

La meg forklare artikkelens tittel med en gang. I utgangspunktet planla jeg å gi gode, pålitelige råd om hvordan man får fart på refleksjon ved hjelp av et enkelt, men realistisk eksempel. Under benchmarking viste det seg imidlertid at refleksjonen ikke var så treg som jeg trodde, og LINQ var tregere enn jeg noen gang hadde forestilt meg. Og det viste seg at jeg også hadde gjort en målefeil... Detaljene i denne virkelige historien finner du under snittet og i kommentarfeltet. Siden eksemplet er ganske hverdagslig og implementert på en måte som vanligvis gjøres i bedrifter, viste det seg å være en ganske interessant demonstrasjon, etter min mening: effekten på ytelsen til artikkelens hovedemne var ikke merkbar på grunn av ekstern logikk: Moq, Autofac, EF Core og andre "bindinger".
Jeg begynte å jobbe under inntrykk av denne artikkelen:
Som du kan se, foreslår forfatteren å bruke kompilerte delegater i stedet for å få direkte tilgang til refleksjonsmetoder som en utmerket måte å øke applikasjonsytelsen betydelig. Selvfølgelig finnes det også IL-utslipp, men det er best å unngå det, da det er den mest arbeidskrevende og feilutsatte måten å utføre oppgaven på.
Siden jeg alltid har hatt en lignende oppfatning om refleksjonshastighet, hadde jeg ikke til hensikt å stille spørsmål ved forfatterens konklusjoner.
Jeg møter ofte naiv bruk av refleksjon i bedriften. En type tas. Egenskapsinformasjon hentes. SetValue-metoden kalles, og alle er fornøyde. Verdien har landet i målfeltet, alle er fornøyde. Smarte folk – seniorer og teamledere – skriver sine egne utvidelser til objektet, og baserer sine "universelle" tilordninger fra én type til en annen på denne naive implementeringen. Hovedpoenget er vanligvis dette: ta alle feltene, ta alle egenskapene, iterer over dem: hvis typemedlemsnavnene samsvarer, kjører vi SetValue. Vi fanger med jevne mellomrom unntak når en egenskap ikke finnes for en av typene, men selv her finnes det en måte å forbedre ytelsen på: Prøv/fang.
Jeg har sett folk gjenoppfinne parsere og mappere uten å være fullt informert om hvordan hjulene som ble oppfunnet før dem fungerte. Jeg har sett folk skjule sine naive implementeringer bak strategier, grensesnitt og injeksjoner, som om det ville unnskylde det påfølgende kaoset. Jeg rynket på nesen av slike implementeringer. Faktisk målte jeg ikke det faktiske ytelsesforbruket, og når det var mulig, byttet jeg ganske enkelt ut implementeringen med en mer "optimal" en da jeg hadde tid. Så de første målingene, som diskuteres nedenfor, forvirret meg alvorlig.
Jeg tror mange av dere, mens dere har lest Richter eller andre ideologer, har kommet over den helt berettigede påstanden om at refleksjon i kode er et fenomen som har en ekstremt negativ innvirkning på ytelsen til en applikasjon.
Å kalle refleksjon tvinger CLR-en til å gå gjennom sammenstillinger for å finne den rette, hente metadataene deres, analysere den, og så videre. Videre fører refleksjon under sekvensgjennomgang til store minneallokeringer. Vi forbruker minne, CLR pakker ut GC-en og fryser deretter. Dette burde være merkbart tregt, tro meg. De enorme mengdene minne i moderne produksjonsservere eller skymaskiner forhindrer ikke høye prosesseringsforsinkelser. Faktisk, jo mer minne du har, desto større er sannsynligheten for at du vil LEGG MERKE TIL GC-ens ytelse. Refleksjon er i teorien et unødvendig rødt flagg for det.
Likevel bruker vi alle både IoC-containere og datamappere, som også er avhengige av refleksjon, men ytelsen deres påvirkes vanligvis ikke. Det er ikke fordi avhengighetsinjeksjon og abstraksjon fra eksterne avgrensede kontekstmodeller er så nødvendige at vi uansett må ofre ytelse. Det er enklere – de påvirker egentlig ikke ytelsen nevneverdig.
