

Innledning
 «Du må løpe så fort du kan bare for å holde deg på plass,»
«Du må løpe så fort du kan bare for å holde deg på plass,»
og for å komme et sted, må du løpe minst dobbelt så fort!
(c) Alice i Eventyrland
For en tid tilbake ble jeg spurt om å holde et foredrag analytikere Selskapet vårt fokuserer på datamodelldesign, ettersom vi bruker lang tid på å jobbe med prosjekter (noen ganger i flere år) og mister oversikten over hva som skjer i IT-verdenen. I selskapet vårt bruker tilfeldigvis mange prosjekter ikke NoSQL-databaser (i hvert fall ikke ennå), så i forelesningen min fokuserte jeg spesifikt på dem, med HBase som eksempel, og prøvde å skreddersy presentasjonen til de som aldri har jobbet med dem. Jeg illustrerte spesifikt noen av detaljene ved datamodelldesign ved hjelp av et eksempel jeg leste for flere år siden. Da jeg analyserte eksempler, sammenlignet jeg flere løsninger på det samme problemet for å bedre formidle hovedideene til publikum.
Nylig, «av kjedsomhet», lurte jeg på (de lange maiferiene under karantenen var spesielt gunstige for dette spørsmålet): hvor godt ville de teoretiske konseptene oversettes til praksis? Slik ble ideen til denne artikkelen født. En utvikler som har jobbet med NoSQL en stund, vil kanskje ikke få noe nytt ut av det (og vil derfor hoppe over halve artikkelen). Men for analytikereFor de som ikke har jobbet mye med NoSQL ennå, tror jeg det vil være nyttig for å få en grunnleggende forståelse av detaljene ved design av datamodeller for HBase.
Eksempelanalyse
Etter min mening må man tenke nøye gjennom og veie fordeler og ulemper før man bruker NoSQL-databaser. Ofte kan en oppgave sannsynligvis løses ved hjelp av tradisjonelle relasjonelle DBMS-er. Derfor er det best å unngå å bruke NoSQL uten en overbevisende grunn. Hvis du bestemmer deg for å bruke en NoSQL-database, må du huske på at designtilnærmingene er noe forskjellige. Noen av dem kan være spesielt ukjente for de som tidligere bare har jobbet med relasjonelle DBMS-er (etter min erfaring). For eksempel, i den relasjonelle verden starter vi vanligvis med å modellere emneområdet og deretter, om nødvendig, denormaliserer modellen. I NoSQL derimot, vi må umiddelbart ta hensyn til forventede scenarier for arbeid med data og i utgangspunktet denormalisere dataene. Det finnes også en rekke andre forskjeller, som vil bli diskutert nedenfor.
La oss se på følgende «syntetiske» problem, som vi skal fortsette å jobbe med:
Vi må designe en lagringsstruktur for en venneliste for brukere av et bestemt abstrakt sosialt nettverk. For enkelhets skyld antar vi at alle forbindelser er dirigerte (som på Instagram, ikke LinkedIn). Strukturen bør tillate at følgende implementeres effektivt:
- Svar på spørsmålet om bruker A leser bruker B (lesemønster)
- Tillat legge til/fjerning av tilkoblinger når bruker A følger/slutter å følge bruker B (mal for dataendring)
Det finnes selvsagt mange mulige løsninger på dette problemet. I en tradisjonell relasjonsdatabase ville vi sannsynligvis bare opprettet en relasjonstabell (kanskje en typebasert en, hvis vi for eksempel trenger å lagre brukergrupper – familie, arbeid osv. – som inkluderer en gitt "venn"), og lagt til indekser/partisjonering for å optimalisere tilgangshastigheten. Den resulterende tabellen ville sannsynligvis se omtrent slik ut:
user_id
venn_id
Vasja
Petya
Vasja
Оля
Fra nå av, for klarhetens skyld og bedre forståelse, vil jeg bruke navn i stedet for ID-er
Når det gjelder HBase, vet vi at:
- effektivt søk uten full tabellskanning er mulig utelukkende etter nøkkel
- Derfor er det en dårlig idé å skrive kjente SQL-spørringer til slike databaser. Teknisk sett kan du selvfølgelig sende en SQL-spørring med sammenføyninger og annen logikk fra Impala til HBase, men hvor effektivt vil det være?
