


For å mestre Kubernetes fullt ut, må du kjenne til forskjellige måter å skalere klyngressursene på: etter , dette er en av hovedoppgavene til Kubernetes. Vi har gitt en oversikt på høyt nivå over horisontal og vertikal autoskalering og klyngestørrelsesmekanismer, samt anbefalinger om hvordan du kan bruke dem effektivt.
Artikkel oversatt av teamet som implementerte automatisk skalering .
Hvorfor det er viktig å tenke på skalering
- et verktøy for ressursstyring og orkestrering. Selvfølgelig er det fint å tukle med de kule funksjonene ved å distribuere, overvåke og administrere pods (en pod er en gruppe containere som lanseres som svar på en forespørsel).
Du bør imidlertid også tenke på følgende spørsmål:
- Hvordan skalere moduler og applikasjoner?
- Hvordan holde containere operative og effektive?
- Hvordan reagere på konstante endringer i kode og arbeidsbelastninger fra brukere?
Å konfigurere Kubernetes-klynger for å balansere ressurser og ytelse kan være utfordrende og krever ekspertkunnskap om Kubernetes indre funksjoner. Arbeidsmengden til applikasjonen eller tjenestene dine kan variere i løpet av dagen eller til og med i løpet av en time, så balansering er best tenkt som en pågående prosess.
Kubernetes autoskaleringsnivåer
Effektiv autoskalering krever koordinering mellom to nivåer:
- Pod-nivå, inkludert horisontal (Horizontal Pod Autoscaler, HPA) og vertikal autoscaler (Vertical Pod Autoscaler, VPA). Dette skalerer de tilgjengelige ressursene for containerne dine.
- Klyngenivå, som administreres av Cluster Autoscaler (CA), som øker eller reduserer antall noder i klyngen.
Horisontal Autoscaler (HPA) modul
Som navnet antyder, skalerer HPA antallet pod-replikaer. De fleste devops bruker CPU og minnebelastning som triggere for å endre antall replikaer. Det er imidlertid mulig å skalere systemet basert på deres eller .
Driftsdiagram over HPA på høyt nivå:
- HPA sjekker kontinuerlig de metriske verdiene spesifisert under installasjonen med et standardintervall på 30 sekunder.
- HPA forsøker å øke antall moduler hvis den angitte terskelen nås.
- HPA oppdaterer antall replikaer i distribusjons-/replikeringskontrolleren.
- Distribusjons-/replikeringskontrolleren distribuerer deretter eventuelle nødvendige tilleggsmoduler.
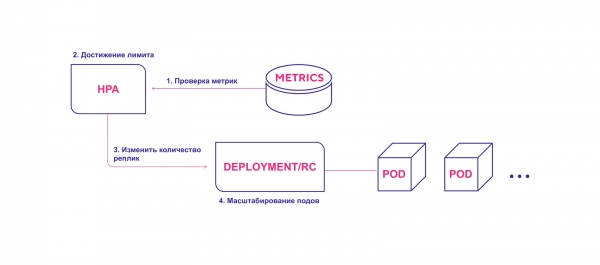
HPA starter moduldistribusjonsprosessen når en metrisk terskel er nådd
Når du bruker HPA, bør du vurdere følgende:
- Standard HPA-sjekkintervall er 30 sekunder. Den er satt av flagget horisontal-pod-autoscaler-sync-periode i kontrolleren.
- Standard relativ feil er 10 %.
- Etter den siste økningen i antall moduler forventer HPA at beregningene vil stabilisere seg innen tre minutter. Dette intervallet er satt av flagget horisontal-pod-autoscaler-upscale-delay.
- Etter siste reduksjon i antall moduler venter HPA i fem minutter på å stabilisere seg. Dette intervallet er satt av flagget horisontal-pod-autoscaler-downscale-delay.
- HPA fungerer best med distribusjonsobjekter i stedet for replikeringskontrollere. Horisontal autoskalering er inkompatibel med rullende oppdatering, som direkte manipulerer replikeringskontrollere. Med distribusjon avhenger antallet replikaer direkte av distribusjonsobjektene.
Vertikal autoskalering av pods
Vertikal autoskalering (VPA) tildeler mer (eller mindre) CPU-tid eller minne til eksisterende pods. Egnet for stateful eller stateless pods, men hovedsakelig beregnet for stateful tjenester. Du kan imidlertid også bruke VPA for statsløse moduler hvis du trenger å automatisk justere mengden av opprinnelig tildelte ressurser.
VPA reagerer også på OOM-hendelser (tom minne). Endring av CPU-tid og minne krever omstart av podene. Ved omstart respekterer VPA tildelingsbudsjettet () for å garantere det minste nødvendige antallet moduler.
Du kan angi minimums- og maksimumsressurser for hver modul. Dermed kan du begrense den maksimale mengden tildelt minne til 8 GB. Dette er nyttig hvis de nåværende nodene definitivt ikke kan tildele mer enn 8 GB minne per beholder. Detaljerte spesifikasjoner og betjeningsmekanisme er beskrevet i .
