

Denne artikkelen er allerede den andre i emnet høyhastighets datakomprimering. Den første artikkelen beskrev en kompressor som opererer med en hastighet på 10 GB/sek. per prosessorkjerne (minimumskomprimering, RTT-Min).
Denne kompressoren har allerede blitt implementert i utstyret til rettsmedisinske duplikatorer for høyhastighetskomprimering av lagringsmediedumper og styrking av kryptografi; den kan også brukes til å komprimere bilder av virtuelle maskiner og RAM-byttefiler når de lagres på høyhastighets SSD-stasjoner.
Den første artikkelen kunngjorde også utviklingen av en komprimeringsalgoritme for å komprimere sikkerhetskopier av HDD- og SSD-diskstasjoner (middels komprimering, RTT-Mid) med betydelig forbedrede datakomprimeringsparametere. Nå er denne kompressoren helt klar, og denne artikkelen handler om det.
En kompressor som implementerer RTT-Mid-algoritmen gir et komprimeringsforhold som kan sammenlignes med standard arkivere som WinRar, 7-Zip, som opererer i høyhastighetsmodus. Samtidig er driftshastigheten minst en størrelsesorden høyere.
Hastigheten på datapakking/utpakking er en kritisk parameter som bestemmer anvendelsesområdet for komprimeringsteknologier. Det er usannsynlig at noen ville tenke på å komprimere en terabyte med data med en hastighet på 10-15 megabyte per sekund (dette er nøyaktig hastigheten til arkivere i standard komprimeringsmodus), fordi det ville ta nesten tjue timer med full prosessorbelastning. .
På den annen side kan samme terabyte kopieres med hastigheter i størrelsesorden 2-3Gigabyte per sekund på omtrent ti minutter.
Derfor er komprimering av store volum informasjon viktig hvis den utføres med en hastighet som ikke er lavere enn hastigheten til reell inngang/utgang. For moderne systemer er dette minst 100 megabyte per sekund.
Moderne kompressorer kan produsere slike hastigheter bare i "rask" modus. Det er i denne nåværende modusen vi skal sammenligne RTT-Mid-algoritmen med tradisjonelle kompressorer.
Sammenlignende testing av en ny kompresjonsalgoritme
RTT-Mid-kompressoren fungerte som en del av testprogrammet. I en ekte "fungerende" applikasjon fungerer den mye raskere, den bruker multithreading klokt og bruker en "normal" kompilator, ikke C#.
Siden kompressorene som brukes i den komparative testen er bygget på forskjellige prinsipper og ulike typer data komprimeres forskjellig, ble metoden for å måle "gjennomsnittstemperaturen på sykehuset" brukt for objektiviteten til testen...
En sektor-for-sektor-dumpfil av den logiske disken som inneholder operativsystemet ble opprettet. Windows 10Dette er den mest naturlige blandingen av ulike datastrukturer som finnes på alle datamaskiner. Komprimering av denne filen vil tillate oss å sammenligne hastigheten og kompresjonsforholdet til den nye algoritmen med de mest avanserte kompressorene som brukes i moderne arkiveringssystemer.
Her er dumpfilen:
Dumpfilen ble komprimert ved hjelp av PTT-Mid-, 7-zip- og WinRar-kompressorer. WinRar og 7-zip-kompressoren ble satt til maksimal hastighet.
Kompressor i gang 7-zip:
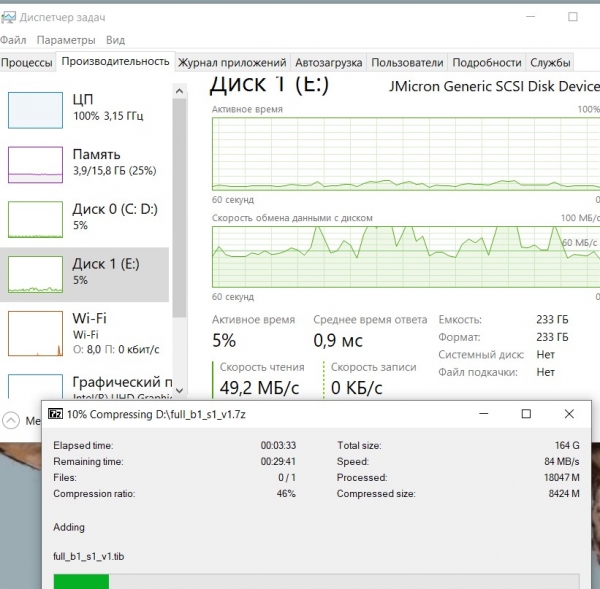
Den laster prosessoren med 100 %, mens gjennomsnittshastigheten for å lese den originale dumpen er omtrent 60 MegaByte/sek.
