


Hovedmålet til Patroni er å gi høy tilgjengelighet for PostgreSQL. Men Patroni er bare en mal, ikke et ferdig verktøy (som generelt sies i dokumentasjonen). Ved første øyekast, etter å ha satt opp Patroni i testlaboratoriet, kan du se hvilket flott verktøy det er og hvor enkelt det håndterer våre forsøk på å bryte klyngen. Men i praksis, i et produksjonsmiljø, skjer ikke alt like vakkert og elegant som i et testlaboratorium.

Jeg skal fortelle deg litt om meg selv. Jeg startet som systemadministrator. Jobbet med webutvikling. Jeg har jobbet i Data Egret siden 2014. Selskapet driver med rådgivning innen Postgres. Og vi betjener akkurat Postgres, og vi jobber med Postgres hver dag, så vi har ulik kompetanse knyttet til driften.
Og på slutten av 2018 begynte vi sakte å bruke Patroni. Og noe erfaring har blitt samlet. Vi diagnostiserte det på en eller annen måte, stilte det, kom frem til våre beste praksiser. Og i denne rapporten vil jeg snakke om dem.
Foruten Postgres liker jeg LinuxJeg elsker å fikle med det og utforske, og jeg elsker å bygge kjerner. Jeg elsker virtualisering, containere, Docker og Kubernetes. Jeg er interessert i alt dette fordi mine gamle administrasjonsvaner holder på å ta igjen. Jeg elsker å fikle med overvåking. Jeg elsker også Postgres-relaterte ting knyttet til administrasjon, som replikering og sikkerhetskopiering. Og på fritiden skriver jeg i Go. Jeg er ikke programvareingeniør, jeg skriver bare i Go for meg selv. Og jeg liker det.

- Jeg tror mange av dere vet at Postgres ikke har HA (High Availability) ut av esken. For å få HA må du installere noe, konfigurere det, gjøre en innsats og få det.
- Det er flere verktøy og Patroni er et av dem som løser HA ganske kult og veldig bra. Men ved å sette det hele i et testlaboratorium og kjøre det, kan vi se at alt fungerer, vi kan reprodusere noen problemer, se hvordan Patroni betjener dem. Og vi skal se at det hele fungerer utmerket.
- Men i praksis sto vi overfor ulike problemer. Og jeg vil snakke om disse problemene.
- Jeg skal fortelle deg hvordan vi diagnostiserte det, hva vi justerte - om det hjalp oss eller ikke.

- Jeg vil ikke fortelle deg hvordan du installerer Patroni, fordi du kan google på Internett, du kan se på konfigurasjonsfilene for å forstå hvordan det hele starter, hvordan det er konfigurert. Du kan forstå ordningene, arkitekturene, finne informasjon om det på Internett.
- Jeg vil ikke snakke om noen andres opplevelse. Jeg vil bare snakke om problemene vi sto overfor.
- Og jeg vil ikke snakke om problemer som er utenfor Patroni og PostgreSQL. Hvis det for eksempel er problemer knyttet til balansering, når klyngen vår har kollapset, vil jeg ikke snakke om det.

Og en liten ansvarsfraskrivelse før vi starter vår rapport.
Alle disse problemene som vi møtte, vi hadde dem i løpet av de første 6-7-8 månedene av driften. Over tid kom vi til våre interne beste praksis. Og problemene våre forsvant. Derfor ble rapporten annonsert for et halvt år siden, da det hele var friskt i hodet mitt og jeg husket det hele perfekt.
I løpet av utarbeidelsen av rapporten tok jeg allerede opp gamle postmortem, så på loggene. Og noen av detaljene kan bli glemt, eller noen av noen detaljer kunne ikke undersøkes fullt ut under analysen av problemene, så på noen punkter kan det virke som om problemene ikke er fullt ut vurdert, eller det er noe mangel på informasjon. Og derfor ber jeg deg unnskylde meg for dette øyeblikket.

Hva er Patroni?
- Dette er en mal for å bygge HA. Det står i dokumentasjonen. Og fra mitt ståsted er dette en veldig riktig presisering. Patroni er ikke en sølvkule som vil løse alle problemene dine, det vil si at du må gjøre en innsats for å få det til å fungere og gi fordeler.
- Dette er en agenttjeneste som er installert på hver databasetjeneste og er et slags init-system for din Postgres. Den starter Postgres, stopper, starter på nytt, konfigurerer på nytt og endrer topologien til klyngen din.
- Følgelig, for å lagre tilstanden til klyngen, er dens nåværende representasjon, slik den ser ut, nødvendig med en slags lagring. Og fra dette synspunktet tok Patroni veien for å lagre tilstand i et eksternt system. Det er et distribuert konfigurasjonslagringssystem. Det kan være Etcd, Consul, ZooKeeper eller kubernetes Etcd, dvs. ett av disse alternativene.
- Og en av funksjonene til Patroni er at du får autofiler ut av esken, bare ved å sette den opp. Hvis vi tar Repmgr for sammenligning, er filen inkludert der. Med Repmgr får vi en overgang, men hvis vi vil ha en autofiler, må vi konfigurere den i tillegg. Patroni har allerede en autofiler ut av esken.
- Og det er mange andre ting. For eksempel vedlikehold av konfigurasjoner, helle nye replikaer, backup osv. Men dette er utenfor rammen av rapporten, jeg skal ikke snakke om det.

Og et lite resultat er at hovedoppgaven til Patroni er å gjøre en autofil godt og pålitelig slik at klyngen vår forblir operativ og applikasjonen ikke merker endringer i klyngetopologien.

Men når vi begynner å bruke Patroni, blir systemet vårt litt mer komplisert. Hvis vi tidligere hadde Postgres, så når vi bruker Patroni får vi Patroni selv, vi får DCS der tilstanden er lagret. Og det hele må fungere på en eller annen måte. Så hva kan gå galt?
Kan bryte:
- Postgres kan gå i stykker. Det kan være en mester eller en kopi, en av dem kan mislykkes.
- Patroni selv kan gå i stykker.
- DCS der tilstanden er lagret kan gå i stykker.
- Og nettverket kan gå i stykker.
Alle disse punktene vil jeg ta for meg i rapporten.