Derfor er vi tvunget til å bruke bruker-ID-en som en nøkkel. Den første tanken rundt temaet «hvor og hvordan lagre venn-ID-er?» kan være ideen om å lagre dem i kolonner. Dette mest åpenbare og «naive» alternativet ville se omtrent slik ut (la oss kalle det Alternativ 1 (standard), for fremtidig referanse):
Radnøkkel
høyttalere
Vasja
1: Petja
2: Olja
3: Dasha
Petya
1: Masja
2: Vasja
Her tilsvarer hver rad én nettverksbruker. Kolonnene heter 1, 2, ... – basert på antall venner – og lagrer venn-ID-ene. Det er viktig å merke seg at hver rad vil ha et ulikt antall kolonner. I eksemplet ovenfor har én rad tre kolonner (1, 2 og 3), mens den andre bare har to (1 og 2). Her har vi utnyttet to HBase-egenskaper som relasjonsdatabaser ikke har:
- muligheten til å endre sammensetningen av kolonner dynamisk (legg til en venn -> legg til en kolonne, fjern en venn -> fjern en kolonne)
- forskjellige rader kan ha ulik kolonnesammensetning
La oss sjekke strukturen vår for å se om den oppfyller oppgavekravene:
- Leser dataFor å forstå om Vasya abonnerer på Olya, må vi trekke fra hele linjen av RowKey = "Vasya" og iterer gjennom kolonneverdiene til vi "møter" Olya. Eller iterer gjennom alle kolonneverdiene, "møter ikke" Olya, og returner False;
- Redigere detaljer: legge til en vennFor et lignende problem må vi også subtrahere hele linjen av RowKey = "Vasya" for å telle det totale antallet venner hans. Vi trenger dette totale antallet venner for å bestemme kolonnenummeret der den nye vennens ID skal lagres.
- Redigere data: slette en venn:
- Det er nødvendig å trekke fra hele linjen med nøkkelen RowKey = “Vasya” og gå gjennom kolonnene for å finne den der vennen som slettes er registrert;
- Deretter, etter å ha slettet en venn, må vi "flytte" alle dataene til én kolonne for å ikke få "hull" i nummereringen deres.
La oss nå evaluere hvor produktive disse algoritmene, som vi må implementere på siden av den "betingede applikasjonen", vil være å bruke. La oss betegne størrelsen på vårt hypotetiske sosiale nettverk som n. Da er det maksimale antallet venner en enkelt bruker kan ha (n-1). Vi kan ignorere dette (-1) for våre formål her, da det er irrelevant i konteksten av bruk av O-symboler.
- Leser dataDet er nødvendig å subtrahere hele raden og, innenfor grensen, iterere over alle kolonnene. Dette betyr at det øvre kostnadsestimatet vil være omtrent O(n)
- Redigere detaljer: legge til en vennFor å bestemme antall venner må du iterere gjennom alle kolonnene i raden, og deretter sette inn en ny kolonne => O(n)
- Redigere data: slette en venn:
- I likhet med addisjon er det nødvendig å iterere over alle kolonnene i limit => O(n)
- Etter at vi har slettet kolonnene, må vi "forskyve" dem. En enkel tilnærming ville kreve opptil (n-1) flere operasjoner. Her og gjennom hele den praktiske delen vil vi imidlertid bruke en annen tilnærming som implementerer "pseudoforskyvningen" i et fast antall operasjoner – som betyr at det tar konstant tid uavhengig av n. Denne konstante tiden (O(2) for å være presis) er ubetydelig sammenlignet med O(n). Tilnærmingen er illustrert i figuren nedenfor: Vi kopierer ganske enkelt dataene fra den "siste" kolonnen til den der dataene må slettes, og sletter deretter den siste kolonnen:

Totalt sett oppnådde vi i alle scenarier en asymptotisk beregningskompleksitet på O(n).
