

Hei, innbyggere i Khabrovsk. Klassene i første gruppe av kurset starter i dag . I denne forbindelse vil vi gjerne fortelle deg om hvordan det åpne webinaret om dette kurset fant sted.

В vi snakket om utfordringene SQL-databaser står overfor i en tid med skyer og Kubernetes. Samtidig så vi på hvordan SQL-databaser tilpasser seg og muterer under påvirkning av disse utfordringene.
Webinaret ble holdt , Google Cloud Practice Delivery Manager hos EPAM Systems.
Da trærne var små...
Først, la oss huske hvordan valget av DBMS begynte på slutten av forrige århundre. Dette vil imidlertid ikke være vanskelig, fordi valget av et DBMS i disse dager begynte og sluttet Oracle.

På slutten av 90-tallet og begynnelsen av 2-tallet var det egentlig ikke noe valg når det gjelder industrielle skalerbare databaser. Ja, det var IBM DBXNUMX, Sybase og noen andre databaser som kom og gikk, men generelt sett var de ikke så merkbare på bakgrunn av Oracle. Følgelig var ferdighetene til ingeniører på den tiden på en eller annen måte knyttet til det eneste valget som fantes.
Oracle DBA måtte kunne:
- installer Oracle Server fra distribusjonssettet;
- konfigurer Oracle Server:
- init.ora;
- lytter.ora;
- skape:
- tabellplasser;
- ordninger;
- brukere;
— utføre sikkerhetskopiering og gjenoppretting;
— utføre overvåking;
— håndtere suboptimale forespørsler.
Samtidig var det ingen spesielle krav fra Oracle DBA:
- kunne velge det optimale DBMS eller annen teknologi for lagring og behandling av data;
- gi høy tilgjengelighet og horisontal skalerbarhet (dette var ikke alltid et DBA-problem);
- god kunnskap om fagområdet, infrastruktur, applikasjonsarkitektur, OS;
- laste og losse data, migrere data mellom ulike DBMSer.
Generelt, hvis vi snakker om valget i disse dager, ligner det valget i en sovjetisk butikk på slutten av 80-tallet:

Vår tid
Siden den gang har selvfølgelig trærne vokst, verden har endret seg, og det ble noe slikt:

DBMS-markedet har også endret seg, som det tydelig fremgår av den siste rapporten fra Gartner:
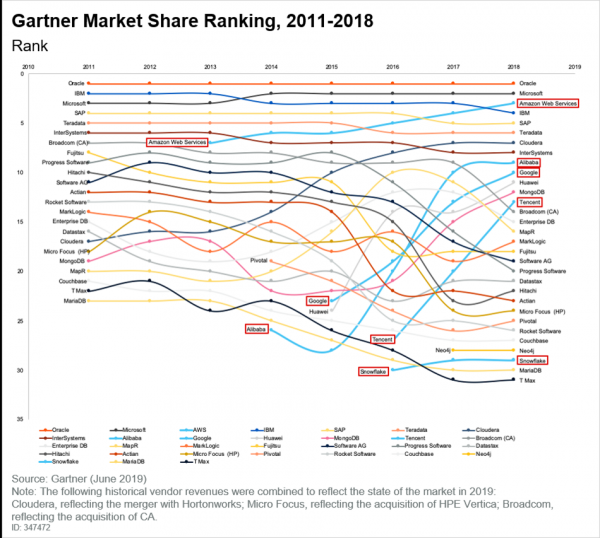
Og her skal det bemerkes at skyer, hvis popularitet vokser, har okkupert deres nisje. Hvis vi leser den samme Gartner-rapporten, vil vi se følgende konklusjoner:
- Mange kunder er på vei til å flytte applikasjoner til skyen.
- Nye teknologier dukker først opp i skyen, og det er ikke et faktum at de noen gang vil flytte til ikke-sky-infrastruktur.
