


Dzisiaj przeanalizujemy metryki podsystemu dyskowego w vSphere. Problem z pamięcią masową jest najczęstszą przyczyną powolnej maszyny wirtualnej. Jeśli w przypadku procesora i pamięci RAM rozwiązywanie problemów kończy się na poziomie hypervisora, to w przypadku problemów z dyskiem konieczne może być zajęcie się siecią danych i systemem przechowywania danych.
Temat omówię na przykładzie blokowania dostępu do systemów pamięci masowej, choć w przypadku dostępu do plików liczniki są w przybliżeniu takie same.
Trochę teorii
Mówiąc o wydajności podsystemu dyskowego maszyn wirtualnych, ludzie zwykle zwracają uwagę na trzy powiązane ze sobą parametry:
- liczba operacji wejścia/wyjścia (operacje wejścia/wyjścia na sekundę, IOPS);
- wydajność;
- opóźnienie operacji wejścia/wyjścia (Latency).
Liczba IOPS zwykle ważne w przypadku losowych obciążeń: dostęp do bloków dyskowych znajdujących się w różnych miejscach. Przykładem takiego obciążenia mogą być bazy danych, aplikacje biznesowe (ERP, CRM) itp.
Przepustowość ważne przy obciążeniach sekwencyjnych: dostęp do bloków umieszczonych jeden po drugim. Na przykład serwery plików (ale nie zawsze) i systemy nadzoru wideo mogą generować takie obciążenie.
Przepustowość jest powiązana z liczbą operacji we/wy w następujący sposób:
Przepustowość = IOPS * Rozmiar bloku, gdzie Rozmiar bloku to rozmiar bloku.
Rozmiar bloku jest dość ważną cechą. Nowoczesne wersje ESXi pozwalają na bloki o rozmiarze do 32 767 KB. Jeśli blok jest jeszcze większy, dzieli się go na kilka. Nie wszystkie systemy pamięci masowej mogą wydajnie współpracować z tak dużymi blokami, dlatego w ustawieniach zaawansowanych ESXi znajduje się parametr DiskMaxIOSize. Za jego pomocą możesz zmniejszyć maksymalny rozmiar bloku pomijany przez hypervisor (więcej szczegółów ). Przed zmianą tego parametru radzę skonsultować się z producentem systemu przechowywania lub przynajmniej przetestować zmiany na stole laboratoryjnym.
Duży rozmiar bloku może mieć szkodliwy wpływ na wydajność pamięci. Nawet jeśli liczba IOPS i przepustowość są stosunkowo małe, przy dużym rozmiarze bloku można zaobserwować duże opóźnienia. Dlatego zwróć uwagę na ten parametr.
Utajenie – najciekawszy parametr wydajnościowy. Opóźnienie we/wy maszyny wirtualnej składa się z:
- opóźnienia wewnątrz hypervisora (KAVG, Average Kernel MilliSec/Read);
- opóźnienie zapewniane przez sieć danych i system przechowywania danych (DAVG, Average Driver MilliSec/Command).
Całkowite opóźnienie widoczne w systemie gościa (GAVG, Average Guest MilliSec/Command) jest sumą KAVG i DAVG.
Mierzone są GAVG i DAVG oraz obliczane KAVG: GAVG–DAVG.
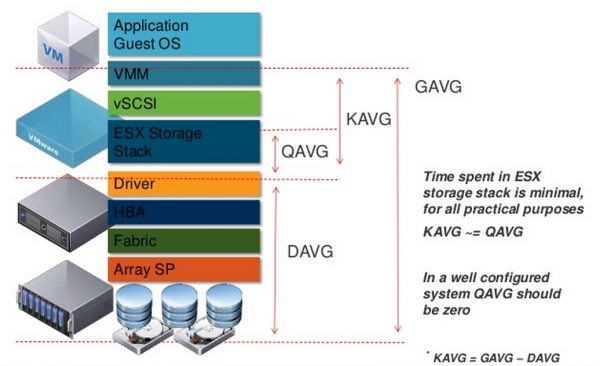
Przyjrzyjmy się bliżej KAVG. Podczas normalnej pracy KAVG powinien dążyć do zera lub przynajmniej być znacznie mniejszy niż DAVG. Jedynym znanym mi przypadkiem, w którym KAVG jest oczekiwanie wysoki, jest limit IOPS na dysku maszyny wirtualnej. W takim przypadku przy próbie przekroczenia limitu wartość KAVG wzrośnie.