Jeg vil vurdere saker etter hvert som de blir mer komplekse, ikke ut fra at saken involverer mange komponenter. Og fra synspunkt av subjektive følelser, at denne saken var vanskelig for meg, var det vanskelig å demontere den ... og omvendt, noen sak var lett og det var lett å demontere den.

Og det første tilfellet er det enkleste. Dette er tilfellet når vi tok en databaseklynge og distribuerte DCS-lagringen vår på samme klynge. Dette er den vanligste feilen. Dette er en feil i bygningsarkitekturer, det vil si å kombinere forskjellige komponenter på ett sted.
Så, det var en filur, la oss gå for å håndtere det som skjedde.

Og her er vi interessert i når filen skjedde. Det vil si at vi er interessert i dette øyeblikket da klyngetilstanden endret seg.
Men filen er ikke alltid øyeblikkelig, det vil si at den ikke tar noen tidsenhet, den kan bli forsinket. Det kan være langvarig.
Derfor har den en starttid og en sluttid, det vil si at det er en kontinuerlig hendelse. Og vi deler alle hendelser inn i tre intervaller: vi har tid før filer, under filer og etter filer. Det vil si at vi vurderer alle hendelser i denne tidslinjen.

Og det første, når en filur skjedde, ser vi etter årsaken til det som skjedde, hva som var årsaken til det som førte til filureren.
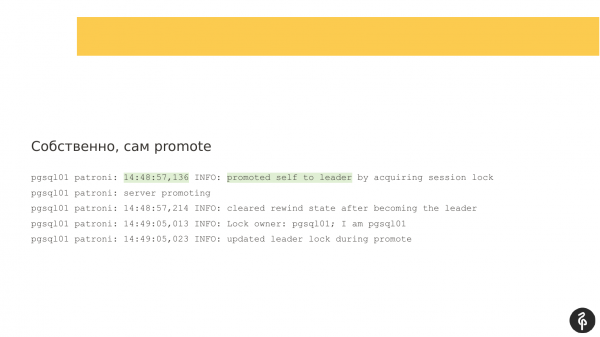
Ser vi på tømmerstokkene blir det klassiske Patroni-stokker. Han forteller oss i dem at serveren har blitt master, og rollen som master har gått over til denne noden. Her er det fremhevet.

Deretter må vi forstå hvorfor filen skjedde, det vil si hvilke hendelser som skjedde som fikk masterrollen til å flytte fra en node til en annen. Og i dette tilfellet er alt enkelt. Vi har en feil i samhandling med lagringssystemet. Mesteren innså at han ikke kunne jobbe med DCS, det vil si at det var et slags problem med samhandlingen. Og han sier at han ikke lenger kan være mester og sier opp. Denne linjen "degraderte selv" sier akkurat det.

Hvis vi ser på hendelsene som gikk forut for filen, kan vi se der selve årsakene til at problemet fortsatte med veiviseren.
Hvis vi ser på Patroni-loggene, vil vi se at vi har mange feil, timeouts, det vil si at Patroni-agenten ikke kan jobbe med DCS. I dette tilfellet er dette Consul-agenten, som kommuniserer på port 8500.
Problemet her er at Patroni og databasen kjører på samme vert. Consul-servere kjørte også på den samme verten. Ved å opprette en belastning på serveren skapte vi problemer for servere Konsul. De klarte ikke å kommunisere normalt.

Etter en tid, da belastningen avtok, kunne vår Patroni kommunisere med agenter igjen. Normalt arbeid ble gjenopptatt. Og den samme Pgdb-2-serveren ble master igjen. Det vil si at det var en liten flip, på grunn av hvilken noden sa opp kreftene til mesteren, og deretter overtok dem igjen, det vil si at alt kom tilbake som det var.

Og dette kan betraktes som en falsk alarm, eller det kan betraktes som at Patroni gjorde alt riktig. Det vil si at han innså at han ikke kunne opprettholde klyngens tilstand og fjernet sin autoritet.
Og her oppsto problemet på grunn av at Consul-serverne er på samme maskinvare som basene. Følgelig, enhver belastning: enten det er belastningen på disker eller prosessorer, påvirker det også interaksjonen med Consul-klyngen.

Og vi bestemte oss for at det ikke skulle bo sammen, vi tildelte en egen klynge til konsul. Og Patroni jobbet allerede med en egen konsul, det vil si at det var en egen Postgres-klynge, en egen konsulklynge. Dette er en grunnleggende instruksjon om hvordan du bærer og oppbevarer alle disse tingene slik at det ikke lever sammen.
Som et alternativ kan du vri parameterne ttl, loop_wait, retry_timeout, dvs. prøve å overleve disse kortsiktige belastningstoppene ved å øke disse parameterne. Men dette er ikke det mest passende alternativet, fordi denne belastningen kan være lang i tid. Og vi vil ganske enkelt gå utover disse grensene for disse parameterne. Og det hjelper kanskje ikke egentlig.
Det første problemet, som du forstår, er enkelt. Vi tok og satte DCS sammen med basen, vi fikk et problem.

Det andre problemet ligner det første. Det ligner på at vi igjen har interoperabilitetsproblemer med DCS-systemet.

Ser vi på loggene vil vi se at vi igjen har en kommunikasjonsfeil. Og Patroni sier at jeg ikke kan samhandle med DCS, så den nåværende masteren går inn i replikamodus.
Den gamle mesteren blir en kopi, her fungerer Patroni, som det skal. Den kjører pg_rewind for å spole tilbake transaksjonsloggen og deretter koble til den nye masteren for å ta igjen den nye masteren. Her trener Patroni, som han skal.

Her må vi finne plassen som gikk foran filer, dvs. de feilene som gjorde at vi hadde en fil. Og i denne forbindelse er Patroni-logger ganske praktiske å jobbe med. Han skriver de samme meldingene med et visst intervall. Og hvis vi begynner å bla raskt gjennom disse loggene, så vil vi se fra loggene at loggene har endret seg, noe som betyr at noen problemer har begynt. Vi kommer raskt tilbake til dette stedet, ser hva som skjer.
Og i en normal situasjon ser loggene omtrent slik ut. Eieren av låsen kontrolleres. Og hvis eieren for eksempel har endret seg, kan det oppstå noen hendelser som Patroni må svare på. Men i dette tilfellet har vi det bra. Vi leter etter stedet hvor feilene startet.