- Betal-som-du-gå-prismodellen har blitt vanlig. Alle ønsker å betale kun for det de bruker, og dette er ikke engang en trend, men bare en faktaerklæring.
Hva nå?
I dag er vi alle i skyen. Og spørsmålene som dukker opp for oss er spørsmål om valg. Og det er enormt, selv om vi bare snakker om valget av DBMS-teknologier i On-premises-formatet. Vi har også administrerte tjenester og SaaS. Dermed blir valget bare vanskeligere for hvert år.
Sammen med spørsmål om valg, er det også begrensende faktorer:
- pris. Mange teknologier koster fortsatt penger;
- ferdigheter. Hvis vi snakker om fri programvare, så oppstår spørsmålet om ferdigheter, siden fri programvare krever tilstrekkelig kompetanse fra menneskene som distribuerer og driver den;
- funksjonell. Ikke alle tjenester som er tilgjengelige i skyen og bygget, for eksempel, selv på samme Postgres, har de samme funksjonene som Postgres On-premises. Dette er en viktig faktor som må være kjent og forstått. Dessuten blir denne faktoren viktigere enn kunnskap om noen skjulte funksjoner i en enkelt DBMS.
Hva forventes av DA/DE nå:
- god forståelse av fagområdet og applikasjonsarkitektur;
- muligheten til å velge riktig DBMS-teknologi på riktig måte, med tanke på oppgaven for hånden;
- evnen til å velge den optimale metoden for å implementere den valgte teknologien i sammenheng med eksisterende begrensninger;
- evne til å utføre dataoverføring og migrering;
- evne til å implementere og drifte utvalgte løsninger.
Nedenfor eksempel basert på GCP demonstrerer hvordan valget av en eller annen teknologi for arbeid med data fungerer avhengig av strukturen:
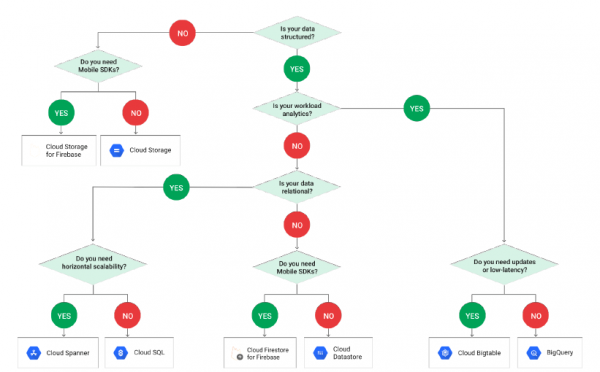
Vær oppmerksom på at PostgreSQL ikke er inkludert i skjemaet, og dette er fordi det er skjult under terminologien CloudSQL. Og når vi kommer til Cloud SQL, må vi ta et valg igjen:
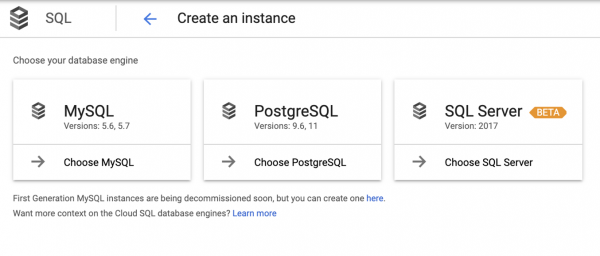
Det skal bemerkes at dette valget ikke alltid er klart, så applikasjonsutviklere styres ofte av intuisjon.
totalt:
- Jo lenger du kommer, jo mer presserende blir spørsmålet om valg. Og selv om du bare ser på GCP, administrerte tjenester og SaaS, så vises en viss omtale av RDBMS bare på det fjerde trinnet (og der er Spanner i nærheten). I tillegg vises valget av PostgreSQL i 4. trinn, og ved siden av er det også MySQL og SQL Server, dvs. det er mye av alt, men du må velge.
