

Ytelse i .NET Core

Hei alle sammen! Denne artikkelen er en samling av beste fremgangsmåter som mine kolleger og jeg har brukt i lang tid når vi har jobbet med forskjellige prosjekter.
Informasjon om maskinen som beregningene ble utført på:BenchmarkDotNet=v0.11.5, OS=Windows 10. 0.18362
Intel Core i5-8250U CPU 1.60 GHz (Kaby Lake R), 1 CPU, 8 logiske og 4 fysiske kjerner
.NET Core SDK=3.0.100
[Vert]: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), 64bit RyuJIT
Kjerne: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), 64-bits RyuJIT
[Vert]: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64bit RyuJIT
Kjerne: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), 64-bits RyuJIT
Job=Core Runtime=Core
ToList vs ToArray og Cycles
Jeg planla å forberede denne informasjonen med utgivelsen av .NET Core 3.0, men de slo meg til det, jeg vil ikke stjele andres ære og kopiere andres informasjon, så jeg vil bare påpeke .
På mine egne vegne vil jeg bare presentere for deg mine målinger og resultater; Jeg la til omvendte løkker til dem for elskere av "C++-stilen" for skriveløkker.
Kode:
public class Bench
{
private List<int> _list;
private int[] _array;
[Params(100000, 10000000)] public int N;
[GlobalSetup]
public void Setup()
{
const int MIN = 1;
const int MAX = 10;
Random random = new Random();
_list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList();
_array = _list.ToArray();
}
[Benchmark]
public int ForList()
{
int total = 0;
for (int i = 0; i < _list.Count; i++)
{
total += _list[i];
}
return total;
}
[Benchmark]
public int ForListFromEnd()
{
int total = 0;t
for (int i = _list.Count-1; i > 0; i--)
{
total += _list[i];
}
return total;
}
[Benchmark]
public int ForeachList()
{
int total = 0;
foreach (int i in _list)
{
total += i;
}
return total;
}
[Benchmark]
public int ForeachArray()
{
int total = 0;
foreach (int i in _array)
{
total += i;
}
return total;
}
[Benchmark]
public int ForArray()
{
int total = 0;
for (int i = 0; i < _array.Length; i++)
{
total += _array[i];
}
return total;
}
[Benchmark]
public int ForArrayFromEnd()
{
int total = 0;
for (int i = _array.Length-1; i > 0; i--)
{
total += _array[i];
}
return total;
}
}
