

Więc zbierasz dane metryczne. Tak jak my. Gromadzimy również dane metryczne. Oczywiście, że są niezbędne w biznesie. Dzisiaj opowiemy Wam o pierwszym ogniwie naszego systemu monitoringu – serwerze agregującym zgodnym ze statsd , dlaczego ją napisaliśmy i dlaczego porzuciliśmy Brubecka.
Z naszych poprzednich artykułów (, ) możesz się dowiedzieć, że do pewnego czasu zbieraliśmy tagi używając Jest napisany w języku C. Jest tak prosty w obsłudze jak mysz (co jest ważne, gdy chcesz się do czegoś przyczynić) i, co najważniejsze, bez problemu obsługuje naszą szczytową liczbę 2 milionów metryk na sekundę (MPS). W dokumentacji podano obsługę 4 milionów MPS (gwiazdka). Oznacza to, że otrzymasz podaną wartość, jeśli poprawnie skonfigurujesz sieć. Linux(Nie wiemy, ile MPS można uzyskać, jeśli sieć pozostanie taka, jaka jest.) Pomimo tych zalet mieliśmy kilka poważnych skarg na firmę brubeck.
Roszczenie 1. Github, twórca projektu, zaprzestał jego wspierania: publikowania poprawek i poprawek, akceptowania naszych żądań i (nie tylko naszych) żądań zmian. W ostatnich miesiącach (gdzieś tak od lutego-marca 2018 r.) aktywność została wznowiona, ale wcześniej przez prawie 2 lata panował całkowity spokój. Ponadto projekt jest w trakcie realizacji , co może stać się poważną przeszkodą we wdrażaniu nowych funkcji.
Roszczenie 2. Dokładność obliczeń. Brubeck zbiera łącznie 65536 wartości do agregacji. W naszym przypadku, w przypadku niektórych metryk, w trakcie okresu agregacji (30 sek.) może zostać zebranych znacznie więcej wartości (1 527 392 w szczycie). W wyniku tego pobierania próbek wartości maksymalne i minimalne okazują się bezużyteczne. Na przykład tak:
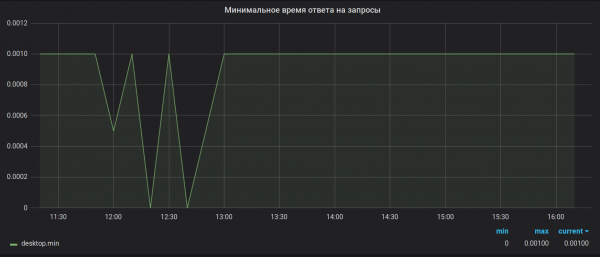
Tak jak było
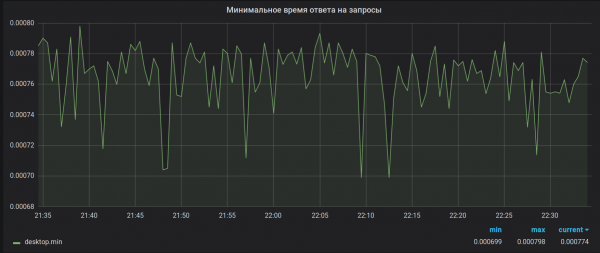
Jak powinno być
Z tego samego powodu kwoty te są na ogół obliczane nieprawidłowo. Dodajmy do tego błąd związany z przepełnieniem 32-bitowej liczby zmiennoprzecinkowej, który zazwyczaj powoduje błąd segmentacji serwera po otrzymaniu pozornie nieszkodliwej metryki, a staje się on zupełnie doskonały. Nawiasem mówiąc, błąd ten nadal nie został naprawiony.