- Vi må ikke glemme restriksjoner på bakgrunn av fristelser. I utgangspunktet vil alle ha en nøkkel, men det er dyrt. Som et resultat ser en typisk forespørsel omtrent slik ut: "Vennligst gjør oss til en nøkkel, men for prisen av Cloud SQL er dere profesjonelle!"

Hva skal vi gjøre?
Uten å påstå å være den ultimate sannheten, la oss si følgende:
Vi må endre vår tilnærming til læring:
- det er ingen vits i å undervise slik DBA-er ble undervist før;
- kunnskap om ett produkt er ikke lenger nok;
- men å kjenne dusinvis på nivå med én er umulig.
Du må vite ikke bare og ikke hvor mye produktet er, men:
- bruk tilfelle av søknaden;
- ulike distribusjonsmetoder;
- fordeler og ulemper ved hver metode;
- lignende og alternative produkter for å gjøre et informert og optimalt valg og ikke alltid til fordel for et kjent produkt.
Du må også kunne migrere data og forstå de grunnleggende prinsippene for integrasjon med ETL.
Virkelig sak
I den siste tiden var det nødvendig å lage en backend for en mobilapplikasjon. Da arbeidet begynte med det, var backend allerede utviklet og klar for implementering, og utviklingsteamet brukte omtrent to år på dette prosjektet. Følgende oppgaver ble satt:
- bygge CI/CD;
- gjennomgå arkitekturen;
- sette det hele i drift.
Selve applikasjonen var mikrotjenester, og Python/Django-koden ble utviklet fra bunnen av og direkte i GCP. Når det gjelder målgruppen, ble det antatt at det ville være to regioner - USA og EU, og trafikken ble distribuert gjennom Global Load Balancer. Alle arbeidsbelastninger og dataarbeidsbelastning kjørte på Google Kubernetes Engine.
Når det gjelder dataene, var det 3 strukturer:
- Skylagring;
- Datalager;
- Cloud SQL (PostgreSQL).
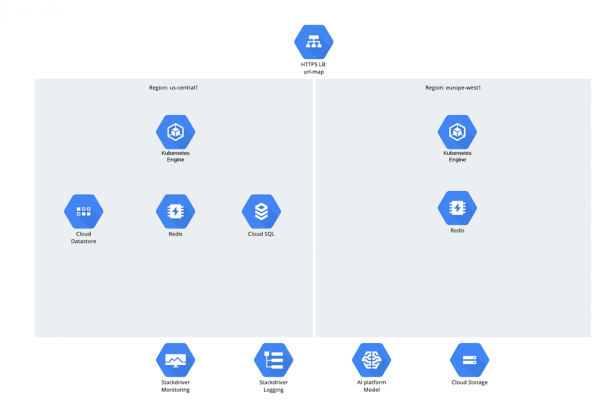
Man kan lure på hvorfor Cloud SQL ble valgt? For å si det sant har et slikt spørsmål forårsaket en slags pinlig pause de siste årene - det er en følelse av at folk har blitt sjenerte for relasjonsdatabaser, men likevel fortsetter de å bruke dem aktivt ;-).
Når det gjelder vårt tilfelle, ble Cloud SQL valgt av følgende grunner:
- Applikasjonen er som nevnt utviklet ved hjelp av Django, og den har en modell for å kartlegge vedvarende data fra en SQL-database til Python-objekter (Django ORM).
- Selve rammeverket støttet en ganske begrenset liste over DBMS-er:
- PostgreSQL;
- MariaDB;
- MySQL;
- orakler;
- SQLite.
Følgelig ble PostgreSQL valgt fra denne listen ganske intuitivt (vel, det er egentlig ikke Oracle å velge).
Hva manglet:
- applikasjonen ble bare distribuert i 2 regioner, og en tredje dukket opp i planer (Asia);
- Databasen var lokalisert i den nordamerikanske regionen (Iowa);
- fra kundens side var det bekymringer om mulig tilgangsforsinkelser fra Europa og Asia og avbrudd i tjeneste i tilfelle DBMS nedetid.