Og etter å ha scrollet til det punktet hvor feilene begynte å dukke opp, ser vi at vi har hatt en auto-filover. Og siden våre feil var relatert til interaksjon med DCS og i vårt tilfelle brukte vi Consul, ser vi også på Consul-loggene, hva som skjedde der.
Ved å grovt sammenligne tidspunktet for filen og tiden i konsulloggene, ser vi at våre naboer i konsulklyngen begynte å tvile på eksistensen til andre medlemmer av konsulklyngen.

Og hvis du også ser på loggene til andre Consul-agenter, kan du også se at det foregår en slags nettverkskollaps der. Og alle medlemmer av Consul-klyngen tviler på hverandres eksistens. Og dette var drivkraften for filisten.
Hvis du ser på hva som skjedde før disse feilene, kan du se at det er alle slags feil, for eksempel fristen, RPC falt, det vil si at det helt klart er en slags problem i samspillet mellom Consul-klyngemedlemmene med hverandre .

Det enkleste svaret er å reparere nettverket. Men for meg som står på podiet er det lett å si dette. Men omstendighetene er slik at ikke alltid kunden har råd til å reparere nettverket. Han kan bo i en DC og kan ikke være i stand til å reparere nettverket, påvirke utstyret. Og så noen andre alternativer er nødvendige.

Det finnes alternativer:
- Det enkleste alternativet, som er skrevet, etter min mening, selv i dokumentasjonen, er å deaktivere Consul-sjekker, det vil si ganske enkelt å sende en tom matrise. Og vi ber konsul-agenten ikke bruke noen sjekker. Med disse kontrollene kan vi ignorere disse nettverksstormene og ikke starte en fil.
- Et annet alternativ er å dobbeltsjekke raft_multiplier. Dette er en parameter for selve Consul-serveren. Som standard er den satt til 5. Denne verdien anbefales av dokumentasjonen for oppsamlingsmiljøer. Dette påvirker faktisk frekvensen av meldinger mellom medlemmer av Consul-nettverket. Faktisk påvirker denne parameteren hastigheten på tjenestekommunikasjon mellom medlemmer av Consul-klyngen. Og for produksjon anbefales det allerede å redusere det slik at nodene utveksler meldinger oftere.
- Et annet alternativ vi har kommet opp med er å øke prioriteringen av Consul-prosesser blant andre prosesser for operativsystemets prosessplanlegger. Det er en så "fin" parameter, den bestemmer bare prioriteten til prosessene som tas i betraktning av OS-planleggeren ved planlegging. Vi har også redusert den fine verdien for Consul-agenter, d.v.s. økte prioriteringen slik at operativsystemet gir Consul-prosesser mer tid til å jobbe og utføre koden deres. I vårt tilfelle løste dette problemet vårt.
- Et annet alternativ er å ikke bruke Consul. Jeg har en venn som er en stor tilhenger av Etcd. Og vi krangler jevnlig med ham hva som er bedre Etcd eller Consul. Men når det gjelder hva som er bedre, er vi vanligvis enige med ham i at Consul har en agent som skal kjøre på hver node med en database. Det vil si at interaksjonen til Patroni med Consul-klyngen går gjennom denne agenten. Og denne agenten blir en flaskehals. Hvis noe skjer med agenten, kan ikke Patroni lenger jobbe med Consul-klyngen. Og dette er problemet. Det er ingen agent i Etcd-planen. Patroni kan jobbe direkte med en liste over Etcd-servere og allerede kommunisere med dem. I denne forbindelse, hvis du bruker Etcd i bedriften din, vil Etcd sannsynligvis være et bedre valg enn Consul. Men vi hos våre kunder er alltid begrenset av hva kunden har valgt og bruker. Og vi har Consul for det meste for alle kunder.
- Og det siste punktet er å revidere parameterverdiene. Vi kan heve disse parameterne i håp om at våre kortsiktige nettverksproblemer blir korte og ikke faller utenfor rekkevidden til disse parameterne. På denne måten kan vi redusere aggressiviteten til Patroni til autofil hvis noen nettverksproblemer oppstår.
Jeg tror mange som bruker Patroni er kjent med denne kommandoen.
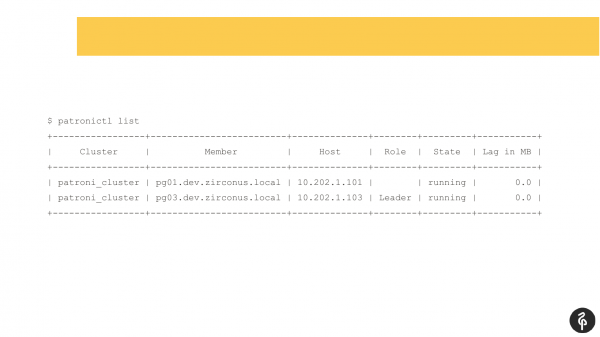
Denne kommandoen viser gjeldende tilstand for klyngen. Og ved første øyekast kan dette bildet virke normalt. Vi har en master, vi har en replika, det er ingen replikeringsforsinkelse. Men dette bildet er normalt helt til vi vet at denne klyngen skal ha tre noder, ikke to.

Følgelig var det en autofil. Og etter denne autofilen forsvant vår kopi. Vi må finne ut hvorfor hun forsvant og bringe henne tilbake, gjenopprette henne. Og vi går igjen til loggene og ser hvorfor vi hadde en auto-filover.

I dette tilfellet ble den andre kopien mesteren. Det er greit her.

Og vi må se på kopien som falt av og som ikke er i klyngen. Vi åpner Patroni-loggene og ser at vi hadde et problem under prosessen med å koble til klyngen på pg_rewind-stadiet. For å koble til klyngen må du spole tilbake transaksjonsloggen, be om den nødvendige transaksjonsloggen fra masteren og bruke den til å ta igjen masteren.
I dette tilfellet har vi ingen transaksjonslogg og replikaen kan ikke starte. Følgelig stopper vi Postgres med en feil. Og derfor er den ikke i klyngen.