Oraz, w końcu, Roszczenie X. W chwili pisania tego tekstu jesteśmy gotowi zaprezentować go wszystkim 14 mniej lub bardziej działającym implementacjom statsd, jakie udało nam się znaleźć. Wyobraźmy sobie, że jakaś indywidualna infrastruktura rozrosła się tak bardzo, że akceptowanie 4 milionów MPS już nie jest wystarczające. Albo może jeszcze się nie rozwinęły, ale wskaźniki są już dla Ciebie tak ważne, że nawet krótkie, 2-3-minutowe spadki na wykresach mogą stać się krytyczne i wywołać u menedżerów napady nieprzezwyciężalnej depresji. Ponieważ leczenie depresji jest zadaniem niewdzięcznym, potrzebne są rozwiązania techniczne.
Po pierwsze, odporność na błędy, aby nagły problem z serwerem nie wywołał w biurze psychiatrycznej apokalipsy zombie. Po drugie, skalowalność, dzięki której serwer może obsłużyć ponad 4 miliony MPS bez konieczności głębokiej analizy stosu sieciowego. Linux i spokojnie rosną „na szerokość” do wymaganego rozmiaru.
Ponieważ dysponowaliśmy pewnym marginesem skalowalności, postanowiliśmy zacząć od odporności na błędy. „O! Tolerancja błędów! „To proste, damy radę” — pomyśleliśmy i uruchomiliśmy dwa serwery, uruchamiając kopię brubecka na każdym z nich. Aby to zrobić, musieliśmy skopiować ruch z metrykami do obu serwerów, a nawet napisać dla tego . Rozwiązaliśmy w ten sposób problem tolerancji błędów, ale... nie za dobrze. Na początku wszystko wydawało się świetne: każdy brubeck zbierał własną wersję agregacji, zapisywał dane do Graphite raz na 30 sekund, nadpisując stary interwał (odbywa się to po stronie Graphite). Jeśli jeden serwer ulegnie awarii, zawsze mamy drugi, który zawiera własną kopię zagregowanych danych. Ale pojawia się problem: jeśli serwer ulegnie awarii, na wykresach pojawi się „piła”. Dzieje się tak, ponieważ 30-sekundowe interwały Brubecka nie są zsynchronizowane i w momencie upadku żaden z nich nie zostaje nadpisany. To samo dzieje się, gdy uruchamiany jest drugi serwer. Jest całkiem znośnie, ale chcę czegoś lepszego! Problem skalowalności również nie zniknął. Wszystkie dane pomiarowe nadal „kierują się” do jednego serwera, dlatego jesteśmy ograniczeni do tych samych 2–4 milionów MPS, w zależności od obciążenia sieci.
Jeśli zastanowisz się chwilę nad problemem i jednocześnie odgarniesz śnieg, do głowy może przyjść oczywisty pomysł: potrzebujesz pliku statsd, który może działać w trybie rozproszonym. Czyli taki, w którym wdrożono synchronizację między węzłami za pomocą czasu i metryk. „Oczywiście, takie rozwiązanie prawdopodobnie już istnieje” – powiedzieliśmy i udaliśmy się do Google…. I nic nie znaleźli. Przejrzawszy dokumentację różnych statystyk ( od 11.12.2017 r. nie znaleźliśmy absolutnie niczego. Najwyraźniej ani twórcy, ani użytkownicy tych rozwiązań nie natknęli się jeszcze na TAKĄ liczbę metryk, w przeciwnym razie na pewno by coś wymyślili.
I wtedy przypomnieliśmy sobie o „zabawkowym” statsd — bioyino, którego napisaliśmy na hackathonie „just for fun” (nazwa projektu została wygenerowana przez skrypt przed rozpoczęciem hackathonu) i zdaliśmy sobie sprawę, że pilnie potrzebujemy własnego statsd. Po co?
- ponieważ na świecie jest zbyt mało klonów statystycznych,
- ponieważ możliwe jest zapewnienie pożądanej lub zbliżonej do pożądanej odporności na błędy i skalowalności (w tym synchronizacji zagregowanych metryk między serwerami i rozwiązania problemu konfliktów podczas wysyłania),
- ponieważ możesz obliczyć wskaźniki dokładniej niż Brubeck,
- ponieważ możesz samodzielnie zebrać bardziej szczegółowe statystyki, których Brubeck praktycznie nam nie dostarczył,
- ponieważ miałem okazję zaprogramować własną, rozproszoną aplikację o wysokiej wydajności, która nie powtarzałaby całkowicie architektury innej takiej aplikacji o wysokiej wydajności... cóż, rozumiesz.
