

Denne artikkelen er en oversettelse av artikkelen min på medium - , som viste seg å være ganske populær, sannsynligvis på grunn av sin enkelhet. Derfor bestemte jeg meg for å skrive det på russisk og legge til litt for å gjøre det klart for en vanlig person som ikke er dataspesialist hva et datavarehus (DW) er, og hva en datainnsjø er (Data Lake), og hvordan de komme sammen.
Hvorfor ville jeg skrive om datasjøen? Jeg har jobbet med data og analyser i over 10 år, og nå jobber jeg definitivt med big data hos Amazon Alexa AI i Cambridge, som er i Boston, selv om jeg bor i Victoria på Vancouver Island og ofte besøker Boston, Seattle , og I Vancouver, og noen ganger til og med i Moskva, snakker jeg på konferanser. Jeg skriver også av og til, men jeg skriver hovedsakelig på engelsk, og jeg har allerede skrevet , jeg har også et behov for å dele analysetrender fra Nord-Amerika, og jeg skriver noen ganger inn .
Jeg har alltid jobbet med datavarehus, og siden 2015 begynte jeg å jobbe tett med Amazon Web Services, og gikk generelt over til skyanalyse (AWS, Azure, GCP). Jeg har observert utviklingen av analyseløsninger siden 2007 og har til og med jobbet for datavarehusleverandøren Teradata og implementert det hos Sberbank, og det var da Big Data med Hadoop dukket opp. Alle begynte å si at lagringstiden var forbi og nå var alt på Hadoop, og så begynte de å snakke om Data Lake, igjen, at nå var slutten på datavarehuset definitivt kommet. Men heldigvis (kanskje dessverre for noen som tjente mye penger på å sette opp Hadoop), forsvant ikke datavarehuset.
I denne artikkelen skal vi se på hva en datainnsjø er. Denne artikkelen er ment for personer som har liten eller ingen erfaring med datavarehus.

På bildet er Lake Bled, dette er en av favorittsjøene mine, selv om jeg bare var der én gang, husket jeg den resten av livet. Men vi skal snakke om en annen type innsjø - en datainnsjø. Kanskje mange av dere allerede har hørt om dette begrepet mer enn en gang, men enda en definisjon vil ikke skade noen.
Først av alt, her er de mest populære definisjonene av en Data Lake:
"en fillagring av alle typer rådata som er tilgjengelig for analyse av alle i organisasjonen" - Martin Fowler.
"Hvis du tror at en datamart er en flaske vann - renset, pakket og pakket for praktisk forbruk, så er en datainnsjø et enormt reservoar av vann i sin naturlige form. Brukere, jeg kan samle vann til meg selv, dykke dypt, utforske» - James Dixon.
Nå vet vi med sikkerhet at en datainnsjø handler om analyser, den lar oss lagre store mengder data i sin opprinnelige form og vi har den nødvendige og praktiske tilgangen til dataene.
Jeg liker ofte å forenkle ting. Hvis jeg kan forklare et komplekst begrep på en enkel måte, betyr det at jeg har forstått hvordan det fungerer og hva det er til for. En gang rotet jeg litt rundt i iPhone i fotogalleriet, og det gikk opp for meg at dette er en ekte datasjø, lagde jeg til og med et lysbilde for konferanser:
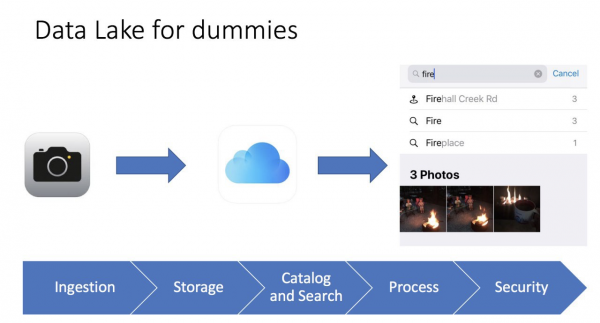
Det er veldig enkelt. Vi tar et bilde på telefonen vår, bildet lagres på telefonen, og kan lagres i iCloud (en skybasert fillagringstjeneste). Telefonen samler også inn bildets metadata: hva som er på bildet, geotaggen og tidspunktet. Som et resultat kan vi bruke et brukervennlig grensesnitt. iPhoneFor å finne bildet vårt, ser vi til og med målinger. Når jeg for eksempel søker etter bilder med ordet «bål», finner jeg tre bilder av et bål. For meg er det som et forretningsintelligensverktøy som fungerer veldig raskt og effektivt.
Og selvfølgelig må vi ikke glemme sikkerheten (autorisasjon og autentisering), ellers kan dataene våre lett havne i det offentlige domene. Det er mange nyheter om store selskaper og startups hvis data ble offentlig tilgjengelig på grunn av uaktsomhet fra utviklere og manglende overholdelse av enkle regler.
