


Variti utvikler beskyttelse mot bots og DDoS-angrep, og gjennomfører også stress- og belastningstesting. På konferansen HighLoad++ 2018 snakket vi om hvordan man kan sikre ressurser fra ulike typer angrep. Kort sagt: isoler deler av systemet, bruk skytjenester og CDN-er, og oppdater regelmessig. Men du vil fortsatt ikke kunne håndtere beskyttelse uten spesialiserte selskaper :)
Før du leser teksten, kan du lese de korte sammendragene .
Og hvis du ikke liker å lese eller bare vil se videoen, er opptaket av rapporten vår under spoileren.
Videoopptak av rapporten

Mange bedrifter vet allerede hvordan de skal utføre belastningstesting, men ikke alle gjør stresstester. Noen av kundene våre tror at siden deres er usårbar fordi de har et høybelastningssystem, og det beskytter godt mot angrep. Vi viser at dette ikke er helt sant.
Før vi gjennomfører tester innhenter vi selvfølgelig tillatelse fra kunden, signert og stemplet, og med vår hjelp kan et DDoS-angrep ikke utføres på noen. Testing utføres på et tidspunkt kunden velger, når trafikken til ressursen hans er minimal, og tilgangsproblemer ikke vil påvirke kundene. I tillegg, siden noe alltid kan gå galt under testprosessen, har vi konstant kontakt med kunden. Dette lar deg ikke bare rapportere oppnådde resultater, men også endre noe under testingen. Etter fullført testing utarbeider vi alltid en rapport der vi påpeker eventuelle mangler og gir anbefalinger for å eliminere nettstedets svakheter.
Hvordan vi jobber
Når vi tester, emulerer vi et botnett. Siden vi jobber med klienter som ikke er lokalisert på våre nettverk, for å sikre at testen ikke avsluttes i det første minuttet på grunn av grenser eller beskyttelse som utløses, leverer vi belastningen ikke fra én IP, men fra vårt eget subnett. I tillegg, for å skape en betydelig belastning, har vi vår egen ganske kraftige testserver.
Postulater
For mye betyr ikke godt
Jo mindre belastning vi kan bringe en ressurs til å svikte, jo bedre. Hvis du kan få nettstedet til å slutte å fungere på én forespørsel per sekund, eller til og med én forespørsel per minutt, er det flott. For i henhold til ondskapens lov vil brukere eller angripere ved et uhell falle inn i denne spesielle sårbarheten.
Delvis svikt er bedre enn fullstendig svikt
Vi anbefaler alltid å gjøre systemer heterogene. Dessuten er det verdt å skille dem på det fysiske nivået, og ikke bare ved containerisering. Ved fysisk separasjon, selv om noe feiler på siden, er det stor sannsynlighet for at det ikke slutter å fungere helt, og brukere vil fortsatt ha tilgang til i det minste deler av funksjonaliteten.
God arkitektur er grunnlaget for bærekraft
Feiltoleransen til en ressurs og dens evne til å motstå angrep og belastninger bør fastsettes på designstadiet, faktisk på stadiet for å tegne de første flytskjemaene i en notatbok. For hvis fatale feil kommer snikende, er det mulig å rette dem i fremtiden, men det er veldig vanskelig.
Ikke bare koden skal være bra, men også konfigurasjonen
Mange tror at et godt utviklingsteam garanterer robusthet for tjenester. Et godt utviklingsteam er riktignok avgjørende, men det må også være god drift, god DevOps. Dette betyr at du trenger spesialister som kan konfigurere det riktig. Linux og nettverket, skriv NGINX-konfigurasjonsfiler riktig, sett grenser og så videre. Ellers vil ressursen bare fungere fint i testing, men på et tidspunkt i produksjonen vil alt gå i stykker.
Forskjeller mellom belastnings- og stresstesting
Lasttesting lar deg identifisere grensene for systemets funksjon. Stresstesting er rettet mot å finne svakheter i et system og brukes til å bryte dette systemet og se hvordan det vil oppføre seg i prosessen med svikt i visse deler. I dette tilfellet forblir belastningens natur vanligvis ukjent for kunden før stresstesting starter.
Særtrekk ved L7-angrep
Vi deler vanligvis typer last inn i laster på L7 og L3&4 nivåer. L7 er en belastning på applikasjonsnivå, oftest betyr det bare HTTP, men vi mener enhver belastning på TCP-protokollnivå.