Na czym pisać? Oczywiście w Rust. Dlaczego?
- ponieważ istniał już prototyp rozwiązania,
- ponieważ autor artykułu znał już wtedy Rusta i chciał napisać w nim coś na potrzeby produkcji z możliwością opublikowania w open-source,
- ponieważ języki z GC nie są dla nas odpowiednie ze względu na charakter odbieranego ruchu (prawie w czasie rzeczywistym), a przerwy w GC są praktycznie nie do przyjęcia,
- ponieważ potrzebujemy maksymalnej wydajności porównywalnej z C
- ponieważ Rust oferuje nam nieustraszoną współbieżność, a gdybyśmy zaczęli pisać go w C/C++, otrzymalibyśmy nawet więcej niż brubeck, luki w zabezpieczeniach, przepełnienia bufora, wyścigi warunków i inne straszne słowa.
Pojawił się również argument przeciwko Rustowi. Firma nie miała doświadczenia w tworzeniu projektów w języku Rust i teraz również nie planujemy używać go w głównym projekcie. Istniały więc poważne obawy, że nic z tego nie wyjdzie, ale postanowiliśmy zaryzykować i spróbować.
Czas mijał…
W końcu, po kilku nieudanych próbach, ukończono pierwszą działającą wersję. Co się stało? Oto jak to wyszło.
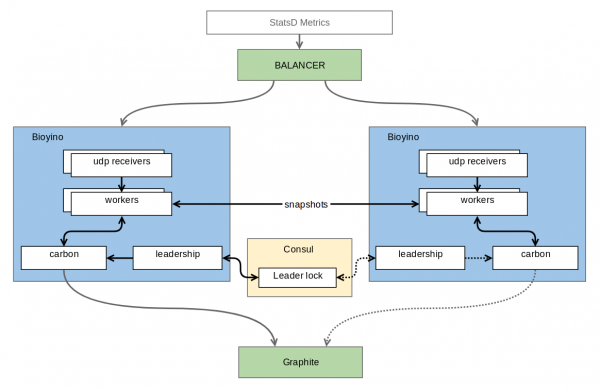
Każdy węzeł otrzymuje własny zestaw metryk i je gromadzi, nie agregując metryk dla tych typów, dla których do końcowej agregacji wymagany byłby pełny zestaw. Węzły są połączone ze sobą za pomocą pewnego rozproszonego protokołu blokady, który pozwala wybrać spośród nich ten jedyny (tu płakaliśmy), który jest godny wysyłania metryk do Wielkiego. W chwili obecnej problem ten rozwiązywany jest za pomocą , ale w przyszłości ambicje autora sięgają Tratwa, gdzie najbardziej godnym będzie oczywiście węzeł będący liderem konsensusu. Oprócz konsensusu, węzły dość często (domyślnie raz na sekundę) wysyłają swoim sąsiadom te części wstępnie zagregowanych metryk, które udało im się zebrać w ciągu danej sekundy. Okazuje się, że skalowalność i odporność na błędy zostają zachowane — każdy węzeł nadal przechowuje pełen zestaw metryk, ale metryki są wysyłane w formie zagregowanej, przez TCP i kodowane w protokole binarnym, więc koszty duplikacji są znacznie niższe w porównaniu z UDP. Mimo dość dużej liczby przychodzących metryk, akumulacja wymaga bardzo mało pamięci i jeszcze mniej mocy obliczeniowej procesora. W przypadku naszych wysoce kompresowalnych metryk jest to zaledwie kilkadziesiąt megabajtów danych. Dodatkową zaletą jest brak zbędnego przepisywania danych w Graphite, co miało miejsce w przypadku Burbecka.
