

Capacity Tier (eller som vi kaller det inne i Vim - captir) dukket opp tilbake i tiden med Veeam Backup and Replication 9.5 Update 4 under navnet Archive Tier. Tanken bak er å gjøre det mulig å flytte sikkerhetskopier som har falt ut av det såkalte operasjonelle gjenopprettingsvinduet til objektlagring. Dette bidro til å rydde opp diskplass for de brukerne som hadde lite av det. Og dette alternativet ble kalt Move Mode.
For å utføre denne enkle (som det ser ut til) handlingen, var det nok å oppfylle to betingelser: alle punkter fra den flyttede sikkerhetskopien må være utenfor grensene til det ovennevnte operasjonelle gjenopprettingsvinduet, som er eksplisitt angitt i brukergrensesnittet. Og for det andre: kjeden må være i den såkalte "sealed form" (sealed backup chain eller Inactive Backup Chain). Det vil si at det ikke skjer noen endringer i denne kjeden over tid.
Men i VBR v10 ble konseptet supplert med nye funksjoner – Copy Mode, Sealed Mode og en ting med det vanskelig å uttale navnet Immutability dukket opp.
Dette er de fascinerende tingene vi skal snakke om i dag. Først om hvordan det fungerte i VBR9.5u4, og deretter om endringene i den tiende versjonen.
Og må forkjemperne for rent språk tilgi meg, men det er for mange begreper som ikke kan oversettes.
Så det vil være massevis av anglisismer her.
Og mange gifs.
Og bilder.
- Uten den minste anger. Forfatter av artikkelen.
Som det var
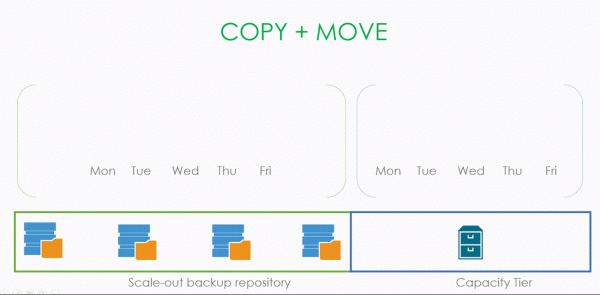
Vel, la oss starte med å analysere det operasjonelle gjenopprettingsvinduet og forseglet sikkerhetskopi (eller som de kalles i dokumentasjonen for Inactive Backup Chain). Uten deres forståelse vil ytterligere forklaring ikke være mulig.
Som vi ser på bildet har vi en slags backupkjede med datablokker, som ligger på Performance tier SOBR til depotet som Capacity Tier er koblet til. Vårt operative backup-vindu er tre dager.
Følgelig forsegler .vbk opprettet på mandag den forrige kjeden, hvis vindu er satt til tre dager. Og det betyr at du trygt kan begynne å frakte alt som er eldre enn disse tre dagene til skytebanen.
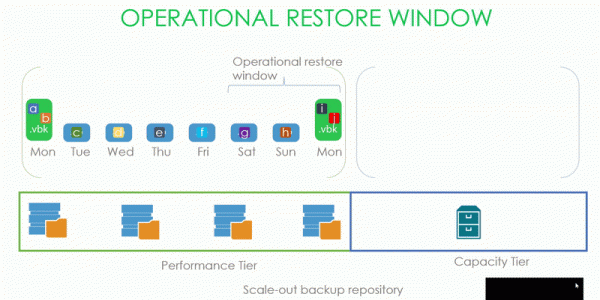
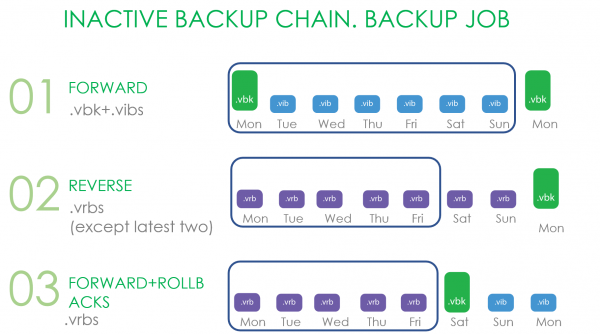
Men hva menes egentlig med en forseglet kjede og hva kunne sendes til kapasitetsskytebanen i oppdatering 4?