Kompressor i gang WinRAR:
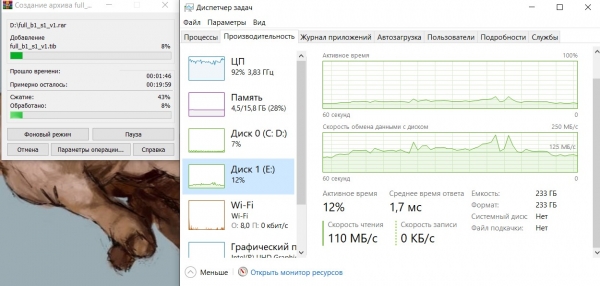
Situasjonen er lik, prosessorbelastningen er nesten 100%, gjennomsnittlig dump-lesehastighet er omtrent 125 megabyte/sek.
Som i det forrige tilfellet er hastigheten til arkiveringsenheten begrenset av prosessorens muligheter.
Kompressortestprogrammet kjører nå RTT-Mid:
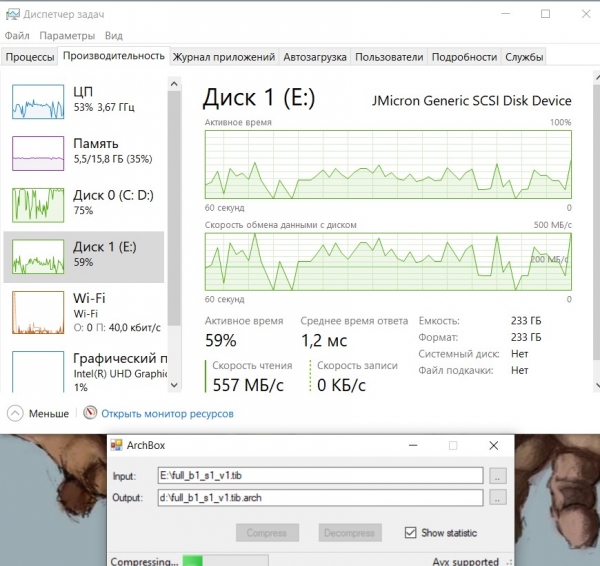
Skjermbildet viser at prosessoren er lastet med 50 % og er inaktiv resten av tiden, fordi det ikke er noe sted å laste opp de komprimerte dataene. Dataopplastingsdisken (Disk 0) er nesten fulllastet. Datalesehastigheten (Disk 1) varierer mye, men i gjennomsnitt mer enn 200 MegaByte/sek.
Hastigheten til kompressoren begrenses i dette tilfellet av muligheten til å skrive komprimerte data til Disk 0.
Nå er komprimeringsforholdet til de resulterende arkivene:



Det kan sees at RTT-Mid-kompressoren gjorde den beste jobben med komprimering; arkivet den opprettet var 1,3 GigaByte mindre enn WinRar-arkivet og 2,1 GigaByte mindre enn 7z-arkivet.
Tid brukt på å lage arkivet:
- 7-zip – 26 minutter 10 sekunder;
- WinRar – 17 minutter 40 sekunder;
- RTT-Mid – 7 minutter 30 sekunder.
Dermed var selv et test, ikke-optimalisert program, ved bruk av RTT-Mid-algoritmen, i stand til å lage et arkiv mer enn to og en halv ganger raskere, mens arkivet viste seg å være betydelig mindre enn konkurrentene ...
De som ikke tror på skjermbildene kan sjekke ektheten deres selv. Testprogrammet er tilgjengelig på , last ned og sjekk.
Men kun på prosessorer med AVX-2-støtte, uten støtte for disse instruksjonene fungerer ikke kompressoren, og test ikke algoritmen på eldre AMD-prosessorer, de er trege når det gjelder å utføre AVX-instruksjoner...
Kompresjonsmetode brukt
Algoritmen bruker en metode for å indeksere gjentatte tekstfragmenter i bytegranularitet. Denne komprimeringsmetoden har vært kjent i lang tid, men ble ikke brukt fordi matchingsoperasjonen var svært kostbar med tanke på nødvendige ressurser og krevde mye mer tid enn å bygge en ordbok. Så RTT-Mid-algoritmen er et klassisk eksempel på å flytte "tilbake til fremtiden" ...