Vi må forstå hvorfor det ikke er i klyngen og hvorfor det ikke var noen logger. Vi går til den nye mesteren og ser på hva han har i loggene. Det viser seg at når pg_rewind ble gjort, oppsto et sjekkpunkt. Og noen av de gamle transaksjonsloggene ble ganske enkelt omdøpt. Da den gamle masteren prøvde å koble til den nye masteren og spørre etter disse loggene, ble de allerede omdøpt, de fantes bare ikke.

Jeg sammenlignet tidsstempler når disse hendelsene skjedde. Og der er forskjellen bokstavelig talt 150 millisekunder, det vil si at sjekkpunktet fullført på 369 millisekunder, ble WAL-segmentene omdøpt. Og bokstavelig talt i 517, etter 150 millisekunder, startet tilbakespolingen på den gamle kopien. Det vil si at bokstavelig talt 150 millisekunder var nok for oss slik at kopien ikke kunne kobles til og tjene.

Hva er alternativene?
Vi brukte først replikeringsspor. Vi syntes det var bra. Selv om vi i den første operasjonsfasen slo av sporene. Det virket for oss at hvis sporene akkumulerer mange WAL-segmenter, kan vi droppe masteren. Han vil falle. Vi led en stund uten spor. Og vi innså at vi trenger spilleautomater, vi returnerte sporene.
Men det er et problem her, at når masteren går til replikaen, sletter den sporene og sletter WAL-segmentene sammen med sporene. Og for å eliminere dette problemet, bestemte vi oss for å heve parameteren wal_keep_segments. Den har som standard 8 segmenter. Vi hevet den til 1 og så på hvor mye ledig plass vi hadde. Og vi donerte 000 gigabyte til wal_keep_segments. Det vil si at når vi bytter har vi alltid en reserve på 16 gigabyte med transaksjonslogger på alle noder.
Og pluss - den er fortsatt relevant for langsiktige vedlikeholdsoppgaver. La oss si at vi må oppdatere en av kopiene. Og vi ønsker å slå den av. Vi må oppdatere programvaren, kanskje operativsystemet, noe annet. Og når vi slår av en kopi, fjernes også sporet for den kopien. Og hvis vi bruker en liten wal_keep_segments, vil transaksjonsloggene gå tapt med et langt fravær av en replika. Vi vil opprette en replika, den vil be om de transaksjonsloggene der den stoppet, men de er kanskje ikke på masteren. Og kopien vil heller ikke kunne kobles til. Derfor har vi et stort lager av blader.

Vi har en produksjonsbase. Det er allerede prosjekter på gang.
Det var en fil. Vi gikk inn og så – alt er i orden, replikaene er på plass, det er ingen replikasjonsetterslep. Det er heller ingen feil i loggene, alt er i orden.
Produktteamet sier at det burde være noen data, men vi ser det fra én kilde, men vi ser det ikke i databasen. Og vi må forstå hva som skjedde med dem.

Det er tydelig at pg_rewind savnet dem. Vi forsto dette umiddelbart, men gikk for å se hva som skjedde.

I loggene kan vi alltid finne når filen skjedde, hvem som ble masteren, og vi kan finne ut hvem som var den gamle masteren og når han ønsket å bli en kopi, dvs. vi trenger disse loggene for å finne ut mengden transaksjonslogger som var tapt.
Vår gamle mester har startet på nytt. Og Patroni ble registrert i autorun. Lanserte Patroni. Deretter startet han Postgres. Mer presist, før du startet Postgres og før han gjorde det til en kopi, lanserte Patroni pg_rewind-prosessen. Følgelig slettet han deler av transaksjonsloggene, lastet ned nye og koblet til. Her jobbet Patroni smart, altså som forventet. Klyngen er gjenopprettet. Vi hadde 3 noder, etter filer 3 noder - alt er kult.

Vi har mistet noen data. Og vi må forstå hvor mye vi har mistet. Vi leter etter akkurat øyeblikket da vi hadde en tilbakespoling. Vi finner det i slike journalposter. Rewind startet, gjorde noe der og sluttet.

Vi må finne posisjonen i transaksjonsloggen der den gamle masteren slapp. I dette tilfellet er dette merket. Og vi trenger et annet merke, det vil si avstanden som den gamle mesteren skiller seg fra den nye.
Vi tar den vanlige pg_wal_lsn_diff og sammenligner disse to merkene. Og i dette tilfellet får vi 17 megabyte. Mye eller lite, alle bestemmer selv. For for noen er 17 megabyte ikke mye, for noen er det mye og uakseptabelt. Her bestemmer hver enkelt selv i henhold til virksomhetens behov.

Men hva har vi funnet ut selv?
Først må vi bestemme selv – trenger vi alltid at Patroni automatisk starter etter en omstart av systemet? Det hender ofte at vi må gå til den gamle mesteren, se hvor langt han har gått. Kanskje inspisere deler av transaksjonsloggen, se hva som er der. Og for å forstå om vi kan miste disse dataene eller om vi må kjøre den gamle masteren i frittstående modus for å trekke disse dataene ut.
Og først etter det må vi bestemme om vi kan forkaste disse dataene eller vi kan gjenopprette dem, koble denne noden som en replika til klyngen vår.
I tillegg er det en "maximum_lag_on_failover" parameter. Som standard, hvis minnet mitt tjener meg, har denne parameteren en verdi på 1 megabyte.
Hvordan jobber han? Hvis kopien vår er bak med 1 megabyte med data i replikeringsforsinkelsen, deltar ikke denne kopien i valget. Og hvis det plutselig er en filover, ser Patroni på hvilke kopier som henger etter. Hvis de ligger bak et stort antall transaksjonslogger, kan de ikke bli en master. Dette er en veldig god sikkerhetsfunksjon som hindrer deg i å miste mye data.
Men det er et problem ved at replikeringsforsinkelsen i Patroni-klyngen og DCS oppdateres med et visst intervall. Jeg tror 30 sekunder er standard ttl-verdi.
Følgelig kan det være en situasjon der det er ett replikasjonsforsinkelse for replikaer i DCS, men faktisk kan det være et helt annet etterslep eller det kan ikke være noe etterslep i det hele tatt, dvs. at denne tingen ikke er sanntid. Og det gjenspeiler ikke alltid det virkelige bildet. Og det er ikke verdt å gjøre fancy logikk på det.
Og risikoen for tap består alltid. Og i verste fall én formel, og i gjennomsnittlig en annen formel. Det vil si at når vi planlegger implementeringen av Patroni og evaluerer hvor mye data vi kan miste, må vi stole på disse formlene og omtrent forestille oss hvor mye data vi kan miste.
Og det er gode nyheter. Når den gamle mesteren har gått foran, kan han gå videre på grunn av noen bakgrunnsprosesser. Det vil si at det var en slags autovakuum, han skrev dataene, lagret dem i transaksjonsloggen. Og vi kan enkelt ignorere og miste disse dataene. Det er ikke noe problem i dette.

