

W tym poście chcielibyśmy podzielić się ciekawym sposobem radzenia sobie z konfiguracją systemu rozproszonego.
Konfiguracja jest reprezentowana bezpośrednio w języku Scala w sposób bezpieczny dla typu. Szczegółowo opisano przykładową realizację. Omawiane są różne aspekty propozycji, w tym wpływ na ogólny proces rozwoju.
()
Wprowadzenie
Budowa solidnych systemów rozproszonych wymaga zastosowania poprawnej i spójnej konfiguracji na wszystkich węzłach. Typowym rozwiązaniem jest użycie tekstowego opisu wdrożenia (terraform, ansible lub coś podobnego) i automatycznie wygenerowanych plików konfiguracyjnych (często – dedykowanych dla każdego węzła/roli). Chcielibyśmy również używać tych samych protokołów i tych samych wersji na każdym komunikującym się węźle (w przeciwnym razie wystąpiłyby problemy z niekompatybilnością). W świecie JVM oznacza to, że przynajmniej biblioteka przesyłania wiadomości powinna być tej samej wersji na wszystkich węzłach komunikacyjnych.
A co z testowaniem systemu? Oczywiście przed przystąpieniem do testów integracyjnych powinniśmy przeprowadzić testy jednostkowe dla wszystkich komponentów. Aby móc ekstrapolować wyniki testów na środowisko wykonawcze, powinniśmy upewnić się, że wersje wszystkich bibliotek są identyczne zarówno w środowisku wykonawczym, jak i testowym.
Podczas uruchamiania testów integracyjnych często znacznie łatwiej jest mieć tę samą ścieżkę klas na wszystkich węzłach. Musimy się tylko upewnić, że podczas wdrażania używana jest ta sama ścieżka klas. (Możliwe jest użycie różnych ścieżek klas na różnych węzłach, ale trudniej jest przedstawić tę konfigurację i poprawnie ją wdrożyć.) Zatem dla uproszczenia rozważymy tylko identyczne ścieżki klas na wszystkich węzłach.
Konfiguracja ma tendencję do ewolucji wraz z oprogramowaniem. Zwykle używamy wersji, aby zidentyfikować różne
etapy ewolucji oprogramowania. Rozsądne wydaje się objęcie konfiguracji zarządzaniem wersjami i oznaczanie różnych konfiguracji pewnymi etykietami. Jeżeli w produkcji dostępna jest tylko jedna konfiguracja, możemy użyć pojedynczej wersji jako identyfikatora. Czasami możemy mieć wiele środowisk produkcyjnych. Dla każdego środowiska możemy potrzebować osobnej gałęzi konfiguracji. Zatem konfiguracje mogą być oznaczone gałęzią i wersją, aby jednoznacznie identyfikować różne konfiguracje. Każda etykieta i wersja gałęzi odpowiada pojedynczej kombinacji rozproszonych węzłów, portów, zasobów zewnętrznych i wersji bibliotek ścieżek klas w każdym węźle. Tutaj omówimy tylko pojedynczą gałąź i zidentyfikujemy konfiguracje za pomocą trójskładnikowej wersji dziesiętnej (1.2.3), w taki sam sposób, jak inne artefakty.
W nowoczesnych środowiskach pliki konfiguracyjne nie są już modyfikowane ręcznie. Zazwyczaj generujemy
pliki konfiguracyjne w czasie wdrażania i następnie. Można więc zapytać, dlaczego nadal używamy formatu tekstowego dla plików konfiguracyjnych? Realną opcją jest umieszczenie konfiguracji w jednostce kompilacji i skorzystanie z walidacji konfiguracji w czasie kompilacji.
W tym poście przeanalizujemy pomysł zachowania konfiguracji w skompilowanym artefakcie.
Kompilowalna konfiguracja
W tej sekcji omówimy przykład konfiguracji statycznej. Konfigurowane i wdrażane są dwie proste usługi - usługa echo i klient usługi echo. Następnie tworzone są dwa różne systemy rozproszone z obydwoma usługami. Jedna dotyczy konfiguracji z jednym węzłem, a druga dla konfiguracji z dwoma węzłami.