Du har sikkert allerede lagt merke til at vi nesten alltid må lese hele raden fra databasen, og i to av tre tilfeller bare for å gå gjennom alle kolonnene og beregne det totale antallet venner. Derfor kan vi, som et forsøk på optimalisering, legge til en "antall"-kolonne for å lagre det totale antallet venner for hver nettverksbruker. I dette tilfellet trenger vi ikke å lese hele raden for å beregne det totale antallet venner, men bare lese "antall"-kolonnen. Det viktigste er å huske å oppdatere "antall" når du manipulerer dataene. På denne måten får vi en forbedret Alternativ 2 (antall):
Radnøkkel
høyttalere
Vasja
1: Petja
2: Olja
3: Dasha
antall: 3
Petya
1: Masja
2: Vasja
antall: 2
Sammenlignet med det første alternativet:
- Leser data: for å få svar på spørsmålet "Leser Vasya Olya?" ingenting har endret seg => O(n)
- Redigere detaljer: legge til en vennVi har forenklet innsetting av en ny venn fordi vi ikke lenger trenger å lese hele raden og iterere gjennom kolonnene. Vi kan nå bare hente kolonneverdien «antall» og dermed umiddelbart bestemme kolonnenummeret for innsetting av en ny venn. Dette reduserer beregningskompleksiteten til O(1).
- Redigere data: slette en vennNår vi sletter en venn, kan vi også bruke denne kolonnen til å redusere antall I/O-operasjoner når vi flytter data én celle til venstre. Vi må imidlertid fortsatt iterere gjennom kolonnene for å finne den vi skal slette, så => O(n)
- På den annen side, når vi nå oppdaterer data, må vi oppdatere «antall»-kolonnen hver gang, men dette tar konstant tid, noe som kan neglisjeres innenfor rammen av O-symboler.
Alt i alt virker alternativ 2 litt mer optimalt, men det er mer som «evolusjon i stedet for revolusjon». For å oppnå en «revolusjon» trenger vi Alternativ 3 (kolonne).
La oss snu alt på hodet: la oss utnevne kolonnenavn bruker-ID! Det som står i selve kolonnen er ikke avgjørende for oss; la oss bare bruke tallet 1 (generelt sett kan nyttige ting lagres der, for eksempel som en gruppe som "familie/venner/osv."). Denne tilnærmingen kan overraske den uinnvidde "lekmannen" som ikke har tidligere erfaring med NoSQL-databaser, men den lar oss utnytte potensialet til HBase mye mer effektivt til denne oppgaven:
Radnøkkel
høyttalere
Vasja
Petja: 1
Olja: 1
Dasha: 1
Petya
Masja: 1
Vasja: 1
Dette gir flere fordeler. For å forstå dem, la oss analysere den nye strukturen og estimere beregningskompleksiteten:
- Leser dataFor å svare på spørsmålet om Vasya abonnerer på Olya, er det nok å lese én kolonne «Olya»: hvis den er det, er svaret sant, hvis ikke – usant => O(1)
- Redigere detaljer: legge til en vennLegge til en venn: bare legg til en ny kolonne "Venne-ID" => O(1)
- Redigere data: slette en venn: bare fjern kolonnen "Venne-ID" => O(1)
Som vi kan se, er en betydelig fordel med denne lagringsmodellen at vi i alle nødvendige scenarier opererer med bare én kolonne, og unngår å lese hele raden fra databasen, og enda mindre å iterere gjennom alle kolonnene i den raden. Vi kunne stoppet der, men…
Vi kan bli litt mer kreative og gå litt lenger med å optimalisere ytelsen og redusere I/O-operasjoner ved tilgang til databasen. Hva om vi lagrer hele relasjonsinformasjonen direkte i selve radnøkkelen? Det vil si, lage nøkkelen sammensatt, som brukerID.vennID? I så fall ville vi ikke engang trenge å lese radkolonnene i det hele tatt (Alternativ 4 (rad)):
Radnøkkel
høyttalere
Vasja. Petja
Petja: 1
Vasya.Olya
Olja: 1
Vasya.Dasha
Dasha: 1
Petja. Masha
Masja: 1
Petja. Vasja
Vasja: 1
Det er åpenbart at evalueringen av alle datamanipulasjonsscenarier i en slik struktur vil være O(1), akkurat som i det forrige alternativet. Forskjellen med alternativ 3 vil utelukkende ligge i effektiviteten til database-I/O-operasjoner.
Og til slutt, den siste godbiten. Det er lett å se at i alternativ 4 vil radnøkkelen vår ha en variabel lengde, noe som potensielt kan påvirke ytelsen (husk at HBase lagrer data som et sett med byte, og tabellrader er sortert etter nøkkel). I tillegg har vi en separator, som kanskje må behandles i noen scenarier. For å eliminere denne påvirkningen kan vi bruke hasher av bruker-ID og venn-ID. Siden begge hashene vil ha en konstant lengde, kan vi ganske enkelt sammenkoble dem uten separatoren. Da vil dataene i tabellen se slik ut:Alternativ 5 (hash)):
Radnøkkel
høyttalere
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Petja: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
Olja: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
Dasha: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Masja: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Vasja: 1
Det er åpenbart at den algoritmiske kompleksiteten ved å jobbe med en slik struktur i henhold til scenariene vi vurderer vil være den samme som for alternativ 4 – det vil si O(1).