L7-angrep har visse særtrekk. For det første kommer de direkte til applikasjonen, det vil si at det er usannsynlig at de vil reflekteres via nettverksmidler. Slike angrep bruker logikk, og på grunn av dette bruker de CPU, minne, disk, database og andre ressurser svært effektivt og med lite trafikk.
HTTP-flom
Ved ethvert angrep er belastningen lettere å skape enn å håndtere, og i tilfelle L7 er dette også sant. Det er ikke alltid lett å skille angrepstrafikk fra legitim trafikk, og som oftest kan dette gjøres etter frekvens, men hvis alt er riktig planlagt, så er det umulig å forstå ut fra loggene hvor angrepet er og hvor de legitime forespørslene er.
Som et første eksempel kan du vurdere et HTTP Flood-angrep. Grafen viser at slike angrep vanligvis er veldig kraftige; i eksemplet nedenfor oversteg toppantallet for forespørsler 600 tusen per minutt.
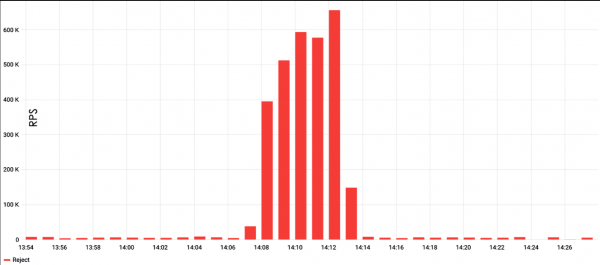
HTTP Flood er den enkleste måten å skape belastning på. Vanligvis krever det et slags belastningstestverktøy, for eksempel ApacheBench, og setter en forespørsel og et mål. Med en så enkel tilnærming er det stor sannsynlighet for å kjøre inn i server-caching, men det er lett å omgå det. For eksempel å legge til tilfeldige strenger i forespørselen, noe som vil tvinge serveren til konstant å vise en ny side.
Ikke glem brukeragenten i ferd med å opprette en last. Mange brukeragenter for populære testverktøy blir filtrert av systemadministratorer, og i dette tilfellet kan det hende at belastningen rett og slett ikke når bakenden. Du kan forbedre resultatet betraktelig ved å sette inn en mer eller mindre gyldig overskrift fra nettleseren i forespørselen.
Så enkle som HTTP Flood-angrep er, har de også sine ulemper. For det første kreves det store mengder kraft for å skape belastningen. For det andre er slike angrep veldig enkle å oppdage, spesielt hvis de kommer fra én adresse. Som et resultat begynner forespørsler umiddelbart å bli filtrert enten av systemadministratorer eller til og med på leverandørnivå.
Hva du skal se etter
For å redusere antall forespørsler per sekund uten å miste effektivitet, må du vise litt fantasi og utforske nettstedet. Dermed kan du laste ikke bare kanalen eller serveren, men også individuelle deler av applikasjonen, for eksempel databaser eller filsystemer. Du kan også se etter steder på siden som gjør store beregninger: kalkulatorer, produktvalgsider osv. Til slutt hender det ofte at siden har et slags PHP-skript som genererer en side på flere hundre tusen linjer. Et slikt skript laster også serveren betydelig og kan bli et mål for et angrep.
Hvor du skal lete
Når vi skanner en ressurs før testing, ser vi først, selvfølgelig, på selve nettstedet. Vi ser etter alle slags inndatafelt, tunge filer - generelt alt som kan skape problemer for ressursen og bremse driften. Banale utviklingsverktøy i Google Chrome og Firefox hjelper her, som viser sidens responstider.
Vi skanner også underdomener. For eksempel er det en bestemt nettbutikk, abc.com, og den har et underdomene admin.abc.com. Mest sannsynlig er dette et adminpanel med autorisasjon, men hvis du legger en belastning på det, kan det skape problemer for hovedressursen.
Nettstedet kan ha et underdomene api.abc.com. Mest sannsynlig er dette en ressurs for mobilapplikasjoner. Applikasjonen finner du i App Store eller Google Play, installer et spesielt tilgangspunkt, disseker API og registrer testkontoer. Problemet er at folk ofte tror at alt som er beskyttet av autorisasjon er immun mot tjenestenektangrep. Angivelig er autorisasjon den beste CAPTCHA, men det er den ikke. Det er enkelt å lage 10-20 testkontoer, men ved å opprette dem får vi tilgang til kompleks og utilslørt funksjonalitet.
