


Entry
Hei!
I denne artikkelen vil jeg dele min erfaring med å bygge en mikrotjenestearkitektur for et prosjekt ved bruk av nevrale nettverk.
La oss snakke om arkitekturkravene, se på ulike strukturelle diagrammer, analysere hver av komponentene i den ferdige arkitekturen, og også evaluere de tekniske beregningene til løsningen.
Liker å lese!
Noen få ord om problemet og dets løsning
Hovedideen er å vurdere en persons attraktivitet på en ti-punkts skala basert på et bilde.
I denne artikkelen vil vi gå bort fra å beskrive både de nevrale nettverkene som brukes og prosessen med dataforberedelse og trening. I en av de følgende publikasjonene vil vi imidlertid definitivt gå tilbake til å analysere vurderingspipelinen på et dyptgående nivå.
Nå skal vi gå gjennom evalueringspipelinen på toppnivå, og vil fokusere på interaksjonen mellom mikrotjenester i sammenheng med den overordnede prosjektarkitekturen.
Under arbeidet med pipelinen for vurdering av attraktivitet ble oppgaven dekomponert i følgende komponenter:
- Velge ansikter i bilder
- Vurdering av hver person
- Gjengi resultatet
Den første løses av kreftene til forhåndstrente . For det andre ble et konvolusjonelt nevralt nettverk trent på PyTorch ved å bruke – fra balansen "kvalitet / slutningshastighet på CPU"

Funksjonsdiagram av evalueringsrørledningen
Analyse av krav til prosjektarkitektur
I livssyklusen prosjektstadier av arbeidet med arkitektur og automatisering av modelldistribusjon er ofte blant de mest tid- og ressurskrevende.
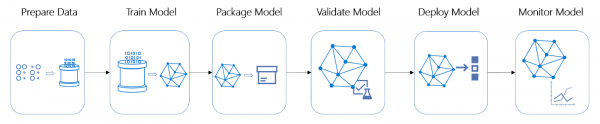
Livssyklusen til et ML-prosjekt
Dette prosjektet er intet unntak - beslutningen ble tatt om å pakke inn vurderingsrørledningen til en nettbasert tjeneste, som krevde å fordype oss i arkitekturen. Følgende grunnleggende krav ble identifisert:
- Samlet logglagring – alle tjenester skal skrive logger på ett sted, de skal være praktiske å analysere
- Mulighet for horisontal skalering av vurderingstjenesten - som mest sannsynlig Flaskehals
- Samme mengde prosessorressurser bør tildeles for å evaluere hvert bilde for å unngå uteliggere i fordelingen av tid for slutninger
- Rask (re)distribusjon av både spesifikke tjenester og stabelen som helhet
- Evnen til, om nødvendig, å bruke vanlige objekter i ulike tjenester
arkitektur
Etter å ha analysert kravene, ble det åpenbart at mikrotjenestearkitekturen passer nesten perfekt.
For å bli kvitt unødvendig hodepine ble Telegram API valgt som frontend.
La oss først se på strukturdiagrammet til den ferdige arkitekturen, deretter gå videre til en beskrivelse av hver av komponentene, og også formalisere prosessen med vellykket bildebehandling.
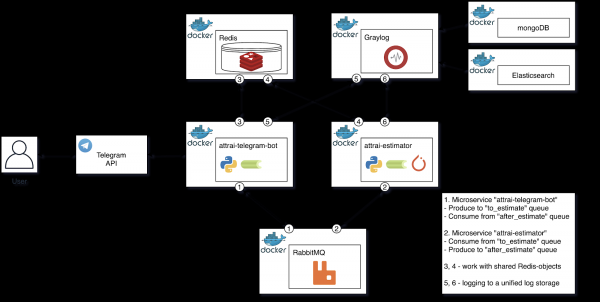
Strukturdiagram av den ferdige arkitekturen
La oss snakke mer detaljert om hver av komponentene i diagrammet, og betegne dem som enkeltansvar i prosessen med bildeevaluering.
Microservice "attrai-telegram-bot"
Denne mikrotjenesten innkapsler all interaksjon med Telegram API. Det er 2 hovedscenarier: arbeid med et tilpasset bilde og arbeid med resultatet av en vurderingspipeline. La oss se på begge scenariene i generelle termer.
Når du mottar en egendefinert melding med et bilde:
- Filtrering utføres, bestående av følgende kontroller:
- Tilgjengelighet av optimal bildestørrelse
- Antall brukerbilder som allerede er i kø
- Når du passerer den første filtreringen, lagres bildet i docker-volumet
- En oppgave produseres i "to_estimate"-køen, som blant annet inkluderer banen til bildet som ligger i volumet vårt
- Hvis trinnene ovenfor er fullført, vil brukeren motta en melding med omtrentlig bildebehandlingstid, som beregnes basert på antall oppgaver i køen. Dersom det oppstår en feil, vil brukeren bli eksplisitt varslet ved å sende en melding med informasjon om hva som kan ha gått galt.