Typowy system rozproszony składa się z kilku węzłów. Węzły można zidentyfikować za pomocą pewnego typu:
sealed trait NodeId
case object Backend extends NodeId
case object Frontend extends NodeIdlub po prostu
case class NodeId(hostName: String)lub nawet
object Singleton
type NodeId = Singleton.typeWęzły te pełnią różne role, uruchamiają pewne usługi i powinny móc komunikować się z innymi węzłami za pomocą połączeń TCP/HTTP.
W przypadku połączenia TCP wymagany jest przynajmniej numer portu. Chcemy również mieć pewność, że klient i serwer komunikują się tym samym protokołem. Aby zamodelować połączenie pomiędzy węzłami zadeklarujmy następującą klasę:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])gdzie Port jest po prostu Int w dozwolonym zakresie:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]Wyrafinowane typy
See biblioteka. Krótko mówiąc, pozwala na dodanie ograniczeń czasu kompilacji do innych typów. W tym przypadku Int może mieć tylko 16-bitowe wartości, które mogą reprezentować numer portu. W przypadku tego podejścia konfiguracyjnego nie ma wymogu używania tej biblioteki. Po prostu wydaje się, że bardzo dobrze pasuje.
W przypadku HTTP (REST) możemy potrzebować także ścieżki usługi:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]]
case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)Typ fantomowy
Aby zidentyfikować protokół podczas kompilacji, używamy funkcji Scala polegającej na deklarowaniu argumentu typu Protocol którego nie używa się na zajęciach. To tzw typ fantomowy. W czasie wykonywania rzadko potrzebujemy instancji identyfikatora protokołu, dlatego go nie przechowujemy. Podczas kompilacji ten typ fantomowy zapewnia dodatkowe bezpieczeństwo typu. Nie możemy przekazać portu z nieprawidłowym protokołem.
Jednym z najczęściej używanych protokołów jest REST API z serializacją Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]gdzie RequestMessage to podstawowy typ wiadomości, które klient może wysyłać do serwera i ResponseMessage to wiadomość odpowiedzi z serwera. Oczywiście możemy stworzyć inne opisy protokołów, które określą protokół komunikacyjny z żądaną precyzją.
Na potrzeby tego wpisu użyjemy prostszej wersji protokołu:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]W tym protokole komunikat żądania jest dołączany do adresu URL, a komunikat odpowiedzi jest zwracany w postaci zwykłego ciągu znaków.
Konfigurację usługi można opisać nazwą usługi, zbiorem portów i pewnymi zależnościami. Istnieje kilka możliwych sposobów przedstawienia wszystkich tych elementów w Scali (na przykład HList, algebraiczne typy danych). Na potrzeby tego wpisu użyjemy wzoru ciasta i przedstawimy możliwe do połączenia elementy (moduły) jako cechy. (Wzorzec ciasta nie jest wymagany w przypadku tego kompilowalnego podejścia do konfiguracji. Jest to tylko jedna z możliwych implementacji tego pomysłu.)
Zależności można przedstawić za pomocą wzorca ciasta jako punktów końcowych innych węzłów:
type EchoProtocol[A] = SimpleHttpGetRest[A, A]
trait EchoConfig[A] extends ServiceConfig {
def portNumber: PortNumber = 8081
def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo")
def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort)
}Usługa Echo wymaga jedynie skonfigurowania portu. I deklarujemy, że ten port obsługuje protokół echa. Zauważ, że nie musimy w tym momencie określać konkretnego portu, ponieważ cecha pozwala na deklarację metod abstrakcyjnych. Jeśli użyjemy metod abstrakcyjnych, kompilator będzie wymagał implementacji w instancji konfiguracyjnej. Tutaj udostępniliśmy implementację (8081) i będzie używana jako wartość domyślna, jeśli pominiemy ją w konkretnej konfiguracji.