Og slik ser loggene ut hvis maximum_lag_on_failover er satt og en filer har oppstått, og du må velge en ny master. Replikaen vurderer seg selv som ute av stand til å delta i valget. Og hun nekter å delta i oppløpet om lederen. Og hun venter på at en ny mester skal velges, slik at hun så kan koble seg til den. Dette er et tilleggstiltak mot tap av data.

Her har vi et produktteam som skrev at deres produkt har problemer med Postgres. Samtidig kan ikke selve masteren nås, fordi den ikke er tilgjengelig via SSH. Og autofilen skjer heller ikke.
Denne verten ble tvunget til å starte på nytt. På grunn av omstarten skjedde det en auto-fil, selv om det var mulig å gjøre en manuell auto-fil, slik jeg nå forstår. Og etter omstarten skal vi allerede se hva vi hadde med den nåværende masteren.
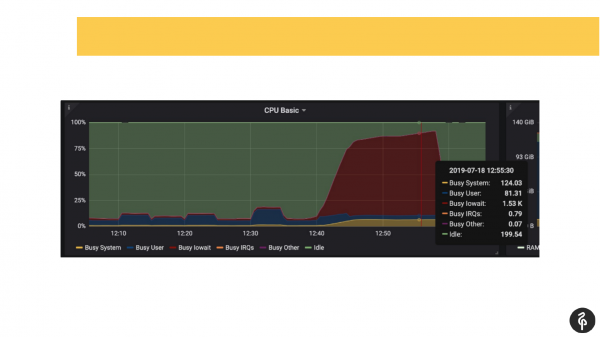
Samtidig visste vi på forhånd at vi hadde problemer med disker, det vil si at vi allerede fra overvåking visste hvor vi skulle grave og hva vi skulle se etter.

Vi kom inn i postgres-loggen, begynte å se hva som skjedde der. Vi så commits som varte der i ett, to, tre sekunder, noe som slett ikke er normalt. Vi så at autovakuumet vårt starter veldig sakte og merkelig. Og vi så midlertidige filer på disken. Det vil si at dette er alle indikatorer på problemer med disker.

Vi så inn i systemet dmesg (kjernelogg). Og vi så at vi har problemer med en av diskene. Diskundersystemet var programvare Raid. Vi så på /proc/mdstat og så at vi manglet en stasjon. Det vil si at det er et Raid på 8 disker, vi mangler en. Hvis du ser nøye på lysbildet, kan du i utgangen se at vi ikke har sde der. Hos oss har, betinget sett, disken falt ut. Dette utløste diskproblemer, og applikasjoner opplevde også problemer når de jobbet med Postgres-klyngen.

Og i dette tilfellet ville ikke Patroni hjelpe oss på noen måte, fordi Patroni ikke har som oppgave å overvåke tilstanden til serveren, tilstanden til disken. Og vi må overvåke slike situasjoner ved ekstern overvåking. Vi la raskt til diskovervåking til ekstern overvåking.
Og det var en slik tanke - kunne fekting eller vakthund-programvare hjelpe oss? Vi trodde at han neppe ville ha hjulpet oss i dette tilfellet, for under problemene fortsatte Patroni å samhandle med DCS-klyngen og så ikke noe problem. Det vil si at fra synspunktet til DCS og Patroni var alt bra med klyngen, selv om det faktisk var problemer med disken, var det problemer med tilgjengeligheten til databasen.
Etter min mening er dette et av de merkeligste problemene jeg har forsket på på veldig lenge, jeg har lest mange logger, plukket om og kalt det en klyngesimulator.

Problemet var at den gamle mesteren ikke kunne bli en normal kopi, dvs. Patroni startet den, Patroni viste at denne noden var tilstede som en kopi, men samtidig var den ikke en normal kopi. Nå vil du se hvorfor. Dette er hva jeg har holdt fra analysen av det problemet.

Og hvordan startet det hele? Det startet, som i forrige oppgave, med skivebremser. Vi hadde forpliktelser for et sekund, to.

Det var brudd i forbindelsene, det vil si at klienter ble revet.

Det var blokkeringer av ulik alvorlighetsgrad.

Og følgelig er diskundersystemet ikke veldig responsivt.

Og det mest mystiske for meg er den umiddelbare nedleggelsesforespørselen som kom. Postgres har tre avstengningsmoduser:
- Det er grasiøst når vi venter på at alle klienter skal koble fra på egen hånd.
- Det er raskt når vi tvinger klienter til å koble fra fordi vi skal stenge.
- Og umiddelbar. I dette tilfellet forteller ikke engang umiddelbar klienter om å stenge, den slår seg bare av uten forvarsel. Og til alle klienter sender operativsystemet allerede en RST-melding (en TCP-melding om at forbindelsen er avbrutt og klienten ikke har noe mer å fange).
Hvem sendte dette signalet? Postgres bakgrunnsprosesser sender ikke slike signaler til hverandre, det vil si at dette er kill-9. De sender ikke slike ting til hverandre, de reagerer bare på slike ting, det vil si at dette er en nødstart av Postgres. Hvem som sendte det, vet jeg ikke.
Jeg så på den "siste" kommandoen og jeg så en person som også logget på denne serveren med oss, men jeg var for sjenert til å stille et spørsmål. Kanskje det var kill -9. Jeg ville sett kill -9 i loggene, fordi Postgres sier det tok kill -9, men jeg så det ikke i loggene.

Når jeg så videre, så jeg at Patroni ikke skrev til loggen på ganske lenge - 54 sekunder. Og hvis vi sammenligner to tidsstempler, var det ingen meldinger på omtrent 54 sekunder.
Og i løpet av denne tiden var det en autofil. Patroni gjorde en god jobb her igjen. Vår gamle herre var utilgjengelig, noe skjedde med ham. Og valget av en ny mester begynte. Alt fungerte bra her. Vår pgsql01 har blitt den nye lederen.