I tillegg lytter denne mikrotjenesten, som en selleriarbeider, til "after_estimate"-køen, som er ment for oppgaver som har gått gjennom evalueringsrørledningen.
Når du mottar en ny oppgave fra «after_estimate»:
- Hvis bildet behandles vellykket, sender vi resultatet til brukeren; hvis ikke, varsler vi om en feil.
- Fjerner bildet som er resultatet av evalueringsrørledningen
Evaluering mikrotjeneste "attrai-estimator"
Denne mikrotjenesten er en selleriarbeider og innkapsler alt relatert til bildeevalueringspipeline. Det er bare én fungerende algoritme her - la oss analysere den.
Når du mottar en ny oppgave fra "to_estimate":
- La oss kjøre bildet gjennom evalueringsrørledningen:
- Laster bildet inn i minnet
- Vi bringer bildet til ønsket størrelse
- Finne alle ansikter (MTCNN)
- Vi evaluerer alle ansikter (vi pakker inn ansiktene som ble funnet i det siste trinnet i en batch og konkluderer ResNet34)
- Gjengi det endelige bildet
- La oss tegne avgrensningsboksene
- Tegning av karakterer
- Sletter et egendefinert (originalt) bilde
- Lagrer utdata fra evalueringspipeline
- Vi legger oppgaven i "after_estimate"-køen, som lyttes til av "attrai-telegram-bot"-mikrotjenesten diskutert ovenfor.
Graylog (+ mongoDB + Elasticsearch)
er en løsning for sentralisert logghåndtering. I dette prosjektet ble det brukt til det tiltenkte formålet.
Valget falt på ham, og ikke på den vanlige stack, på grunn av bekvemmeligheten av å jobbe med den fra Python. Alt du trenger å gjøre for å logge på Graylog er å legge til GELFTCPHandler fra pakken til resten av rotlogger-behandlerne til vår python-mikrotjeneste.
Som en som tidligere bare hadde jobbet med ELK-stakken, hadde jeg en generelt positiv opplevelse mens jeg jobbet med Graylog. Det eneste som er deprimerende er overlegenheten i Kibana-funksjonene over Graylog-nettgrensesnittet.
Kanin MQ
er en meldingsmegler basert på AMQP-protokollen.
I dette prosjektet ble det brukt som megler for selleri og jobbet i holdbar modus.
Redis
er et NoSQL DBMS som fungerer med nøkkelverdi-datastrukturer
Noen ganger er det behov for å bruke vanlige objekter som implementerer visse datastrukturer i forskjellige Python-mikrotjenester.
For eksempel lagrer Redis en hashmap av formen "telegram_user_id => antall aktive oppgaver i køen", som lar deg begrense antall forespørsler fra én bruker til en viss verdi og dermed forhindre DoS-angrep.
La oss formalisere prosessen med vellykket bildebehandling
- Brukeren sender et bilde til Telegram-boten
- "attrai-telegram-bot" mottar en melding fra Telegram API og analyserer den
- Oppgaven med bildet legges til den asynkrone køen "to_estimate"
- Brukeren mottar en melding med planlagt vurderingstid
- "attrai-estimator" tar en oppgave fra "to_estimate"-køen, kjører estimatene gjennom pipelinen og produserer oppgaven inn i "etter_estimate"-køen
- "attrai-telegram-bot" som lytter til "after_estimate"-køen, sender resultatet til brukeren
DevOps
Til slutt, etter å ha gjennomgått arkitekturen, kan du gå videre til den like interessante delen - DevOps
Docker sverm

— et klyngesystem, hvis funksjonalitet er implementert inne i Docker Engine og er tilgjengelig ut av esken.
Ved å bruke en "sverm" kan alle noder i klyngen vår deles inn i 2 typer - arbeider og leder. På maskiner av den første typen er grupper av containere (stabler) utplassert, maskiner av den andre typen er ansvarlige for skalering, balansering og . Ledere er også arbeidere som standard.
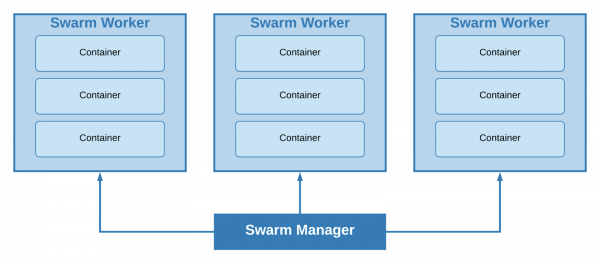
Klynge med en lederleder og tre arbeidere
Minste mulige klyngestørrelse er 1 node; én enkelt maskin vil samtidig fungere som lederleder og arbeider. På bakgrunn av prosjektets størrelse og minstekrav til feiltoleranse ble det besluttet å bruke denne tilnærmingen.
