

Cześć, nazywam się Dmitry Logvinenko — inżynier danych w dziale analityki grupy firm Vezet.
Opowiem Ci o wspaniałym narzędziu do rozwijania procesów ETL - Apache Airflow. Ale Airflow jest na tyle wszechstronny i wielopłaszczyznowy, że warto przyjrzeć mu się bliżej, nawet jeśli nie zajmujesz się przepływami danych, ale masz potrzebę okresowego uruchamiania dowolnych procesów i monitorowania ich wykonania.
I tak, nie tylko powiem, ale także pokażę: program ma dużo kodu, zrzutów ekranu i rekomendacji.
Co zwykle widzisz, gdy wpiszesz w Google słowo Airflow / Wikimedia Commons
Spis treści
Wprowadzenie
Apache Airflow jest podobny do Django:
- napisany w Pythonie
- jest świetny panel administracyjny,
- możliwość rozbudowy w nieskończoność
- tylko lepszy, a powstał w zupełnie innych celach, a mianowicie (tak jak jest napisane przed katem):
- uruchamianie i monitorowanie zadań na nieograniczonej liczbie maszyn (na tyle Celery / Kubernetes i sumienie Ci pozwoli)
- z dynamicznym generowaniem przepływu pracy z bardzo łatwego do napisania i zrozumienia kodu Pythona
- oraz możliwość łączenia ze sobą dowolnych baz danych i API za pomocą zarówno gotowych komponentów, jak i domowych wtyczek (co jest niezwykle proste).
Używamy Apache Airflow w następujący sposób:
- zbieramy dane z różnych źródeł (wiele instancji SQL Server i PostgreSQL, różne API z metrykami aplikacji, nawet 1C) w DWH i ODS (mamy Vertica i Clickhouse).
- jak zaawansowany
cron, która uruchamia procesy konsolidacji danych na ODS, a także monitoruje ich utrzymanie.
Do niedawna nasze potrzeby pokrywał jeden mały serwer z 32 rdzeniami i 50 GB RAM. W Airflow działa to:
- więcej 200 dni (właściwie workflow, w które upchnęliśmy zadania),
- średnio w każdym 70 zadań,
- ta dobroć się zaczyna (też średnio) raz na godzinę.
A o tym, jak się rozwinęliśmy, napiszę poniżej, ale teraz zdefiniujmy über-problem, który rozwiążemy:
Istnieją trzy oryginalne serwery SQL, każdy z 50 bazami danych - odpowiednio instancjami jednego projektu, mają one taką samą strukturę (prawie wszędzie, mua-ha-ha), co oznacza, że każdy ma tabelę Orders (na szczęście tabela z tym nazwisko można wcisnąć do dowolnej firmy). Pobieramy dane, dodając pola usług (serwer źródłowy, źródłowa baza danych, identyfikator zadania ETL) i naiwnie wrzucamy je do, powiedzmy, Vertica.
Chodźmy!
Część główna, praktyczna (i trochę teoretyczna)
Dlaczego my (i wy)
Kiedy drzewa były duże, a ja byłem prosty SQL-schik w jednym z rosyjskich sklepów detalicznych oszukaliśmy procesy ETL, czyli przepływy danych, używając dwóch dostępnych nam narzędzi:
- Centrum zasilania Informatica - niezwykle rozłożysty system, niezwykle produktywny, z własnym sprzętem, własnym wersjonowaniem. Wykorzystałem nie daj Boże 1% jego możliwości. Dlaczego? Cóż, po pierwsze, ten interfejs, gdzieś z 380 roku, wywierał na nas mentalną presję. Po drugie, to urządzenie jest przeznaczone do niezwykle wymyślnych procesów, wściekłego ponownego wykorzystania komponentów i innych bardzo ważnych sztuczek korporacyjnych. O tym, ile to kosztuje, podobnie jak skrzydło Airbusa AXNUMX / rok, nic nie powiemy.
Uważaj, zrzut ekranu może trochę zaszkodzić osobom poniżej 30 roku życia
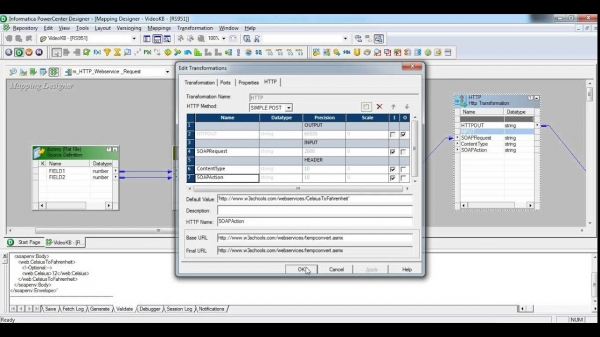
- Serwer integracji SQL Server - wykorzystaliśmy tego towarzysza w naszych przepływach wewnątrzprojektowych. Cóż, w rzeczywistości: korzystamy już z SQL Server i byłoby w jakiś sposób nierozsądne, gdybyśmy nie korzystali z jego narzędzi ETL. Wszystko w nim jest dobre: zarówno interfejs jest piękny, jak i raporty z postępów ... Ale nie dlatego kochamy oprogramowanie, och, nie za to. Wersja to
dtsx(który jest XML z węzłami przetasowanymi podczas zapisywania) możemy, ale o co chodzi? Co powiesz na stworzenie pakietu zadań, który przeciągnie setki tabel z jednego serwera na drugi? Tak, co sto, palec wskazujący spadnie z dwudziestu kawałków, klikając przycisk myszy. Ale zdecydowanie wygląda bardziej modnie:
Z pewnością szukaliśmy wyjścia. Sprawa nawet prawie przyszedł do samodzielnie napisanego generatora pakietów SSIS ...
…a potem znalazła mnie nowa praca. A Apache Airflow mnie na tym wyprzedził.
Kiedy dowiedziałem się, że opisy procesów ETL to prosty kod Pythona, po prostu nie tańczyłem z radości. W ten sposób strumienie danych były wersjonowane i różnicowane, a wlewanie tabel o jednej strukturze z setek baz danych do jednego celu stało się kwestią kodu Pythona na półtora lub dwóch 13-calowych ekranach.
Montaż klastra
Nie aranżujmy zupełnie przedszkola i nie mówmy tu o rzeczach zupełnie oczywistych, jak instalacja Airflow, wybranej przez Ciebie bazy danych, Selera i innych przypadkach opisanych w dokach.
Abyśmy mogli natychmiast rozpocząć eksperymenty, naszkicowałem docker-compose.yml w którym:
- Właściwie podbijmy Airflow: Harmonogram, serwer WWW. Kwiat będzie się tam również kręcił, aby monitorować zadania Selera (ponieważ został już wepchnięty
apache/airflow:1.10.10-python3.7, ale nam to nie przeszkadza) - PostgreSQL, w którym Airflow zapisze informacje o swojej usłudze (dane harmonogramu, statystyki wykonania itp.), a Celery oznaczy wykonane zadania;
- Redis, która będzie pełnić rolę brokera zadań dla Selera;
- Pracownik selera, które będą zaangażowane w bezpośrednią realizację zadań.
- Do folderu
./dagsdodamy nasze pliki z opisem dagów. Będą zbierane na bieżąco, więc nie ma potrzeby żonglowania całym stosem po każdym kichnięciu.