For Forward Incremental er et tegn på forsegling av kjeden opprettelsen av en ny full backup. Og det spiller ingen rolle hvordan denne fullstendige sikkerhetskopien oppnås: både syntetiske fulle og aktive fulle sikkerhetskopier vurderes.
Når det gjelder Reverse, er dette alle filer som ikke faller inn i driftsvinduet.
I tilfelle av Forward increment med rollbacks, er disse alle rollbacks og .vbk, hvis det er en annen .vbk på ytelsesomfanget
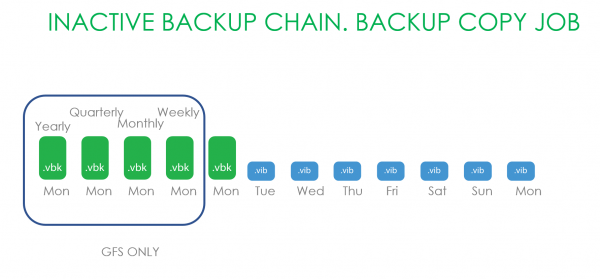
La oss nå vurdere muligheten for å jobbe med Backup Copy-kjeder. Kun gjenstander som faller inn under GFS-oppbevaring ble fraktet hit. Fordi alt som er lagret i nyere sikkerhetskopikjeder kan endres på en eller annen måte.
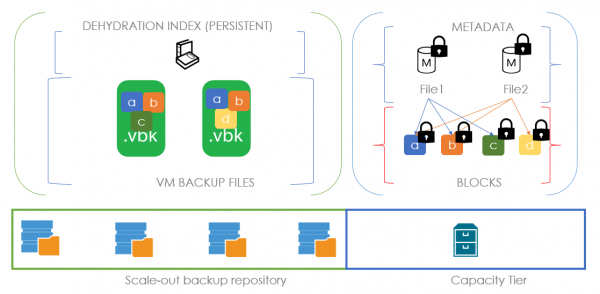
La oss nå se under panseret. Der oppstår en prosess som kalles dehydrering - etterlater tomme sikkerhetskopifiler på omfanget og drar blokker fra disse filene til kapasitetsskytebanen. For å optimalisere denne prosessen brukes den såkalte dehydreringsindeksen, som lar deg unngå å kopiere blokker som allerede er kopiert til kapasitetsskytebanen.
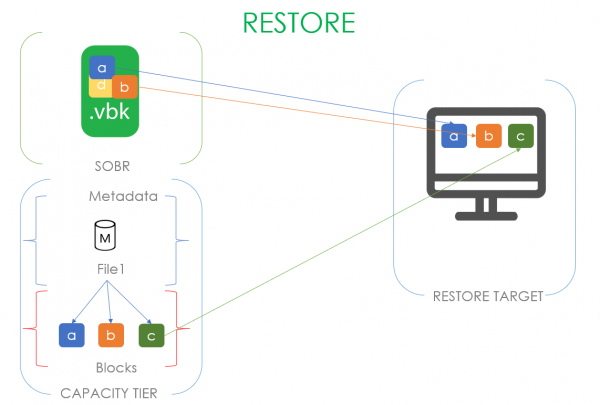
La oss se hvordan dette ser ut med et eksempel: La oss si at vi har en .vbk som kom ut av transaksjonsvinduet og tilhører en forseglet kjede. Det betyr at vi har all rett til å flytte den til kapasitetsskytebanen. På tidspunktet for flytting opprettes en metadatafil i kapasitetsstreken og blokkene til den overførte filen. Metadatafilen på lenkenivå beskriver hvilke blokker filen vår består av. I tilfellet på bildet består vår første fil av blokkene a, b, c og metadataene inneholder lenker til disse blokkene. Når vi har en andre .vbk-fil, klar til å flytte og som består av blokkene a, b og d, forstår vi, ved å analysere dehydreringsindeksen, at bare blokk d må overføres. Og metadatafilen vil inneholde lenker til to tidligere blokker og en ny.
