

Sieć semantyczna i powiązane dane są jak przestrzeń kosmiczna: nie ma tam życia. Pojechać tam na mniej więcej długi okres czasu… no cóż, nie wiem, co Ci mówili w dzieciństwie w odpowiedzi na „Chcę zostać astronautą”. Ale możesz obserwować, co dzieje się na Ziemi; O wiele łatwiej jest zostać astronomem-amatorem, a nawet profesjonalistą.
W artykule skupimy się na najnowszych, nie starszych niż kilka miesięcy, trendach ze świata przechowywania RDF. Metafora w pierwszym akapicie została zainspirowana imponującym obrazem reklamowym pod rozcięciem.
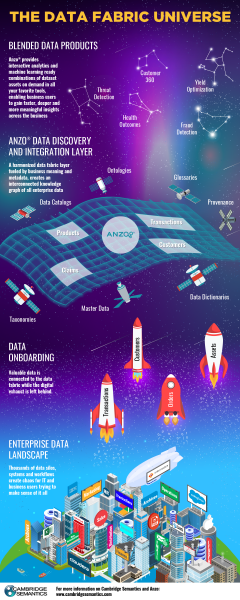
epicki obraz
I. GraphQL dla dostępu do RDF
że GraphQL twierdzi, że jest uniwersalnym językiem dostępu do baz danych. A co z możliwością dostępu za pomocą GraphQL do RDF?
Po wyjęciu z pudełka możliwość tę zapewniają:
- gwiezdny pies (, );
- Produkty TopQuadrant (, ).
Jeśli repozytorium nie daje takiej możliwości, jest to realizowane samodzielnie poprzez napisanie odpowiedniego „resolwera” (resolver). Dokonano tego na przykład we francuskim projekcie . Lub możesz już nic nie pisać, ale po prostu weź .
Z punktu widzenia ortodoksyjnego wyznawcy Semantic Web i Linked Data wszystko to jest oczywiście smutne, ponieważ wydaje się przeznaczone do integracji budowanych wokół kolejnego silosu danych, a nie odpowiednich platform (oczywiście magazynów RDF) .
Wrażenia z porównania GraphQL ze SPARQL są dwojakie.
- Z jednej strony GraphQL wygląda jak daleki krewny SPARQL: rozwiązuje typowy dla REST problem ponownej selekcji i wielokrotnych zapytań – bez których prawdopodobnie nie dałoby się język zapytań, przynajmniej w sieci;
- Z drugiej strony sztywny schemat GraphQL zaburza. W związku z tym jego „introspektywność” wydaje się być bardzo ograniczona w porównaniu z pełną zwrotnością RDF. I nie ma odpowiednika ścieżek właściwości, więc nie jest nawet jasne, dlaczego jest to „Wykres-”.
II. Adaptery dla MongoDB
Trend komplementarny do poprzedniego.
- teraz w Stardogu - w szczególności wszystkie na tym samym GraphQL - skonfigurować wyświetlanie danych MongoDB na wirtualnych wykresach RDF;
- GraphDB ma ostatnio wstaw do fragmentów SPARQL w zapytaniu MongoDB.
Mówiąc szerzej o adapterach do źródeł JSON, które pozwalają mniej więcej „w locie” reprezentować JSON zapisany w tych źródłach jako RDF, to możemy też od dłuższego czasu przywoływać istniejący które można regulować , do Apache Jena.
Podsumowując dwa pierwsze trendy, można stwierdzić, że repozytoria RDF wykazują pełną gotowość do integracji i funkcjonowania w warunkach „multiple storage” (poliglotowa persystencja). Wiadomo jednak, że ten ostatni już dawno wyszedł z mody i trzeba go zastąpić multimodelowanie. A co z multimodelowaniem w świecie przechowywania RDF?
Krótko mówiąc, nie ma mowy. Tematowi wielomodelowego DBMS chciałbym poświęcić osobny artykuł, ale póki co widać, że nie ma obecnie wielomodelowych DBMS „opartych” na modelu grafowym (RDF można uznać za jego odmianę). Niektóre małe multimodelowanie - wspierane przez magazyny RDF alternatywnego modelu wykresu LPG - zostaną omówione w .
III. OLTP vs. OLAP
Jednak ten sam Gartner że multimodelowanie jest przede wszystkim warunkiem sine qua non operowanie DBMS. Jest to zrozumiałe: w sytuacji „wielokrotnego przechowywania” główne problemy pojawiają się z transakcyjnością.