Faktum er at de vanligste rammeverkene basert på refleksjon bruker alle slags triks for å optimalisere bruken. Vanligvis involverer dette en hurtigbuffer. Uttrykk og delegater kompilert fra uttrykkstrær er også vanlige. Automapperen vedlikeholder for eksempel en samtidig ordbok som mapper typer til funksjoner som kan konverteres til hverandre uten å ty til refleksjon.
Hvordan oppnås dette? I hovedsak er det ikke annerledes enn logikken plattformen selv bruker for å generere JIT-kode. Første gang en metode kalles, kompileres den (og ja, denne prosessen er ikke rask). Etterfølgende kall overfører kontrollen til den kompilerte metoden, og det vil ikke bli noen betydelig ytelsestap.
I vårt tilfelle kan vi også dra nytte av JIT-kompilering og deretter bruke den kompilerte oppførselen med samme ytelse som dens AOT-motparter. Uttrykk vil komme til unnsetning i dette tilfellet.
Prinsippet det gjelder kan kort formuleres slik:
Det endelige resultatet av refleksjonen bør mellomlagres som en delegat som inneholder den kompilerte funksjonen. Det er også fornuftig å mellomlagre alle nødvendige objekter med typeinformasjon i felt av arbeidstypen din som er lagret eksternt.
Det er logikk i dette. Sunn fornuft sier oss at hvis noe kan kompileres og mellomlagres, så bør det gjøres det.
Når man ser fremover, bør det bemerkes at mellomlagring har sine fordeler når man jobber med refleksjon, selv uten å bruke den foreslåtte uttrykkskompileringsmetoden. Faktisk gjentar jeg her bare poengene til forfatteren av artikkelen jeg lenket til ovenfor.
Nå, over til koden. La oss se på et eksempel basert på et nylig smertepunkt jeg møtte i et større produksjonsmiljø hos en stor finansinstitusjon. Alle enheter er fiktive, så ingen vil gjette.
Det finnes en bestemt enhet. La oss kalle den Kontakt. Det finnes e-poster med standardiserte brødtekster, som parseren og hydratoren oppretter disse kontaktene fra. En e-post kommer inn, vi leser den, analyserer den i nøkkelverdipar, oppretter en kontakt og lagrer den i databasen.
Det er enkelt. La oss si at en kontakt har egenskaper som fullt navn, alder og telefonnummer. Disse dataene overføres i e-posten. Bedriften ønsker også støtte for raskt å kunne legge til nye nøkler for å tilordne enhetsegenskaper til par i e-postens brødtekst. Dette er i tilfelle noen gjør en skrivefeil i malen, eller hvis tilordningen må lanseres raskt fra en ny partner før utgivelsen, og tilpasses et nytt format. Da kan vi legge til en ny tilordningskorrelasjon som en billig datafiks. Så dette er et eksempel fra virkeligheten.
Vi implementerer det, lager tester. Det fungerer.
Jeg vil ikke vise koden: det finnes mye kildekode, og den er tilgjengelig på GitHub via lenken på slutten av artikkelen. Du kan laste den ned, finjustere den til det ugjenkjennelige og måle hvordan det vil påvirke tilfellet ditt. Jeg vil bare vise koden for to malmetoder som skiller hydratoren som skulle være rask fra hydratoren som skulle være treg.
Logikken er som følger: malmetoden mottar par generert av parseren sin kjernelogikk. LINQ-laget er parseren og hydratorens kjernelogikk, som spør databasekonteksten og matcher nøkler med parseren sin par (det finnes ikke-LINQ-kode for disse funksjonene for sammenligning). Parene sendes deretter til hovedhydreringsmetoden, og parverdiene settes til de tilsvarende entitetsegenskapene.
"Rask" (prefikset Rask i referansetester):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Som vi kan se, brukes en statisk samling med egenskapssettere – kompilerte lambdaer som kaller enhetens setter. De opprettes med følgende kode:
static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
Det er generelt sett klart. Vi går gjennom egenskapene i løkker, oppretter delegater for dem, kaller settere og lagrer dem. Deretter kaller vi dem når det er nødvendig.
"Slow" (Slow-prefikset i referansetester):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Her omgår vi umiddelbart egenskapene og kaller SetValue direkte.
