

Kjære fellesskap, Denne artikkelen vil fokusere på effektiv lagring og henting av hundrevis av millioner små filer. På dette stadiet er den endelige løsningen foreslått for POSIX-kompatible filsystemer med full støtte for låser, inkludert klyngelåser, og tilsynelatende til og med uten krykker.
Så jeg skrev min egen tilpassede server for dette formålet.
I løpet av implementeringen av denne oppgaven klarte vi å løse hovedproblemet, og samtidig oppnå besparelser i diskplass og RAM, som klyngefilsystemet vårt nådeløst forbrukte. Faktisk er et slikt antall filer skadelig for ethvert klynget filsystem.
Tanken er denne:
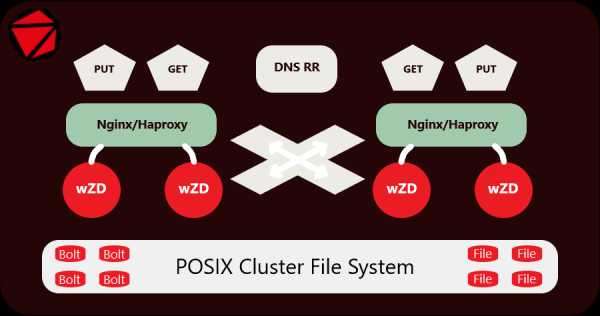
Med enkle ord lastes små filer opp gjennom serveren, de lagres direkte i arkivet, og leses også fra det, og store filer legges side om side. Opplegg: 1 mappe = 1 arkiv, totalt har vi flere millioner arkiver med små filer, og ikke flere hundre millioner filer. Og alt dette er implementert fullt ut, uten noen skript eller å legge filer i tar/zip-arkiver.
Jeg skal prøve å holde det kort, jeg beklager på forhånd hvis innlegget blir langt.
Det hele startet med at jeg ikke kunne finne en passende server i verden som kunne lagre data mottatt via HTTP-protokollen direkte inn i arkiver, uten de ulempene som ligger i konvensjonelle arkiver og objektlagring. Og grunnen til søket var Origin-klyngen på 10 servere som hadde vokst til stor skala, der 250,000,000 XNUMX XNUMX små filer allerede hadde samlet seg, og veksttrenden kom ikke til å stoppe.
For de som ikke liker å lese artikler, er litt dokumentasjon enklere:
и .
Og docker på samme tid, nå er det et alternativ bare med nginx inne i tilfelle:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdNeste:
Hvis det er mange filer, trengs det betydelige ressurser, og det verste er at noen av dem er bortkastet. For eksempel, når du bruker et klynget filsystem (i dette tilfellet MooseFS), tar filen, uavhengig av den faktiske størrelsen, alltid opp minst 64 KB. Det vil si at for filer på 3, 10 eller 30 KB kreves det 64 KB på disk. Hvis det er en kvart milliard filer, taper vi fra 2 til 10 terabyte. Det vil ikke være mulig å lage nye filer på ubestemt tid, siden MooseFS har en begrensning: ikke mer enn 1 milliard med en replika av hver fil.
Etter hvert som antallet filer øker, trengs det mye RAM for metadata. Hyppige store metadatadumper bidrar også til slitasje på SSD-stasjoner.
wZD server. Vi setter ting i orden på diskene.
Serveren er skrevet i Go. Først av alt trengte jeg å redusere antall filer. Hvordan gjøre det? På grunn av arkivering, men i dette tilfellet uten komprimering, siden filene mine bare er komprimerte bilder. BoltDB kom til unnsetning, som fortsatt måtte elimineres fra sine mangler, dette gjenspeiles i dokumentasjonen.
Totalt, i stedet for en kvart milliard filer, var det i mitt tilfelle bare 10 millioner Bolt-arkiver igjen. Hvis jeg hadde muligheten til å endre gjeldende katalogfilstruktur, ville det vært mulig å redusere den til omtrent 1 million filer.