Ytelseshastighetene i .NET Core 2.2 og 3.0 er nesten identiske. Her er hva jeg klarte å få i .NET Core 3.0:
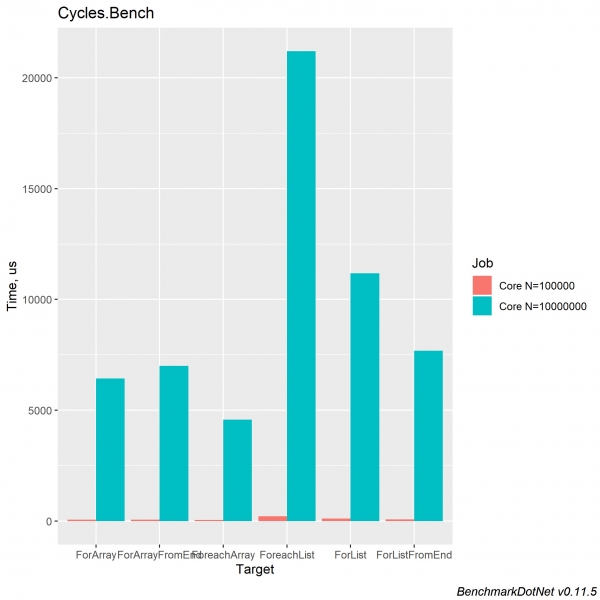
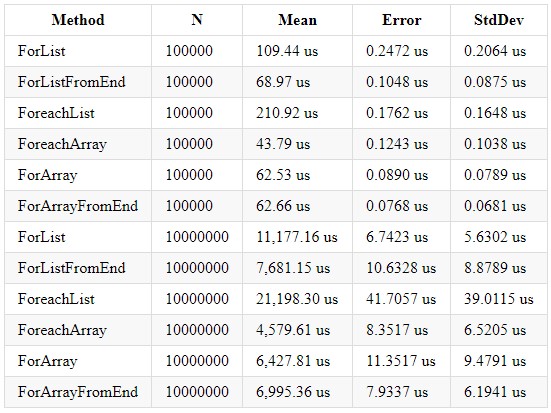
Vi kan konkludere med at iterativ behandling av en Array-samling er raskere på grunn av dens interne optimaliseringer og eksplisitt tildeling av samlingsstørrelse. Det er også verdt å huske at en listesamling har sine egne fordeler, og du bør bruke riktig samling avhengig av beregningene som kreves. Selv om du skriver logikk for å jobbe med løkker, ikke glem at dette er en vanlig løkke og den er også underlagt mulig løkkeoptimalisering. En artikkel ble publisert på habr for ganske lenge siden: . Den er fortsatt relevant og anbefalt lesning.
Kast
For et år siden jobbet jeg i et selskap på et legacy-prosjekt, i det prosjektet var det normalt å behandle feltvalidering gjennom en try-catch-throw-konstruksjon. Jeg forsto allerede da at dette var usunn forretningslogikk for prosjektet, så når det var mulig prøvde jeg å ikke bruke et slikt design. Men la oss finne ut hvorfor tilnærmingen til å håndtere feil med en slik konstruksjon er dårlig. Jeg skrev en liten kode for å sammenligne de to tilnærmingene og laget benchmarks for hvert alternativ.
Kode:
public bool ContainsHash()
{
bool result = false;
foreach (var file in _files)
{
var extension = Path.GetExtension(file);
if (_hash.Contains(extension))
result = true;
}
return result;
}
public bool ContainsHashTryCatch()
{
bool result = false;
try
{
foreach (var file in _files)
{
var extension = Path.GetExtension(file);
if (_hash.Contains(extension))
result = true;
}
if(!result)
throw new Exception("false");
}
catch (Exception e)
{
result = false;
}
return result;
}Resultatene i .NET Core 3.0 og Core 2.2 har et lignende resultat (.NET Core 3.0):
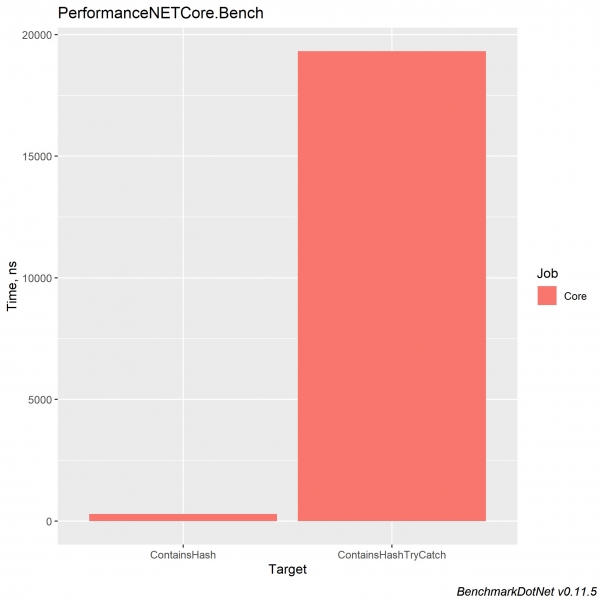
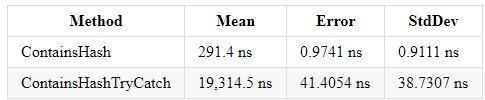
Try catch gjør koden vanskeligere å forstå og øker utførelsestiden for programmet. Men hvis du trenger denne konstruksjonen, bør du ikke sette inn de kodelinjene som ikke forventes å håndtere feil - dette vil gjøre koden lettere å forstå. Faktisk er det ikke så mye håndteringen av unntak som laster systemet, men snarere kasting av feil gjennom den nye unntakskonstruksjonen.