Najważniejszym elementem KAVG jest QAVG – czas kolejki przetwarzania wewnątrz hiperwizora. Pozostałe składniki KAVG są znikome.
Kolejka w sterowniku adaptera dysku oraz kolejka do księżyców ma stały rozmiar. W przypadku mocno obciążonych środowisk przydatne może być zwiększenie tego rozmiaru. opisuje jak zwiększyć kolejki w sterowniku adaptera (jednocześnie zwiększy się kolejka do księżyców). To ustawienie działa, gdy tylko jedna maszyna wirtualna współpracuje z Księżycem, co jest rzadkością. Jeśli na Księżycu znajduje się kilka maszyn wirtualnych, należy również zwiększyć ten parametr Disk.SchedNumReqOutstanding (instrukcje ). Zwiększając kolejkę, zmniejszasz odpowiednio QAVG i KAVG.
Ale najpierw przeczytaj dokumentację od dostawcy karty HBA i przetestuj zmiany na stole laboratoryjnym.
Na wielkość kolejki na Księżyc może mieć wpływ włączenie mechanizmu SIOC (Storage I/O Control). Zapewnia jednolity dostęp do księżyca ze wszystkich serwerów w klastrze poprzez dynamiczną zmianę kolejki do księżyca na serwerach. Oznacza to, że jeśli na jednym z hostów działa maszyna wirtualna, która wymaga nieproporcjonalnie dużej wydajności (zaszumiona sąsiadująca maszyna wirtualna), SIOC zmniejsza długość kolejki na tym hoście (DQLEN). Więcej szczegółów .
Uporządkowaliśmy KAVG, teraz trochę o DAVG. Tutaj wszystko jest proste: DAVG to opóźnienie wprowadzane przez środowisko zewnętrzne (sieć danych i system przechowywania). Każdy nowoczesny i mniej nowoczesny system przechowywania ma własne liczniki wydajności. Aby przeanalizować problemy z DAVG, warto się im przyjrzeć. Jeśli po stronie ESXi i pamięci masowej wszystko jest w porządku, sprawdź sieć danych.
Aby uniknąć problemów z wydajnością, wybierz właściwą politykę wyboru ścieżki (PSP) dla swojego systemu pamięci masowej. Prawie wszystkie nowoczesne systemy pamięci masowej obsługują PSP Round-Robin (z lub bez ALUA, asymetrycznego dostępu do jednostki logicznej). Polityka ta umożliwia wykorzystanie wszystkich dostępnych ścieżek do systemu pamięci masowej. W przypadku ALUA używane są tylko ścieżki do kontrolera będącego właścicielem księżyca. Nie wszystkie systemy pamięci masowej w ESXi mają domyślne reguły określające zasadę działania okrężnego. Jeśli nie ma reguły dla Twojego systemu pamięci masowej, użyj wtyczki od producenta systemu pamięci masowej, która utworzy odpowiednią regułę na wszystkich hostach w klastrze, lub utwórz regułę samodzielnie. Detale .
Ponadto niektórzy producenci systemów pamięci masowej zalecają zmianę liczby IOPS na ścieżkę ze standardowej wartości 1000 na 1. W naszej praktyce umożliwiło to „wyciśnięcie” większej wydajności z systemu pamięci masowej i znaczne skrócenie czasu wymaganego na przełączenie awaryjne w przypadku awarii lub aktualizacji sterownika. Sprawdź zalecenia sprzedawcy, a jeśli nie ma przeciwwskazań, spróbuj zmienić ten parametr. Detale .