Vi har en kopi som har blitt en mester. Og det er et annet svar. Og det var problemer med den andre kopien. Hun prøvde å rekonfigurere. Slik jeg forstår det, prøvde hun å endre recovery.conf, starte Postgres på nytt og koble til den nye masteren. Hun skriver meldinger hvert 10. sekund om at hun prøver, men hun lykkes ikke.

Og under disse forsøkene kommer et umiddelbar avstengningssignal til den gamle mesteren. Masteren startes på nytt. Og også gjenoppretting stopper fordi den gamle masteren starter på nytt. Det vil si at replikaen ikke kan koble til den, fordi den er i avstengningsmodus.

På et tidspunkt fungerte det, men replikeringen startet ikke.
Min eneste gjetning er at det var en gammel masteradresse i recovery.conf. Og når en ny mester dukket opp, prøvde den andre kopien fortsatt å koble til den gamle mester.
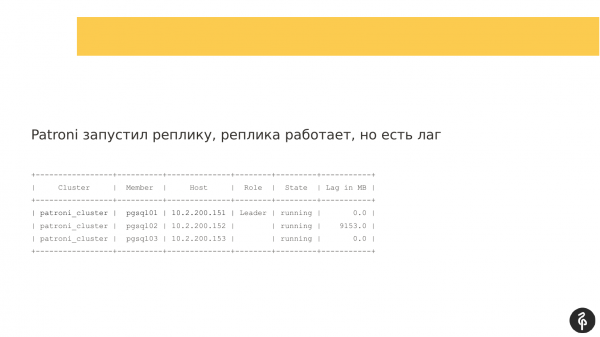
Da Patroni startet opp på den andre kopien, startet noden opp, men kunne ikke replikere. Og det ble dannet et replikasjonsforsinkelse, som så omtrent slik ut. Det vil si at alle tre nodene var på plass, men den andre noden sakket etter.
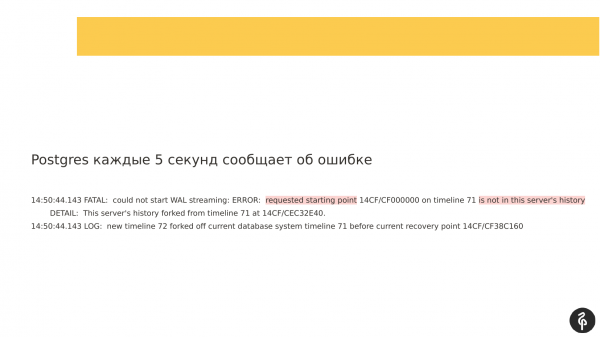
Samtidig, hvis du ser på loggene som ble skrevet, kunne du se at replikering ikke kunne starte fordi transaksjonsloggene var forskjellige. Og de transaksjonsloggene som masteren tilbyr, som er spesifisert i recovery.conf, passer ganske enkelt ikke til vår nåværende node.

Og her tok jeg feil. Jeg måtte komme og se hva som var i recovery.conf for å teste hypotesen min om at vi koblet til feil master. Men så holdt jeg bare på med dette, og det falt meg ikke inn, eller jeg så at kopien ble hengende etter og måtte fylles på igjen, det vil si at jeg på en eller annen måte jobbet uforsiktig. Dette var min felles.

Etter 30 minutter kom allerede administratoren, det vil si at jeg startet Patroni på nytt på replikaen. Jeg har allerede satt en stopper for det, jeg tenkte at det måtte fylles på igjen. Og jeg tenkte - jeg starter Patroni på nytt, kanskje det dukker opp noe bra. Gjenoppretting startet. Og basen åpnet til og med, den var klar til å ta imot forbindelser.
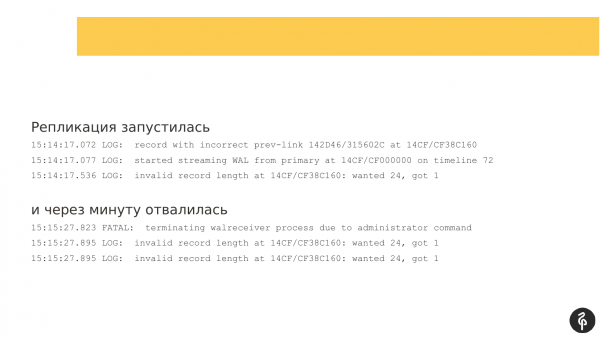
Replikering har startet. Men et minutt senere falt hun av med en feil om at transaksjonslogger ikke passer for henne.

Jeg tenkte jeg skulle starte på nytt. Jeg startet Patroni på nytt, og jeg startet ikke Postgres på nytt, men startet Patroni på nytt i håp om at den på magisk vis ville starte databasen.

Replikeringen startet på nytt, men merkene i transaksjonsloggen var forskjellige, de var ikke de samme som forrige startforsøk. Replikeringen stoppet igjen. Og budskapet var allerede litt annerledes. Og det var ikke veldig informativt for meg.

Og så går det opp for meg - hva om jeg starter Postgres på nytt, på dette tidspunktet lager jeg et sjekkpunkt på gjeldende master for å flytte punktet i transaksjonsloggen litt fremover slik at gjenoppretting starter fra et annet øyeblikk? I tillegg hadde vi fortsatt aksjer av WAL.

Jeg startet Patroni på nytt, gjorde et par sjekkpunkter på masteren, et par restartpunkter på replikaen da den åpnet. Og det hjalp. Jeg tenkte lenge på hvorfor det hjalp og hvordan det fungerte. Og kopien startet. Og replikasjonen ble ikke lenger revet.

Et slikt problem for meg er et av de mer mystiske, som jeg fortsatt lurer på over hva som egentlig skjedde der.
Hva er implikasjonene her? Patroni kan fungere etter hensikten og uten feil. Men samtidig er ikke dette en 100% garanti for at alt er bra med oss. Replikaen kan starte, men den kan være i en halvarbeidende tilstand, og applikasjonen kan ikke fungere med en slik replika, fordi det vil være gamle data.
Og etter filen må du alltid sjekke at alt er i orden med klyngen, det vil si at det er det nødvendige antallet replikaer, det er ingen replikeringsforsinkelse.
Og mens vi går gjennom disse problemene, vil jeg komme med anbefalinger. Jeg prøvde å kombinere dem til to lysbilder. Sannsynligvis kunne alle historiene kombineres til to lysbilder og bare fortelles.