Ale gdzie w skali OLTP-OLAP są repozytoria RDF? Odpowiem tak: ani tam, ani tutaj. Aby wskazać, do czego są przeznaczone, potrzebny jest jakiś trzeci skrót. Jako opcję sugerowałbym OLIP — Przetwarzanie intelektualne online.
Jednak nadal:
- nie mniej ważne są mechanizmy integracji zaimplementowane w GraphDB z MongoDB obejść problemy z wydajnością zapisu;
- Stardog idzie jeszcze dalej i całkowicie silnik, ponownie w celu poprawy wydajności zapisu.
Teraz pozwólcie, że przedstawię na rynku nowego gracza. od twórców IBM Netezza i Amazon Redshift - . Na początku artykułu umieszczono zdjęcie z reklamy produktu na jego podstawie. AnzoGraph pozycjonuje się jako rozwiązanie GOLAP. Jak ci się podoba SPARQL z funkcjami okna? —
SELECT ?month (COUNT(?event) OVER (PARTITION BY ?month) AS ?events) WHERE { … }IV. RocksDB
Powyżej już do ogłoszenia Stardog 7 Beta, które mówiło, że Stardog zamierza używać RocksDB jako podstawowego systemu przechowywania – przechowywania klucz-wartość, rozwidlenia Facebooka dla Google LevelDB. Dlaczego warto mówić o pewnym trendzie?
Po pierwsze, sądząc po , nie tylko repozytoria RDF są „przeszczepiane” do RocksDB. Istnieją projekty wykorzystujące RocksDB jako silnik pamięci masowej w ArangoDB, MongoDB, MySQL i MariaDB, Cassandra.
Po drugie, projekty (czyli nie produkty) odpowiedniego tematu są tworzone w RocksDB.
Na przykład eBay używa RocksDB w dla twojego „wykresu wiedzy”. Swoją drogą, zabawnie się czyta: język zapytań na początku był rodzimym formatem, ale ostatnio zaczął przypominać SPARQL. Jak w żartach: bez względu na to, ile wykresów wiedzy zrobimy, i tak otrzymamy RDF.
Inny przykład - pojawił się kilka miesięcy temu . Przed jego wprowadzeniem dostęp do informacji historycznych Wikidata musiał być możliwy za pośrednictwem do standardowego API Mediawiki. Wiele jest teraz możliwe w czystym SPARQL. „Pod maską” jest też RocksDB. Nawiasem mówiąc, zrobił to WDHQS, wygląda na to, że osoba zaangażowana w import Freebase do Google Knowledge Graph.
V. Obsługa LPG
Przypomnę główną różnicę między wykresami LPG a wykresami RDF.
W LPG właściwości skalarne można dołączać do instancji krawędzi, podczas gdy w RDF można je dołączać tylko do „typów” krawędzi (ale nie tylko właściwości skalarne, ale także zwykłe łącza). To ograniczenie RDF w porównaniu do LPG jakaś technika modelowania. Ograniczenia LPG w porównaniu z RDF są trudniejsze do pokonania, ale wykresy LPG bardziej przypominają obrazki z podręcznika Harariego niż wykresy RDF, więc ludzie ich chcą.
Oczywiście zadanie „wspomagania LPG” dzieli się na dwie części:
- wprowadzanie zmian w modelu RDF umożliwiających symulowanie w nim konstrukcji LPG;
- wprowadzenie zmian w języku zapytań RDF umożliwiających dostęp do danych w tym zmodyfikowanym modelu lub implementacja możliwości zapytania tego modelu w popularnych językach zapytań LPG.
V.1. Model danych
Istnieje kilka możliwych podejść.
V.1.1. własność singletona
Najbardziej dosłownym podejściem do harmonizacji RDF i LPG jest prawdopodobnie :
- Zamiast na przykład predykatu
:isMarriedToużywane są predykaty:isMarriedTo1,:isMarriedTo2itd. - Predykaty te stają się następnie podmiotami nowych trojaczków:
:isMarriedTo1 :since "2013-09-13"^^xsd:dateitd. - Połączenie tych wystąpień predykatów ze wspólnym predykatem jest ustalane przez trójki formy
:isMarriedTo1 rdf:singletonPropertyOf :isMarriedTo. - Oczywiście,
rdf:singletonPropertyOf rdfs:subPropertyOf rdf:type, ale zastanów się, dlaczego nie powinieneś po prostu pisać:isMarriedTo1 rdf:type :isMarriedTo.