Podstawowe liczniki wydajności podsystemu dysku maszyny wirtualnej
Liczniki wydajności podsystemu dyskowego w vCenter gromadzone są w sekcjach Datastore, Dysk, Dysk wirtualny:
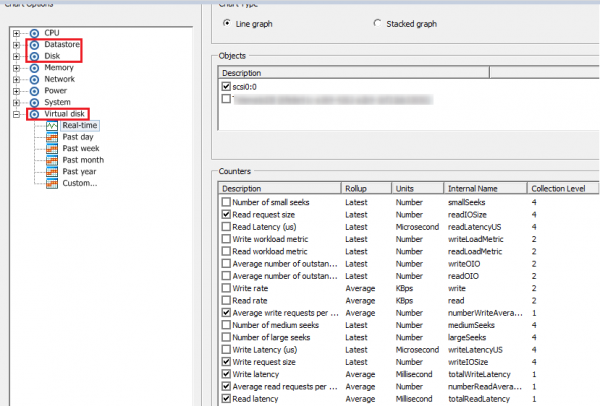
W sekcji Magazyn danych istnieją metryki dotyczące magazynów dyskowych vSphere (magazynów danych), na których znajdują się dyski maszyn wirtualnych. Tutaj znajdziesz standardowe liczniki dla:
- IOPS (średnie żądania odczytu/zapisu na sekundę),
- przepustowość (szybkość odczytu/zapisu),
- opóźnienia (odczyt/zapis/najwyższe opóźnienie).
W zasadzie wszystko jest jasne z nazw liczników. Jeszcze raz zwrócę uwagę na fakt, że statystyki tutaj nie dotyczą konkretnej maszyny wirtualnej (lub dysku VM), ale statystyki ogólne dla całego datastore. Moim zdaniem wygodniej jest patrzeć na te statystyki w ESXTOP, choćby biorąc pod uwagę fakt, że minimalny okres pomiaru wynosi tam 2 sekundy.
W sekcji Dysk istnieją metryki na urządzeniach blokowych używanych przez maszynę wirtualną. Istnieją liczniki IOPS typu sumującego (liczba operacji wejścia/wyjścia w okresie pomiarowym) oraz kilka liczników związanych z dostępem do bloków (Przerwane polecenia, Resety magistrali). Moim zdaniem wygodniej jest też przeglądać te informacje w ESXTOP.
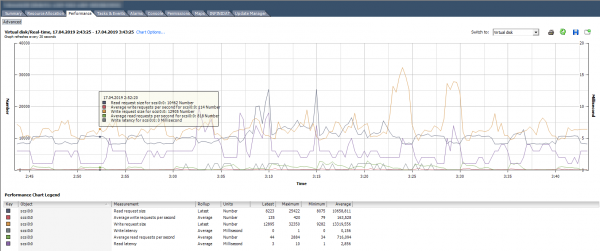
Rubryka Dysk wirtualny – najbardziej przydatny z punktu widzenia wyszukiwania problemów wydajnościowych podsystemu dyskowego maszyny wirtualnej. Tutaj możesz zobaczyć wydajność każdego dysku wirtualnego. To właśnie te informacje są potrzebne, aby zrozumieć, czy konkretna maszyna wirtualna ma problem. Oprócz standardowych liczników liczby operacji we/wy, wielkości odczytu/zapisu i opóźnień, w tej sekcji znajdują się przydatne liczniki pokazujące rozmiar bloku: Rozmiar żądania odczytu/zapisu.
Na poniższym obrazku znajduje się wykres wydajności dysku VM, na którym widać liczbę IOPS, opóźnienia i rozmiar bloku.
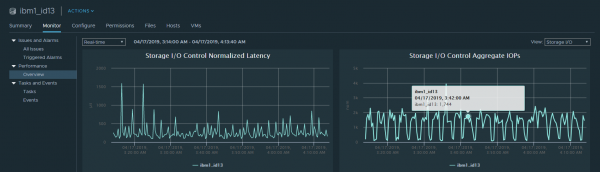
Możesz także wyświetlić metryki wydajności dla całego magazynu danych, jeśli włączono SIOC. Oto podstawowe informacje na temat średniego opóźnienia i IOPS. Domyślnie informacje te można przeglądać tylko w czasie rzeczywistym.