W niektórych miejscach kod w przykładach nie jest pokazany w całości (aby nie zaśmiecać tekstu), ale gdzieś w trakcie jest modyfikowany. Kompletne działające przykłady kodu można znaleźć w repozytorium .
docker-compose.yml
version: '3.4'
x-airflow-config: &airflow-config
AIRFLOW__CORE__DAGS_FOLDER: /dags
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__FERNET_KEY: MJNz36Q8222VOQhBOmBROFrmeSxNOgTCMaVp2_HOtE0=
AIRFLOW__CORE__HOSTNAME_CALLABLE: airflow.utils.net:get_host_ip_address
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgres+psycopg2://airflow:airflow@airflow-db:5432/airflow
AIRFLOW__CORE__PARALLELISM: 128
AIRFLOW__CORE__DAG_CONCURRENCY: 16
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_RETRY: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_FAILURE: 'False'
AIRFLOW__CELERY__BROKER_URL: redis://broker:6379/0
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@airflow-db/airflow
x-airflow-base: &airflow-base
image: apache/airflow:1.10.10-python3.7
entrypoint: /bin/bash
restart: always
volumes:
- ./dags:/dags
- ./requirements.txt:/requirements.txt
services:
# Redis as a Celery broker
broker:
image: redis:6.0.5-alpine
# DB for the Airflow metadata
airflow-db:
image: postgres:10.13-alpine
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
volumes:
- ./db:/var/lib/postgresql/data
# Main container with Airflow Webserver, Scheduler, Celery Flower
airflow:
<<: *airflow-base
environment:
<<: *airflow-config
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: 30
AIRFLOW__SCHEDULER__CATCHUP_BY_DEFAULT: 'False'
AIRFLOW__SCHEDULER__MAX_THREADS: 8
AIRFLOW__WEBSERVER__LOG_FETCH_TIMEOUT_SEC: 10
depends_on:
- airflow-db
- broker
command: >
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint initdb &&
(/entrypoint webserver &) &&
(/entrypoint flower &) &&
/entrypoint scheduler"
ports:
# Celery Flower
- 5555:5555
# Airflow Webserver
- 8080:8080
# Celery worker, will be scaled using `--scale=n`
worker:
<<: *airflow-base
environment:
<<: *airflow-config
command: >
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint worker"
depends_on:
- airflow
- airflow-db
- brokerUwagi:
- Przy składaniu kompozycji oparłem się w dużej mierze na dobrze znanym obrazie - sprawdź koniecznie. Może nie potrzebujesz już niczego więcej w swoim życiu.
- Wszystkie ustawienia Airflow są dostępne nie tylko przez
airflow.cfg, ale także poprzez zmienne środowiskowe (dzięki twórcom), które złośliwie wykorzystałem. - Naturalnie nie jest gotowy do produkcji: celowo nie kładłem pulsu na pojemnikach, nie zawracałem sobie głowy bezpieczeństwem. Ale zrobiłem minimum odpowiednie dla naszych eksperymentatorów.
- Zwróć uwagę, że:
- Folder dag musi być dostępny zarówno dla programu planującego, jak i dla procesów roboczych.
- To samo dotyczy wszystkich bibliotek innych firm — wszystkie muszą być zainstalowane na komputerach z harmonogramem i procesami roboczymi.
Cóż, teraz to proste:
$ docker-compose up --scale worker=3Po tym, jak wszystko się podniesie, możesz spojrzeć na interfejsy internetowe:
- Przepływ powietrza:
- Kwiat:
Podstawowe pojęcia
Jeśli nic nie zrozumiałeś z tych wszystkich „dagów”, oto krótki słownik:
- Scheduler - najważniejszy wujek w Airflow, kontrolujący, że roboty ciężko pracują, a nie człowiek: pilnuje harmonogramu, aktualizuje daty, uruchamia zadania.
Generalnie w starszych wersjach miał problemy z pamięcią (nie, nie amnezja, tylko przecieki) a parametr legacy nawet pozostał w configach
run_duration— interwał ponownego uruchomienia. Ale teraz wszystko jest w porządku. - DZIEŃ (aka "dag") - "skierowany graf acykliczny", ale taka definicja niewiele osób powie, ale w rzeczywistości jest to kontener dla zadań wchodzących ze sobą w interakcje (patrz niżej) lub analog Package w SSIS i Workflow w Informatica .
Oprócz dagów mogą być jeszcze subdagi, ale raczej do nich nie dotrzemy.
- Bieg DAG - zainicjowany dag, który ma przypisany własny
execution_date. Dagrany tego samego dnia mogą pracować równolegle (oczywiście jeśli uczyniłeś swoje zadania idempotentnymi). - Operator to fragmenty kodu odpowiedzialne za wykonanie określonej akcji. Istnieją trzy rodzaje operatorów:
- akcjajak nasz ulubieniec
PythonOperator, który może wykonać dowolny (poprawny) kod Pythona; - przenieść, które przenoszą dane z miejsca na miejsce, powiedzmy,
MsSqlToHiveTransfer; - czujnik z drugiej strony pozwoli zareagować lub spowolnić dalsze wykonywanie dagu do momentu wystąpienia zdarzenia.
HttpSensormoże pobrać określony punkt końcowy, a gdy żądana odpowiedź oczekuje, rozpocznij transferGoogleCloudStorageToS3Operator. Dociekliwy umysł zapyta: „dlaczego? W końcu możesz robić powtórzenia bezpośrednio w operatorze!” A potem, żeby nie zapchać puli zadań zawieszonymi operatorami. Czujnik uruchamia się, sprawdza i gaśnie przed następną próbą.
- akcjajak nasz ulubieniec
- Zadanie - zadeklarowani operatorzy, bez względu na typ, i podpięci pod dag awansują do rangi zadania.
- instancja zadania - kiedy główny planista zdecydował, że nadszedł czas, aby wysłać zadania do bitwy na wykonawców-robotników (na miejscu, jeśli używamy
LocalExecutorlub do zdalnego węzła w przypadkuCeleryExecutor), przypisuje im kontekst (tj. zestaw zmiennych - parametry wykonania), rozszerza szablony poleceń lub zapytań i łączy je.
Generujemy zadania
Najpierw nakreślmy ogólny schemat naszego Douga, a potem będziemy zagłębiać się coraz bardziej w szczegóły, ponieważ stosujemy kilka nietrywialnych rozwiązań.
Tak więc w najprostszej formie taki dag będzie wyglądał następująco:
from datetime import timedelta, datetime
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from commons.datasources import sql_server_ds
dag = DAG('orders',
schedule_interval=timedelta(hours=6),
start_date=datetime(2020, 7, 8, 0))
def workflow(**context):
print(context)
for conn_id, schema in sql_server_ds:
PythonOperator(
task_id=schema,
python_callable=workflow,
provide_context=True,
dag=dag)Zrozummy:
- Najpierw importujemy niezbędne biblioteki i coś innego;
sql_server_ds- jestList[namedtuple[str, str]]z nazwami połączeń z Airflow Connections oraz bazami danych, z których weźmiemy naszą tablicę;dag- zapowiedź naszego dagu, który koniecznie musi być wglobals(), inaczej Airflow go nie znajdzie. Doug musi też powiedzieć:- jak on ma na imię
orders- ta nazwa pojawi się wtedy w interfejsie internetowym, - że będzie pracował od północy ósmego lipca,
- i powinien działać mniej więcej co 6 godzin (dla twardzieli tutaj zamiast
timedelta()dopuszczalnycron-linia0 0 0/6 ? * * *, dla mniej fajnych - wyrażenie typu@daily);
- jak on ma na imię
workflow()wykona główną pracę, ale nie teraz. Na razie po prostu zrzucimy nasz kontekst do dziennika.- A teraz prosta magia tworzenia zadań:
- przeglądamy nasze źródła;
- zainicjować
PythonOperator, który wykona nasz manekinworkflow(). Nie zapomnij podać unikalnej (w dagu) nazwy zadania i zawiązać sam dag. Flagaprovide_contextz kolei wleje do funkcji dodatkowe argumenty, których będziemy starannie zbierać za pomocą**context.
