

Ettersom IPv4-adresser blir oppbrukt, står mange teleoperatører overfor behovet for å gi sine kunder nettverkstilgang ved å bruke adresseoversettelse. I denne artikkelen vil jeg fortelle deg hvordan du kan få Carrier Grade NAT-ytelse på vareservere.
En bit av historien
Emnet for utmattelse av IPv4-adresserom er ikke lenger nytt. På et tidspunkt dukket det opp ventelister i RIPE, så dukket det opp børser hvor adresseblokker ble handlet og avtaler ble inngått for å lease dem. Etter hvert begynte teleoperatører å tilby Internett-tilgangstjenester ved å bruke adresse- og portoversettelse. Noen klarte ikke å skaffe nok adresser til å utstede en "hvit" adresse til hver abonnent, mens andre begynte å spare penger ved å nekte å kjøpe adresser på annenhåndsmarkedet. Produsenter av nettverksutstyr støttet denne ideen, fordi denne funksjonaliteten krever vanligvis ekstra utvidelsesmoduler eller lisenser. For eksempel, i Junipers linje med MX-rutere (bortsett fra de nyeste MX104 og MX204), kan du utføre NAPT på et separat MS-MIC servicekort, Cisco ASR1k krever en CGN-lisens, Cisco ASR9k krever en separat A9K-ISM-100-modul og en A9K-CGN-lisens -LIC til ham. Generelt koster gleden mye penger.
iptables
NAT-implementering krever ikke spesialiserte dataressurser; den kan håndteres av generelle prosessorer, slik som de som finnes i enhver hjemmeruter. På teleoperatørnivå kan denne oppgaven utføres ved hjelp av standardservere som kjører FreeBSD (ipfw/pf) eller GNU/Linux (iptables). Vi skal ikke se på FreeBSD, siden jeg sluttet å bruke det operativsystemet for en stund siden, så la oss holde oss til GNU/Linux.
Å aktivere adresseoversettelse er slett ikke vanskelig. Først må du registrere en regel i iptables i nat-tabellen:
iptables -t nat -A POSTROUTING -s 100.64.0.0/10 -j SNAT --to <pool_start_addr>-<pool_end_addr> --persistent
Operativsystemet vil laste nf_conntrack-modulen, som vil overvåke alle aktive tilkoblinger og utføre de nødvendige konverteringene. Det er flere finesser her. For det første, siden vi snakker om NAT på skalaen til en teleoperatør, er det nødvendig å justere tidsavbruddene, fordi med standardverdier vil størrelsen på oversettelsestabellen raskt vokse til katastrofale verdier. Nedenfor er et eksempel på innstillingene jeg brukte på serverne mine:
net.ipv4.ip_forward = 1
net.ipv4.ip_local_port_range = 8192 65535
net.netfilter.nf_conntrack_generic_timeout = 300
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 600
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 45
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 60
net.netfilter.nf_conntrack_icmpv6_timeout = 30
net.netfilter.nf_conntrack_icmp_timeout = 30
net.netfilter.nf_conntrack_events_retry_timeout = 15
net.netfilter.nf_conntrack_checksum=0
Og for det andre, siden standardstørrelsen på oversettelsestabellen ikke er designet for å fungere under forholdene til en teleoperatør, må den økes:
net.netfilter.nf_conntrack_max = 3145728
Det er også nødvendig å øke antall bøtter for hashtabellen som lagrer alle sendinger (dette er et alternativ i nf_conntrack-modulen):
options nf_conntrack hashsize=1572864
Etter disse enkle manipulasjonene oppnås et fullt funksjonelt design som kan kringkaste et stort antall klientadresser til en pool av eksterne adresser. Ytelsen til denne løsningen etterlater imidlertid mye å være ønsket. I mine første forsøk på å bruke GNU/Linux For NAT (ca. 2013) klarte jeg å få ytelse på rundt 7 Gbit/s ved 0.8 Mpps på en enkelt server (Xeon E5-1650v2). Siden den gang har GNU-kjernens nettverksstakk/Linux Tallrike optimaliseringer ble gjort, og ytelsen til en enkelt server på samme maskinvare økte til nesten 18–19 Gbit/s ved 1.8–1.9 Mpps (dette var maksimumsverdiene), men etterspørselen etter trafikk håndtert av en enkelt server vokste mye raskere. Til syvende og sist ble det utviklet lastbalanseringsordninger for forskjellige servere, men alt dette økte kompleksiteten i oppsett, vedlikehold og kvaliteten på tjenestene som ble levert.
NFT-tabeller
I dag er en moteriktig trend innen programvare "shifting bags" bruken av DPDK og XDP. Det er skrevet mange artikler om dette temaet, mange forskjellige taler er holdt, og det dukker opp kommersielle produkter (for eksempel SKAT fra VasExperts). Men gitt de begrensede programmeringsressursene til telekomoperatører, er det ganske problematisk å lage et hvilket som helst "produkt" basert på disse rammene på egen hånd. Det vil bli mye vanskeligere å drifte en slik løsning i fremtiden, spesielt diagnostiske verktøy må utvikles. For eksempel vil standard tcpdump med DPDK ikke fungere akkurat slik, og den vil ikke "se" pakker sendt tilbake til ledningene ved hjelp av XDP. Midt i alt snakket om nye teknologier for å sende ut pakkevideresending til brukerområdet, gikk de ubemerket hen и Pablo Neira Ayuso, vedlikeholder av iptables, om utviklingen av flytavlasting i nftables. La oss se nærmere på denne mekanismen.