Naturligvis ser vi på historien, på robots.txt og WebArchive, ViewDNS, og ser etter gamle versjoner av ressursen. Noen ganger hender det at utviklere har rullet ut for eksempel mail2.yandex.net, men den gamle versjonen, mail.yandex.net, gjenstår. Denne mail.yandex.net støttes ikke lenger, utviklingsressurser er ikke allokert til den, men den fortsetter å konsumere databasen. Følgelig, ved å bruke den gamle versjonen, kan du effektivt bruke ressursene til backend og alt som ligger bak layouten. Dette skjer selvfølgelig ikke alltid, men vi møter dette ganske ofte.
Naturligvis analyserer vi alle forespørselsparametrene og informasjonskapselstrukturen. Du kan for eksempel dumpe noe verdi inn i en JSON-array inne i en informasjonskapsel, lage mye nesting og få ressursen til å fungere i urimelig lang tid.
Søkelast
Det første du tenker på når du undersøker et nettsted er å laste databasen, siden nesten alle har et søk, og for nesten alle, dessverre, er den dårlig beskyttet. Av en eller annen grunn tar ikke utviklere nok oppmerksomhet til søk. Men det er en anbefaling her - du bør ikke komme med forespørsler av samme type, fordi du kan støte på caching, slik tilfellet er med HTTP-flom.
Å gjøre tilfeldige spørringer til databasen er heller ikke alltid effektivt. Det er mye bedre å lage en liste over søkeord som er relevante for søket. Hvis vi går tilbake til eksemplet med en nettbutikk: la oss si at nettstedet selger bildekk og lar deg stille inn radiusen til dekkene, typen bil og andre parametere. Følgelig vil kombinasjoner av relevante ord tvinge databasen til å fungere under mye mer komplekse forhold.
I tillegg er det verdt å bruke paginering: det er mye vanskeligere for et søk å returnere den nest siste siden med søkeresultatene enn den første. Det vil si at ved hjelp av paginering kan du diversifisere belastningen litt.
Eksemplet nedenfor viser søkebelastningen. Det kan ses at siden det aller første sekundet av testen med en hastighet på ti forespørsler per sekund, gikk siden ned og svarte ikke.
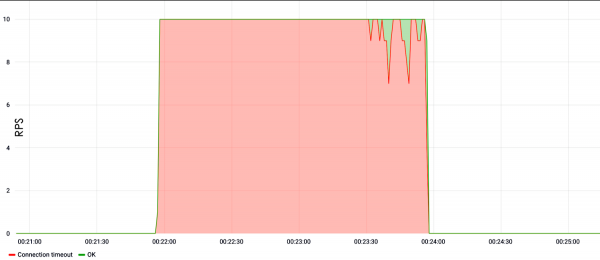
Hvis det ikke er søk?
Hvis det ikke er søk, betyr ikke dette at nettstedet ikke inneholder andre sårbare inndatafelt. Dette feltet kan være autorisasjon. Nå for tiden liker utviklere å lage komplekse hashes for å beskytte påloggingsdatabasen mot et regnbuetabellangrep. Dette er bra, men slike hashes bruker mye CPU-ressurser. En stor strøm av falske autorisasjoner fører til en prosessorfeil, og som et resultat slutter nettstedet å fungere.
Tilstedeværelsen på nettstedet av alle slags skjemaer for kommentarer og tilbakemeldinger er en grunn til å sende veldig store tekster dit eller bare skape en massiv flom. Noen ganger godtar nettsteder vedlagte filer, inkludert i gzip-format. I dette tilfellet tar vi en 1TB fil, komprimerer den til flere byte eller kilobyte ved hjelp av gzip og sender den til nettstedet. Deretter pakkes den ut og en veldig interessant effekt oppnås.
Rest API
Jeg vil gjerne være litt oppmerksom på så populære tjenester som Rest API. Å sikre en Rest API er mye vanskeligere enn en vanlig nettside. Selv trivielle metoder for beskyttelse mot passord brute force og annen illegitim aktivitet fungerer ikke for Rest API.
Rest API er veldig lett å bryte fordi den får direkte tilgang til databasen. Samtidig medfører svikt i en slik tjeneste ganske alvorlige konsekvenser for næringslivet. Faktum er at Rest API vanligvis brukes ikke bare for hovednettstedet, men også for mobilapplikasjonen og noen interne forretningsressurser. Og hvis alt dette faller, så er effekten mye sterkere enn ved en enkel nettsidefeil.