Na razie to wszystko. Co otrzymaliśmy:
- nowy dag w interfejsie webowym,
- półtora setki zadań, które będą wykonywane równolegle (jeśli pozwolą na to ustawienia Airflow, Celery i pojemność serwera).
Cóż, prawie się udało.
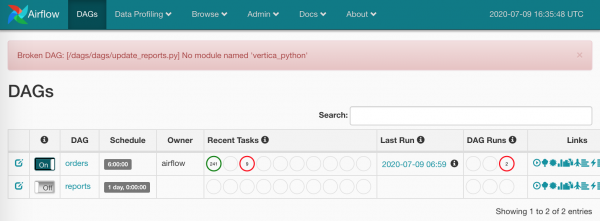
Kto zainstaluje zależności?
Aby uprościć to wszystko, wkręciłem się docker-compose.yml przetwarzanie requirements.txt na wszystkich węzłach.
Teraz go nie ma:
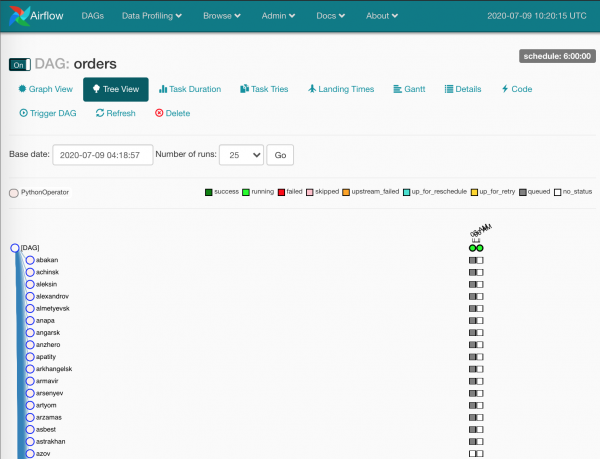
Szare kwadraty to instancje zadań przetwarzane przez harmonogram.
Czekamy chwilę, zadania są rozchwytywane przez robotników:
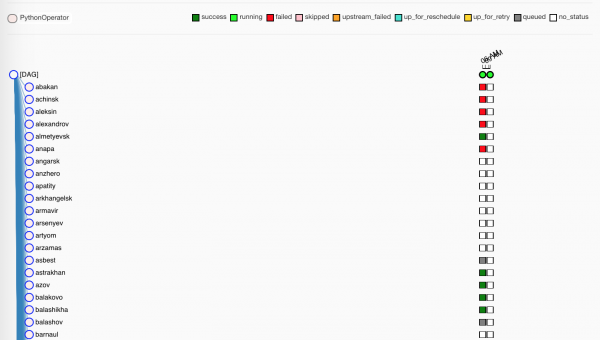
Zieloni oczywiście pomyślnie zakończyli swoją pracę. Czerwoni nie są zbyt skuteczni.
Nawiasem mówiąc, nie ma folderu na naszym prod
./dags, nie ma synchronizacji między maszynami - wszystkie dagi leżągitw naszym Gitlabie, a Gitlab CI rozsyła aktualizacje do maszyn podczas łączeniamaster.
Trochę o kwiatku
Podczas gdy robotnicy tłuką nasze smoczki, pamiętajmy o jeszcze jednym narzędziu, które może nam coś pokazać – o Kwiatku.
Pierwsza strona z podsumowaniem informacji o węzłach roboczych:
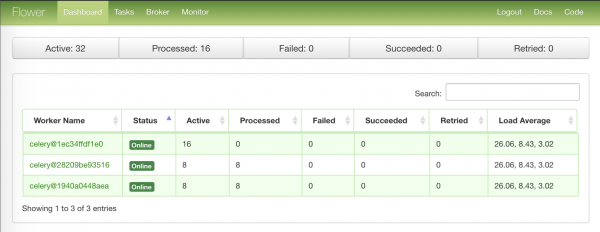
Najbardziej intensywna strona z zadaniami, które poszły do pracy:
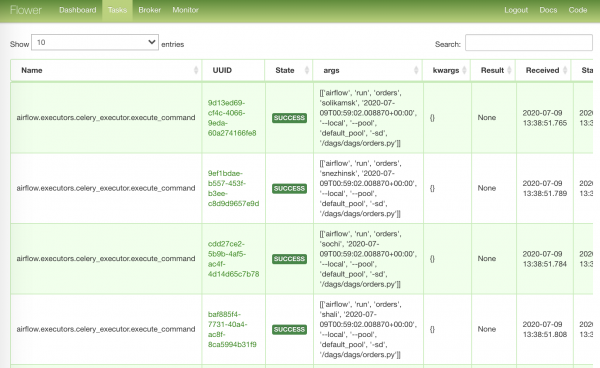
Najnudniejsza strona ze statusem naszego brokera:
Najjaśniejsza strona to wykresy statusu zadań i czasu ich wykonania:
Ładujemy niedociążone
Więc wszystkie zadania zostały wykonane, możesz zabrać rannych.
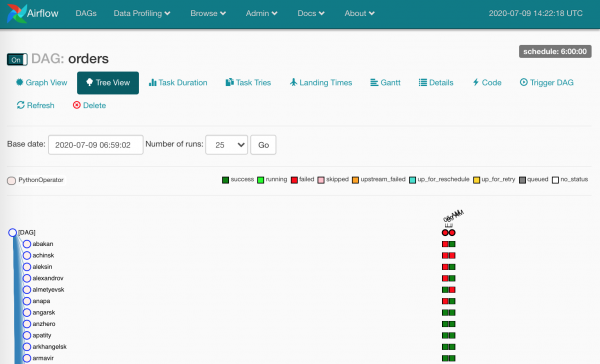
I było wielu rannych - z tego czy innego powodu. W przypadku poprawnego użycia Airflow właśnie te kwadraty wskazują, że dane zdecydowanie nie dotarły.
Musisz obejrzeć dziennik i ponownie uruchomić upadłe instancje zadań.
Klikając w dowolny kwadrat zobaczymy dostępne dla nas akcje:
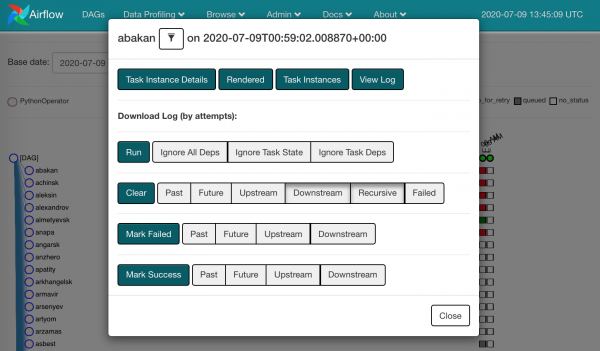
Możesz zabrać i oczyścić upadłych. Czyli zapominamy, że coś tam się nie powiodło i to samo zadanie instancji trafi do harmonogramu.