ESXTOP
ESXTOP posiada kilka ekranów, które dostarczają informacji o podsystemie dysku hosta jako całości, poszczególnych maszynach wirtualnych i ich dyskach.
Zacznijmy od informacji o maszynach wirtualnych. Ekran „Disk VM” wywołuje się klawiszem „v”:
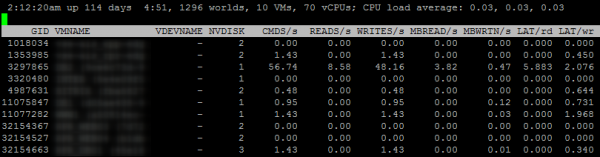
NVDISK to liczba dysków maszyn wirtualnych. Aby wyświetlić informacje o każdym dysku, naciśnij „e” i wprowadź GID interesującej maszyny wirtualnej.
Znaczenie pozostałych parametrów na tym ekranie wynika z ich nazw.
Kolejnym przydatnym ekranem podczas rozwiązywania problemów jest Adapter dysku. Wywoływane klawiszem „d” (pola A,B,C,D,E,G zostały zaznaczone na poniższym obrazku):

NPTH – liczba ścieżek do księżyców widocznych z tego adaptera. Aby uzyskać informacje o każdej ścieżce adaptera, naciśnij „e” i wprowadź nazwę adaptera:
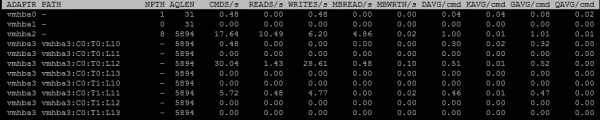
AQLEN – maksymalny rozmiar kolejki na adapterze.
Na tym ekranie znajdują się również liczniki opóźnień, o których mówiłem powyżej: KAVG/cmd, GAVG/cmd, DAVG/cmd, QAVG/cmd.
Ekran Urządzenia dyskowe, który wywołujemy po naciśnięciu klawisza „u”, dostarcza informacji o poszczególnych urządzeniach blokowych – księżycach (pola A, B, F, G, I zaznaczono na poniższym obrazku). Tutaj możesz zobaczyć stan kolejki po księżyce.

DQLEN – wielkość kolejki dla urządzenia blokowego.
ACTV – liczba poleceń I/O w jądrze ESXi.
QUED – liczba poleceń I/O w kolejce.
% USD – ACTV/DQLEN × 100%.
ZAŁADOWAĆ – (ACTV + QUED) / DQLEN.
Jeśli %USD jest wysoki, powinieneś rozważyć zwiększenie kolejki. Im więcej poleceń w kolejce, tym wyższa wartość QAVG i odpowiednio KAVG.
Na ekranie urządzenia dyskowego można także sprawdzić, czy w systemie pamięci masowej działa VAAI (vStorage API for Array Integration). W tym celu zaznacz pola A i O.
Mechanizm VAAI umożliwia przeniesienie części pracy z hypervisora bezpośrednio do systemu pamięci masowej, np. zerowanie, kopiowanie bloków czy blokowanie.
![]()
Jak widać na powyższym obrazku, VAAI działa na tym systemie przechowywania: aktywnie wykorzystywane są prymitywy Zero i ATS.
Wskazówki dotyczące optymalizacji pracy z podsystemem dyskowym na ESXi
- Zwróć uwagę na rozmiar bloku.
- Ustaw optymalny rozmiar kolejki na karcie HBA.
- Nie zapomnij włączyć SIOC w magazynach danych.
- Wybierz PSP zgodnie z zaleceniami producenta systemu pamięci masowej.
- Upewnij się, że VAAI działa.
Przydatne artykuły na ten temat:
Źródło: www.habr.com
