

Vær oppmerksom på operasjoner som gir buffere...
Ved å bruke en liten spørring som eksempel, la oss se på noen universelle tilnærminger for å optimalisere spørringer i PostgreSQL. Om du bruker dem eller ikke er opp til deg, men det er verdt å vite om dem.
I noen påfølgende versjoner av PG kan situasjonen endre seg etter hvert som planleggeren blir smartere, men for 9.4/9.6 ser det omtrent likt ut, som i eksemplene her.
La oss ta en veldig reell forespørsel:
SELECT
TRUE
FROM
"Документ" d
INNER JOIN
"ДокументРасширение" doc_ex
USING("@Документ")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 or d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex."Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1; om tabell- og feltnavnDe "russiske" navnene på felt og tabeller kan behandles annerledes, men dette er en smakssak. Fordi det det er ingen utenlandske utviklere, og PostgreSQL lar oss gi navn selv i hieroglyfer, hvis de vedlagt anførselstegn, da foretrekker vi å navngi objekter entydig og tydelig slik at det ikke er noen avvik.
La oss se på den resulterende planen:
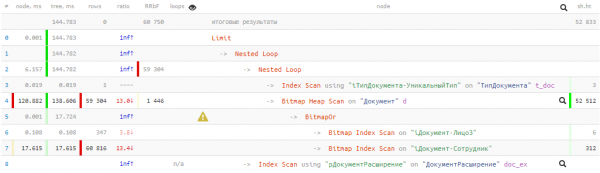
144ms og nesten 53K buffere - det vil si mer enn 400MB data! Og vi vil være heldige hvis alle er i hurtigbufferen ved forespørselen vår, ellers vil det ta mange ganger lengre tid når de leses fra disk.
Algoritmen er viktigst!
For på en eller annen måte å optimalisere en forespørsel, må du først forstå hva den skal gjøre.
La oss la utviklingen av selve databasestrukturen ligge utenfor rammen av denne artikkelen for nå, og er enige om at vi kan relativt "billig" skrive forespørselen om og/eller rulle inn på basen noen av tingene vi trenger Indekser.
Så forespørselen:
— kontrollerer at det finnes minst et dokument
- i den tilstanden vi trenger og av en viss type
- hvor forfatteren eller utøveren er den ansatte vi trenger
BLI MED + GRENSE 1
Ganske ofte er det lettere for en utvikler å skrive en spørring der et stort antall tabeller først blir slått sammen, og så gjenstår bare én post fra hele dette settet. Men enklere for utvikleren betyr ikke mer effektiv for databasen.
I vårt tilfelle var det bare 3 bord - og hva er effekten...
La oss først bli kvitt forbindelsen med "Document Type"-tabellen, og samtidig fortelle databasen at vår typerekord er unik (vi vet dette, men planleggeren har ingen anelse ennå):
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
LIMIT 1
)
...
WHERE
d."ТипДокумента" = (TABLE T)
...Ja, hvis tabellen/CTE består av et enkelt felt i en enkelt post, så kan du i PG til og med skrive slik, i stedet for
d."ТипДокумента" = (SELECT "@ТипДокумента" FROM T LIMIT 1)Lat evaluering i PostgreSQL-spørringer
BitmapOr vs UNION
I noen tilfeller vil Bitmap Heap Scan koste oss mye - for eksempel i vår situasjon, når ganske mange poster oppfyller den nødvendige betingelsen. Vi fikk det fordi OR-tilstand omgjort til BitmapOr- drift i plan.
La oss gå tilbake til det opprinnelige problemet - vi må finne en tilsvarende post hvem som helst fra betingelsene - det vil si at det ikke er nødvendig å søke etter alle 59K-poster under begge forholdene. Det er en måte å løse en tilstand på, og gå til den andre bare når ingenting ble funnet i den første. Følgende design vil hjelpe oss:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1"Ekstern" LIMIT 1 sikrer at søket avsluttes når den første posten er funnet. Og hvis den allerede finnes i den første blokken, vil den andre blokken ikke bli utført (aldri henrettet med respekt for).
«Skjuler vanskelige forhold under CASE»
Det er et ekstremt ubeleilig øyeblikk i den opprinnelige spørringen - å sjekke statusen mot den relaterte tabellen "DocumentExtension". Uavhengig av sannheten i andre forhold i uttrykket (f.eks. d. "Slettet" ER IKKE SANN), denne forbindelsen blir alltid utført og "koster ressurser". Mer eller mindre av dem vil bli brukt - avhenger av størrelsen på dette bordet.
Men du kan endre spørringen slik at søket etter en relatert post bare skjer når det virkelig er nødvendig:
SELECT
...
FROM
"Документ" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END En gang fra den koblede tabellen til oss ingen av feltene er nødvendige for resultatet, så har vi muligheten til å gjøre JOIN til en betingelse på en underspørring.
La oss la de indekserte feltene være "utenfor CASE-parentesene", legg til enkle betingelser fra posten til WHEN-blokken - og nå utføres den "tunge" spørringen bare når den går til THEN.
Mitt etternavn er "Totalt"
Vi samler inn den resulterende spørringen med alle mekanikkene beskrevet ovenfor:
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
)
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("Лицо3", "ТипДокумента") = (19091, (TABLE T)) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("ТипДокумента", "Сотрудник") = ((TABLE T), 19091) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
LIMIT 1;Justere [til] indekser
Et trent øye la merke til at de indekserte forholdene i UNION-underblokkene er litt forskjellige - dette er fordi vi allerede har passende indekser på bordet. Og hvis de ikke eksisterte, ville det være verdt å lage: Dokument(Person3, DocumentType) и Dokument(DocumentType, Employee).
om rekkefølgen på feltene i ROW-forholdFra planleggerens synspunkt kan du selvfølgelig skrive (A, B) = (constA, constB)Og (B, A) = (constB, constA). Men ved opptak i rekkefølgen til feltene i indeksen, er en slik forespørsel ganske enkelt mer praktisk å feilsøke senere.
Hva står i planen?
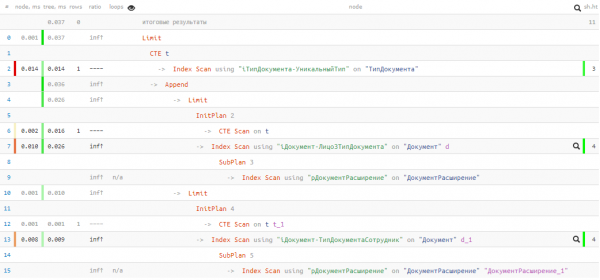
Dessverre var vi uheldige og ingenting ble funnet i den første UNION-blokken, så den andre ble fortsatt henrettet. Men likevel - bare 0.037 ms og 11 buffere!
Vi har fremskyndet forespørselen og redusert datapumping i minnet flere tusen ganger, ved hjelp av ganske enkle teknikker - et godt resultat med litt copy-paste. 🙂
Kilde: www.habr.com