Oczywiste jest, że robienie tego myszką ze wszystkimi czerwonymi kwadratami jest mało humanitarne – nie tego oczekujemy od Airflow. Oczywiście mamy broń masowego rażenia: Browse/Task Instances
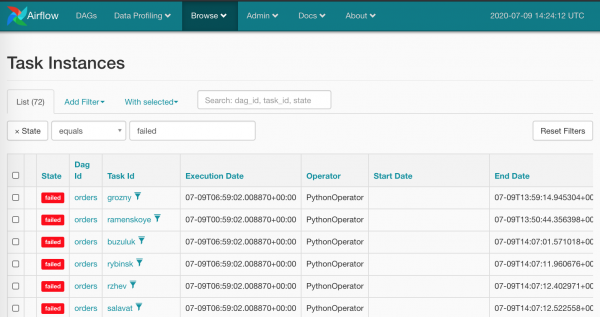
Wybierzmy wszystko na raz i zresetujmy do zera, kliknij właściwy element:
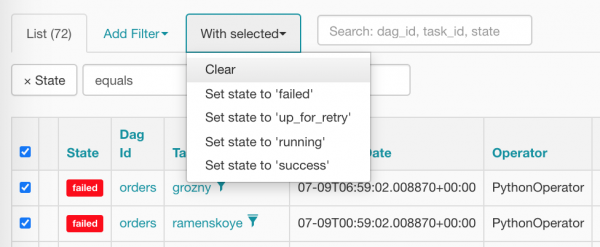
Po oczyszczeniu nasze taksówki wyglądają tak (już czekają na rozkład jazdy):

Połączenia, haki i inne zmienne
Czas spojrzeć na kolejny DAG, update_reports.py:
from collections import namedtuple
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.contrib.operators.vertica_operator import VerticaOperator
from airflow.operators.email_operator import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
from commons.operators import TelegramBotSendMessage
dag = DAG('update_reports',
start_date=datetime(2020, 6, 7, 6),
schedule_interval=timedelta(days=1),
default_args={'retries': 3, 'retry_delay': timedelta(seconds=10)})
Report = namedtuple('Report', 'source target')
reports = [Report(f'{table}_view', table) for table in [
'reports.city_orders',
'reports.client_calls',
'reports.client_rates',
'reports.daily_orders',
'reports.order_duration']]
email = EmailOperator(
task_id='email_success', dag=dag,
to='{{ var.value.all_the_kings_men }}',
subject='DWH Reports updated',
html_content=dedent("""Господа хорошие, отчеты обновлены"""),
trigger_rule=TriggerRule.ALL_SUCCESS)
tg = TelegramBotSendMessage(
task_id='telegram_fail', dag=dag,
tg_bot_conn_id='tg_main',
chat_id='{{ var.value.failures_chat }}',
message=dedent("""
Наташ, просыпайся, мы {{ dag.dag_id }} уронили
"""),
trigger_rule=TriggerRule.ONE_FAILED)
for source, target in reports:
queries = [f"TRUNCATE TABLE {target}",
f"INSERT INTO {target} SELECT * FROM {source}"]
report_update = VerticaOperator(
task_id=target.replace('reports.', ''),
sql=queries, vertica_conn_id='dwh',
task_concurrency=1, dag=dag)
report_update >> [email, tg]Czy wszyscy kiedykolwiek aktualizowali raport? To znowu ona: jest lista źródeł, z których można pobrać dane; jest lista, gdzie umieścić; nie zapomnij zatrąbić, gdy wszystko się wydarzy lub zepsuje (cóż, tu nie chodzi o nas, nie).
Przejrzyjmy ponownie plik i spójrzmy na nowe, niejasne rzeczy:
from commons.operators import TelegramBotSendMessage- nic nie stoi na przeszkodzie, aby stworzyć własnych operatorów, z czego skorzystaliśmy robiąc mały wrapper do wysyłania wiadomości do Unblocked. (Porozmawiamy więcej o tym operatorze poniżej);default_args={}- dag może przekazywać te same argumenty wszystkim swoim operatorom;to='{{ var.value.all_the_kings_men }}'- poletonie będziemy mieć zakodowanych, ale dynamicznie generowanych za pomocą Jinja i zmiennej z listą e-maili, które starannie umieściłemAdmin/Variables;trigger_rule=TriggerRule.ALL_SUCCESS— warunek uruchomienia operatora. W naszym przypadku list poleci do szefów tylko wtedy, gdy wszystkie zależności się spełnią z powodzeniem;tg_bot_conn_id='tg_main'- argumentyconn_idakceptuj identyfikatory połączeń, które tworzymy wAdmin/Connections;trigger_rule=TriggerRule.ONE_FAILED- wiadomości w Telegramie będą odlatywać tylko wtedy, gdy są upadłe zadania;task_concurrency=1- zabraniamy jednoczesnego uruchamiania kilku instancji jednego zadania. Inaczej dostaniemy jednoczesne uruchomienie kilkuVerticaOperator(patrząc na jeden stół);report_update >> [email, tg]- WszystkoVerticaOperatorzbiegają się w wysyłaniu listów i wiadomości, takich jak ta:
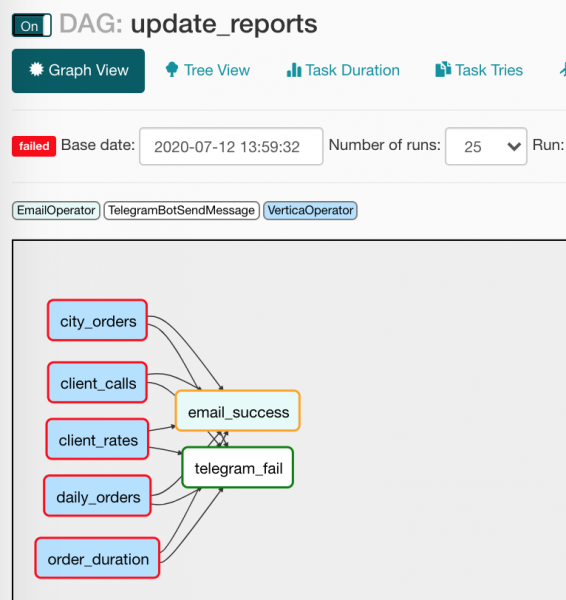
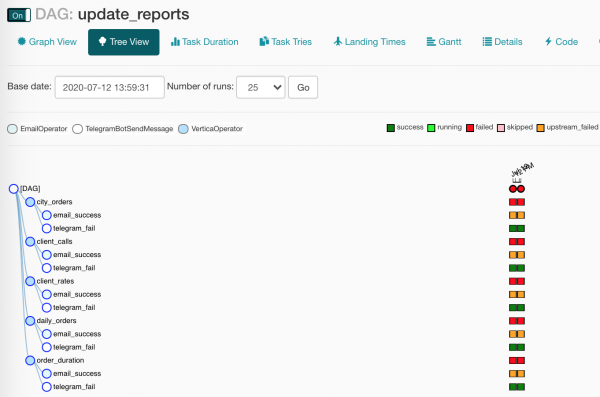
Ale ponieważ operatorzy powiadomień mają różne warunki uruchamiania, tylko jeden będzie działał. W widoku drzewa wszystko wygląda trochę mniej wizualnie:

Powiem kilka słów nt makra i ich przyjaciele - zmienne.
Makra to symbole zastępcze Jinja, które mogą zastępować różne przydatne informacje argumentami operatora. Na przykład tak:
SELECT
id,
payment_dtm,
payment_type,
client_id
FROM orders.payments
WHERE
payment_dtm::DATE = '{{ ds }}'::DATE{{ ds }} rozwinie się do zawartości zmiennej kontekstowej execution_date w formacie YYYY-MM-DD: 2020-07-14. Najlepsze jest to, że zmienne kontekstowe są przybijane do określonej instancji zadania (kwadrat w Widoku drzewa), a po ponownym uruchomieniu symbole zastępcze rozwiną się do tych samych wartości.
