elementer legges til og kan og bør brukes når du skriver spørringer. Denne funksjonen er påtrengende nødvendig for å jobbe med tidsserier (data fra sentraler, telemetri, hendelseslogger), fordi hvis dataene er sortert etter tid, trenger ikke brukeren å bruke noen SQL-triks for å finne den første eller siste raden eller N rader i tabellen , bestemme hvilken linje som følger den N-te linjen osv. Tabellsammenføyninger forenkles ytterligere, for eksempel tar det omtrent et sekund på disken å finne det siste sitatet for 16000 500 VOD.L (Vodafone)-transaksjoner i en tabell med XNUMX millioner elementer på disken og titalls millisekunder i minnet.
Et eksempel på en tidssammenføyning - sitattabellen er tilordnet minnet, så det er ikke nødvendig å spesifisere VOD.L hvor, indeksen på sym-kolonnen og det faktum at dataene er sortert etter tid, brukes implisitt. Nesten alle sammenføyninger i Q er vanlige funksjoner, ikke en del av et utvalgt uttrykk:
1. aj[`sym`time;select from trade where date=2019.03.26, sym=`VOD.L;select from quote where date=2019.03.26]
Til slutt er det verdt å merke seg at ingeniørene hos KX, som starter med Arthur Whitney selv, er virkelig besatt av effektivitet og strekker seg langt for å få mest mulig ut av Qs standardfunksjoner og optimalisere de vanligste bruksmønstrene.
Total
KDB+ er populær blant bedrifter, først og fremst på grunn av sin eksepsjonelle allsidighet - den fungerer like godt som en database i minnet, som en database for lagring av terabyte med historiske data, og som en plattform for dataanalyse. På grunn av det faktum at databehandling skjer direkte i databasen, oppnås høy arbeidshastighet og ressursbesparelser. Et fullverdig programmeringsspråk integrert med databasefunksjoner lar deg implementere hele stabelen med nødvendige prosesser på én plattform – fra mottak av data til behandling av brukerforespørsler.
For mer informasjon,
Begrensninger
En betydelig ulempe med KDB+/Q er den høye inngangsterskelen. Språket har en merkelig syntaks, noen funksjoner er kraftig overbelastet (verdi har for eksempel ca. 11 brukstilfeller). Viktigst av alt, det krever en radikalt annerledes tilnærming til å skrive programmer. I et vektorspråk må du alltid tenke i array-transformasjoner, implementere alle løkker gjennom flere varianter av kart-/reduseringsfunksjonene (som kalles adverb i Q), og aldri prøve å spare penger ved å erstatte vektoroperasjoner med atomiske. For å finne indeksen for den N-te forekomsten av et element i en matrise, bør du for eksempel skrive:
1. (where element=vector)[N]
selv om dette virker veldig ineffektivt etter C/Java-standarder (= skaper en boolsk vektor, der returnerer de sanne indeksene til elementene i den). Men denne notasjonen gjør betydningen av uttrykket mer tydelig og du bruker raske vektoroperasjoner i stedet for langsomme atomoperasjoner. Den konseptuelle forskjellen mellom et vektorspråk og andre kan sammenlignes med forskjellen mellom imperative og funksjonelle tilnærminger til programmering, og du må være forberedt på dette.
Noen brukere er også misfornøyde med QSQL. Poenget er at det bare ser ut som ekte SQL. I virkeligheten er det bare en tolk av SQL-lignende uttrykk som ikke støtter spørringsoptimalisering. Brukeren må selv skrive optimale spørringer, og i Q, som mange ikke er klare for. På den annen side, selvfølgelig, kan du alltid skrive den optimale spørringen selv, i stedet for å stole på en black-box optimizer.
Som et pluss er en bok om Q - Q For Mortals tilgjengelig gratis på , det er også mye annet nyttig materiale samlet der.
En annen stor ulempe er kostnaden for lisensen. Det er titusenvis av dollar per år per CPU. Bare store selskaper har råd til slike utgifter. Nylig har KX gjort sin lisensieringspolicy mer fleksibel og gir muligheten til å betale kun for brukstiden eller leie KDB+ i Google- og Amazon-skyene. KX tilbyr også for nedlasting (32 bit versjon eller 64 bit på forespørsel).
konkurrenter
Det er ganske mange spesialiserte databaser bygget på lignende prinsipper - kolonneformede, i minnet, fokusert på svært store datamengder. Problemet er at dette er spesialiserte databaser. Et slående eksempel er Clickhouse. Denne databasen har et veldig likt prinsipp som KDB+ for å lagre data på disk og bygge en indeks; den utfører noen spørringer raskere enn KDB+, selv om den ikke er vesentlig. Men selv som database er Clickhouse mer spesialisert enn KDB+ - webanalyse vs vilkårlige tidsserier (denne forskjellen er veldig viktig - på grunn av den er det for eksempel i Clickhouse ikke mulig å bruke bestilling av poster). Men viktigst av alt, Clickhouse har ikke allsidigheten til KDB+, et språk som vil tillate behandling av data direkte i databasen, i stedet for å laste det først inn i en separat applikasjon, bygge vilkårlige SQL-uttrykk, bruke vilkårlige funksjoner i en spørring, lage prosesser ikke relatert til utførelse av historiske databasefunksjoner. Derfor er det vanskelig å sammenligne KDB+ med andre databaser, de kan være bedre i visse brukstilfeller eller rett og slett bedre når det kommer til klassiske databaseoppgaver, men jeg kjenner ikke til et annet like effektivt og allsidig verktøy for å behandle midlertidige data.
Python-integrasjon
For å gjøre KDB+ enklere å bruke for folk som ikke er kjent med teknologien, opprettet KX biblioteker for å integrere tett med Python i en enkelt prosess. Du kan enten kalle en hvilken som helst Python-funksjon fra Q, eller omvendt - kall en hvilken som helst Q-funksjon fra Python (spesielt QSQL-uttrykk). Biblioteker konverterer, om nødvendig (ikke alltid for effektivitetens skyld), data fra formatet til ett språk til formatet til et annet. Som et resultat lever Q og Python i en så nær symbiose at grensene mellom dem viskes ut. Som et resultat har programmereren på den ene siden full tilgang til en rekke nyttige Python-biblioteker, på den annen side får han en rask base for å jobbe med store data integrert i Python, noe som er spesielt nyttig for de som er involvert i maskinlæring eller modellering.
Arbeide med Q i Python:
1. >>> q()
2.q)trade:([]date:();sym:();qty:())
3. q)
4. >>> q.insert('trade', (date(2006,10,6), 'IBM', 200))
5. k(',0')
6. >>> q.insert('trade', (date(2006,10,6), 'MSFT', 100))
7. k(',1')
referanser
Nettstedet til selskapet -
Nettsted for utviklere -
Bok Q For Mortals (på engelsk) -
Artikler om KDB+/Q-applikasjoner fra kx-ansatte -
Kilde: www.habr.com