Å kaste unntak er tregere enn noen klasse som vil samle feilen i det nødvendige formatet. Hvis du behandler et skjema eller noen data og du tydelig vet hva feilen skal være, hvorfor ikke behandle den?
Du bør ikke skrive en throw new Exception()-konstruksjon hvis denne situasjonen ikke er eksepsjonell. Å håndtere og kaste et unntak er veldig dyrt!!!
ToLower, ToLowerInvariant, ToUpper, ToUpperInvariant
I løpet av mine 5 års erfaring med .NET-plattformen, har jeg kommet over mange prosjekter som brukte strengmatching. Jeg så også følgende bilde: det var én Enterprise-løsning med mange prosjekter, som hver utførte strengsammenligninger forskjellig. Men hva bør brukes og hvordan forene det? I boken CLR via C# av Richter leste jeg informasjon om at ToUpperInvariant()-metoden er raskere enn ToLowerInvariant().
Utdrag fra boken:

Jeg trodde selvfølgelig ikke på det og bestemte meg for å kjøre noen tester da på .NET Framework, og resultatet sjokkerte meg - mer enn 15 % ytelsesøkning. Så, da jeg kom på jobb neste morgen, viste jeg disse målingene til mine overordnede og ga dem tilgang til kildekoden. Etter dette ble 2 av 14 prosjekter endret for å imøtekomme de nye målingene, og tatt i betraktning at disse to prosjektene eksisterte for å behandle enorme Excel-tabeller, var resultatet mer enn betydelig for produktet.
Jeg presenterer også målinger for ulike versjoner av .NET Core, slik at hver enkelt av dere kan ta et valg mot den mest optimale løsningen. Og jeg vil bare legge til at i selskapet der jeg jobber, bruker vi ToUpper() for å sammenligne strenger.
Kode:
public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3";
[Benchmark]
public bool ToLower()
{
return defaultString.ToLower() == defaultString.ToLower();
}
[Benchmark]
public bool ToLowerInvariant()
{
return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant();
}
[Benchmark]
public bool ToUpper()
{
return defaultString.ToUpper() == defaultString.ToUpper();
}
[Benchmark]
public bool ToUpperInvariant()
{
return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant();
}
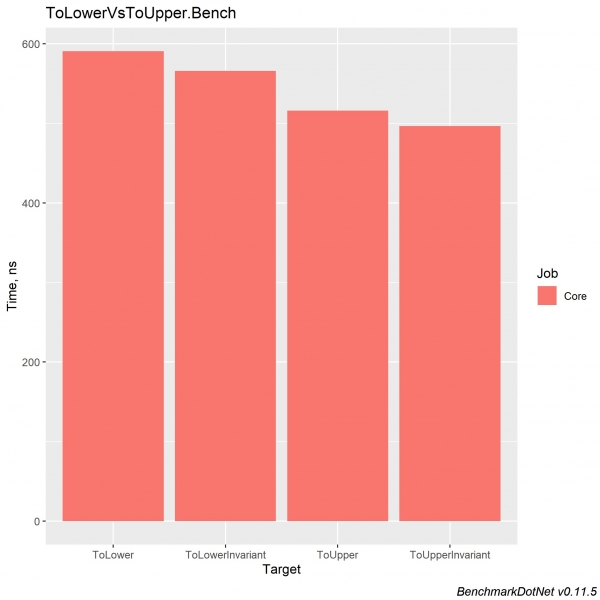
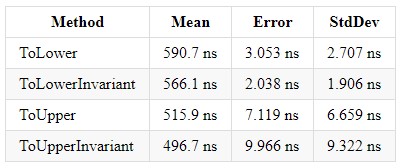
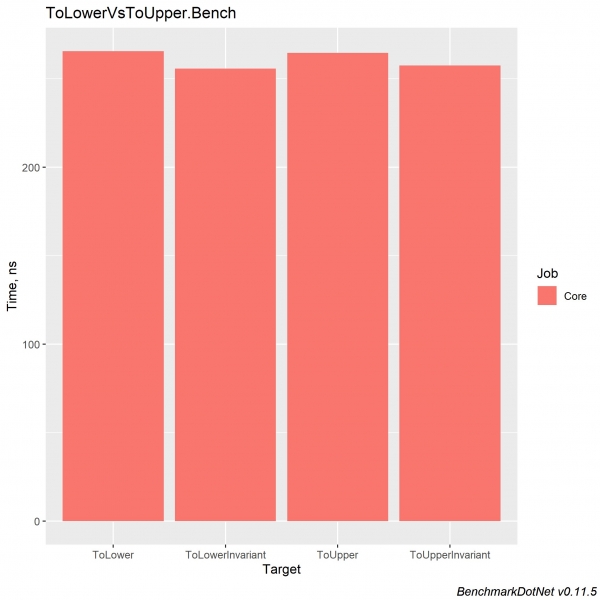
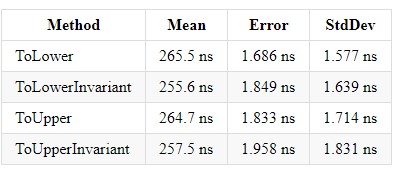