Ser jeg fremover vil jeg si at siden den første produksjonsleveransen, som var i midten av juni, har det ikke vært noen problemer knyttet til denne klyngeorganisasjonen (men dette betyr ikke at en slik organisasjon på noen måte er akseptabel i noen middels stor prosjekter som er underlagt feiltoleransekrav).
Docker Stack
I svermmodus er han ansvarlig for å distribuere stabler (sett med docker-tjenester)
Den støtter docker-compose-konfigurasjoner, slik at du i tillegg kan bruke distribusjonsparametere.
For eksempel, ved å bruke disse parameterne, var ressursene for hver av evalueringsmikrotjenesteforekomstene begrenset (vi tildeler N kjerner for N forekomster, i selve mikrotjenesten begrenser vi antallet kjerner brukt av PyTorch til én)
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…Det er viktig å merke seg at Redis, RabbitMQ og Graylog er stateful tjenester og de kan ikke skaleres så enkelt som "attrai-estimator"
Foreskygger spørsmålet - hvorfor ikke Kubernetes?
Det ser ut til at det å bruke Kubernetes i små og mellomstore prosjekter er en overhead; all nødvendig funksjonalitet kan fås fra Docker Swarm, som er ganske brukervennlig for en containerorkestrator og også har lav inngangsbarriere.
infrastruktur
Alt dette ble distribuert på VDS med følgende egenskaper:
- CPU: 4-kjerners Intel® Xeon® Gold 5120 CPU @ 2.20 GHz
- RAM: 8 GB
- SSD: 160 GB
Etter lokal belastningstesting så det ut til at med en seriøs tilstrømning av brukere ville denne maskinen være nok.
Men umiddelbart etter utrullingen la jeg ut en lenke til et av de mest populære bildetavlene i CIS (ja, det samme), hvoretter folk ble interessert og i løpet av noen timer behandlet tjenesten titusenvis av bilder. Samtidig ble ikke CPU- og RAM-ressursene halvparten brukt på høye øyeblikk.
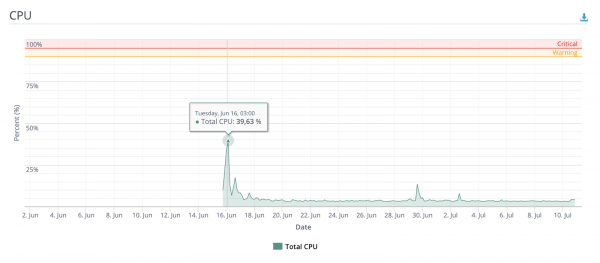
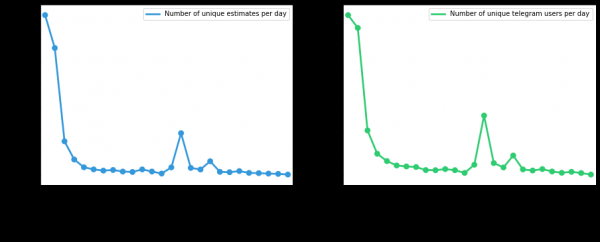
Litt mer grafikk
Antall unike brukere og evalueringsforespørsler siden distribusjon, avhengig av dagen
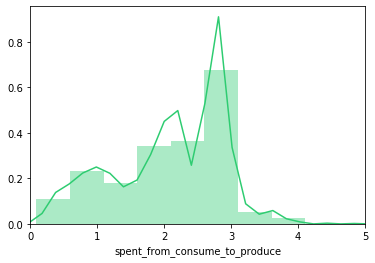
Evaluering pipeline inferens tidsfordeling
Funn
For å oppsummere kan jeg si at arkitekturen og tilnærmingen til orkestrering av containere rettferdiggjorde seg fullt ut - selv i toppøyeblikk var det ingen fall eller svikt i behandlingstiden.
Jeg tror at små og mellomstore prosjekter som bruker sanntidsslutning av nevrale nettverk på CPU'en i prosessen kan med hell ta i bruk praksisene beskrevet i denne artikkelen.
Jeg vil legge til at artikkelen i utgangspunktet var lengre, men for ikke å legge ut en longread, bestemte jeg meg for å utelate noen punkter i denne artikkelen - vi kommer tilbake til dem i fremtidige publikasjoner.
Du kan stikke boten på Telegram - @AttraiBot, den vil fungere i det minste til slutten av høsten 2020. La meg minne deg på at ingen brukerdata lagres - verken originalbildene eller resultatene av evalueringspipelinen - alt blir revet etter behandling.
Kilde: www.habr.com