Til tross for at Django selv kan jobbe med flere databaser parallelt og dele dem inn i lesing og skriving, var det ikke så mye skriving i applikasjonen (mer enn 90 % er lesing). Og generelt, og generelt, hvis det var mulig å gjøre lese-replika av hovedbasen i Europa og Asia, vil dette være en kompromissløsning. Vel, hva er så komplisert med det?
Vanskeligheten var at kunden ikke ønsket å gi opp å bruke administrerte tjenester og Cloud SQL. Og mulighetene til Cloud SQL er begrenset for øyeblikket. Cloud SQL støtter høy tilgjengelighet (HA) og Read Replica (RR), men samme RR støttes bare i én region. Etter å ha opprettet en database i den amerikanske regionen, kan du ikke lage en lesereplika i den europeiske regionen ved å bruke Cloud SQL, selv om Postgres selv ikke hindrer deg i å gjøre dette. Korrespondanse med Google-ansatte førte ingen steder og endte med løfter i stil med "vi kjenner problemet og jobber med det, en dag vil problemet bli løst."
Hvis vi lister opp egenskapene til Cloud SQL kort, vil det se omtrent slik ut:
1. Høy tilgjengelighet (HA):
- innenfor én region;
- via diskreplikering;
- PostgreSQL-motorer brukes ikke;
- automatisk og manuell kontroll mulig - failover/failback;
- Når du bytter, er DBMS utilgjengelig i flere minutter.
2. Les replika (RR):
- innenfor én region;
- varm standby;
- PostgreSQL streaming replikering.
I tillegg, som vanlig, står du alltid overfor noen når du velger en teknologi begrensninger:
- kunden ønsket ikke å opprette enheter og bruke IaaS, bortsett fra gjennom GKE;
- kunden ønsker ikke å distribuere selvbetjent PostgreSQL/MySQL;
- Vel, generelt sett ville Google Spanner vært ganske egnet hvis det ikke var for prisen, men Django ORM kan ikke jobbe med det, men det er en god ting.
Med tanke på situasjonen fikk kunden et oppfølgingsspørsmål: "Kan du gjøre noe lignende slik at det er som Google Spanner, men også fungerer med Django ORM?"
Løsningsalternativ nr. 0
Det første som kom til tankene:
- holde deg innenfor CloudSQL;
- det vil ikke være noen innebygd replikering mellom regioner i noen form;
- prøv å knytte en replika til en eksisterende Cloud SQL av PostgreSQL;
- lanser en PostgreSQL-forekomst et sted og på en eller annen måte, men berør i det minste ikke master.
Akk, det viste seg at dette ikke kan gjøres, fordi det ikke er tilgang til verten (den er i et helt annet prosjekt) - pg_hba og så videre, og det er heller ingen tilgang under superbruker.
Løsningsalternativ nr. 1
Etter videre refleksjon og tatt i betraktning tidligere omstendigheter, endret tankegangen seg noe:
- Vi prøver fortsatt å holde oss innenfor CloudSQL, men vi bytter til MySQL, fordi Cloud SQL av MySQL har en ekstern master, som:
— er en proxy for ekstern MySQL;
- ser ut som en MySQL-forekomst;
- oppfunnet for å migrere data fra andre skyer eller lokale.
Siden oppsett av MySQL-replikering ikke krever tilgang til verten, fungerte i prinsippet alt, men det var veldig ustabilt og upraktisk. Og da vi gikk videre, ble det helt skummelt, fordi vi satte ut hele strukturen med terraform, og plutselig viste det seg at den eksterne masteren ikke ble støttet av terraform. Ja, Google har en CLI, men av en eller annen grunn fungerte alt her nå og da - noen ganger blir det opprettet, noen ganger blir det ikke opprettet. Kanskje fordi CLI ble oppfunnet for ekstern datamigrering, og ikke for replikaer.