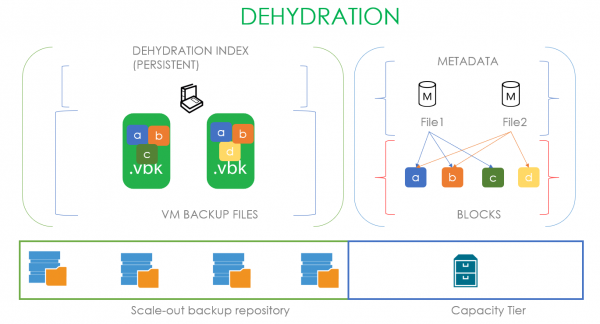
Følgelig kalles prosessen med å fylle disse tomme plassene tilbake med data rehydrering. Den bruker allerede sin egen rehydreringsindeks, basert på den eldste .vbk-filen på den lokale ytelsesgraden. Det vil si at hvis brukeren ønsker å returnere en fil fra kapasitetsskytebanen, lager vi først en indeks over blokkene til den eldste full backup og overfører kun de manglende blokkene fra kapasitetsskytegalleriet. I tilfellet som er presentert på bildet, for å rehydrere FullBackup1.vbk i henhold til rehydreringsindeksen, trenger vi bare blokk C, som vi tar fra kapasitetsskytebanen. Hvis et lagringsskyobjekt fungerer som en skytebane med kapasitet, kan du spare enorme mengder penger.
Her kan det virke som om denne teknologien er identisk med den som brukes i WAN Accelerators, men det virker bare slik. I akseleratorer er deduplisering global; her brukes lokal deduplisering i hver fil med en bestemt forskyvning. Dette skjer på grunn av forskjellen i oppgavene som løses: her må vi kopiere store fulle backup-filer, og i følge vår forskning, selv om det går lang tid mellom dem, gir denne dedupliseringsalgoritmen det beste resultatet.
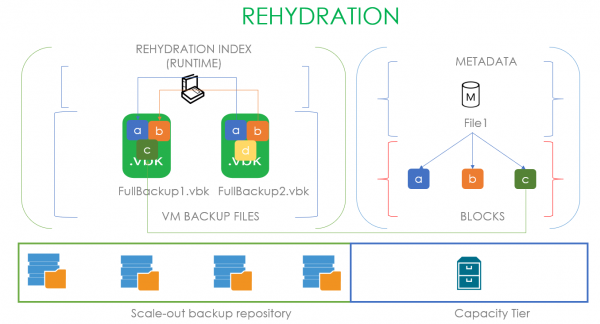
Men flere indekser for indeksguden! Det er også en indeks for datagjenoppretting! Når vi begynner å gjenopprette en maskin som ligger i kapasitetsdashen, vil vi kun lese unike datablokker som ikke er i ytelsesdashen.
Hvordan skjedde det?
Det var alt for den innledende delen. Det er ganske detaljert, men som nevnt ovenfor, uten disse detaljene vil det ikke være mulig å forklare hvordan de nye funksjonene fungerer. Derfor, uten videre, la oss gå videre til den første.
Kopimodus
Den er i stor grad basert på eksisterende teknologier, men har en helt annen brukslogikk.
Hensikten med denne modusen er å sikre at alle data som er lokalisert i lokal utstrekning har en kopi i kapasitetsstreken.
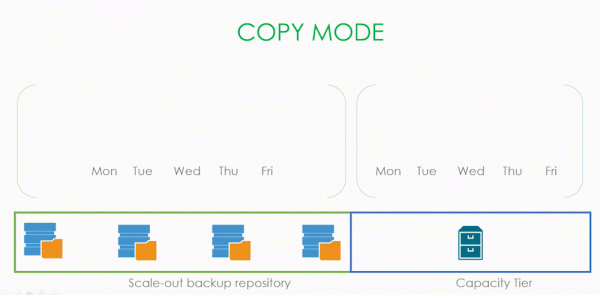
Hvis du sammenligner Flytt- og Kopier-modusene front-on, vil det se slik ut:
- Bare den forseglede kjeden kan flyttes. Ved kopieringsmodus overføres absolutt alt, uavhengig av hva som skjer i backupjobben.