Przypisane wartości można przeglądać za pomocą przycisku Renderowane na każdej instancji zadania. Tak wygląda zadanie z wysłaniem listu:
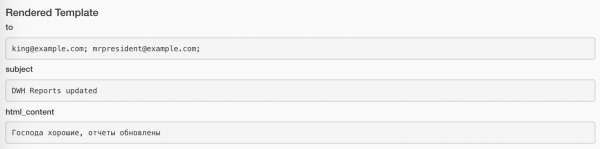
I tak przy zadaniu z wysłaniem wiadomości:

Pełna lista wbudowanych makr dla najnowszej dostępnej wersji jest dostępna tutaj:
Co więcej, za pomocą wtyczek możemy zadeklarować własne makra, ale to już inna historia.
Oprócz predefiniowanych rzeczy możemy podstawić wartości naszych zmiennych (ja już to wykorzystałem w kodzie powyżej). Stwórzmy w Admin/Variables kilka rzeczy:
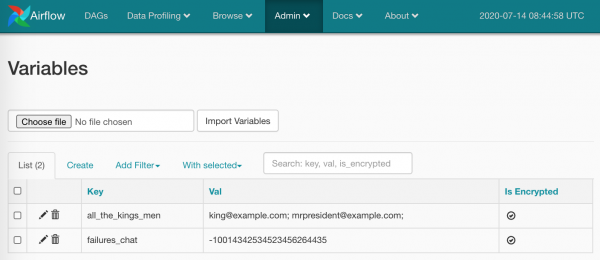
Wszystko, czego możesz użyć:
TelegramBotSendMessage(chat_id='{{ var.value.failures_chat }}')Wartość może być wartością skalarną lub JSON. W przypadku JSON:
bot_config
{
"bot": {
"token": 881hskdfASDA16641,
"name": "Verter"
},
"service": "TG"
}po prostu użyj ścieżki do żądanego klucza: {{ var.json.bot_config.bot.token }}.
Powiem dosłownie jedno słowo i pokażę jeden zrzut ekranu o połączenia. Tutaj wszystko jest elementarne: na stronie Admin/Connections tworzymy połączenie, dodajemy tam nasze loginy/hasła i bardziej szczegółowe parametry. Lubię to:
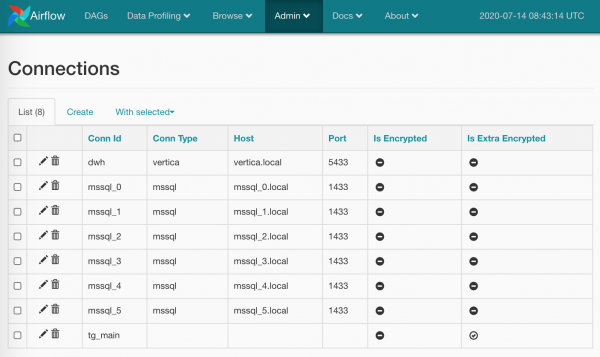
Hasła mogą być szyfrowane (bardziej dokładnie niż domyślnie) lub możesz pominąć typ połączenia (tak jak zrobiłem to dla tg_main) - faktem jest, że lista typów jest na stałe w modelach Airflow i nie da się jej rozszerzyć bez wchodzenia w kody źródłowe (jeśli nagle coś nie googlowałem, to proszę mnie poprawić), ale nic nie stoi na przeszkodzie, aby zdobyć kredyty po prostu nazwa.
Możesz także utworzyć kilka połączeń o tej samej nazwie: w tym przypadku metoda BaseHook.get_connection(), który daje nam połączenia po imieniu, da losowy od kilku imienników (bardziej logiczne byłoby zrobienie Round Robin, ale zostawmy to na sumieniu twórców Airflow).
Zmienne i połączenia są z pewnością fajnymi narzędziami, ale ważne jest, aby nie stracić równowagi: które części przepływów przechowujesz w samym kodzie, a które przekazujesz Airflow do przechowywania. Z jednej strony wygodna może być szybka zmiana wartości, na przykład skrzynki pocztowej, za pośrednictwem interfejsu użytkownika. Z drugiej strony to wciąż powrót do kliknięcia myszką, którego my (ja) chcieliśmy się pozbyć.
Praca z połączeniami to jedno z zadań haki. Ogólnie rzecz biorąc, haczyki Airflow to punkty umożliwiające połączenie go z usługami i bibliotekami innych firm. Np, JiraHook otworzy dla nas klienta do interakcji z Jira (możesz przenosić zadania tam iz powrotem), a przy pomocy SambaHook możesz przesłać plik lokalny do smb-punkt.
Analizowanie operatora niestandardowego
I zbliżyliśmy się, by zobaczyć, jak to jest zrobione TelegramBotSendMessage
kod commons/operators.py z faktycznym operatorem:
from typing import Union
from airflow.operators import BaseOperator
from commons.hooks import TelegramBotHook, TelegramBot
class TelegramBotSendMessage(BaseOperator):
"""Send message to chat_id using TelegramBotHook
Example:
>>> TelegramBotSendMessage(
... task_id='telegram_fail', dag=dag,
... tg_bot_conn_id='tg_bot_default',
... chat_id='{{ var.value.all_the_young_dudes_chat }}',
... message='{{ dag.dag_id }} failed :(',
... trigger_rule=TriggerRule.ONE_FAILED)
"""
template_fields = ['chat_id', 'message']
def __init__(self,
chat_id: Union[int, str],
message: str,
tg_bot_conn_id: str = 'tg_bot_default',
*args, **kwargs):
super().__init__(*args, **kwargs)
self._hook = TelegramBotHook(tg_bot_conn_id)
self.client: TelegramBot = self._hook.client
self.chat_id = chat_id
self.message = message
def execute(self, context):
print(f'Send "{self.message}" to the chat {self.chat_id}')
self.client.send_message(chat_id=self.chat_id,
message=self.message)Tutaj, podobnie jak wszystko inne w Airflow, wszystko jest bardzo proste:
- Odziedziczony po
BaseOperator, który implementuje sporo rzeczy specyficznych dla Airflow (spójrz na swój czas wolny) - Zadeklarowane pola
template_fields, w którym Jinja będzie szukał makr do przetworzenia. - Ułożył odpowiednie argumenty za
__init__(), w razie potrzeby ustaw wartości domyślne. - Nie zapomnieliśmy również o inicjalizacji przodka.
- Otworzył odpowiedni hak
TelegramBotHookotrzymał od niego obiekt klienta. - Przesłonięta (ponownie zdefiniowana) metoda
BaseOperator.execute(), którym Airfow drgnie, gdy przyjdzie czas na uruchomienie operatora – w nim zrealizujemy główną akcję, zapominając się zalogować. (Nawiasem mówiąc, logujemy się od razustdoutиstderr- Przepływ powietrza przechwyci wszystko, pięknie owinie, rozłoży tam, gdzie to konieczne.)