På dette tidspunktet ble det faktisk klart at Cloud SQL ikke er egnet i det hele tatt. Som de sier, vi gjorde alt vi kunne.
Løsningsalternativ nr. 2
Siden det ikke var mulig å holde seg innenfor Cloud SQL-rammeverket, prøvde vi å formulere krav til en kompromissløsning. Kravene viste seg å være følgende:
- arbeid i Kubernetes, maksimal bruk av ressurser og muligheter til Kubernetes (DCS, ...) og GCP (LB, ...);
- mangel på ballast fra en haug med unødvendige ting i skyen som HA proxy;
- muligheten til å kjøre PostgreSQL eller MySQL i hoved-HA-regionen; i andre regioner - HA fra RR i hovedregionen pluss kopien (for pålitelighet);
- multi master (jeg ønsket ikke å kontakte ham, men det var ikke veldig viktig)
.
Som et resultat av disse kravene, spassende DBMS og bindingsmuligheter:
- MySQL Galera;
- KakerlakkDB;
- PostgreSQL-verktøy
:
- pgpool-II;
— Patroni.
MySQL Galera
MySQL Galera-teknologien er utviklet av Codership og er en plugin for InnoDB. Egenskaper:
- multi master;
- synkron replikering;
- lesing fra hvilken som helst node;
- opptak til hvilken som helst node;
- innebygd HA-mekanisme;
- Det er et Helm-diagram fra Bitnami.
KakerlakkDB
I følge beskrivelsen er tingen absolutt bombe og er et åpen kildekode-prosjekt skrevet i Go. Hoveddeltakeren er Cockroach Labs (grunnlagt av folk fra Google). Denne relasjonelle DBMS ble opprinnelig designet for å være distribuert (med horisontal skalering ut av esken) og feiltolerant. Forfatterne fra selskapet skisserte målet om å "kombinere rikdommen til SQL-funksjonalitet med den horisontale tilgjengeligheten som er kjent for NoSQL-løsninger."
En fin bonus er støtte for post-gress-tilkoblingsprotokollen.
Pgpool
Dette er et tillegg til PostgreSQL, faktisk en ny enhet som tar over alle tilkoblinger og behandler dem. Den har sin egen lastbalanser og parser, lisensiert under BSD-lisensen. Det gir mange muligheter, men ser noe skummelt ut, fordi tilstedeværelsen av en ny enhet kan bli kilden til noen ekstra eventyr.
Patroni
Dette er det siste øynene mine falt på, og som det viste seg, ikke forgjeves. Patroni er et åpen kildekodeverktøy, som i hovedsak er en Python-demon som lar deg automatisk vedlikeholde PostgreSQL-klynger med ulike typer replikering og automatisk rollebytte. Tingen viste seg å være veldig interessant, siden den integreres godt med kuberen og ikke introduserer noen nye enheter.
Hva valgte du til slutt?
Valget var ikke lett:
- KakerlakkDB - ild, men mørkt;
- MySQL Galera - heller ikke dårlig, det brukes mange steder, men MySQL;
- Pgpool — mange unødvendige enheter, så som så integrasjon med skyen og K8s;
- Patroni - utmerket integrasjon med K8s, ingen unødvendige enheter, integreres godt med GCP LB.
Dermed falt valget på Patroni.
Funn
Det er på tide å oppsummere kort. Ja, verden av IT-infrastruktur har endret seg betydelig, og dette er bare begynnelsen. Og hvis skyene før bare var en annen type infrastruktur, er alt annerledes nå. Dessuten dukker det stadig opp innovasjoner i skyene, de vil dukke opp, og kanskje de vil vises bare i skyene, og først da, ved innsats fra oppstart, vil de bli overført til lokale.
Når det gjelder SQL, vil SQL leve. Dette betyr at du må kjenne til PostgreSQL og MySQL og kunne jobbe med dem, men enda viktigere er det å kunne bruke dem riktig.
Kilde: www.habr.com
