


Vi har allerede snakket om , som lar deg utvikle distribuerte applikasjoner og pakke dem. Alt som gjenstår er å lære hvordan du distribuerer og administrerer disse applikasjonene. Ikke bekymre deg, vi har deg dekket! Vi har samlet alle de beste fremgangsmåtene for å jobbe med Tarantool Cartridge og skrevet , som vil distribuere pakken til servere, starte instanser, kombinere dem til en klynge, konfigurere autorisasjon, bootstrappe vshard, aktivere automatisk failover og oppdatere klyngekonfigurasjonen.
Interessert? Les videre, så forteller og viser vi deg alt.
La oss starte med et eksempel
Vi vil bare dekke en del av rollens funksjonalitet. En fullstendig beskrivelse av alle dens funksjoner og inndataparametere finner du alltid i Men det er bedre å prøve én gang enn å se hundre ganger, så la oss distribuere en liten applikasjon.
Tarantool-patronen har Å lage en liten Cartridge-applikasjon som lagrer informasjon om bankklienter og kontoene deres, og tilbyr et API for datahåndtering via HTTP. For å oppnå dette beskriver applikasjonen to mulige roller: api и storage, som kan tilordnes til instanser.
Cartridge i seg selv forklarer ikke hvordan man starter prosesser; den gir bare muligheten til å konfigurere allerede kjørende instanser. Brukeren må gjøre resten selv: distribuere konfigurasjonsfiler, starte tjenester og konfigurere topologien. Men vi skal ikke gjøre alt dette; Ansible vil gjøre det for oss.
Fra ord til gjerninger
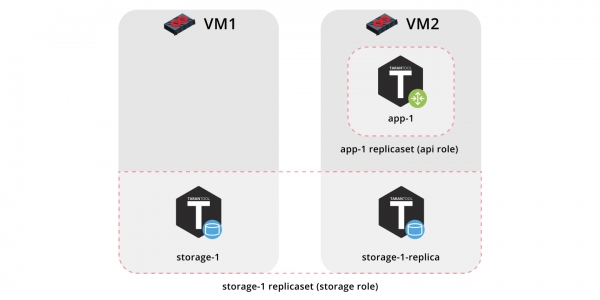
Så, la oss distribuere applikasjonen vår til to virtuelle maskiner og sette opp en enkel topologi:
- Replikasett
app-1vil implementere rollenapi, som inkluderer rollenvshard-routerDet vil bare være ett eksempel her. - Replikasett
storage-1innser rollenstorage(og samtidigvshard-storage), legger vi til to instanser fra forskjellige maskiner her.
For å kjøre eksemplet trenger vi и (versjon 2.8 eller nyere).
Selve rollen er i Dette er et arkiv som lar deg dele utviklingen din og bruke ferdige roller.
La oss klone eksempelrepositoriet:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git
$ cd deploy-tarantool-cartridge-app && git checkout 1.0.0La oss sette opp virtuelle maskiner:
$ vagrant upInstaller Tarantool Cartridge Ansible-rollen:
$ ansible-galaxy install tarantool.cartridge,1.0.1La oss starte den installerte rollen:
$ ansible-playbook -i hosts.yml playbook.ymlVi venter til handlingsplanen er ferdig, og går deretter videre til og nyt resultatet:
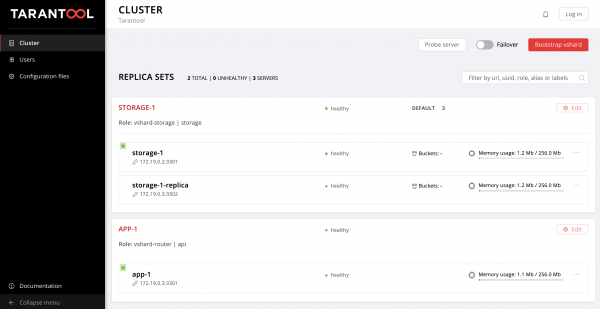
Du kan helle inn data. Kult, ikke sant?