Når du bruker Patroni, må du ha overvåking. Du bør alltid vite når en autofilover skjedde, for hvis du ikke vet at du hadde en autofilover, har du ingen kontroll over klyngen. Og det er ille.
Etter hver filer må vi alltid kontrollere klyngen manuelt. Vi må sørge for at vi alltid har et oppdatert antall replikaer, det er ingen replikeringsforsinkelse, det er ingen feil i loggene knyttet til streaming replikering, med Patroni, med DCS-systemet.
Automatisering kan fungere vellykket, Patroni er et veldig godt verktøy. Det kan fungere, men dette vil ikke bringe klyngen til ønsket tilstand. Og hvis vi ikke finner ut av det, får vi problemer.
Og Patroni er ikke en sølvkule. Vi må fortsatt forstå hvordan Postgres fungerer, hvordan replikering fungerer og hvordan Patroni fungerer med Postgres, og hvordan kommunikasjon mellom noder tilbys. Dette er nødvendig for å kunne fikse problemer med hendene.

Hvordan forholder jeg meg til spørsmålet om diagnose? Det har seg slik at vi jobber med forskjellige klienter og ingen har en ELK-stack, og vi må sortere loggene ved å åpne 6 konsoller og 2 faner. I den ene fanen er dette Patroni-loggene for hver node, i den andre fanen er dette Consul-loggene, eller Postgres om nødvendig. Det er veldig vanskelig å diagnostisere dette.
Hvilke tilnærminger har jeg tatt? Først ser jeg alltid når filisten har kommet. Og for meg er dette et vannskille. Jeg ser på hva som skjedde før filur, under filur og etter filur. Fileover har to merker: dette er start- og sluttid.
Deretter ser jeg i loggene etter hendelser før filen, som gikk foran filen, dvs. jeg ser etter årsakene til at filen skjedde.
Og dette gir et bilde av å forstå hva som skjedde og hva som kan gjøres i fremtiden slik at slike omstendigheter ikke oppstår (og som et resultat er det ingen filer).
Og hvor ser vi vanligvis? Jeg ser:
- Først til Patroni-loggene.
- Deretter ser jeg på Postgres-loggene, eller DCS-loggene, avhengig av hva som ble funnet i Patroni-loggene.
- Og systemloggene gir også noen ganger en forståelse av hva som forårsaket filen.

Hva føler jeg om Patroni? Jeg har et veldig godt forhold til Patroni. Etter min mening er dette det beste som finnes i dag. Jeg kjenner mange andre produkter. Disse er Stolon, Repmgr, Pg_auto_failover, PAF. 4 verktøy. Jeg prøvde dem alle. Patroni er min favoritt.
Hvis de spør meg: "Anbefaler jeg Patroni?". Jeg vil si ja, fordi jeg liker Patroni. Og jeg tror jeg har lært å lage mat.
Hvis du er interessert i å se hvilke andre problemer det er med Patroni i tillegg til problemene jeg har nevnt, kan du alltids sjekke ut siden på GitHub. Det er mange forskjellige historier og mange interessante saker diskuteres der. Og som et resultat ble noen feil introdusert og løst, det vil si at dette er interessant lesning.
Det er noen interessante historier om folk som skyter seg selv i foten. Veldig informativ. Du leser og forstår at det ikke er nødvendig å gjøre det. Jeg krysset av for meg selv.
Og jeg vil gjerne si en stor takk til Zalando for utviklingen av dette prosjektet, nemlig til Alexander Kukushkin og Alexey Klyukin. Aleksey Klyukin er en av medforfatterne, han jobber ikke lenger på Zalando, men dette er to personer som begynte å jobbe med dette produktet.
Og jeg synes at Patroni er en veldig kul ting. Jeg er glad for at hun finnes, det er interessant med henne. Og en stor takk til alle bidragsyterne som skriver patcher til Patroni. Jeg håper at Patroni vil bli mer moden, kul og effektiv med årene. Den er allerede funksjonell, men jeg håper den blir enda bedre. Derfor, hvis du planlegger å bruke Patroni, ikke vær redd. Dette er en god løsning, den kan implementeres og brukes.
Det er alt. Hvis du har spørsmål, spør.