I tillegg har VPA en interessant anbefalingsfunksjon (VPA Recommender). Den overvåker ressursbruk og OOM-hendelser for alle moduler for å foreslå nye minne- og CPU-tidsverdier basert på en intelligent algoritme basert på historiske beregninger. Det er også et API som tar et pod-håndtak og returnerer foreslåtte ressursverdier.
Det er verdt å merke seg at VPA Recommender ikke sporer ressurs "grense". Dette kan føre til at modulen monopoliserer ressurser i noder. Det er bedre å sette grensen på navneområdenivået for å unngå stort minne- eller CPU-forbruk.
VPA-driftsopplegg på høyt nivå:
- VPA sjekker kontinuerlig de metriske verdiene spesifisert under installasjonen med et standardintervall på 10 sekunder.
- Hvis den angitte terskelen nås, forsøker VPA å endre den tildelte ressursmengden.
- VPA oppdaterer antall ressurser i distribusjons-/replikeringskontrolleren.
- Når moduler startes på nytt, blir alle nye ressurser brukt på de opprettede forekomstene.
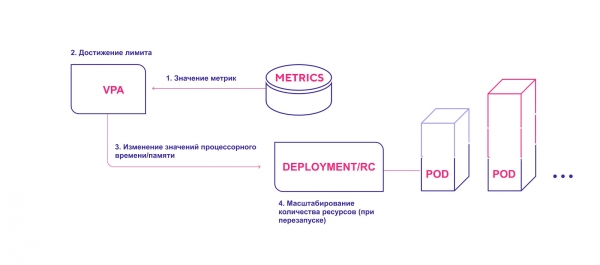
VPA legger til den nødvendige mengden ressurser
Vær oppmerksom på følgende punkter når du bruker VPA:
- Skalering krever en obligatorisk omstart av poden. Dette er nødvendig for å unngå ustabil drift etter endringer. For pålitelighet startes moduler på nytt og distribueres på tvers av noder basert på nylig tildelte ressurser.
- VPA og HPA er ennå ikke kompatible med hverandre og kan ikke kjøre på de samme podene. Hvis du bruker begge skaleringsmekanismene i samme klynge, sørg for at innstillingene dine forhindrer at de aktiveres på de samme objektene.
- VPA justerer containerforespørsler for ressurser bare basert på tidligere og nåværende bruk. Den setter ikke grenser for ressursbruk. Det kan være problemer med at applikasjoner ikke fungerer som de skal og begynner å ta over flere og flere ressurser, dette vil føre til at Kubernetes slår av denne poden.
- VPA er fortsatt på et tidlig stadium av utviklingen. Vær forberedt på at systemet kan gjennomgå noen endringer i nær fremtid. Du kan lese om и . Dermed er det planer om å implementere felles drift av VPA og HPA, samt distribusjon av moduler sammen med en vertikal autoskaleringspolicy for dem (for eksempel en spesiell etikett "krever VPA").
Automatisk skalering av en Kubernetes-klynge
Cluster Autoscaler (CA) endrer antall noder basert på antall ventende pods. Systemet sjekker med jevne mellomrom for ventende moduler - og øker klyngestørrelsen hvis det trengs flere ressurser og hvis klyngen ikke overskrider de fastsatte grensene. CA kommuniserer med skytjenesteleverandøren, ber om ytterligere noder fra den eller frigir inaktive. Den første allment tilgjengelige versjonen av CA ble introdusert i Kubernetes 1.8.
Opplegg på høyt nivå for SA-drift:
- CA sjekker for ventende moduler med et standardintervall på 10 sekunder.
- Hvis én eller flere pods er i standby-tilstand fordi klyngen ikke har nok tilgjengelige ressurser til å tildele dem, prøver den å klargjøre én eller flere ekstra noder.
- Når skytjenesteleverandøren tildeler den nødvendige noden, blir den med i klyngen og er klar til å betjene podene.
- Kubernetes-planleggeren distribuerer ventende pods til den nye noden. Hvis noen moduler etter dette fortsatt forblir i ventetilstand, gjentas prosessen og nye noder legges til klyngen.
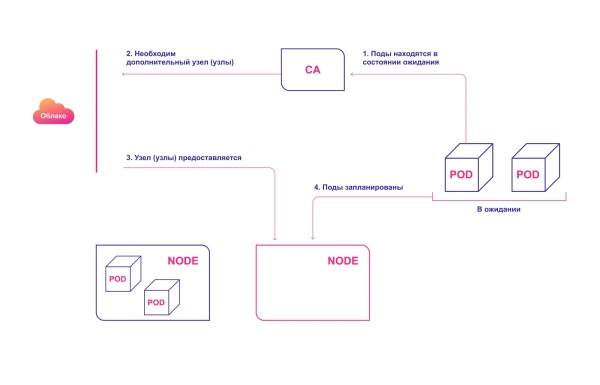
Automatisk klargjøring av klyngenoder i skyen
Tenk på følgende når du bruker CA:
- CA sikrer at alle pods i klyngen har plass til å kjøre, uavhengig av CPU-belastning. Den prøver også å sikre at det ikke er unødvendige noder i klyngen.