- Flytting utløses når filene går utover grensene til det operative sikkerhetskopieringsvinduet, og kopiering utløses så snart backupfilen vises.
- Overvåking av nye data for kopiering skjer hele tiden, og for flytting ble det utløst en gang hver 4. time.
Når jeg vurderer den nye modusen, foreslår jeg å gå fra enkle eksempler til komplekse.
I det vanligste tilfellet har vi rett og slett nye filer med inkrementer, og vi kopierer dem ganske enkelt til kapasitetsskytebanen. Uansett hvilken modus som brukes i backupjobben, uansett om den tilhører den forseglede delen av kjeden eller ikke, uavhengig av om driftsvinduet vårt er utløpt. De bare tok den og kopierte den.
Prosessen bak dette er fortsatt dehydrering som beskrevet ovenfor. I kopieringsmodus sørger den også for at vi ikke kopierer blokker som allerede er på lageret vårt. Den eneste forskjellen er at hvis vi i filmmodus erstattet ekte filer med dummy-filer, berører vi dem ikke på noen måte og lar alt være som det er. Ellers er det nøyaktig den samme dehydreringsindeksen, som nøye prøver å spare penger og tid.
Spørsmålet dukker opp - hvis du ser på brukergrensesnittet, er det en mulighet til å velge begge alternativene samtidig. Hvordan vil en slik kombinert modus fungere?
La oss finne ut det.
Begynnelsen er standard: en sikkerhetskopifil opprettes og kopieres umiddelbart. Et inkrement opprettes til den og kopieres også. Dette skjer til det øyeblikket vi innser at filene har forlatt operasjonsvinduet vårt og en forseglet kjede har dukket opp. På dette tidspunktet utfører vi en dehydreringsoperasjon og erstatter disse filene med dummy-filer. Selvfølgelig kopierer vi ikke noe igjen til kapasitetsskytebanen.
All denne fascinerende logikken er ansvarlig for bare én avmerkingsboks i grensesnittet: Kopier sikkerhetskopier til objektlagring så snart de er opprettet.
Hvorfor trenger vi denne kopimodusen?
Det er enda bedre å omformulere spørsmålet på denne måten: hvilke risikoer er vi beskyttet mot med hjelpen? Hvilket problem hjelper det oss å løse?
Svaret er åpenbart: selvfølgelig er dette datagjenoppretting. Hvis vi har en fullstendig kopi av lokale data på objektlagringen, så uansett hva som skjer med produktet vårt, kan vi alltid gjenopprette data fra filer som ligger i den betingede Amazon.
Så la oss gå gjennom de mulige scenariene, fra de enkleste til de mer komplekse.
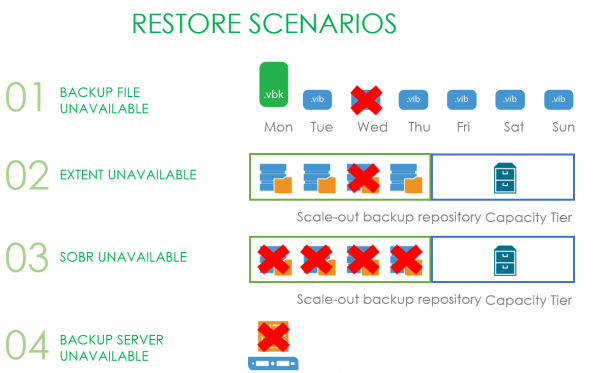
Den enkleste ulykken som kan falle på hodet er utilgjengeligheten til en av filene i sikkerhetskopikjeden.
En tristere historie er at en av utstrekningene til SOBR-depotet vårt gikk i stykker.