spørsmål
Takk for rapporten! Hvis du fortsatt trenger å se der veldig nøye etter en filer, hvorfor trenger vi da en automatisk filer?
For det er nye ting. Vi har bare vært sammen med henne i ett år. Bedre å være trygg. Vi ønsker å komme inn og se at alt virkelig fungerte som det skulle. Dette er nivået av voksen mistillit - det er bedre å dobbeltsjekke og se.
For eksempel gikk vi om morgenen og så, ikke sant?
Ikke om morgenen, vi lærer vanligvis om autofilen nesten umiddelbart. Vi mottar varsler, vi ser at en autofil har oppstått. Vi går nesten umiddelbart og ser. Men alle disse kontrollene bør bringes til overvåkingsnivået. Hvis du får tilgang til Patroni via REST API, er det en historie. Etter historikk kan du se tidsstemplene når filen skjedde. Basert på dette kan overvåking gjøres. Du kan se historien, hvor mange arrangementer som var der. Hvis vi har flere hendelser, har det oppstått en autofil. Du kan gå og se. Eller vår overvåkingsautomatisering sjekket at vi har alle kopiene på plass, det er ingen etterslep og alt er i orden.
Takk!
Tusen takk for den flotte historien! Hvis vi flyttet DCS-klyngen et sted langt fra Postgres-klyngen, må denne klyngen også vedlikeholdes med jevne mellomrom? Hva er de beste fremgangsmåtene for at enkelte deler av DCS-klyngen må slås av, noe som må gjøres med dem osv.? Hvordan overlever hele denne strukturen? Og hvordan gjør du disse tingene?
For ett selskap var det nødvendig å lage en matrise med problemer, hva skjer hvis en av komponentene eller flere komponenter feiler. I henhold til denne matrisen går vi sekvensielt gjennom alle komponentene og bygger scenarier i tilfelle feil på disse komponentene. Følgelig, for hvert feilscenario, kan du ha en handlingsplan for gjenoppretting. Og når det gjelder DCS, kommer det som en del av standardinfrastrukturen. Og administratoren administrerer det, og vi stoler allerede på administratorene som administrerer det og deres evne til å fikse det i tilfelle ulykker. Hvis det ikke er noen DCS i det hele tatt, distribuerer vi det, men samtidig overvåker vi det ikke spesielt, fordi vi ikke er ansvarlige for infrastrukturen, men vi gir anbefalinger om hvordan og hva vi skal overvåke.
Det vil si, forsto jeg riktig at jeg må deaktivere Patroni, deaktivere filen, deaktivere alt før jeg gjør noe med vertene?
Det avhenger av hvor mange noder vi har i DCS-klyngen. Hvis det er mange noder og hvis vi deaktiverer bare én av nodene (replikaen), opprettholder klyngen et quorum. Og Patroni forblir operativ. Og ingenting utløses. Hvis vi har noen komplekse operasjoner som påvirker flere noder, hvis fravær kan ødelegge quorumet, så - ja, det kan være fornuftig å sette Patroni på pause. Den har en tilsvarende kommando - patronictl pause, patronictl CV. Vi stopper bare og autofiler fungerer ikke på det tidspunktet. Vi gjør vedlikehold på DCS-klyngen, så tar vi av pausen og fortsetter å leve.
Tusen takk!
Tusen takk for rapporten! Hvordan opplever produktteamet at data går tapt?
Produktteam bryr seg ikke, og teamledere er bekymret.
Hvilke garantier er det?
Garantier er veldig vanskelig. Alexander Kukushkin har en rapport "Hvordan beregne RPO og RTO", dvs. gjenopprettingstid og hvor mye data vi kan miste. Jeg tror vi må finne disse lysbildene og studere dem. Så vidt jeg husker, er det spesifikke trinn for hvordan man beregner disse tingene. Hvor mange transaksjoner vi kan miste, hvor mye data vi kan miste. Som et alternativ kan vi bruke synkron replikering på Patroni-nivå, men dette er et tveegget sverd: enten har vi datapålitelighet, eller så mister vi hastighet. Det er synkron replikering, men det garanterer heller ikke 100 % beskyttelse mot tap av data.
Alexey, takk for den flotte rapporten! Noen erfaring med å bruke Patroni for nullnivåbeskyttelse? Altså i forbindelse med synkron standby? Dette er det første spørsmålet. Og det andre spørsmålet. Du har brukt forskjellige løsninger. Vi brukte Repmgr, men uten autofiler, og nå planlegger vi å inkludere autofiler. Og vi vurderer Patroni som en alternativ løsning. Hva kan du si som fordeler sammenlignet med Repmgr?
Det første spørsmålet handlet om synkrone kopier. Ingen bruker synkron replikering her, fordi alle er redde (Flere klienter bruker det allerede, i prinsippet la de ikke merke til ytelsesproblemer - Talerens notat). Men vi har utviklet en regel for oss selv om at det skal være minst tre noder i en synkron replikeringsklynge, for hvis vi har to noder og hvis masteren eller replikaen feiler, bytter Patroni denne noden til frittstående modus slik at applikasjonen fortsetter å arbeid. I dette tilfellet er det fare for tap av data.
Når det gjelder det andre spørsmålet, har vi brukt Repmgr og gjør det fortsatt med noen klienter av historiske årsaker. Hva kan sies? Patroni kommer med en autofiler ut av esken, Repmgr kommer med autofiler som en tilleggsfunksjon som må aktiveres. Vi må kjøre Repmgr-demonen på hver node, og så kan vi konfigurere autofiler.
Repmgr sjekker om Postgres-noder er i live. Repmgr-prosesser sjekker eksistensen av hverandre, dette er ikke en veldig effektiv tilnærming. det kan være komplekse tilfeller av nettverksisolasjon der en stor Repmgr-klynge kan falle fra hverandre i flere mindre og fortsette å jobbe. Jeg har ikke fulgt Repmgr på lenge, kanskje det ble fikset ... eller kanskje ikke. Men fjerning av informasjon om tilstanden til klyngen i DCS, som Stolon, Patroni gjør, er det mest levedyktige alternativet.
Alexey, jeg har et spørsmål, kanskje et dårligere spørsmål. I et av de første eksemplene flyttet du DCS fra den lokale maskinen til en ekstern vert. Vi forstår at nettverket er en ting som har sine egne egenskaper, det lever av seg selv. Og hva skjer hvis DCS-klyngen av en eller annen grunn blir utilgjengelig? Jeg vil ikke si årsakene, det kan være mange av dem: fra de skjeve hendene til nettverkere til virkelige problemer.
Jeg sa det ikke høyt, men DCS-klyngen må også være failover, dvs. det er et oddetall noder, for at et quorum skal oppfylles. Hva skjer hvis DCS-klyngen blir utilgjengelig, eller et quorum ikke kan oppfylles, dvs. en slags nettverksdeling eller nodefeil? I dette tilfellet går Patroni-klyngen i skrivebeskyttet modus. Patroni-klyngen kan ikke bestemme tilstanden til klyngen og hva som skal gjøres. Den kan ikke kontakte DCS og lagre den nye klyngetilstanden der, så hele klyngen går i skrivebeskyttet. Og venter enten på manuell inngripen fra operatøren eller på at DCS skal komme seg.
Grovt sett blir DCS en tjeneste for oss like viktig som selve basen?
Ja Ja. I så mange moderne bedrifter er Service Discovery en integrert del av infrastrukturen. Det blir implementert allerede før det i det hele tatt var en database i infrastrukturen. Relativt sett ble infrastrukturen lansert, distribuert i DC, og vi har umiddelbart Service Discovery. Hvis det er Consul, kan DNS bygges på det. Hvis dette er Etcd, kan det være en del fra Kubernetes-klyngen, der alt annet vil bli distribuert. Det virker for meg som at Service Discovery allerede er en integrert del av moderne infrastrukturer. Og de tenker på det mye tidligere enn på databaser.
Takk!
Kilde: www.habr.com