- CA registrerer behovet for skalering etter ca. 30 sekunder.
- Når en node ikke lenger er nødvendig, vil CA som standard vente 10 minutter før systemet skaleres ut.
- Autoskaleringssystemet har konseptet utvidere. Dette er ulike strategier for å velge en gruppe noder som nye noder skal legges til.
- Bruk alternativet ansvarlig cluster-autoscaler.kubernetes.io/safe-to-evict (true). Hvis du installerer mange pods, eller hvis mange av dem er spredt over alle nodene, vil du i stor grad miste muligheten til å skalere ut klyngen.
- bruk for å forhindre at pods blir slettet, noe som kan føre til at deler av programmet mislykkes fullstendig.
Hvordan Kubernetes autoskalere samhandler med hverandre
For perfekt harmoni bør autoskalering brukes på både pod-nivå (HPA/VPA) og klyngenivå. De samhandler med hverandre relativt enkelt:
- HPA-er eller VPA-er oppdaterer pod-replikaer eller ressurser som er tildelt eksisterende poder.
- Hvis det ikke er nok noder for den planlagte skaleringen, merker CA tilstedeværelsen av pods i ventetilstand.
- CA tildeler nye noder.
- Moduler distribueres til nye noder.
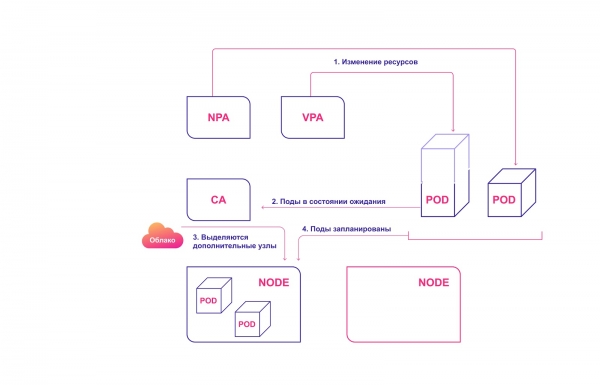
Samarbeidende Kubernetes-utskaleringssystem
Vanlige feil i Kubernetes autoskalering
Det er flere vanlige problemer som oppstår når du prøver å implementere autoskalering.
HPA og VPA avhenger av beregninger og noen historiske data. Hvis det ikke tildeles tilstrekkelige ressurser, vil modulene bli minimert og vil ikke kunne generere beregninger. I dette tilfellet vil autoskalering aldri skje.
Selve skaleringsoperasjonen er tidssensitiv. Vi ønsker at modulene og klyngen skal skaleres raskt – før brukere oppdager problemer eller feil. Derfor bør den gjennomsnittlige skaleringstiden for pods og klyngen tas i betraktning.
Ideell scenario - 4 minutter:
- 30 sekunder. Oppdater målberegninger: 30–60 sekunder.
- 30 sekunder. HPA sjekker metriske verdier: 30 sekunder.
- Mindre enn 2 sekunder. Pods opprettes og går i ventetilstand: 1 sekund.
- Mindre enn 2 sekunder. CA ser ventemoduler og sender anrop til klargjøringsnoder: 1 sekund.
- 3 minutter. Skyleverandøren tildeler noder. K8s venter til de er klare: opptil 10 minutter (avhengig av flere faktorer).
Worst case (mer realistisk) scenario - 12 minutter:
- 30 sekunder. Oppdater målberegninger.
- 30 sekunder. HPA sjekker de metriske verdiene.
- Mindre enn 2 sekunder. Podene opprettes og går inn i standby-tilstand.
- Mindre enn 2 sekunder. CA ser ventemodulene og ringer for å klargjøre nodene.
- 10 minutter. Skyleverandøren tildeler noder. K8s venter til de er klare. Ventetiden avhenger av flere faktorer, for eksempel leverandørforsinkelse, OS-forsinkelse og støtteverktøy.
Ikke forveksle skyleverandørers skaleringsmekanismer med vår CA. Sistnevnte kjører inne i en Kubernetes-klynge, mens skyleverandørmotoren opererer på nodedistribusjonsbasis. Den vet ikke hva som skjer med podene eller applikasjonen din. Disse systemene fungerer parallelt.
Hvordan administrere skalering i Kubernetes
- Kubernetes er et ressursstyrings- og orkestreringsverktøy. Operasjoner for å administrere pods og klyngeressurser er en viktig milepæl for å mestre Kubernetes.
- Forstå logikken i pod-skalerbarhet med hensyn til HPA og VPA.
- CA bør bare brukes hvis du har en god forståelse av behovene til pods og beholdere.
- For å konfigurere en klynge optimalt, må du forstå hvordan ulike skaleringssystemer fungerer sammen.
- Når du estimerer skaleringstid, må du huske på de verste og beste tilfellene.
Kilde: www.habr.com