I .NET Core 3.0 er økningen for hver av disse metodene ~x2 og balanserer implementeringene seg imellom.
Nivåsamling
I min siste artikkel beskrev jeg denne funksjonaliteten kort, jeg vil gjerne korrigere og supplere mine ord. Multi-level kompilering gir raskere oppstartstid for løsningen din, men du ofrer at deler av koden din blir kompilert til en mer optimalisert versjon i bakgrunnen, noe som kan introdusere en liten overhead. Med bruken av NET Core 3.0 har byggetiden for prosjekter med tierkompilering aktivert redusert og feil knyttet til denne teknologien er fikset. Tidligere førte denne teknologien til feil i de første forespørslene i ASP.NET Core og fryser under den første byggingen i multi-level kompileringsmodus. Den er for øyeblikket aktivert som standard i .NET Core 3.0, men du kan deaktivere den hvis du ønsker det. Hvis du er i stillingen som teamleder, senior, mellomleder, eller du er leder for en avdeling, må du forstå at rask prosjektutvikling øker verdien av teamet og denne teknologien vil tillate deg å spare tid for begge utviklerne og tidspunktet for selve prosjektet.
.NET nivå opp
Oppgrader .NET Framework / .NET Core-versjonen. Ofte gir hver nye versjon ytterligere ytelsesgevinster og legger til nye funksjoner.
Men hva er egentlig fordelene? La oss se på noen av dem:
- .NET Core 3.0 introduserte R2R-bilder som vil redusere oppstartstiden for .NET Core-applikasjoner.
- Med versjon 2.2 dukket Tier Compilation opp, takket være hvilke programmerere vil bruke mindre tid på å starte et prosjekt.
- Støtte for nye .NET-standarder.
- Støtte for en ny versjon av programmeringsspråket.
- Optimalisering, med hver ny versjon forbedres optimeringen av basisbibliotekene Collection/Struct/Stream/String/Regex og mye mer. Hvis du migrerer fra .NET Framework til .NET Core, vil du få et stort ytelsesløft rett ut av esken. Som et eksempel legger jeg ved en lenke til noen av optimaliseringene som ble lagt til .NET Core 3.0:

Konklusjon
Når du skriver kode, er det verdt å ta hensyn til ulike aspekter av prosjektet ditt og bruke funksjonene til programmeringsspråket og plattformen for å oppnå det beste resultatet. Jeg ville bli glad om du deler din kunnskap knyttet til optimalisering i .NET.
Kilde: www.habr.com