Zadanie „wsparcia LPG” jest tutaj rozwiązane na poziomie RDFS. Decyzja taka wymaga umieszczenia w stosownym . Niektóre repozytoria RDF obsługujące dołączanie konsekwencji mogą wymagać pewnych zmian, ale na razie Singleton Property można traktować jako kolejną technikę modelowania.
V.1.2. Reifikacja wykonana dobrze
Mniej naiwne podejście wynika z uświadomienia sobie, że instancje właściwości są doskonale tworzone przez trójki. Będąc w stanie mówić o trojaczkach, możemy również mówić o instancjach własności.
Najbardziej solidnym z tych podejść jest inaczej RDR, w trzewiach Blazegrapha. To od początku dla mnie i AnzoGraph. O solidności podejścia decyduje fakt, że w jego ramach odpowiednie zmiany w . Sprawa jest jednak niezwykle prosta. W serializacji RDF Turtle możesz teraz napisać coś takiego:
<<:bob :isMarriedTo :alice>> :since "2013-09-13"^^xsd:date .V.1.3. Inne podejścia
Nie możesz zawracać sobie głowy formalną semantyką, ale po prostu weź pod uwagę, że trójki mają pewne identyfikatory, którymi są oczywiście URI, i komponuj nowe trójki z tymi URI. Pozostaje tylko dać dostęp do tych URI w SPARQL. Więc gwiezdny pies.
w allegrografie w sposób pośredni. Wiadomo, że identyfikatory trójek w Allegrograph , ale po zaimplementowaniu potrójnych atrybutów nie wystają. Jednak nawet semantyka formalna jest bardzo daleko. Warto zauważyć, że atrybuty trypletowe nie są identyfikatorami URI, a wartości tych atrybutów również mogą być tylko literałami. Zwolennicy LPG dostają dokładnie to, czego chcieli. W specjalnie wymyślonym formacie NQX przykład podobny do powyższego dla RDF* wygląda następująco:
:bob :marriedTo :alice {"since" : "2013-09-13"}V.2. Języki zapytań
Wspierając LPG w taki czy inny sposób na poziomie modelu, musisz umożliwić odpytywanie danych w takim modelu.
- Obsługa zapytań Blazegraph dla RDF* и . Zapytanie SPARQL* wygląda następująco:
SELECT * { <<:bob :isMarriedTo ?wife>> :since ?since }- Anzograf obsługuje również i zamierza wspierać , język zapytań w Neo4j.
- Stardog utrzymuje swoje własne SPARQL i Zły duch. Możesz uzyskać identyfikator URI trypletu i „meta-informacje” w SPARQL, używając czegoś takiego:
SELECT * {
BIND (stardog:identifier(:bob, :isMarriedTo, ?wife) AS ?id)
?id :since ?since
}- Allegrograph obsługuje również własne SPARQL:
SELECT * { ("since" ?since) franz:attributesNameValue ( :bob :marriedTo ?wife ) }Nawiasem mówiąc, GraphDB obsługiwał kiedyś Tinkerpop/Gremlin bez obsługi LPG, ale przestało to działać w wersji 8.0 lub 8.1.
VI. Zaostrzenie licencji
Nie dodano ostatnio żadnych dodatków do skrzyżowania zestawów „potrójny sklep z wyboru” i „potrójny sklep z otwartym kodem źródłowym”. Nowe sklepy RDF typu open source są dalekie od dobrego wyboru do codziennego użytku, a nowe sklepy RDF, z których chciałbym korzystać (jak AnzoGraph), są źródłami zamkniętymi. Można raczej mówić o spadkach...
Oczywiście wcześniej otwarte oprogramowanie nie jest zamknięte, ale niektóre repozytoria open source stopniowo przestają być uważane za warte wyboru. Virtuoso, które ma edycję open source, moim zdaniem tonie w błędach. Blazegraph kupiony przez AWS i stanowiący podstawę Amazon Neptune; teraz nie jest jasne, czy będzie jeszcze co najmniej jedno wydawnictwo. Została tylko Jenna...
Jeśli open source nie jest bardzo ważne, ale po prostu chcesz spróbować, wszystko jest również mniej różowe niż wcześniej. Na przykład:
- Gwiezdny Pies rozpowszechniać darmową wersję (jednak okres próbny zwykłej wersji podwoił się);
- в , gdzie wcześniej można było wybrać bezpłatny plan podstawowy, zawiesił rejestrację nowych użytkowników.
Ogólnie rzecz biorąc, przestrzeń staje się coraz bardziej niedostępna dla zwykłego laika IT, jej rozwój staje się udziałem korporacji.
Źródło: www.habr.com