Alle små filer pakkes inn i Bolt-arkiver, som automatisk mottar navnene på katalogene de er plassert i, og alle store filer forblir ved siden av arkivene; det er ingen vits i å pakke dem, dette kan tilpasses. Små arkiveres, store blir stående uendret. Serveren fungerer transparent med begge.
Arkitektur og funksjoner til wZD-serveren.

Serveren opererer under kontroll av operativsystemer Linux, BSD, Solaris og OSX. Jeg testet bare for AMD64-arkitekturen under Linux, men det burde også fungere for ARM64, PPC64, MIPS64.
Hovedtrekkene:
- Multithreading;
- Multiserver, gir feiltoleranse og lastbalansering;
- Maksimal åpenhet for brukeren eller utvikleren;
- Støttede HTTP-metoder: GET, HEAD, PUT og DELETE;
- Kontroll av lese- og skriveatferd via klientoverskrifter;
- Støtte for fleksible virtuelle verter;
- Støtt CRC-dataintegritet når du skriver/leser;
- Semidynamiske buffere for minimalt minneforbruk og optimal justering av nettverksytelse;
- Utsatt datakomprimering;
- I tillegg tilbys en multi-threaded archiver wZA for å migrere filer uten å stoppe tjenesten.
Virkelig erfaring:
Jeg har utviklet og testet serveren og arkiveren på live data i ganske lang tid, nå fungerer den med suksess på en klynge som inkluderer 250,000,000 15,000,000 10 små filer (bilder) plassert i 2 2 XNUMX kataloger på separate SATA-stasjoner. En klynge på XNUMX servere er en Origin-server installert bak et CDN-nettverk. For å betjene den brukes XNUMX Nginx-servere + XNUMX wZD-servere.
For de som bestemmer seg for å bruke denne serveren, vil det være lurt å planlegge katalogstrukturen, hvis aktuelt, før bruk. La meg ta en reservasjon med en gang at serveren ikke er ment å stappe alt inn i et 1 Bolt-arkiv.
Ytelsestesting:
Jo mindre størrelsen på den zippede filen er, desto raskere utføres GET- og PUT-operasjoner på den. La oss sammenligne den totale tiden for HTTP-klientskriving med vanlige filer og Bolt-arkiver, samt lesing. Arbeid med filer i størrelsene 32 KB, 256 KB, 1024 KB, 4096 KB og 32768 KB sammenlignes.
Når man jobber med Bolt-arkiver, sjekkes dataintegriteten til hver fil (CRC brukes), før opptak og også etter opptak skjer det avlesning og omberegning underveis, dette medfører naturligvis forsinkelser, men det viktigste er datasikkerhet.
Jeg gjennomførte ytelsestester på SSD-stasjoner, siden tester på SATA-stasjoner ikke viser en klar forskjell.
Grafer basert på testresultater:
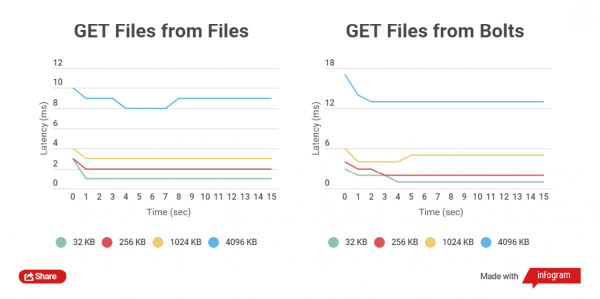
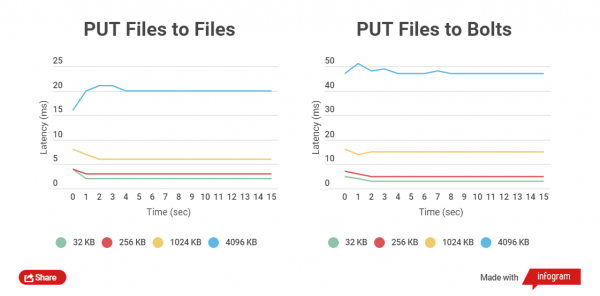
Som du kan se, for små filer er forskjellen i lese- og skrivetider mellom arkiverte og ikke-arkiverte filer liten.