Pakiety UDP z metrykami są nierównoważone między węzłami w sprzęcie sieciowym za pośrednictwem prostej metody Round Robin. Oczywiście sprzęt sieciowy nie analizuje zawartości pakietów i dlatego może obsłużyć znacznie więcej niż 4 mln pakietów na sekundę, nie wspominając o metrykach, o których nie ma pojęcia. Biorąc pod uwagę, że dane nie są dostarczane osobno w każdym pakiecie, nie przewidujemy żadnych problemów z wydajnością w tym obszarze. Jeżeli serwer ulegnie awarii, urządzenie sieciowe szybko (w ciągu 1-2 sekund) wykryje ten fakt i usunie uszkodzony serwer z listy. Dzięki temu węzły pasywne (czyli niebędące liderami) można włączać i wyłączać praktycznie bez zauważalnych spadków na wykresach. Najwięcej, co tracimy, to niektóre dane pomiarowe dostarczone w ostatniej chwili. Nagła utrata lub zmiana lidera nadal spowoduje niewielką anomalię (30-sekundowy interwał nadal będzie niezsynchronizowany), ale jeśli istnieje komunikacja między węzłami, problemy te można zminimalizować, na przykład wysyłając pakiety synchronizacyjne.
Kilka słów o strukturze wewnętrznej. Aplikacja jest oczywiście wielowątkowa, jednak architektura wątków różni się od tej zastosowanej w brubeck. Strumienie w systemie Brubeck są identyczne - każdy z nich odpowiada zarówno za zbieranie informacji, jak i ich agregowanie. W bioyino pracownicy dzielą się na dwie grupy: tych, którzy odpowiadają za sieć i tych, którzy odpowiadają za agregację. Podział ten umożliwia bardziej elastyczne zarządzanie aplikacjami w zależności od rodzaju metryk: tam, gdzie wymagana jest intensywna agregacja, można dodać agregatory; jeśli ruch sieciowy jest duży, możesz dodać liczbę przepływów sieciowych. W tej chwili pracujemy na naszych serwerach w 8 strumieniach sieciowych i 4 agregacyjnych.
Część zliczająca (agregująca) jest dość nudna. Bufory wypełnione przepływami sieciowymi są rozdzielane pomiędzy przepływy zliczające, gdzie są następnie analizowane i agregowane. Na żądanie metryki są wysyłane do innych węzłów. Wszystko to, łącznie z przesyłaniem danych między węzłami i pracą z Consul, odbywa się asynchronicznie i działa w ramach .
Znacznie więcej problemów w trakcie rozwoju sprawiała część sieciowa odpowiedzialna za odbiór danych pomiarowych. Głównym celem rozdzielenia przepływów sieciowych na oddzielne jednostki było skrócenie czasu, jaki przepływ spędza nie do odczytu danych z gniazda. Opcje wykorzystujące asynchroniczny protokół UDP i zwykły recvmsg szybko odeszły w zapomnienie: pierwsza opcja pochłaniała zbyt dużo zasobów procesora użytkownika na przetwarzanie zdarzeń, druga – zbyt wiele przełączeń kontekstu. Dlatego jest teraz używany z dużymi buforami (a bufory, panowie oficerowie, to nie byle co!). Wsparcie dla zwykłego protokołu UDP pozostawiono na wypadek braku obciążenia, gdy recvmmsg nie jest potrzebne. W trybie wielokomunikacyjnym można osiągnąć najważniejsze: w zdecydowanej większości przypadków przepływ sieciowy czyści kolejkę systemu operacyjnego — odczytuje dane z gniazda i przesyła je do bufora przestrzeni użytkownika, tylko okazjonalnie przełączając się, aby przekazać wypełniony bufor agregatorom. Kolejka w gnieździe praktycznie się nie kumuluje, liczba utraconych pakietów praktycznie się nie zwiększa.