Så, la oss oppsummere alle våre beregningskompleksitetsestimater i én tabell:
Legge til en venn
Sjekker en venn
Fjerne en venn
Alternativ 1 (standard)
O (n)
O (n)
O (n)
Alternativ 2 (antall)
O (1)
O (n)
O (n)
Alternativ 3 (kolonne)
O (1)
O (1)
O (1)
Alternativ 4 (rad)
O (1)
O (1)
O (1)
Alternativ 5 (hash)
O (1)
O (1)
O (1)
Som du kan se, virker alternativ 3–5 å foretrekke, og de sikrer teoretisk sett utførelse av alle nødvendige datamanipuleringsscenarier i konstant tid. Problemstillingen vår krever ikke eksplisitt at man henter en liste over alle en brukers venner, men i virkelige prosjekter, som gode analytikere, ville vi være kloke i å forutse et slikt problem og ta forholdsregler. Derfor favoriserer jeg alternativ 3. Det er imidlertid ganske mulig at denne forespørselen allerede har blitt adressert på andre måter i et virkelig prosjekt, så uten en generell forståelse av hele problemet er det best å ikke trekke noen endelige konklusjoner.
Forberedelse av eksperimentet
Jeg vil gjerne teste den ovennevnte teoretiske resonnementet i praksis – det var målet med ideen som oppsto over en langhelg. For å gjøre dette må vi evaluere ytelsen til vår «hypotetiske applikasjon» i alle de beskrevne databasebruksscenariene, samt hvordan denne tiden øker med størrelsen på det sosiale nettverket (n). Målparameteren vi er interessert i, og som vi skal måle under eksperimentet, er tiden det tar for den «hypotetiske applikasjonen» å utføre én «forretningsoperasjon». Med «forretningsoperasjon» mener vi én av følgende:
- Legger til én ny venn
- Sjekker om bruker A er en venn av bruker B
- Fjerner én venn
Med tanke på kravene spesifisert i den innledende uttalelsen, er verifiseringsscenarioet som følger:
- DataregistreringGenerer tilfeldig et initialt nettverk av størrelse n. For å bedre tilnærme den «virkelige verden» er antallet venner hver bruker har også tilfeldig. Mål tiden det tar for «dummy-applikasjonen» vår å skrive alle genererte data til HBase. Del deretter denne tiden med det totale antallet venner som er lagt til – dette vil gi oss gjennomsnittstiden for én «forretningsoperasjon».
- Leser dataFor hver bruker lager du en liste over «personligheter» som du må avgjøre om brukeren følger dem eller ikke. Listelengden er omtrent lik antallet venner til brukeren, der svaret er «Ja» for halvparten av vennene som er merket av og «Nei» for den andre halvparten. Sjekkene utføres på en slik måte at svarene «Ja» og «Nei» veksler (det betyr at vi i alle andre tilfeller må gå gjennom alle kolonnene i raden for alternativ 1 og 2). Den totale sjekketiden deles deretter på antall venner som er merket av for å få gjennomsnittstiden per sjekk.
- Sletter dataSlett alle brukerens venner. Sletterekkefølgen er tilfeldig (dvs. vi blander den opprinnelige listen som ble brukt til å registrere dataene). Den totale verifiseringstiden deles deretter på antall venner som slettes for å få gjennomsnittstiden per verifisering.
Scenariene må kjøres for hver av de fem datamodellvariantene og for ulike størrelser på sosiale nettverk for å se hvordan tiden endrer seg etter hvert som nettverket vokser. Innenfor en enkelt n-modell må nettverkstilkoblingene og listen over brukere som skal testes selvfølgelig være den samme for alle fem variantene.