La oss nå finne ut hvordan vi kan jobbe med dette, og samtidig legge til et nytt replikasett i topologien.
La oss begynne å finne ut av det
Så hva skjedde?
Vi har satt opp to virtuelle maskiner og kjørt Ansible-håndboken som konfigurerte klyngen vår. La oss ta en titt på innholdet i filen. playbook.yml:
---
- name: Deploy my Tarantool Cartridge app
hosts: all
become: true
become_user: root
tasks:
- name: Import Tarantool Cartridge role
import_role:
name: tarantool.cartridgeIngenting interessant skjer her, vi lanserer den ansvarlige rollen som heter tarantool.cartridge.
Alle de viktigste tingene (nemlig klyngekonfigurasjonen) er i -fil hosts.yml:
---
all:
vars:
# common cluster variables
cartridge_app_name: getting-started-app
cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package
cartridge_cluster_cookie: app-default-cookie # cluster cookie
# common ssh options
ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key
ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no'
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
app-1:
config:
advertise_uri: '172.19.0.3:3301'
http_port: 8182
storage-1-replica:
config:
advertise_uri: '172.19.0.3:3302'
http_port: 8183
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
# GROUP INSTANCES BY REPLICA SETS
replicaset_app_1:
vars: # replica set configuration
replicaset_alias: app-1
failover_priority:
- app-1 # leader
roles:
- 'api'
hosts: # replica set instances
app-1:
replicaset_storage_1:
vars: # replica set configuration
replicaset_alias: storage-1
weight: 3
failover_priority:
- storage-1 # leader
- storage-1-replica
roles:
- 'storage'
hosts: # replica set instances
storage-1:
storage-1-replica:Alt vi trenger å gjøre er å lære hvordan vi administrerer instanser og replikasett ved å endre innholdet i denne filen. Vi legger til nye seksjoner senere. For å unngå forvirring om hvor du skal legge dem til, kan du se den endelige versjonen av denne filen. hosts.updated.yml, som ligger i eksempelarkivet.
Forekomstbehandling
I Ansible-termer er hver instans en vert (ikke å forveksle med en maskinvareserver), dvs. en infrastrukturnode som Ansible administrerer. For hver vert kan vi spesifisere tilkoblingsparametere (som ansible_host и ansible_user), samt forekomstkonfigurasjonen. Beskrivelser av forekomster finnes i avsnittet hosts.
La oss se på instanskonfigurasjonen storage-1:
all:
vars:
...
# INSTANCES
hosts:
storage-1:
config:
advertise_uri: '172.19.0.2:3301'
http_port: 8181
...I en variabel config vi spesifiserte instansparametrene - advertise URI и HTTP port.
Nedenfor er instansparametrene app-1 и storage-1-replica.
Vi må fortelle Ansible tilkoblingsparametrene for hver instans. Det virker logisk å gruppere instanser etter virtuell maskin. For dette formålet grupperes instanser. host1 и host2, og i hver gruppe i seksjonen vars verdier er angitt ansible_host и ansible_user for én virtuell maskin. Og i seksjonen hosts — verter (også kjent som instanser) som er en del av denne gruppen:
all:
vars:
...
hosts:
...
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
# first machine connection options
ansible_host: 172.19.0.2
ansible_user: vagrant
hosts: # instances to be started on the first machine
storage-1:
host2:
vars:
# second machine connection options
ansible_host: 172.19.0.3
ansible_user: vagrant
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:Vi begynner å forandre oss hosts.ymlLa oss legge til to eksempler til, storage-2-replica på den første virtuelle maskinen og storage-2 på den andre:
all:
vars:
...