PTT-kompressoren bruker en unik høyhastighets matchsøkeskanner, som lar oss fremskynde komprimeringsprosessen. En selvlaget skanner, dette er "min sjarm...", "den er ganske dyr, fordi den er helt håndlaget" (skrevet i assembler).
Matchsøkeskanneren er laget i henhold til et to-nivås sannsynlighetsskjema: først skannes tilstedeværelsen av et "tegn" på en kamp, og først etter at "tegnet" er identifisert på dette stedet, prosedyren for å oppdage en ekte match er startet.
Matchsøkevinduet har en uforutsigbar størrelse, avhengig av graden av entropi i den behandlede datablokken. For helt tilfeldige (ukomprimerbare) data har den en størrelse på megabyte, for data med repetisjoner er den alltid større enn en megabyte.
Men mange moderne dataformater er ukomprimerbare og å kjøre en ressurskrevende skanner gjennom dem er ubrukelig og bortkastet, så skanneren bruker to driftsmoduser. Først gjennomsøkes deler av kildeteksten med mulige repetisjoner; denne operasjonen utføres også ved hjelp av en sannsynlighetsmetode og utføres veldig raskt (med en hastighet på 4-6 GigaBytes/sek). Områdene med mulige treff blir deretter behandlet av hovedskanneren.
Indekskomprimering er lite effektivt, du må erstatte dupliserte fragmenter med indekser, og indeksmatrisen reduserer komprimeringsforholdet betydelig.
For å øke komprimeringsforholdet indekseres ikke bare komplette samsvar med bytestrenger, men også delvise, når strengen inneholder matchede og umatchede byte. For å gjøre dette inkluderer indeksformatet et samsvarsmaskefelt som indikerer samsvarende byte for to blokker. For enda større komprimering brukes indeksering til å legge flere delvis samsvarende blokker over den gjeldende blokken.
Alt dette gjorde det mulig å oppnå i PTT-Mid-kompressoren et kompresjonsforhold som kan sammenlignes med kompressorer laget ved hjelp av ordbokmetoden, men som fungerer mye raskere.
Hastigheten til den nye komprimeringsalgoritmen
Hvis kompressoren opererer med eksklusiv bruk av cache-minne (4 megabyte kreves per tråd), varierer driftshastigheten fra 700-2000 megabyte/sek. per prosessorkjerne, avhengig av typen data som komprimeres og avhenger lite av prosessorens driftsfrekvens.
Med en flertrådsimplementering av kompressoren bestemmes effektiv skalerbarhet av størrelsen på cachen på tredje nivå. For eksempel å ha 9 MegaByte cache-minne "ombord", er det ingen vits i å starte mer enn to komprimeringstråder; hastigheten vil ikke øke fra dette. Men med en cache på 20 megabyte kan du allerede kjøre fem komprimeringstråder.
Også latensen til RAM blir en viktig parameter som bestemmer hastigheten til kompressoren. Algoritmen bruker tilfeldig tilgang til OP-en, hvorav noen ikke kommer inn i hurtigbufferminnet (ca. 10%), og den må gå på tomgang og vente på data fra OP-en, noe som reduserer operasjonshastigheten.
I/O-systemet påvirker kompressorhastigheten betydelig. I/O-forespørsler til RAM-blokkens CPU ber om data, noe som også reduserer komprimeringshastigheten. Dette problemet er betydelig for bærbare og stasjonære datamaskiner. servere Det er mindre viktig på grunn av en mer avansert systembuss-tilgangskontrollenhet og flerkanals RAM.
Gjennom hele teksten i artikkelen snakker vi om komprimering; dekompresjon forblir utenfor rammen av denne artikkelen siden "alt er dekket av sjokolade". Dekompresjon er mye raskere og begrenses av I/O-hastighet. Én fysisk kjerne i én tråd gir enkelt utpakkingshastigheter på 3-4 GB/sek.
Dette skyldes fraværet av en matchsøkeoperasjon under dekompresjonsprosessen, som "spiser opp" hovedressursene til prosessoren og hurtigbufferminnet under komprimering.