For bedre forståelse er nedenfor et eksempel på genererte data for n = 5. "Generatoren" jeg har skrevet produserer tre ID-ordbøker:
- den første er til innsetting
- den andre er for å sjekke
- den tredje er for fjerning
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # всего 15 друзей
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # всего 18 проверяемых субъектов
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # всего 15 друзей
Som du kan se, er alle ID-er større enn 10 000 i ordboken for verifisering nettopp de som definitivt vil returnere Usann. Innsetting, verifisering og sletting av «venner» utføres i nøyaktig den rekkefølgen som er angitt i ordboken.
Eksperimentet ble utført på en bærbar PC som kjørte Windows 10, der HBase kjørte i én Docker-container, og Python med Jupyter Notebook kjørte i en annen. Docker ble tildelt 2 CPU-kjerner og 2 GB RAM. All logikk, inkludert simuleringen av "dummy-applikasjonen" og rammeverket for å generere testdata og måle tid, ble skrevet i Python. Biblioteket , for å beregne hasher (MD5) for alternativ 5 - hashlib
Med tanke på datakraften til en spesifikk bærbar PC ble det eksperimentelt valgt en oppstart for n = 10, 30, …. 170 – når den totale kjøretiden for hele testsyklusen (alle scenarier for alle alternativer for alle n) fortsatt var mer eller mindre rimelig og passet under ett teselskap (i gjennomsnitt 15 minutter).
Det er viktig å merke seg at vi i dette eksperimentet ikke primært evaluerer absolutte ytelsestall. Selv en relativ sammenligning av to forskjellige varianter er kanskje ikke helt nøyaktig. Vi er for tiden interessert i hvordan tidsendringen fungerer som en funksjon av n, siden det, gitt den ovennevnte testkonfigurasjonen, er svært vanskelig å oppnå tidsestimater som er "frie" fra påvirkning av tilfeldige og andre faktorer (og det var faktisk ikke målet).
Resultatet av eksperimentet
Den første testen så på hvordan tiden det tar å fylle en venneliste endrer seg. Resultatene vises i grafen nedenfor.
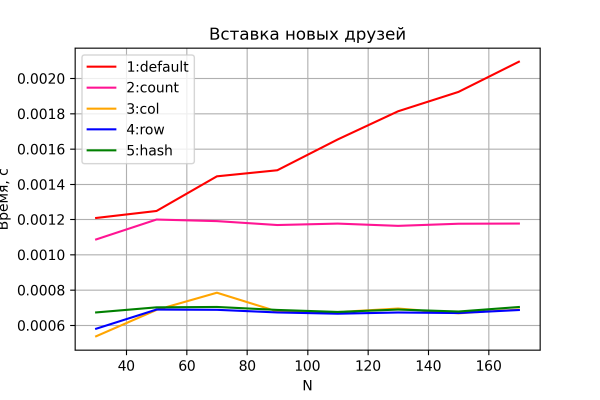
Alternativ 3–5 viser, som forventet, en tilnærmet konstant «driftstid», som er uavhengig av vekst i nettverksstørrelse, og en ubetydelig forskjell i ytelse.
Variant 2 viser også konstant, men litt dårligere ytelse, nesten nøyaktig 2 ganger så høy som variantene 3–5. Dette er oppmuntrende, ettersom det stemmer overens med teorien – i denne varianten er antallet I/O-operasjoner til/fra HBase nøyaktig 2 ganger større. Dette kan tjene som indirekte bevis på at testoppsettet vårt generelt leverer anstendig nøyaktighet.
Alternativ 1 viser seg også å være det tregeste, som forventet, og viser en lineær økning i tiden det tar å legge til én venn, avhengig av nettverksstørrelsen.
La oss nå se på resultatene av den andre testen.
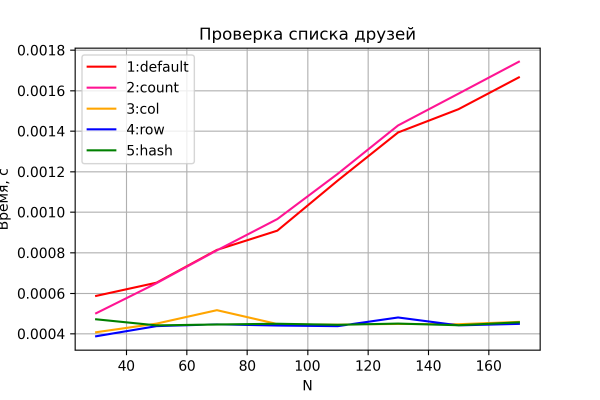
Variantene 3–5 oppfører seg igjen som forventet – konstant tid, uavhengig av nettverksstørrelse. Variant 1 og 2 viser lineær tidsvekst med nettverksstørrelse og lignende ytelse. Variant 2 er imidlertid litt tregere – tilsynelatende på grunn av behovet for å analysere og behandle den ekstra «antall»-kolonnen, som blir mer merkbar etter hvert som n øker. Jeg vil imidlertid forbeholde meg min dom, ettersom nøyaktigheten av denne sammenligningen er relativt lav. Videre varierte korrelasjonene (hvilken variant, 1 eller 2, som er raskest) fra kjøring til kjøring (samtidig som de opprettholdt et konsistent mønster og var jevnbyrdige).