# INSTANCES
hosts:
...
storage-2: # <==
config:
advertise_uri: '172.19.0.3:3303'
http_port: 8184
storage-2-replica: # <==
config:
advertise_uri: '172.19.0.2:3302'
http_port: 8185
children:
# GROUP INSTANCES BY MACHINES
host1:
vars:
...
hosts: # instances to be started on the first machine
storage-1:
storage-2-replica: # <==
host2:
vars:
...
hosts: # instances to be started on the second machine
app-1:
storage-1-replica:
storage-2: # <==
...La oss kjøre Ansible-håndboken:
$ ansible-playbook -i hosts.yml
--limit storage-2,storage-2-replica
playbook.ymlVær oppmerksom på alternativet --limitSiden hver klyngeinstans er en vert i Ansible-termer, kan vi eksplisitt spesifisere hvilke instanser som skal konfigureres når vi kjører en playbook.
La oss gå tilbake til nettgrensesnittet og vi ser våre nye tilfeller:
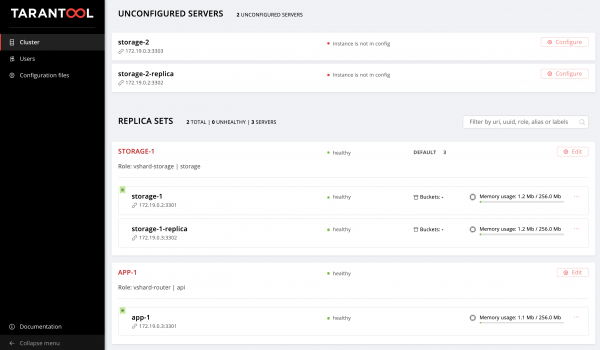
La oss ikke stoppe der, men mestre topologihåndtering.
Topologistyring
La oss kombinere de nye instansene våre til et replikasett storage-2La oss legge til en ny gruppe. replicaset_storage_2 og vi vil beskrive parameterne til replikasettet i dets variabler analogt med replicaset_storage_1I seksjonen hosts La oss spesifisere hvilke forekomster som skal inkluderes i denne gruppen (det vil si replikasettet vårt):
---
all:
vars:
...
hosts:
...
children:
...
# GROUP INSTANCES BY REPLICA SETS
...
replicaset_storage_2: # <==
vars: # replicaset configuration
replicaset_alias: storage-2
weight: 2
failover_priority:
- storage-2
- storage-2-replica
roles:
- 'storage'
hosts: # replicaset instances
storage-2:
storage-2-replica:La oss kjøre handlingsplanen igjen:
$ ansible-playbook -i hosts.yml
--limit replicaset_storage_2
--tags cartridge-replicasets
playbook.ymlI parameteren --limit Denne gangen sendte vi navnet på gruppen som tilsvarer replikasettet vårt.
La oss vurdere alternativet tags.
Rollen vår utfører sekvensielt ulike oppgaver, som er merket med følgende koder:
cartridge-instancesinstansadministrasjon (konfigurasjon, tilkobling til medlemskap);cartridge-replicasetstopologihåndtering (håndtering av replikasett og permanent sletting (utvisning) av instanser fra klyngen);cartridge-config: administrere andre klyngeparametere (vshard bootstrapping, automatisk failover-modus, autorisasjonsparametere og applikasjonskonfigurasjon).
Vi kan eksplisitt spesifisere hvilken del av arbeidet vi ønsker å utføre, og da vil rollen hoppe over resten av oppgavene. I vårt tilfelle ønsker vi bare å jobbe med topologien, så vi spesifiserte cartridge-replicasets.
La oss evaluere resultatene av arbeidet vårt. Vi finner et nytt replikasett på .
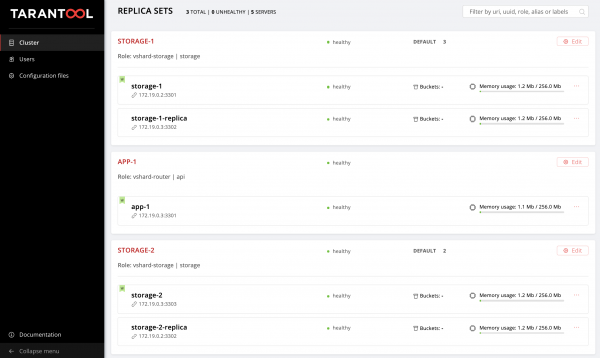
Hurra!