Enda verre blir det når hele SOBR-depotet er blitt utilgjengelig, men kapasitetsskytebanen fungerer.
Og alt er virkelig dårlig - dette er når backupserveren dør og ditt første ønske er å prøve å løpe til den kanadiske grensen på ti minutter.
La oss nå se på hver situasjon separat.
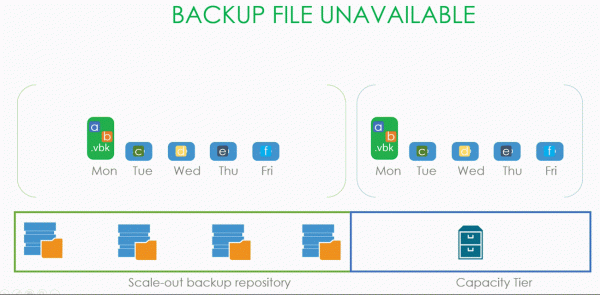
Når vi har mistet en (og til og med flere) sikkerhetskopifiler, er alt vi trenger å gjøre å starte repository rescan-prosessen, og den tapte filen vil bli erstattet med en dummy-fil. Og ved å bruke rehydreringsprosessen (som ble diskutert i begynnelsen av artikkelen), vil brukeren kunne laste ned data fra kapasitetsskytebanen til lokal lagring.
Nå er situasjonen mer komplisert. La oss anta at vår SOBR består av to utstrekninger som kjører i Performance-modus, noe som betyr at våre .vbk og .vib er spredt over dem i et ganske ujevnt lag. Og på et tidspunkt blir en av utstrekningene utilgjengelig, og brukeren trenger snarest å gjenopprette maskinen, en del av dataene som ligger nettopp på dette omfanget.
Brukeren starter gjenopprettingsveiviseren, velger punktet han vil gjenopprette, og veiviseren, mens han arbeider, innser at han ikke har alle dataene som er nødvendige for gjenoppretting lokalt og derfor må lastes ned fra kapasitetsopptaket galleri. Samtidig vil blokker som forblir på lokal lagring ikke lastes ned fra skyen. Ære til gjenopprettingsindeksen (ja, den ble også nevnt i begynnelsen av artikkelen).

En undertype av denne saken er at hele SOBR-depotet ble utilgjengelig. I dette tilfellet har vi ingenting å kopiere fra lokal lagring, og alle blokker lastes ned fra skyen.
Og den mest interessante situasjonen er at backupserveren døde. Det er to alternativer her: adminen er flott og har laget konfigurasjonssikkerhetskopier, og adminen er en ond Pinocchio selv og har ikke laget konfigurasjonssikkerhetskopier.
I det første tilfellet vil det være nok for ham å bare distribuere en ren installasjon av VBR et sted og gjenopprette databasen fra en sikkerhetskopi ved hjelp av standardmidler. På slutten av denne prosessen vil alt gå tilbake til det normale. Eller det vil bli gjenopprettet i henhold til et av scenariene ovenfor.
Men hvis administratoren enten er sin egen fiende, eller konfigurasjonsbackupen også led en episk feil, vil vi ikke overlate ham til skjebnen selv her. For dette tilfellet har vi introdusert en ny prosedyre kalt Import Object Storage. Den lar deg hoppe over prosessen med å manuelt gjenskape et SOBR-lager og knytte en kapasitetsskytebane til det med påfølgende rescan, og ganske enkelt legge til et lagringsobjekt til Vim-grensesnittet og kjøre Import Storage Repository-prosedyren. Det eneste som kan stå i veien mellom deg og sikkerhetskopiene dine er en forespørsel om å skrive inn et passord hvis sikkerhetskopiene dine var kryptert.
Dette handler sannsynligvis om kopieringsmodus, og vi går videre til
Forseglet modus
Hovedideen er at nye sikkerhetskopier ikke kan vises på den valgte SOBR-utstrekningen av depotet. Før v10 hadde vi bare vedlikeholdsmodus, da alt arbeid med depotet var fullstendig forbudt. En slags hardcore-modus for å stenge ned lagring, der bare Evakuer-knappen er tilgjengelig, som transporterer sikkerhetskopier til en annen grad en gang.