Laster tungt innhold
Hvis vi får tilbud om å teste en vanlig enkeltsideapplikasjon, landingsside eller visittkortnettsted som ikke har kompleks funksjonalitet, ser vi etter tungt innhold. For eksempel store bilder som serveren sender, binære filer, pdf-dokumentasjon – vi prøver å laste ned alt dette. Slike tester laster filsystemet godt og tetter kanaler, og er derfor effektive. Det vil si at selv om du ikke legger ned serveren og laster ned en stor fil med lave hastigheter, vil du ganske enkelt tette kanalen til målserveren og da vil en tjenestenekt oppstå.
Et eksempel på en slik test viser at med en hastighet på 30 RPS sluttet nettstedet å svare eller produserte 500. serverfeil.
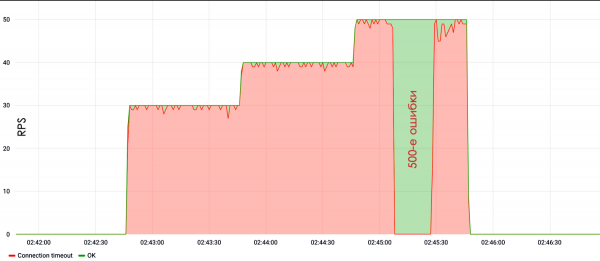
Ikke glem å sette opp servere. Du kan ofte finne at en person har kjøpt en virtuell maskin, installert Apache der, konfigurert alt som standard, installert en PHP-applikasjon, og nedenfor kan du se resultatet.
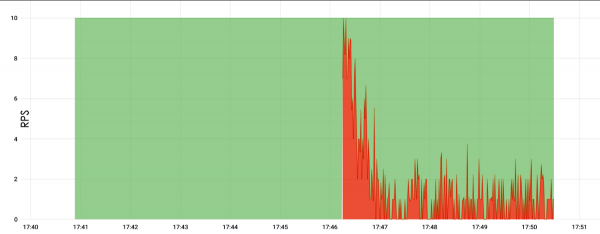
Her gikk belastningen til roten og utgjorde kun 10 RPS. Vi ventet 5 minutter og serveren krasjet. Det er riktig at det ikke er helt kjent hvorfor han falt, men det er en antagelse om at han rett og slett hadde for mye hukommelse og derfor sluttet å svare.
Bølgebasert
Det siste året eller to har bølgeangrep blitt ganske populære. Dette skyldes det faktum at mange organisasjoner kjøper visse deler av maskinvare for DDoS-beskyttelse, som krever en viss tid for å samle statistikk for å begynne å filtrere angrepet. Det vil si at de ikke filtrerer angrepet i løpet av de første 30-40 sekundene, fordi de samler data og lærer. Følgelig kan du på disse 30-40 sekundene starte så mye på nettstedet at ressursen vil ligge lenge til alle forespørsler er ryddet opp.
Ved angrepet nedenfor var det et intervall på 10 minutter, hvoretter en ny, modifisert del av angrepet kom.
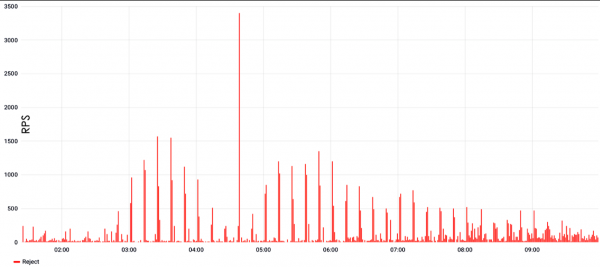
Det vil si at forsvaret lærte, begynte å filtrere, men en ny, helt annen del av angrepet kom, og forsvaret begynte å lære igjen. Faktisk slutter filtrering å fungere, beskyttelsen blir ineffektiv, og nettstedet er utilgjengelig.
Bølgeangrep er preget av svært høye verdier på toppen, det kan nå hundre tusen eller en million forespørsler per sekund, når det gjelder L7. Hvis vi snakker om L3&4, kan det være hundrevis av gigabits trafikk, eller følgelig hundrevis av mpps, hvis du teller i pakker.