Selv et så enkelt bilde hjelper oss å forestille oss hva en datainnsjø er, dens forskjeller fra et tradisjonelt datavarehus og hovedelementene:
- Laster inn data (Inntak) er en nøkkelkomponent i datainnsjøen. Data kan komme inn i datavarehuset på to måter - batch (lasting med intervaller) og streaming (dataflyt).
- Fillagring (Lagring) er hovedkomponenten i Data Lake. Vi trengte at lagringen skulle være lett skalerbar, ekstremt pålitelig og lave kostnader. For eksempel, i AWS er det S3.
- Katalog og søk (Katalog og søk) - for at vi skal unngå datasumpen (dette er når vi dumper alle dataene i en haug, og da er det umulig å jobbe med det), må vi lage et metadatalag for å klassifisere dataene slik at brukerne enkelt kan finne dataene de trenger for analyse. I tillegg kan du bruke flere søkeløsninger som ElasticSearch. Søk hjelper brukeren med å finne de nødvendige dataene gjennom et brukervennlig grensesnitt.
- Processing (Prosess) - dette trinnet er ansvarlig for å behandle og transformere data. Vi kan transformere data, endre strukturen, rense den og mye mer.
- Безопасность (Sikkerhet) – Det er viktig å bruke tid på sikkerhetsdesign av løsningen. For eksempel datakryptering under lagring, behandling og lasting. Det er viktig å bruke autentiserings- og autorisasjonsmetoder. Til slutt trengs et revisjonsverktøy.
Fra et praktisk synspunkt kan vi karakterisere en datainnsjø med tre attributter:
- Samle og lagre hva som helst — datainnsjøen inneholder alle dataene, både rå ubehandlet data for en hvilken som helst tidsperiode og behandlet/renset data.
- Dypt Søk — en datainnsjø lar brukere utforske og analysere data.
- Fleksibel tilgang — Datasjøen gir fleksibel tilgang for ulike data og ulike scenarier.
Nå kan vi snakke om forskjellen mellom et datavarehus og en datainnsjø. Vanligvis spør folk:
- Hva med datavarehuset?
- Erstatter vi datavarehuset med en datainnsjø eller utvider vi det?
- Er det fortsatt mulig å klare seg uten en datainnsjø?
Kort sagt, det er ikke noe klart svar. Alt avhenger av den spesifikke situasjonen, ferdighetene til laget og budsjettet. For eksempel å migrere et datavarehus til Oracle til AWS og opprette en datainnsjø av et Amazon-datterselskap - Woot - .
På den annen side sier leverandøren Snowflake at du ikke lenger trenger å tenke på en datainnsjø, siden deres dataplattform (frem til 2020 var det et datavarehus) lar deg kombinere både en datainnsjø og et datavarehus. Jeg har ikke jobbet mye med Snowflake, og det er virkelig et unikt produkt som kan gjøre dette. Prisen på problemet er en annen sak.
Avslutningsvis er min personlige mening at vi fortsatt trenger et datavarehus som hovedkilde for data for rapporteringen vår, og det som ikke passer lagrer vi i en datainnsjø. Hele rollen til analyse er å gi enkel tilgang for virksomheten til å ta beslutninger. Uansett hva man kan si, jobber forretningsbrukere mer effektivt med et datavarehus enn en datainnsjø, for eksempel i Amazon – det er Redshift (analytisk datavarehus) og det er Redshift Spectrum/Athena (SQL-grensesnitt for en datainnsjø i S3 basert på Hive/Presto). Det samme gjelder andre moderne analytiske datavarehus.
La oss se på en typisk datavarehusarkitektur:
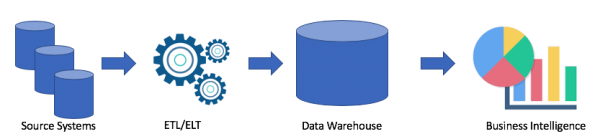
Dette er en klassisk løsning. Vi har kildesystemer, ved hjelp av ETL/ELT kopierer vi data inn i et analytisk datavarehus og kobler det til en Business Intelligence-løsning (min favoritt er Tableau, hva med din?).
Denne løsningen har følgende ulemper:
- ETL/ELT-operasjoner krever tid og ressurser.
- Som regel er minne for lagring av data i et analytisk datavarehus ikke billig (for eksempel Redshift, BigQuery, Teradata), siden vi må kjøpe en hel klynge.
- Bedriftsbrukere har tilgang til rensede og ofte aggregerte data og har ikke tilgang til rådata.