Og forseglet modus er et slags "mykt" alternativ: vi forbyr opprettelse av nye sikkerhetskopier og sletter gradvis gamle i henhold til valgt oppbevaring, men i prosessen mister vi ikke muligheten til å gjenopprette fra lagrede punkter. En veldig nyttig ting når vi enten har en maskinvare som nærmer seg slutten av levetiden og trenger å erstatte den, eller vi bare trenger å frigjøre den for noe viktigere, men det er ingen steder å ta den og flytte alt på en gang. Eller det kan ikke slettes.
Følgelig er operasjonsprinsippet ganske enkelt: det er nødvendig å forby alle skriveoperasjoner (utseendet til nye data), la lese (restaureringer) og slette (oppbevaring).
Begge modusene kan brukes samtidig, men husk at vedlikehold har høyere prioritet.
Som et eksempel kan du vurdere en SOBR som består av to utstrekninger. La oss anta at vi de første fire dagene laget sikkerhetskopier i Forward Forever Incremental-modus, og deretter forsegler vi omfanget. Dette fører til at vi starter opprettelsen av en ny aktiv full på den andre tilgjengelige utstrekningen. Hvis vår oppbevaring er fire, blir den slettet med god samvittighet når hele kjeden som ligger på den forseglede utstrekningen går utover sine grenser.

Det er situasjoner hvor sletting skjer tidligere. Dette er for eksempel Videresend inkrementell med periodiske fuller. Hvis vi opprettet fullstendige sikkerhetskopier for de to første dagene, og på torsdag bestemmer vi oss for å forsegle depotet, så på fredag, når en ny sikkerhetskopi opprettes, vil filen for mandag bli slettet fordi det er ingen avhengigheter til dette punktet. Og selve poenget er ikke avhengig av noen. Så venter vi til fire punkter er opprettet på tilgjengelig omfang og sletter de resterende tre, som ikke kan slettes uavhengig av hverandre.

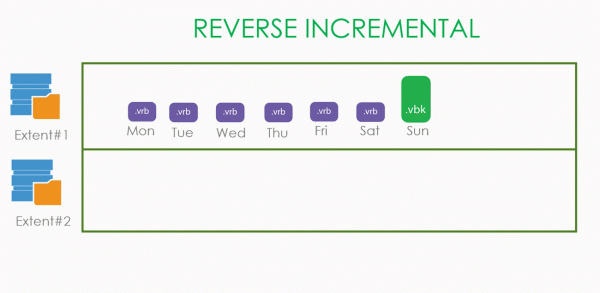
Ting er enklere med Reverse Incremental. I den er de eldste punktene ikke avhengige av noe og kan trygt slettes. Derfor, så snart en ny .vbk er opprettet på et nytt omfang, vil de gamle .vrbs bli slettet én etter én.
Forresten, hvorfor lager vi en ny .vbk hver gang: hvis vi ikke opprettet den, men fortsatte den gamle kjeden av inkrementer, ville den gamle .vbk fryse i uendelig lang tid i alle moduser, og forhindret sletting av den. Derfor ble det bestemt at så snart omfanget er forseglet, lager vi en full backup på det frie omfanget.
Ting er mer komplisert med kapasitetsskytebanen.
La oss først se på kopieringsmodus. La oss anta at vi aktivt opprettet sikkerhetskopier i fire dager, og deretter ble kapasitetsskytebanen forseglet. Vi sletter ikke noe, men tåler ydmykt oppbevaringen, hvoretter vi sletter dataene fra kapasitetsskytebanen.
Omtrent det samme skjer i flyttemodus - vi venter på retusjeringen, sletter den gamle i det lokale lageret og sletter det som er lagret i objektlageret.