Hovedideen er at hvis ruteren sendte pakker fra en økt i begge retninger av flyten (TCP-økten gikk inn i ETABLISTERT-tilstanden), så er det ikke nødvendig å sende påfølgende pakker av denne økten gjennom alle brannmurregler, fordi alle disse sjekkene vil fortsatt ende med at pakken blir overført videre til rutingen. Og vi trenger faktisk ikke å velge en rute - vi vet allerede til hvilket grensesnitt og til hvilken vert vi må sende pakker i denne økten. Alt som gjenstår er å lagre denne informasjonen og bruke den til ruting på et tidlig stadium av pakkebehandling. Når du utfører NAT, er det nødvendig å i tillegg lagre informasjon om endringer i adresser og porter oversatt av nf_conntrack-modulen. Ja, selvfølgelig, i dette tilfellet slutter forskjellige politifolk og annen informasjon og statistiske regler i iptables å fungere, men innenfor rammen av oppgaven med en separat stående NAT eller for eksempel en grense, er dette ikke så viktig, fordi tjenestene er fordelt på tvers av enheter.
Konfigurasjon
For å bruke denne funksjonen trenger vi:
- Bruk en fersk kjerne. Til tross for at selve funksjonaliteten dukket opp i kjerne 4.16, var den i ganske lang tid veldig "rå" og forårsaket regelmessig kjernepanikk. Alt stabiliserte seg rundt desember 2019, da LTS-kjernene 4.19.90 og 5.4.5 ble utgitt.
- Omskriv iptables-regler i nftables-format ved å bruke en ganske ny versjon av nftables. Fungerer nøyaktig i versjon 0.9.0
Hvis alt i prinsippet er klart med det første punktet, er hovedsaken ikke å glemme å inkludere modulen i konfigurasjonen under montering (CONFIG_NFT_FLOW_OFFLOAD=m), så krever det andre punktet forklaring. nftables-regler beskrives helt annerledes enn i iptables. avslører nesten alle punkter, det er også spesielle regler fra iptables til nftables. Derfor vil jeg bare gi et eksempel på å sette opp NAT og flow offload. En liten legende for eksempel: , - Dette er nettverksgrensesnittene trafikken går gjennom; i virkeligheten kan det være mer enn to av dem. , – start- og sluttadressen til området med «hvite» adresser.
NAT-konfigurasjonen er veldig enkel:
#! /usr/sbin/nft -f
table nat {
chain postrouting {
type nat hook postrouting priority 100;
oif <o_if> snat to <pool_addr_start>-<pool_addr_end> persistent
}
}
Med flytavlastning er det litt mer komplisert, men ganske forståelig:
#! /usr/sbin/nft -f
table inet filter {
flowtable fastnat {
hook ingress priority 0
devices = { <i_if>, <o_if> }
}
chain forward {
type filter hook forward priority 0; policy accept;
ip protocol { tcp , udp } flow offload @fastnat;
}
}
Det er faktisk hele oppsettet. Nå vil all TCP/UDP-trafikk falle inn i fastnat-tabellen og behandles mye raskere.
Funn
For å gjøre det tydelig hvor mye raskere dette er, legger jeg ved et skjermbilde av belastningen på to ekte servere, med samme maskinvare (Xeon E5-1650v2), konfigurert identisk, med samme kjerne. Linux, men utfører NAT i iptables (NAT4) og i nftables (NAT5).
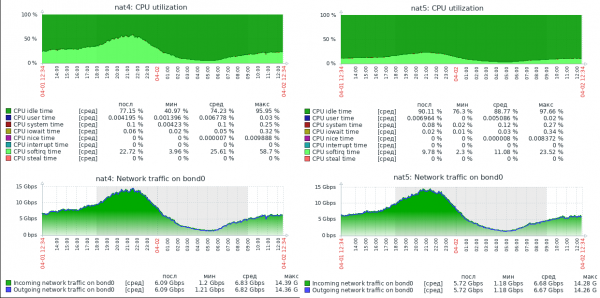
Det er ingen graf over pakker per sekund i skjermbildet, men i lasteprofilen til disse serverne er den gjennomsnittlige pakkestørrelsen rundt 800 byte, så verdiene når opp til 1.5Mpps. Som du kan se, har serveren med nftables en enorm ytelsesreserve. For øyeblikket behandler denne serveren opptil 30Gbit/s ved 3Mpps og er tydelig i stand til å møte den fysiske nettverksbegrensningen på 40Gbps, samtidig som den har ledige CPU-ressurser.
Jeg håper dette materialet vil være nyttig for nettverksingeniører som prøver å forbedre ytelsen til serverne deres.
Kilde: www.habr.com