Zobaczmy, co mamy commons/hooks.py. Pierwsza część pliku, z samym hakiem:
from typing import Union
from airflow.hooks.base_hook import BaseHook
from requests_toolbelt.sessions import BaseUrlSession
class TelegramBotHook(BaseHook):
"""Telegram Bot API hook
Note: add a connection with empty Conn Type and don't forget
to fill Extra:
{"bot_token": "YOuRAwEsomeBOtToKen"}
"""
def __init__(self,
tg_bot_conn_id='tg_bot_default'):
super().__init__(tg_bot_conn_id)
self.tg_bot_conn_id = tg_bot_conn_id
self.tg_bot_token = None
self.client = None
self.get_conn()
def get_conn(self):
extra = self.get_connection(self.tg_bot_conn_id).extra_dejson
self.tg_bot_token = extra['bot_token']
self.client = TelegramBot(self.tg_bot_token)
return self.clientNie wiem nawet, co tu wyjaśniać, zwrócę tylko uwagę na ważne punkty:
- Dziedziczymy, pomyśl o argumentach - w większości przypadków będzie to jeden:
conn_id; - Zastępowanie standardowych metod: ograniczyłem się
get_conn(), w którym otrzymuję parametry połączenia według nazwy i po prostu otrzymuję sekcjęextra(jest to pole JSON), w które (według własnych wskazówek!) umieściłem token bota Telegrama:{"bot_token": "YOuRAwEsomeBOtToKen"}. - Tworzę instancję naszego
TelegramBot, nadając mu określony token.
To wszystko. Możesz zdobyć klienta z haka za pomocą TelegramBotHook().clent lub TelegramBotHook().get_conn().
I druga część pliku, w której robię microwrapper dla Telegram REST API, żeby nie przeciągać tego samego dla jednej metody sendMessage.
class TelegramBot:
"""Telegram Bot API wrapper
Examples:
>>> TelegramBot('YOuRAwEsomeBOtToKen', '@myprettydebugchat').send_message('Hi, darling')
>>> TelegramBot('YOuRAwEsomeBOtToKen').send_message('Hi, darling', chat_id=-1762374628374)
"""
API_ENDPOINT = 'https://api.telegram.org/bot{}/'
def __init__(self, tg_bot_token: str, chat_id: Union[int, str] = None):
self._base_url = TelegramBot.API_ENDPOINT.format(tg_bot_token)
self.session = BaseUrlSession(self._base_url)
self.chat_id = chat_id
def send_message(self, message: str, chat_id: Union[int, str] = None):
method = 'sendMessage'
payload = {'chat_id': chat_id or self.chat_id,
'text': message,
'parse_mode': 'MarkdownV2'}
response = self.session.post(method, data=payload).json()
if not response.get('ok'):
raise TelegramBotException(response)
class TelegramBotException(Exception):
def __init__(self, *args, **kwargs):
super().__init__((args, kwargs))Właściwym sposobem jest dodanie wszystkiego:
TelegramBotSendMessage,TelegramBotHook,TelegramBot- we wtyczce umieść w publicznym repozytorium i przekaż do Open Source.
Podczas gdy analizowaliśmy to wszystko, nasze aktualizacje raportów zakończyły się niepowodzeniem i wysłały mi komunikat o błędzie w kanale. zaraz sprawdzę czy się nie myli...
Coś pękło w naszej dozie! Czy nie tego się spodziewaliśmy? Dokładnie!
Będziesz wlewał?
Czy czujesz, że coś przegapiłem? Wygląda na to, że obiecał przenieść dane z SQL Servera do Vertica, a potem wziął to i odszedł od tematu, łajdak!
To okrucieństwo było zamierzone, po prostu musiałem rozszyfrować dla ciebie pewną terminologię. Teraz możesz iść dalej.
Nasz plan był taki:
- Dag
- Generuj zadania
- Zobacz, jakie wszystko jest piękne
- Przypisz numery sesji do wypełnień
- Pobierz dane z SQL Server
- Umieść dane w Vertica
- Zbieraj statystyki
Tak więc, aby to wszystko działało, zrobiłem mały dodatek do naszego docker-compose.yml:
docker-compose.db.yml
version: '3.4'
x-mssql-base: &mssql-base
image: mcr.microsoft.com/mssql/server:2017-CU21-ubuntu-16.04
restart: always
environment:
ACCEPT_EULA: Y
MSSQL_PID: Express
SA_PASSWORD: SayThanksToSatiaAt2020
MSSQL_MEMORY_LIMIT_MB: 1024
services:
dwh:
image: jbfavre/vertica:9.2.0-7_ubuntu-16.04
mssql_0:
<<: *mssql-base
mssql_1:
<<: *mssql-base
mssql_2:
<<: *mssql-base
mssql_init:
image: mio101/py3-sql-db-client-base
command: python3 ./mssql_init.py
depends_on:
- mssql_0
- mssql_1
- mssql_2
environment:
SA_PASSWORD: SayThanksToSatiaAt2020
volumes:
- ./mssql_init.py:/mssql_init.py
- ./dags/commons/datasources.py:/commons/datasources.pyTam podnosimy:
- Vertica jako gospodarz
dwhz najbardziej domyślnymi ustawieniami, - trzy instancje SQL Server,
- wypełniamy bazy danych w tym ostatnim jakimiś danymi (w żadnym wypadku nie zaglądaj
mssql_init.py!)
Wszystko co dobre uruchamiamy za pomocą nieco bardziej skomplikowanego polecenia niż ostatnio:
$ docker-compose -f docker-compose.yml -f docker-compose.db.yml up --scale worker=3Co wygenerował nasz cudowny randomizer, możesz użyć przedmiotu Data Profiling/Ad Hoc Query:
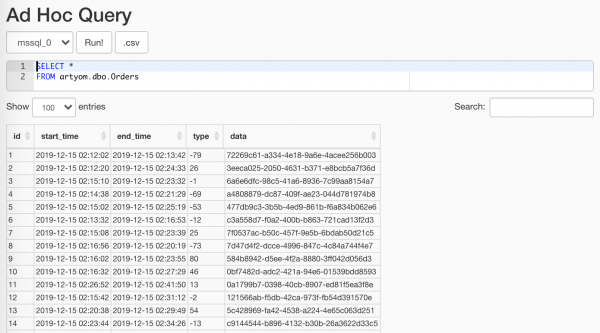
Najważniejsze, żeby nie pokazywać tego analitykom
rozwinąć Sesje ETL Nie będę, tam wszystko jest banalne: robimy bazę, jest w niej znak, owijamy wszystko menedżerem kontekstu, a teraz robimy to:
with Session(task_name) as session:
print('Load', session.id, 'started')
# Load worflow
...