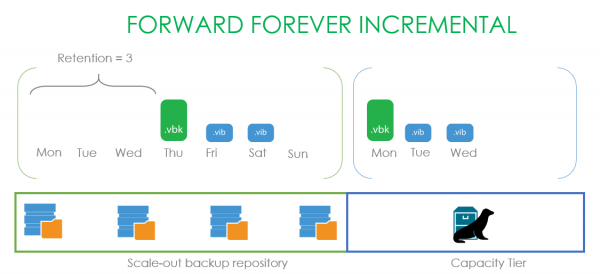
Et interessant eksempel med Forever forward incremental. Vi installerer oppbevaring på tre punkter og begynner å lage sikkerhetskopier på mandag, som jevnlig kopieres til skyen. Etter at lagringen er forseglet, fortsetter det å lage sikkerhetskopier, mens tre punkter opprettholdes, men dataene som er lagret i kapasitetsstreken forblir avhengige og kan ikke slettes. Derfor venter vi til torsdag, når vår .vbk går utover oppbevaring, og først da sletter vi rolig hele den lagrede kjeden.
Og en liten ansvarsfraskrivelse: alle eksemplene her vises med én maskin. Hvis du har flere av dem i sikkerhetskopien, vil retusjeringen deres variere avhengig av om Active Full ble laget eller ikke.
Det er i grunnen alt som skal til. Så la oss gå videre til den mest hardcore funksjonen -
Uforanderlighet
Som med de foregående punktene, er det første hvilket problem denne funksjonen løser. Så snart vi laster opp sikkerhetskopiene våre et sted for lagring, er det et sterkt ønske om å garantere deres sikkerhet, det vil si å fysisk forby sletting og enhver endring under en gitt oppbevaring. Inkludert administratorer, inkludert under root-kontoene deres. Dette lar deg beskytte dem mot utilsiktet eller tilsiktet skade. Alle som jobber med AWS kan ha kommet over en lignende funksjon kalt Object Lock.
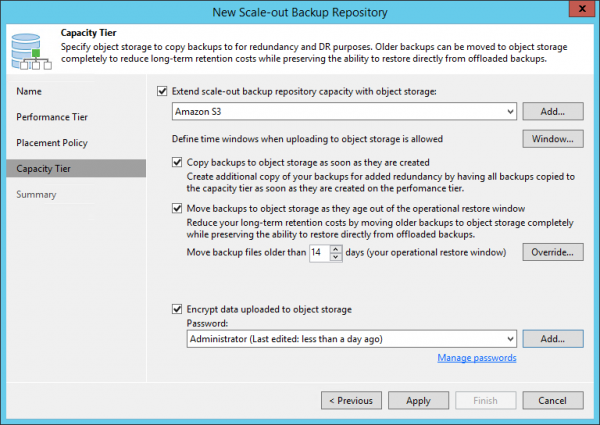
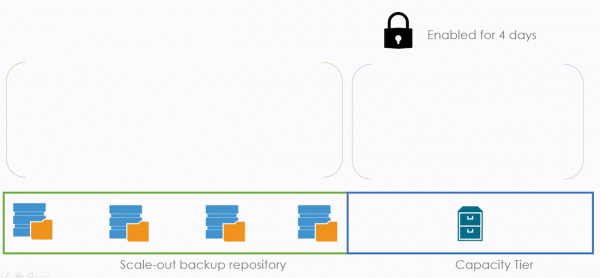
La oss nå se på modusen i generelle termer, og deretter fordype oss i detaljene. I vårt eksempel vil Immutability være aktivert for vår kapasitetsskytebane med en oppbevaring på fire dager. Og kopieringsmodus er aktivert i sikkerhetskopien.
Uforanderlighet samhandler ikke med generell retensjon på noen måte. Det gir for eksempel ikke ekstra poeng eller noe sånt. Det er bare det at en person ikke kan slette sikkerhetskopifiler innen fire dager. Hvis du tar en sikkerhetskopi på mandag, vil du bare kunne slette filen på fredag.
Alle tidligere forklarte konsepter om dehydrering, indekser og metadata fortsetter å fungere nøyaktig det samme. Men med en betingelse - blokken er satt ikke bare for data, men også for metadata. Dette gjøres i tilfelle en utspekulert angriper bestemmer seg for å slette metadatadatabasen vår og forhindre at datablokker blir til ubrukelig binær grøt.