Pålitelighet av komprimert datalagring
Som navnet på hele klassen av programvare som bruker datakomprimering (arkivere) antyder, er de designet for langtidslagring av informasjon, ikke i årevis, men i århundrer og årtusener...
Under lagring mister lagringsmedier noen data, her er et eksempel:

Denne "analoge" informasjonsbæreren er tusen år gammel, noen fragmenter har gått tapt, men generelt er informasjonen "lesbar"...
Ingen av de ansvarlige produsentene av moderne digitale datalagringssystemer og digitale medier for dem gir garantier for fullstendig datasikkerhet i mer enn 75 år.
Og dette er et problem, men et utsatt problem, våre etterkommere vil løse det...
Digitale datalagringssystemer kan miste data ikke bare etter 75 år, feil i data kan dukke opp når som helst, selv under opptak, prøver de å minimere disse forvrengningene ved å bruke redundans og korrigere dem med feilrettingssystemer. Redundans- og korreksjonssystemer kan ikke alltid gjenopprette tapt informasjon, og hvis de gjør det, er det ingen garanti for at gjenopprettingsoperasjonen ble korrekt utført.
Og dette er også et stort problem, men ikke et utsatt, men et nåværende.
Moderne kompressorer som brukes til å arkivere digitale data er bygget på forskjellige modifikasjoner av ordbokmetoden, og for slike arkiver vil tap av en informasjon være en fatal hendelse; det er til og med en etablert betegnelse for en slik situasjon - et "ødelagt" arkiv ...
Den lave påliteligheten til å lagre informasjon i arkiver med ordbokkomprimering er assosiert med strukturen til de komprimerte dataene. Informasjonen i et slikt arkiv inneholder ikke kildeteksten, antall oppføringer i ordboken er lagret der, og selve ordboken modifiseres dynamisk av den aktuelle komprimerte teksten. Hvis et arkivfragment går tapt eller blir ødelagt, kan ikke alle påfølgende arkivoppføringer identifiseres verken etter innholdet eller lengden på oppføringen i ordboken, siden det ikke er klart hva ordbokoppføringsnummeret tilsvarer.
Det er umulig å gjenopprette informasjon fra et slikt "ødelagt" arkiv.
RTT-algoritmen er basert på en mer pålitelig metode for lagring av komprimerte data. Den bruker indeksmetoden for å gjøre rede for gjentatte fragmenter. Denne tilnærmingen til komprimering lar deg minimere konsekvensene av forvrengning av informasjon på lagringsmediet, og i mange tilfeller automatisk korrigere forvrengninger som oppsto under informasjonslagring.
Dette skyldes det faktum at arkivfilen i tilfelle indekskomprimering inneholder to felt:
- et kildetekstfelt med gjentatte seksjoner fjernet fra det;
- indeksfelt.
Indeksfeltet, som er kritisk for informasjonsgjenoppretting, er ikke stort i størrelse og kan dupliseres for pålitelig datalagring. Derfor, selv om et fragment av kildeteksten eller indeksmatrisen går tapt, vil all annen informasjon bli gjenopprettet uten problemer, som på bildet med et "analogt" lagringsmedium.
Ulemper med algoritmen
Det er ingen fordeler uten ulemper. Indekskomprimeringsmetoden komprimerer ikke korte repeterende sekvenser. Dette skyldes begrensningene i indeksmetoden. Indekser er minst 3 byte store og kan være opptil 12 byte store. Hvis det oppstår en repetisjon med en mindre størrelse enn indeksen som beskriver den, blir det ikke tatt hensyn til det, uansett hvor ofte slike repetisjoner oppdages i den komprimerte filen.
Den tradisjonelle ordbokkomprimeringsmetoden komprimerer effektivt flere repetisjoner av kort lengde og oppnår derfor et høyere kompresjonsforhold enn indekskomprimering. Riktignok oppnås dette på grunn av den høye belastningen på sentralprosessoren; for at ordbokmetoden skal begynne å komprimere data mer effektivt enn indeksmetoden, må den redusere databehandlingshastigheten til 10-20 megabyte per sekund på ekte datainstallasjoner med full CPU-belastning.
Slike lave hastigheter er uakseptable for moderne datalagringssystemer og er av mer "akademisk" interesse enn praktisk.
Graden av informasjonskomprimering vil økes betydelig i neste modifikasjon av RTT-algoritmen (RTT-Max), som allerede er under utvikling.
Så, som alltid, fortsetter...
Kilde: www.habr.com