Vi får et helt annet bilde når vi tester lesing og skriving av filer på 32 MB:
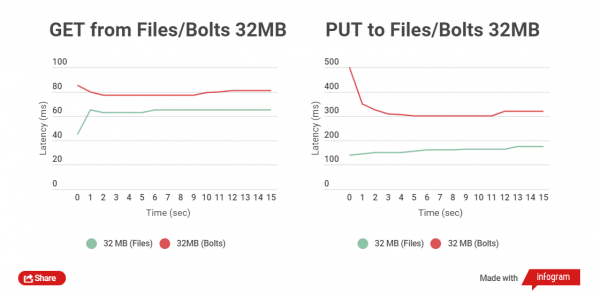
Tidsforskjellen mellom lesing av filer er innenfor 5-25 ms. Med opptak går det verre, forskjellen er omtrent 150 ms. Men i dette tilfellet er det ikke nødvendig å laste opp store filer; det er rett og slett ingen vits i å gjøre det; de kan leve atskilt fra arkivene.
*Teknisk kan du bruke denne serveren til oppgaver som krever NoSQL.
Grunnleggende metoder for å jobbe med wZD-server:
Laster en vanlig fil:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgOpplasting av en fil til Bolt-arkivet (hvis serverparameteren fmaxsize, som bestemmer den maksimale filstørrelsen som kan inkluderes i arkivet, ikke overskrides; hvis den overskrides, vil filen bli lastet opp som vanlig ved siden av arkivet):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgNedlasting av en fil (hvis det er filer med samme navn på disken og i arkivet, blir den uarkiverte filen prioritert ved nedlasting som standard):
curl -o test.jpg http://localhost/test/test.jpgLaste ned en fil fra Bolt-arkivet (tvungen):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgBeskrivelser av andre metoder finnes i dokumentasjonen.
Serveren støtter for øyeblikket bare HTTP-protokollen; den fungerer ikke med HTTPS ennå. POST-metoden støttes heller ikke (det er ennå ikke bestemt om det er nødvendig eller ikke).
Den som graver i kildekoden vil finne butterscotch der, ikke alle liker det, men jeg knyttet ikke hovedkoden til funksjonene til nettrammeverket, bortsett fra avbruddsbehandleren, så i fremtiden kan jeg raskt omskrive den for nesten alle motor.
ToDo:
- Utvikling av egen replikator og distributør + geo for mulighet for bruk i store systemer uten klyngefilsystemer (Alt for voksne)
- Mulighet for fullstendig omvendt gjenoppretting av metadata hvis de går tapt (hvis du bruker en distributør)
- Innebygd protokoll for muligheten til å bruke vedvarende nettverkstilkoblinger og drivere for forskjellige programmeringsspråk
- Avanserte muligheter for bruk av NoSQL-komponenten
- Komprimeringer av forskjellige typer (gzip, zstd, snappy) for filer eller verdier inne i Bolt-arkiver og for vanlige filer
- Kryptering av forskjellige typer for filer eller verdier inne i Bolt-arkiver og for vanlige filer
- Forsinket videokonvertering på serversiden, inkludert på GPU
Jeg har alt, jeg håper denne serveren vil være nyttig for noen, BSD-3-lisens, dobbel opphavsrett, siden hvis det ikke var noe firma der jeg jobber, ville ikke serveren blitt skrevet. Jeg er den eneste utvikleren. Jeg vil være takknemlig for eventuelle feil og funksjonsforespørsler du finner.
Kilde: www.habr.com