Vel, den siste grafen er resultatet av fjerningstesten.
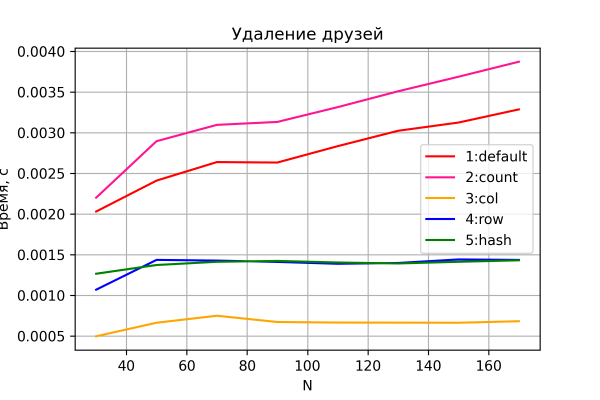
Igjen, ingen overraskelser her. Alternativ 3–5 utfører sletting i konstant tid.
Interessant nok viser alternativ 4 og 5, i motsetning til de foregående scenariene, merkbart litt dårligere ytelse enn alternativ 3. Tilsynelatende er sletting av rader dyrere enn sletting av kolonner, noe som generelt er logisk.
Alternativ 1 og 2 viser, som forventet, lineær tidsvekst. Alternativ 2 er imidlertid gjennomgående tregere enn alternativ 1 på grunn av den ekstra I/O-operasjonen som kreves for å opprettholde tellekolonnen.
Generelle konklusjoner fra eksperimentet:
- Alternativ 3–5 viser større effektivitet, ettersom de utnytter HBase. Ytelsen deres er imidlertid forskjellig fra hverandre med en konstant og avhenger ikke av nettverksstørrelsen.
- Det ble ikke observert noen forskjell mellom alternativ 4 og 5. Dette betyr imidlertid ikke at alternativ 5 ikke bør brukes. Det er sannsynlig at det eksperimentelle scenarioet som ble brukt, gitt testområdets ytelsesegenskaper, forhindret at dette ble oppdaget.
- Økningen i tiden som kreves for å utføre «forretningsdrift» med data bekreftet generelt de tidligere innhentede teoretiske beregningene for alle alternativene.
Epilog
Disse grove eksperimentene bør ikke tas som absolutt sannhet. Det er mange faktorer som ikke ble tatt i betraktning og som forvrengte resultatene (disse svingningene er spesielt synlige i grafene for små nettverksstørrelser). For eksempel hastigheten på thrift, som brukes av happybase, volumet og implementeringsmetoden til logikken jeg skrev i Python (jeg kan ikke påstå at koden ble skrevet optimalt eller utnyttet alle komponenter effektivt), muligens HBase-hurtigbufringsfunksjoner og bakgrunnsaktivitet. Windows 10 På den bærbare datamaskinen min, osv. Alt i alt kan det konkluderes med at alle teoretiske antagelser har blitt eksperimentelt bevist å være gyldige. Eller i det minste var det ikke mulig å motbevise dem med et slikt direkte angrep.
Avslutningsvis er her noen anbefalinger for alle som nettopp har begynt å designe datamodeller i HBase: legg til side din tidligere erfaring med relasjonsdatabaser og husk "budene":
- Når vi designer, går vi ut fra oppgave- og datamanipuleringsmønstrene, og ikke fra domenemodellen.
- Effektiv tilgang (uten full tabellskanning) – kun med nøkkel
- Denormalisering
- Ulike rader kan inneholde forskjellige kolonner.
- Dynamisk sammensetning av kolonner
Kilde: www.habr.com