Eksperimenter med å endre konfigurasjonene til forekomster og replikasett, og se hvordan klyngetopologien endres. Du kan prøve ut ulike driftsscenarier, for eksempel: eller øke memtx_memoryRollen vil forsøke å gjøre dette uten å starte forekomsten på nytt for å redusere potensiell nedetid for applikasjonen din.
Ikke glem å løpe vagrant haltfor å stoppe de virtuelle maskinene når du er ferdig med å jobbe med dem.
Hva er under panseret?
Her skal jeg gå mer i detalj om hva som skjedde under panseret til Ansible-rollen under eksperimentene våre.
La oss se på trinnene for å distribuere et Cartridge-program.
Installere pakken og starte instanser
Først må du levere pakken til serveren og installere den. For øyeblikket kan rollen fungere med RPM- og DEB-pakker.
Deretter starter vi instansene. Det er veldig enkelt: hver instans er en separat instans. systemd-tjeneste. Jeg skal forklare med et eksempel:
$ systemctl start myapp@storage-1Denne kommandoen vil starte instansen. storage-1 приложения myappDen lanserte instansen vil søke etter sin в /etc/tarantool/conf.d/Forekomstlogger kan vises ved hjelp av journald.
Enhetsfil /etc/systemd/system/myapp@.sevice for systemd-tjenesten vil bli levert sammen med pakken.
Ansible har innebygde moduler for å installere pakker og administrere systemd-tjenester, men vi har ikke funnet opp noe nytt her.
Konfigurering av klyngetopologi
Og det er her det blir interessant. Du er sikkert enig i at det ville være rart å bry seg med en spesiell Ansible-rolle for å installere pakker og kjøre systemd-tjenester.
Du kan konfigurere klyngen manuelt:
- Det første alternativet: åpne nettgrensesnittet og klikk på knappene. Dette fungerer fint for engangsstart av flere instanser.
- Det andre alternativet er å bruke GraphQl API. Dette muliggjør automatisering, for eksempel å skrive et Python-skript.
- Det tredje alternativet (for de viljesterke): gå til serveren, koble til en av instansene ved hjelp av
tarantoolctl connectog vi utfører alle nødvendige manipulasjoner med Lua-modulencartridge.
Hovedmålet med oppfinnelsen vår er å gjøre denne vanskeligste delen av jobben for deg.
Ansible lar deg skrive dine egne moduler og bruke dem i en rolle. Rollen vår bruker disse modulene til å administrere ulike klyngekomponenter.
Hvordan fungerer det? Du beskriver den ønskede klyngetilstanden i en deklarativ konfigurasjon, og rollen sender konfigurasjonsdelen sin som input til hver modul. Modulen mottar gjeldende klyngetilstand og sammenligner den med inputen. Deretter kjøres koden gjennom en socket på en av instansene, noe som bringer klyngen til ønsket tilstand.
Resultater av
I dag forklarte og demonstrerte vi hvordan du distribuerer applikasjonen din til Tarantool Cartridge og setter opp en enkel topologi. For å gjøre dette brukte vi Ansible, et kraftig og brukervennlig verktøy som lar deg konfigurere flere infrastrukturnoder samtidig (i vårt tilfelle klyngeforekomster).
Ovenfor har vi dekket en av de mange måtene å beskrive en klyngekonfigurasjon ved hjelp av Ansible. Når du er klar til å gå videre, kan du utforske for å skrive strategier. Det kan være mer praktisk å administrere topologien ved hjelp av group_vars и host_vars.
Snart skal vi forklare hvordan du permanent sletter (utviser) instanser fra topologien, bootstrapper vshard, administrerer automatisk failover-modus, konfigurerer autorisasjon og oppdaterer klyngekonfigurasjonen. I mellomtiden kan du utforske på egenhånd. og eksperimentere med å endre klyngeparametere.
Hvis noe ikke fungerer, sørg for å Fortell oss om problemet, så fikser vi det raskt!
Kilde: www.habr.com