session.successful = True
session.loaded_rows = 15sesja.py
from sys import stderr
class Session:
"""ETL workflow session
Example:
with Session(task_name) as session:
print(session.id)
session.successful = True
session.loaded_rows = 15
session.comment = 'Well done'
"""
def __init__(self, connection, task_name):
self.connection = connection
self.connection.autocommit = True
self._task_name = task_name
self._id = None
self.loaded_rows = None
self.successful = None
self.comment = None
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_val, exc_tb):
if any(exc_type, exc_val, exc_tb):
self.successful = False
self.comment = f'{exc_type}: {exc_val}n{exc_tb}'
print(exc_type, exc_val, exc_tb, file=stderr)
self.close()
def __repr__(self):
return (f'<{self.__class__.__name__} '
f'id={self.id} '
f'task_name="{self.task_name}">')
@property
def task_name(self):
return self._task_name
@property
def id(self):
return self._id
def _execute(self, query, *args):
with self.connection.cursor() as cursor:
cursor.execute(query, args)
return cursor.fetchone()[0]
def _create(self):
query = """
CREATE TABLE IF NOT EXISTS sessions (
id SERIAL NOT NULL PRIMARY KEY,
task_name VARCHAR(200) NOT NULL,
started TIMESTAMPTZ NOT NULL DEFAULT current_timestamp,
finished TIMESTAMPTZ DEFAULT current_timestamp,
successful BOOL,
loaded_rows INT,
comment VARCHAR(500)
);
"""
self._execute(query)
def open(self):
query = """
INSERT INTO sessions (task_name, finished)
VALUES (%s, NULL)
RETURNING id;
"""
self._id = self._execute(query, self.task_name)
print(self, 'opened')
return self
def close(self):
if not self._id:
raise SessionClosedError('Session is not open')
query = """
UPDATE sessions
SET
finished = DEFAULT,
successful = %s,
loaded_rows = %s,
comment = %s
WHERE
id = %s
RETURNING id;
"""
self._execute(query, self.successful, self.loaded_rows,
self.comment, self.id)
print(self, 'closed',
', successful: ', self.successful,
', Loaded: ', self.loaded_rows,
', comment:', self.comment)
class SessionError(Exception):
pass
class SessionClosedError(SessionError):
passNadszedł czas zbierać nasze dane z naszych półtora setki stołów. Zróbmy to za pomocą bardzo bezpretensjonalnych linii:
source_conn = MsSqlHook(mssql_conn_id=src_conn_id, schema=src_schema).get_conn()
query = f"""
SELECT
id, start_time, end_time, type, data
FROM dbo.Orders
WHERE
CONVERT(DATE, start_time) = '{dt}'
"""
df = pd.read_sql_query(query, source_conn)- Za pomocą haczyka dostajemy od Airflow
pymssql-łączyć - Podstawmy do żądania ograniczenie w postaci daty - zostanie ona wrzucona do funkcji przez silnik szablonów.
- Karmienie naszej prośby
pandaskto nas dopadnieDataFrame- przyda nam się w przyszłości.
Korzystam z zamienników
{dt}zamiast parametru żądania%snie dlatego, że jestem złym Pinokio, ale dlatego, żepandasnie mogę sobie poradzićpymssqli wsuwa ostatniąparams: Listchociaż bardzo chcetuple.
Należy również pamiętać, że deweloperpymssqlpostanowił nie wspierać go już i czas się wyprowadzićpyodbc.
Zobaczmy, czym Airflow wypchał argumenty naszych funkcji:
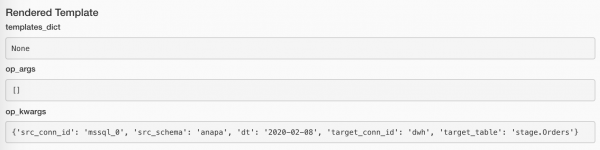
Jeśli nie ma danych, nie ma sensu kontynuować. Ale dziwne jest również uznanie wypełnienia za udane. Ale to nie jest błąd. A-ah-ah, co robić?! A oto co:
if df.empty:
raise AirflowSkipException('No rows to load')AirflowSkipException powie Airflow, że nie ma błędów, ale pomijamy to zadanie. Interfejs nie będzie miał zielonego ani czerwonego kwadratu, ale różowy.
Wyrzućmy nasze dane wiele kolumn:
df['etl_source'] = src_schema
df['etl_id'] = session.id
df['hash_id'] = hash_pandas_object(df[['etl_source', 'id']])A mianowicie:
- Baza danych, z której pobieraliśmy zamówienia,
- Identyfikator naszej sesji zalewania (będzie inny dla każdego zadania),
- Hash ze źródła i identyfikatora zamówienia - dzięki czemu w ostatecznej bazie danych (gdzie wszystko wlewa się do jednej tabeli) mamy unikalny identyfikator zamówienia.
Pozostaje przedostatni krok: wlej wszystko do Vertica. I, co dziwne, jednym z najbardziej spektakularnych i skutecznych sposobów na zrobienie tego jest CSV!
# Export data to CSV buffer
buffer = StringIO()
df.to_csv(buffer,
index=False, sep='|', na_rep='NUL', quoting=csv.QUOTE_MINIMAL,
header=False, float_format='%.8f', doublequote=False, escapechar='\')
buffer.seek(0)
# Push CSV
target_conn = VerticaHook(vertica_conn_id=target_conn_id).get_conn()
copy_stmt = f"""
COPY {target_table}({df.columns.to_list()})
FROM STDIN
DELIMITER '|'
ENCLOSED '"'
ABORT ON ERROR
NULL 'NUL'
"""
cursor = target_conn.cursor()
cursor.copy(copy_stmt, buffer)- Robimy specjalny odbiornik
StringIO. pandasuprzejmie umieścimy naszeDataFramew formieCSV-linie.- Otwórzmy połączenie z naszą ulubioną Verticą za pomocą haka.
- A teraz z pomocą
copy()wyślij nasze dane bezpośrednio do Vertika!
Odbierzemy od kierowcy ile linii zostało wypełnionych i powiemy kierownikowi sesji, że wszystko jest w porządku:
session.loaded_rows = cursor.rowcount
session.successful = TrueTo wszystko.
Na wyprzedaży tarczę docelową tworzymy ręcznie. Tutaj pozwoliłem sobie na małą maszynkę:
create_schema_query = f'CREATE SCHEMA IF NOT EXISTS {target_schema};'
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {target_schema}.{target_table} (
id INT,
start_time TIMESTAMP,
end_time TIMESTAMP,
type INT,
data VARCHAR(32),
etl_source VARCHAR(200),
etl_id INT,
hash_id INT PRIMARY KEY
);"""
create_table = VerticaOperator(
task_id='create_target',
sql=[create_schema_query,
create_table_query],
vertica_conn_id=target_conn_id,
task_concurrency=1,
dag=dag)ja używam
VerticaOperator()Tworzę schemat bazy danych i tabelę (jeśli oczywiście jeszcze nie istnieją). Najważniejsze jest prawidłowe ułożenie zależności:
for conn_id, schema in sql_server_ds:
load = PythonOperator(
task_id=schema,
python_callable=workflow,
op_kwargs={
'src_conn_id': conn_id,
'src_schema': schema,
'dt': '{{ ds }}',
'target_conn_id': target_conn_id,
'target_table': f'{target_schema}.{target_table}'},
dag=dag)
create_table >> loadPodsumowując
- Cóż - powiedziała mała mysz - czyż nie teraz
Czy jesteś przekonany, że jestem najstraszniejszym zwierzęciem w lesie?
Julia Donaldson, Gruffalo
Myślę, że gdybyśmy z kolegami mieli konkurencję: kto szybko stworzy i uruchomi proces ETL od podstaw: oni ze swoim SSIS i myszką, a ja z Airflow… I wtedy porównalibyśmy jeszcze łatwość utrzymania… Wow, myślę, że zgodzisz się, że pokonam ich na wszystkich frontach!
Jeśli trochę poważniej, to Apache Airflow – opisując procesy w postaci kodu programu – zrobił swoje dużo wygodniejsze i przyjemniejsze.
Jego nieograniczona rozbudowę, zarówno jeśli chodzi o wtyczki, jak i predyspozycje do skalowalności, daje możliwość wykorzystania Airflow w niemal każdym obszarze: nawet w pełnym cyklu zbierania, przygotowywania i przetwarzania danych, nawet w wystrzeliwaniu rakiet (na Marsa, kurs).
Część końcowa, odniesienia i informacje
Prowizja, którą dla Ciebie zebraliśmy
start_date. Tak, to już lokalny mem. Poprzez główny argument Dougastart_datewszyscy przechodzą. Krótko mówiąc, jeśli określisz wstart_dateaktualna data ischedule_interval- pewnego dnia, to DAG zacznie się jutro nie wcześniej.start_date = datetime(2020, 7, 7, 0, 1, 2)I żadnych więcej problemów.