Problemet med slike angrep er synkronisering. Angrepene kommer fra et botnett og krever høy grad av synkronisering for å skape en veldig stor engangsspike. Og denne koordineringen fungerer ikke alltid: noen ganger er utgangen en slags parabolsk topp, som ser ganske patetisk ut.
Ikke HTTP alene
I tillegg til HTTP på L7, liker vi å utnytte andre protokoller. Som regel har en vanlig nettside, spesielt en vanlig hosting, e-postprotokoller og MySQL som stikker ut. E-postprotokoller er utsatt for mindre belastning enn databaser, men de kan også lastes ganske effektivt og ende opp med en overbelastet CPU på serveren.
Vi var ganske vellykkede med å bruke 2016 SSH-sårbarheten. Nå er denne sårbarheten fikset for nesten alle, men dette betyr ikke at last ikke kan sendes til SSH. Kan. Det er rett og slett en enorm mengde autorisasjoner, SSH spiser opp nesten hele CPUen på serveren, og så kollapser nettsiden fra en eller to forespørsler per sekund. Følgelig kan disse en eller to forespørslene basert på loggene ikke skilles fra en legitim belastning.
Mange tilkoblinger som vi åpner i servere forblir også relevante. Tidligere var Apache skyldig i dette, nå lider nginx faktisk av dette, siden det ofte er konfigurert som standard. Antall tilkoblinger som nginx kan holde åpne er begrenset, så vi åpner dette antallet tilkoblinger, nginx godtar ikke lenger en ny tilkobling, og som et resultat fungerer ikke siden.
Testklyngen vår har nok CPU til å angripe SSL-håndtrykk. I prinsippet, som praksis viser, liker botnett noen ganger å gjøre dette også. På den ene siden er det klart at du ikke kan klare deg uten SSL, fordi Googles resultater, rangering, sikkerhet. På den annen side har SSL dessverre et CPU-problem.
L3&4
Når vi snakker om et angrep på L3&4-nivå, snakker vi vanligvis om et angrep på linknivå. En slik belastning kan nesten alltid skilles fra en legitim, med mindre det er et SYN-flom-angrep. Problemet med SYN-flom-angrep for sikkerhetsverktøy er deres store volum. Den maksimale L3&4-verdien var 1,5-2 Tbit/s. Denne typen trafikk er svært vanskelig å behandle selv for store selskaper, inkludert Oracle og Google.
SYN og SYN-ACK er pakker som brukes når du oppretter en tilkobling. Derfor er SYN-flom vanskelig å skille fra en legitim last: det er ikke klart om dette er en SYN som kom for å etablere en forbindelse, eller en del av en flom.
UDP-flom
Vanligvis har ikke angripere de egenskapene vi har, så forsterkning kan brukes til å organisere angrep. Det vil si at angriperen skanner Internett og finner enten sårbare eller feilkonfigurerte servere som for eksempel, som svar på én SYN-pakke, svarer med tre SYN-ACKer. Ved å forfalske kildeadressen fra adressen til målserveren, er det mulig å øke kraften med for eksempel tre ganger med en enkelt pakke og omdirigere trafikk til offeret.
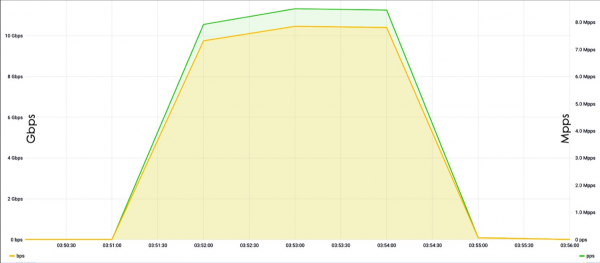
Problemet med forsterkninger er at de er vanskelige å oppdage. Nylige eksempler inkluderer den oppsiktsvekkende saken om den sårbare memcached. Pluss, nå er det mange IoT-enheter, IP-kameraer, som også stort sett er konfigurert som standard, og som standard er de konfigurert feil, noe som er grunnen til at angripere oftest gjør angrep gjennom slike enheter.
Vanskelig SYN-flom
SYN-flood er sannsynligvis den mest interessante typen angrep fra en utviklers synspunkt. Problemet er at systemadministratorer ofte bruker IP-blokkering for beskyttelse. Dessuten påvirker IP-blokkering ikke bare systemadministratorer som handler ved hjelp av skript, men også, dessverre, noen sikkerhetssystemer som kjøpes for mye penger.
