

— en svært kraftig og praktisk mekanisme hvis de samme handlingene utføres på relaterte data «i dybden». Men ukontrollert rekursjon er ondt, noe som kan føre til enten endeløs oppfyllelse prosess, eller (oftere) til "spiser opp" alt tilgjengelig minne.

DBMS-er fungerer i denne forbindelse etter de samme prinsippene - "De ba meg grave, så jeg graver". Forespørselen din kan ikke bare bremse ned nærliggende prosesser, som stadig opptar prosessorressurser, men også "drop" hele databasen, som "spiser" alt tilgjengelig minne. Derfor. uendelig rekursjonsbeskyttelse – utbyggerens eget ansvar.
I PostgreSQL er muligheten til å bruke rekursive spørringer via dukket opp i uminnelige tider versjon 8.4, men du kan fortsatt jevnlig støte på potensielt sårbare "forsvarsløse" spørsmål. Hvordan redde deg selv fra slike problemer?
Ikke skriv rekursive spørringer
Og skriv ikke-rekursive. Med vennlig hilsen, Hilsen K.O.
Faktisk tilbyr PostgreSQL ganske mye funksjonalitet som kan brukes til å no bruk rekursjon.
Bruk en fundamentalt annerledes tilnærming til problemet
Noen ganger kan man bare se på problemet «fra den andre siden». Jeg ga et eksempel på en slik situasjon i artikkelen. — multiplikasjon av et tallsett uten å bruke brukerdefinerte aggregatfunksjoner:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY -- отбор финального результата
i DESC
LIMIT 1;Denne spørringen kan erstattes med et alternativ fra matematikkeksperter:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Bruk generate_series i stedet for løkker
La oss si at vi står overfor oppgaven med å generere alle mulige prefikser for en streng 'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T; Er du sikker på at du trenger rekursjon her? ... Hvis du bruker LATERAL и generate_series, da vil ikke engang CTE-er være nødvendig:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Endre strukturen til databasen
For eksempel har du en tabell over forummeldinger med lenker til hvem som har svart hvem, eller en tråd i :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to); 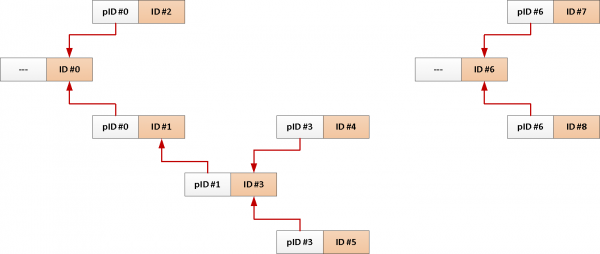
Vel, en typisk forespørsel om å laste ned alle meldinger om ett emne ser omtrent slik ut:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Men siden vi alltid trenger hele emnet fra roten av budskapet, hvorfor ikke legg til ID-en til hver oppføring automatisk?
-- добавим поле с общим идентификатором темы и индекс на него
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
-- инициализируем идентификатор темы в триггере при вставке
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id -- берем из стартового события
ELSE ( -- или из сообщения, на которое отвечаем
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins(); 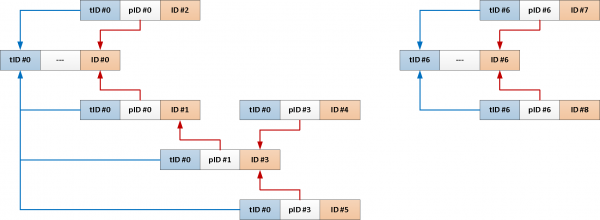
Nå kan hele den rekursive spørringen vår reduseres til bare dette:
SELECT
*
FROM
message
WHERE
theme_id = $1;Bruk anvendte "begrensere"
Hvis vi av en eller annen grunn ikke kan endre strukturen i databasen, la oss se hva vi kan stole på, slik at selv tilstedeværelsen av en feil i dataene ikke fører til uendelig utførelse av rekursjon.
Rekursjons-"dybde"-teller
Vi øker ganske enkelt telleren med én i hvert trinn av rekursjonen inntil vi når en grense som vi anser som åpenbart utilstrekkelig:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 -- предел
) Pro: Når vi prøver å loope, vil vi fortsatt ikke gjøre mer enn den spesifiserte grensen for iterasjoner "i dybden".
ulemper: Det er ingen garanti for at vi ikke vil behandle den samme posten om og om igjen – for eksempel på en dybde på 15 og 25, og deretter hver +10. Og ingen lovet noe om «i bredden».
Formelt sett vil en slik rekursjon ikke være uendelig, men hvis antallet poster øker eksponentielt i hvert trinn, vet vi alle hvordan dette ender ...
Vokter av "stien"
Vi legger til alle objektidentifikatorene vi møtte langs rekursjonsbanen én etter én til en array, som er en unik «bane» til den:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) -- не совпадает ни с одним из
) Pro: Hvis det er en syklus i dataene, vil vi definitivt ikke behandle den samme posten gjentatte ganger innenfor samme bane.
ulemper: Men samtidig kan vi gå gjennom bokstavelig talt alle postene uten å gjenta oss selv.
Begrensning av banelengde
For å unngå situasjonen med rekursjons"vandring" på ukjent dybde, kan vi kombinere de to foregående metodene. Eller, hvis vi ikke ønsker å støtte unødvendige felt, kan vi supplere betingelsen for rekursjonsfortsettelse med et estimat av banelengden:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
) Velg metoden etter din smak!
Kilde: www.habr.com