Nå er det en flott tid for å forklare blokkgenerasjonsteknologien vår. Eller blokkgenerering. For å gjøre dette, vurder situasjonen som førte til utseendet.
La oss ta en tidsskala på seks dager og nedenfor vil vi markere tidspunktet for forventet utløp av uforanderlighet. Den første dagen tar vi og lager en fil som består av datablokk a og dens metadata. Hvis uforanderlighet er satt til tre dager, er det logisk å anta at den fjerde dagen vil dataene låses opp og slettes. På den andre dagen legger vi til en ny fil2, bestående av blokk b med de samme innstillingene. Blokk a må fortsatt fjernes den fjerde dagen. Men på den tredje dagen skjer det noe forferdelig - en File3-fil opprettes, bestående av en ny blokk d og en lenke til den gamle blokken a. Dette betyr at for en blokk og dens uforanderlighet må flagget tilbakestilles til en ny dato, som flyttes til den sjette dagen. Og her oppstår et problem - i ekte sikkerhetskopier er det et stort antall slike blokker. Og for å forlenge deres uforanderlighetsperiode, må du komme med et stort antall forespørsler hver gang. Og faktisk vil dette være en nesten uendelig daglig prosess, siden vi med en høy grad av sannsynlighet vil finne heftige stabler av dedupliserte blokker med hver kopi. Hva betyr et stort antall forespørsler fra leverandører av objektlagring? Ikke sant! Stor regning i slutten av måneden.

Og for ikke å ut av det blå avsløre favorittkundene dine for betydelige penger, ble blokkgenereringsmekanismen oppfunnet. Dette er en tilleggsperiode som vi legger til den angitte uforanderlighetsperioden. I eksemplet nedenfor er denne perioden to dager. Men dette er bare et eksempel. I virkeligheten bruker de sin egen formel, som gir omtrent ti ekstra dager i løpet av en månedlig låsing.
La oss fortsette å vurdere den samme situasjonen, men med blokkgenerering. Den første dagen lager vi fil1 fra blokk a og metadata. Vi legger sammen generasjonsperioden og uforanderligheten - dette betyr at muligheten for å slette filen vil være på den sjette dagen. Hvis vi på den andre dagen lager File2, bestående av blokk b og en lenke til blokk a, skjer det ingenting med forventet slettingsdato. Hun sto som hun gjorde den sjette dagen. Og dermed prøver vi å spare penger på antall forespørsler. Den eneste situasjonen når fristen kan flyttes er dersom generasjonsperioden er utløpt. Det vil si at hvis den nye File3 på den tredje dagen inneholder en lenke for å blokkere a, vil generasjon 2 bli lagt til siden Gen1 allerede er utløpt. Og forventet dato for sletting av blokk a vil skifte til den åttende dagen. Dette lar oss dramatisk redusere antallet forespørsler for å forlenge levetiden til dedupliserte blokker, noe som sparer kundene massevis av penger.

Selve teknologien er tilgjengelig for brukere av S3- og S3-kompatibel maskinvare, hvis produsenter garanterer at implementeringen deres ikke skiller seg fra Amazons. Derav svaret på det legitime spørsmålet hvorfor Azure ikke støttes - de har en lignende funksjon, men den fungerer på nivå med containere, ikke individuelle objekter. Amazon selv har forresten objektlås i to moduser: compliance og governance. I det andre tilfellet er det fortsatt mulighet for at den største administratoren over administratorer og root over røtter, til tross for objektlåsen, fortsatt sletter dataene. Når det gjelder samsvar, er alt spikret tett og ingen kan slette sikkerhetskopiene. Til og med Amazon-administratorer (ifølge deres offisielle uttalelser). Dette er modusen vi støtter.
Og, som vanlig, noen nyttige linker:
- Про i hver detalj.
- All informasjon om på sitt beste
- О i detalj
Kilde: www.habr.com