Denne metoden kan bli en katastrofe, fordi hvis angriperne erstatter IP-adresser, vil selskapet blokkere sitt eget delnett. Når brannmuren blokkerer sin egen klynge, vil ekstern kommunikasjon bli forstyrret og ressursen vil svikte.
Dessuten er det ikke vanskelig å blokkere ditt eget nettverk. Hvis klientens kontor har et Wi-Fi-nettverk, eller hvis ytelsen til ressursene måles ved hjelp av ulike overvåkingssystemer, tar vi IP-adressen til dette overvåkingssystemet eller klientens kontor Wi-Fi og bruker den som kilde. På slutten ser det ut til at ressursen er tilgjengelig, men mål-IP-adressene er blokkert. Dermed kan Wi-Fi-nettverket til HighLoad-konferansen, hvor selskapets nye produkt presenteres, bli blokkert, og dette medfører visse forretningsmessige og økonomiske kostnader.
Under testing kan vi ikke bruke forsterkning gjennom memcached med noen eksterne ressurser, fordi det er avtaler om å sende trafikk kun til tillatte IP-adresser. Følgelig bruker vi forsterkning gjennom SYN og SYN-ACK, når systemet reagerer på å sende en SYN med to eller tre SYN-ACKer, og ved utgangen multipliseres angrepet med to eller tre ganger.
Verktøy
Et av hovedverktøyene vi bruker for L7-arbeidsbelastning er Yandex-tank. Spesielt brukes et fantom som en pistol, pluss at det er flere skript for å generere kassetter og for å analysere resultatene.
Tcpdump brukes til å analysere nettverkstrafikk, og Nmap brukes til serveranalyse. OpenSSL og litt tilpasset magi med DPDK-biblioteket brukes til å generere last på L3- og L4-nivå. DPDK er et Intel-bibliotek som lar deg jobbe med nettverksgrensesnittet uten å gå gjennom stakken. Linux, og dermed øke effektiviteten. Naturligvis bruker vi DPDK ikke bare på nivå 3 og L4, men også på L7, fordi det lar oss generere svært høye belastninger, opptil flere millioner forespørsler per sekund fra en enkelt maskin.
Vi bruker også visse trafikkgeneratorer og spesialverktøy som vi skriver for spesifikke tester. Hvis vi husker sårbarheten under SSH, kan ikke settet ovenfor utnyttes. Hvis vi angriper e-postprotokollen, tar vi e-postverktøy eller bare skriver skript på dem.
Funn
Som en konklusjon vil jeg si:
- I tillegg til klassisk belastningstesting er det nødvendig å gjennomføre stresstesting. Vi har et reelt eksempel der en partners underleverandør kun utførte lasttesting. Den viste at ressursen tåler normal belastning. Men så dukket det opp en unormal belastning, besøkende på nettstedet begynte å bruke ressursen litt annerledes, og som et resultat la underleverandøren seg. Dermed er det verdt å se etter sårbarheter selv om du allerede er beskyttet mot DDoS-angrep.
- Det er nødvendig å isolere noen deler av systemet fra andre. Hvis du har et søk, må du flytte det til separate maskiner, det vil si ikke engang til Docker. For hvis søk eller autorisasjon mislykkes, vil i det minste noe fortsette å fungere. Når det gjelder en nettbutikk, vil brukerne fortsette å finne produkter i katalogen, gå fra aggregatoren, kjøpe hvis de allerede er autorisert, eller autorisere via OAuth2.
- Ikke overse alle typer skytjenester.
- Bruk CDN ikke bare for å optimalisere nettverksforsinkelser, men også som et middel for beskyttelse mot angrep på utmattelse av kanaler og rett og slett oversvømmelser til statisk trafikk.
- Det er nødvendig å bruke spesialiserte beskyttelsestjenester. Du kan ikke beskytte deg mot L3&4-angrep på kanalnivå, fordi du mest sannsynlig rett og slett ikke har en tilstrekkelig kanal. Det er heller lite sannsynlig at du vil bekjempe L7-angrep, siden de kan være veldig store. I tillegg er søket etter små angrep fortsatt prerogativet til spesielle tjenester, spesielle algoritmer.
- Oppdater regelmessig. Dette gjelder ikke bare for kjernen, men også for SSH-demonen, spesielt hvis du har dem åpne til utsiden. I prinsippet må alt oppdateres, fordi du neppe kan spore visse sårbarheter på egen hånd.
Kilde: www.habr.com