Alt avhenger selvfølgelig av din sak. Hvis du ikke har problemer med datavarehuset ditt, trenger du ikke en datainnsjø i det hele tatt. Men når det oppstår problemer med mangel på plass, strøm eller pris spiller en nøkkelrolle, kan du vurdere alternativet med en datainnsjø. Dette er grunnen til at datasjøen er veldig populær. Her er et eksempel på en datainnsjø-arkitektur:
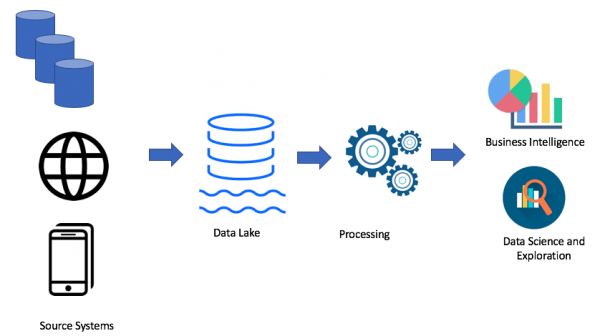
Ved å bruke datainnsjø-tilnærmingen laster vi rådata inn i datasjøen vår (batch eller streaming), deretter behandler vi dataene etter behov. Datasjøen lar forretningsbrukere lage sine egne datatransformasjoner (ETL/ELT) eller analysere data i Business Intelligence-løsninger (hvis nødvendig driver er tilgjengelig).
Målet med enhver analyseløsning er å betjene forretningsbrukere. Derfor må vi alltid jobbe etter forretningskrav. (Hos Amazon er dette et av prinsippene - å jobbe bakover).
Ved å jobbe med både et datavarehus og en datainnsjø kan vi sammenligne begge løsningene:
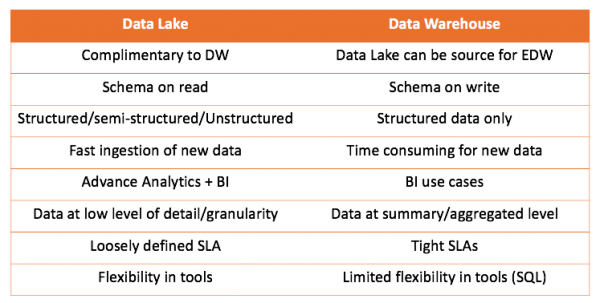
Hovedkonklusjonen som kan trekkes er at datavarehuset ikke konkurrerer med datasjøen, men snarere utfyller den. Men det er opp til deg å avgjøre hva som er riktig for ditt tilfelle. Det er alltid interessant å prøve det selv og trekke de riktige konklusjonene.
Jeg vil også fortelle deg et av tilfellene da jeg begynte å bruke datainnsjø-tilnærmingen. Alt er ganske trivielt, jeg prøvde å bruke et ELT-verktøy (vi hadde Matillion ETL) og Amazon Redshift, løsningen min fungerte, men passet ikke kravene.
Jeg trengte å ta nettlogger, transformere dem og samle dem for å gi data for 2 tilfeller:
- Markedsføringsteamet ønsket å analysere botaktivitet for SEO
- IT ønsket å se på ytelsesberegninger for nettstedet
Veldig enkle, veldig enkle logger. Her er et eksempel:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"En fil veide 1-4 megabyte.
Men det var en vanskelighet. Vi hadde 7 domener rundt om i verden, og 7000 tusen filer ble opprettet på en dag. Dette er ikke mye mer volum, bare 50 gigabyte. Men størrelsen på vår rødforskyvningsklynge var også liten (4 noder). Å laste inn én fil på tradisjonell måte tok omtrent ett minutt. Det vil si at problemet ikke ble løst direkte. Og dette var tilfellet da jeg bestemte meg for å bruke datainnsjø-tilnærmingen. Løsningen så omtrent slik ut:
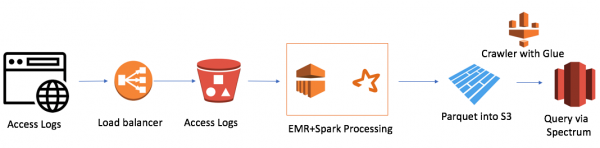
Det er ganske enkelt (jeg vil merke at fordelen med å jobbe i skyen er enkelhet). Jeg brukte:
- AWS Elastic Map Reduce (Hadoop) for Compute Power
- AWS S3 som fillagring med mulighet til å kryptere data og begrense tilgang
- Spark som InMemory datakraft og PySpark for logikk og datatransformasjon
- Parkett som følge av Spark
- AWS Glue Crawler som metadatasamler om nye data og partisjoner
- Redshift Spectrum som et SQL-grensesnitt til datasjøen for eksisterende Redshift-brukere
Den minste EMR+Spark-klyngen behandlet hele stabelen med filer på 30 minutter. Det er andre saker for AWS, spesielt mange relatert til Alexa, hvor det er mye data.
For nylig lærte jeg at en av ulempene med en datainnsjø er GDPR. Problemet er at når klienten ber om å slette den og dataene er i en av filene, kan vi ikke bruke Data Manipulation Language og DELETE-operasjon som i en database.
Jeg håper denne artikkelen har klargjort forskjellen mellom et datavarehus og en datainnsjø. Hvis du var interessert, kan jeg oversette flere av artiklene mine eller artikler fra fagfolk jeg leser. Og også fortelle om løsningene jeg jobber med og deres arkitektur.
Kilde: www.habr.com