Operacja
Domyślnie rozmiar bufora jest dość duży. Jeśli nagle zdecydujesz się na samodzielne wypróbowanie serwera, może się okazać, że po wysłaniu niewielkiej liczby metryk, nie dotrą one do Graphite, pozostając w buforze przepływu sieciowego. Aby pracować z mniejszą liczbą metryk, należy ustawić mniejsze wartości w konfiguracji bufsize i task-queue-size.
Na koniec kilka wykresów dla miłośników wykresów.
Statystyki dotyczące liczby metryk przychodzących dla każdego serwera: ponad 2 miliony MPS.
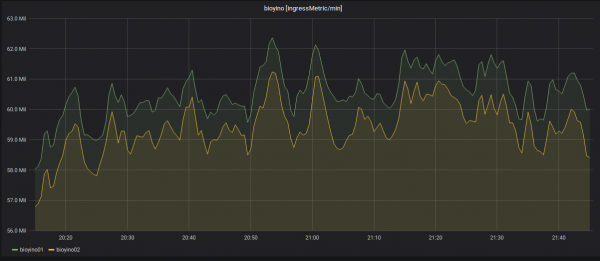
Wyłączenie jednego z węzłów i redystrybucja przychodzących metryk.
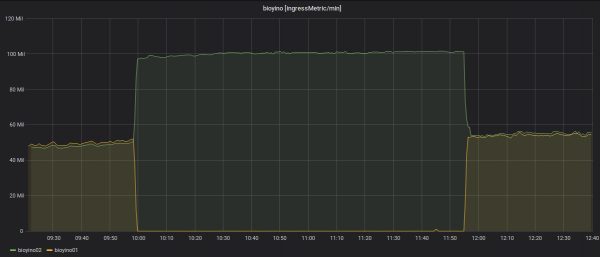
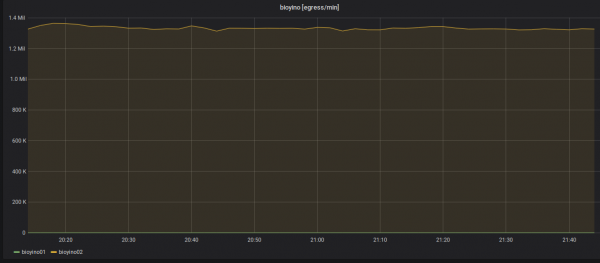
Statystyki danych wychodzących: zawsze wysyła tylko jeden węzeł — boss raidu.
Statystyki pracy każdego węzła, uwzględniające błędy w różnych modułach systemu.
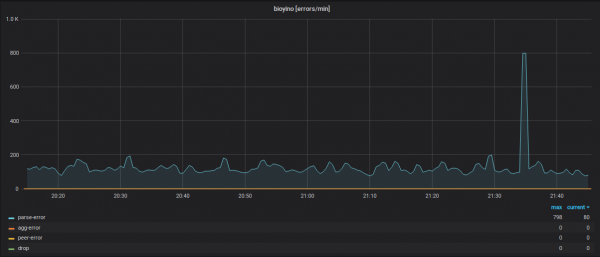
Szczegóły metryk przychodzących (nazwy metryk są ukryte).
Co planujemy dalej z tym wszystkim zrobić? Oczywiście, pisz kod, k...! Projekt pierwotnie planowano jako projekt typu open source i taki pozostanie przez cały czas jego trwania. Nasze najbliższe plany obejmują przejście na własną wersję Raft, zmianę protokołu peer-to-peer na bardziej przenośny, wprowadzenie dodatkowych statystyk wewnętrznych, nowych typów metryk, naprawienie błędów i inne usprawnienia.
Oczywiście, zapraszamy wszystkich chętnych do pomocy w rozwijaniu projektu: twórzcie PR, zgłaszajcie problemy, będziemy reagować, udoskonalać się itd., jeśli będzie to możliwe.
To tyle, ludzie, jak to mówią, kupujcie nasze słonie!

Źródło: www.habr.com