For klarhetens skyld og som et referansepunkt implementerte jeg en naiv metode som skriver verdiene til korrelasjonsparene deres direkte til entitetsfelt. Prefikset er Manuell.
La oss nå ta BenchmarkDotNet og teste ytelsen. Og plutselig ... (spoiler alert: dette er et feil resultat; detaljer nedenfor)
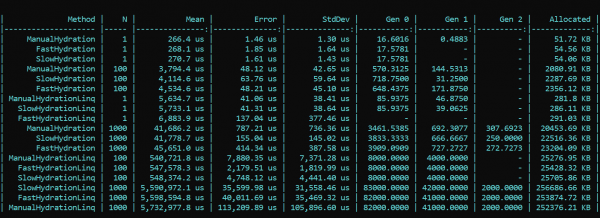
Hva ser vi her? Metoder som triumferende bærer prefikset Fast er tregere enn metoder med prefikset Slow i nesten alle passeringer. Dette gjelder både allokerings- og utførelseshastighet. På den annen side reduserer en vakker og elegant mapping-implementering, som bruker LINQ-metoder når det er mulig, ytelsen betydelig. Forskjellen er størrelsesordener. Denne trenden endres ikke med ulikt antall passeringer. Den eneste forskjellen er skala. Med LINQ er det 4–200 ganger tregere, med omtrent samme mengde søppel.
OPPDATERT
Jeg kunne ikke tro mine egne øyne, men enda viktigere, kollegaen vår trodde verken mine egne øyne eller koden min - Etter å ha testet løsningen min på nytt, oppdaget og påpekte han på en strålende måte en feil jeg hadde oversett på grunn av en rekke endringer i den første implementeringen. Etter å ha fikset den oppdagede feilen i Moq-oppsettet, gikk alle resultatene tilbake til det normale. Resultatene fra den nye testingen viser at hovedtrenden forblir uendret – LINQ påvirker fortsatt ytelsen mer enn refleksjon. Det er imidlertid fint å se at arbeidet med å kompilere uttrykk er verdt det, og resultatene er synlige både i allokering og utførelsestid. Den første kjøringen, når statiske felt initialiseres, er naturlig nok tregere for den "raske" metoden, men deretter endrer situasjonen seg.
Her er resultatet av retesten:
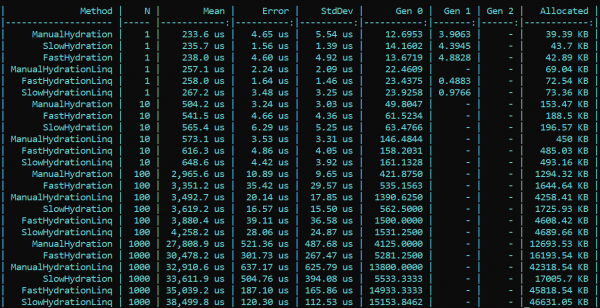
Konklusjon: Når man bruker refleksjon i bedriften, er det ikke nødvendig å ty til triks – LINQ vil redusere ytelsen betydelig. I metoder med høy belastning som krever optimalisering, kan imidlertid refleksjon bevares i form av initialiseringsverktøy og delegeringskompilatorer, som deretter gir "rask" logikk. På denne måten kan du bevare både fleksibiliteten til refleksjonen og hastigheten til applikasjonen din.
Referansekoden er tilgjengelig her. Alle som er interesserte kan dobbeltsjekke uttalelsene mine:
PS: Koden i testene bruker IoC, mens benchmark-testene bruker en eksplisitt konstruksjon. Dette er fordi jeg i den endelige implementeringen eliminerte alle faktorer som kunne påvirke ytelsen og forvrenge resultatene.
PPS: Takk til brukeren For å ha oppdaget feilen min i Moq-oppsettet, som påvirket de første målingene. Hvis noen lesere har nok karma, vennligst gi den en like. Noen stoppet, noen leste nøye, noen dobbeltsjekket og påpekte feilen. Jeg synes dette fortjener respekt og sympati.
PPPS: Takk til den omhyggelige leseren som gravde seg inn i stilen og layouten. Jeg er helt for konsistens og brukervennlighet. Presentasjonens diplomati er mye å ønske, men jeg har tatt kritikken til etterretning. Vennligst sett i gang.
Kilde: www.habr.com