Związany jest z tym inny błąd czasu wykonywania:
Task is missing the start_date parameter, co najczęściej wskazuje, że zapomniałeś powiązać z operatorem dag.- Wszystko na jednej maszynie. Tak, i bazy (sam Airflow i nasza powłoka), serwer WWW, harmonogram i pracownicy. I nawet zadziałało. Ale z biegiem czasu liczba zadań dla usług rosła, a kiedy PostgreSQL zaczął odpowiadać na indeks w 20 s zamiast 5 ms, wzięliśmy to i ponieśliśmy.
- Lokalny wykonawca. Tak, nadal na nim siedzimy, a już doszliśmy do krawędzi przepaści. Do tej pory wystarczał nam LocalExecutor, ale teraz nadszedł czas, aby rozszerzyć go o co najmniej jednego pracownika i będziemy musieli ciężko pracować, aby przejść do CeleryExecutor. A w związku z tym, że można z nim pracować na jednej maszynie, nic nie stoi na przeszkodzie, aby użyć Celery nawet na serwerze, który „oczywiście nigdy nie wejdzie do produkcji, szczerze!”
- Nie używane wbudowane narzędzia:
- połączenia przechowywać dane uwierzytelniające usługi,
- Braki SLA odpowiadać na zadania, które nie wyszły na czas,
- xcom do wymiany metadanych (powiedziałem metadane!) między zadaniami dag.
- Nadużycie poczty. Cóż mogę powiedzieć? Ustawiono alerty dla wszystkich powtórzeń upadłych zadań. Teraz mój służbowy Gmail ma ponad 90 100 e-maili z Airflow, a kaganiec poczty internetowej odmawia odebrania i usunięcia więcej niż XNUMX na raz.
Więcej pułapek:
Więcej narzędzi do automatyzacji
Abyśmy mogli jeszcze bardziej pracować głową, a nie rękami, Airflow przygotował dla nas to:
- - nadal posiada status Eksperymentalisty, co nie przeszkadza mu w pracy. Dzięki niemu możesz nie tylko uzyskać informacje o dniach i zadaniach, ale także zatrzymać/rozpocząć dzień, utworzyć bieg DAG lub pulę.
- - wiele narzędzi jest dostępnych za pośrednictwem wiersza poleceń, które są nie tylko niewygodne w użyciu za pośrednictwem WebUI, ale generalnie są nieobecne. Na przykład:
backfillpotrzebne do ponownego uruchomienia instancji zadań.
Na przykład analitycy przyszli i powiedzieli: „A ty, towarzyszu, masz bzdury w danych od 1 do 13 stycznia! Napraw to, napraw to, napraw to, napraw to!" A ty jesteś taką kuchenką:airflow backfill -s '2020-01-01' -e '2020-01-13' orders- Usługa podstawowa:
initdb,resetdb,upgradedb,checkdb. run, co pozwala uruchomić jedno zadanie instancji, a nawet ocenić wszystkie zależności. Co więcej, możesz go uruchomić przezLocalExecutor, nawet jeśli masz klaster selera.- Robi prawie to samo
test, tylko też w bazach nic nie pisze. connectionsumożliwia masowe tworzenie połączeń z powłoki.
- - raczej hardkorowy sposób interakcji, który jest przeznaczony dla wtyczek, a nie roi się w nim małymi rączkami. Ale kto powstrzyma nas przed pójściem do
/home/airflow/dags, uruchomićipythoni zacząć kombinować? Możesz na przykład wyeksportować wszystkie połączenia za pomocą następującego kodu:from airflow import settings from airflow.models import Connection fields = 'conn_id conn_type host port schema login password extra'.split() session = settings.Session() for conn in session.query(Connection).order_by(Connection.conn_id): d = {field: getattr(conn, field) for field in fields} print(conn.conn_id, '=', d) - Łączenie z metabazą danych Airflow. Nie polecam pisania do niego, ale uzyskiwanie stanów zadań dla różnych konkretnych metryk może być znacznie szybsze i łatwiejsze niż przez którykolwiek z interfejsów API.
Powiedzmy, że nie wszystkie nasze zadania są idempotentne, ale czasami mogą spaść i jest to normalne. Ale kilka blokad jest już podejrzanych i trzeba by to sprawdzić.
Strzeż się SQLa!
WITH last_executions AS ( SELECT task_id, dag_id, execution_date, state, row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) AS rn FROM public.task_instance WHERE execution_date > now() - INTERVAL '2' DAY ), failed AS ( SELECT task_id, dag_id, execution_date, state, CASE WHEN rn = row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) THEN TRUE END AS last_fail_seq FROM last_executions WHERE state IN ('failed', 'up_for_retry') ) SELECT task_id, dag_id, count(last_fail_seq) AS unsuccessful, count(CASE WHEN last_fail_seq AND state = 'failed' THEN 1 END) AS failed, count(CASE WHEN last_fail_seq AND state = 'up_for_retry' THEN 1 END) AS up_for_retry FROM failed GROUP BY task_id, dag_id HAVING count(last_fail_seq) > 0
referencje
No i oczywiście pierwsze dziesięć linków z wydania Google to zawartość folderu Airflow z moich zakładek.
- - oczywiście musimy zacząć od biura. dokumentacji, ale kto czyta instrukcje?
- - Cóż, przynajmniej przeczytaj rekomendacje twórców.
- - sam początek: interfejs użytkownika na zdjęciach
- - podstawowe pojęcia są dobrze opisane, jeśli (nagle!) czegoś ode mnie nie zrozumiałeś.
- - krótki przewodnik dotyczący konfiguracji klastra Airflow.
- - prawie ten sam ciekawy artykuł, może poza większym formalizmem i mniejszą liczbą przykładów.
- — o współpracy z Celery.
- - o idempotencji zadań, ładowaniu po ID zamiast daty, transformacji, strukturze plików i innych ciekawostkach.
- - zależności zadań i Trigger Rule, o których wspomniałem tylko mimochodem.
- - jak przezwyciężyć niektóre „prace zgodnie z przeznaczeniem” w harmonogramie, załadować utracone dane i nadać priorytet zadaniom.
- — przydatne zapytania SQL do metadanych Airflow.
- - jest przydatna sekcja dotycząca tworzenia niestandardowego czujnika.
- — ciekawa krótka notatka o budowaniu infrastruktury na AWS for Data Science.
- - często popełniane błędy (kiedy ktoś nadal nie czyta instrukcji).
- - uśmiechnij się, jak ludzie przechowują hasła, chociaż możesz po prostu użyć Connections.
- - niejawne przekazywanie DAG, wrzucanie kontekstu w funkcjach, znowu o zależnościach, a także o pomijaniu uruchamiania zadań.
- - o użyciu
default argumentsиparamsw szablonach, a także Zmienne i Połączenia. - - opowieść o tym, jak planista przygotowuje się do Airflow 2.0.
- - nieco nieaktualny artykuł o wdrażaniu naszego klastra w
docker-compose. - - zadania dynamiczne z wykorzystaniem szablonów i przekazywania kontekstu.
- — standardowe i niestandardowe powiadomienia pocztą i Slackiem.
- - Zadania rozgałęziające, makra i XCom.
Oraz linki użyte w artykule:
- - symbole zastępcze dostępne do użycia w szablonach.
- — Częste błędy podczas tworzenia dagów.
- Do
docker-composedo eksperymentowania, debugowania i nie tylko. - — Opakowanie Pythona dla Telegram REST API.
Źródło: www.habr.com