Możemy zadeklarować zależność w konfiguracji klienta usługi echo:
trait EchoClientConfig[A] {
def testMessage: String = "test"
def pollInterval: FiniteDuration
def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]]
}Zależność ma ten sam typ co echoService. W szczególności wymaga tego samego protokołu. Dlatego możemy być pewni, że jeśli połączymy te dwie zależności, będą one działać poprawnie.
Wdrażanie usług
Usługa potrzebuje funkcji do uruchomienia i bezpiecznego zamknięcia. (Możliwość zamknięcia usługi ma kluczowe znaczenie podczas testowania.) Ponownie istnieje kilka opcji określenia takiej funkcji dla danej konfiguracji (na przykład moglibyśmy użyć klas typów). W tym poście ponownie użyjemy wzoru ciasta. Możemy reprezentować usługę za pomocą cats.Resource który już zapewnia nawiasy i zwalnianie zasobów. Aby pozyskać zasób, powinniśmy podać konfigurację i kontekst wykonawczy. Zatem funkcja uruchamiania usługi może wyglądać następująco:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]]
trait ServiceImpl[F[_]] {
type Config
def resource(
implicit
resolver: AddressResolver[F],
timer: Timer[F],
contextShift: ContextShift[F],
ec: ExecutionContext,
applicative: Applicative[F]
): ResourceReader[F, Config, Unit]
}gdzie
Config— typ konfiguracji wymagany przez ten starter usługiAddressResolver— obiekt wykonawczy, który ma możliwość uzyskania rzeczywistych adresów innych węzłów (szczegóły czytaj dalej).
pochodzą inne typy cats:
F[_]— rodzaj efektu (w najprostszym przypadkuF[A]może być po prostu() => A. W tym poście użyjemycats.IO.)Reader[A,B]— jest mniej więcej synonimem funkcjiA => Bcats.Resource— ma sposoby zdobywania i uwalnianiaTimer— pozwala spać/odmierzać czasContextShift- analogExecutionContextApplicative— opakowanie działających funkcji (prawie monada) (możemy w końcu zastąpić go czymś innym)
Za pomocą tego interfejsu możemy wdrożyć kilka usług. Na przykład usługa, która nic nie robi:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] {
type Config <: Any
def resource(...): ResourceReader[F, Config, Unit] =
Reader(_ => Resource.pure[F, Unit](()))
}(Patrz w przypadku wdrożeń innych usług — ,
oraz .)
Węzeł to pojedynczy obiekt, który uruchamia kilka usług (uruchomienie łańcucha zasobów umożliwia Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO]
with EchoServiceService
with EchoClientService
with FiniteDurationLifecycleServiceImpl
{
type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig
}Należy pamiętać, że w węźle określamy dokładny typ konfiguracji, jaki jest potrzebny temu węzłowi. Kompilator nie pozwoli nam zbudować obiektu (Cake) o niewystarczającym typie, ponieważ każda cecha usługi deklaruje ograniczenie Config typ. Nie będziemy również mogli uruchomić węzła bez zapewnienia pełnej konfiguracji.
Rozpoznawanie adresu węzła
Aby nawiązać połączenie potrzebujemy prawdziwego adresu hosta dla każdego węzła. Może być znany później niż inne części konfiguracji. Dlatego potrzebujemy sposobu na dostarczenie mapowania między identyfikatorem węzła a jego rzeczywistym adresem. To mapowanie jest funkcją:
case class NodeAddress[NodeId](host: Uri.Host)
trait AddressResolver[F[_]] {
def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]]
}Istnieje kilka możliwych sposobów implementacji takiej funkcji.
- Jeśli znamy rzeczywiste adresy przed wdrożeniem, podczas tworzenia instancji hostów węzłów, możemy wygenerować kod Scala z rzeczywistymi adresami, a następnie uruchomić kompilację (która sprawdza czas kompilacji, a następnie uruchamia zestaw testów integracyjnych). W tym przypadku nasza funkcja mapowania jest znana statycznie i można ją uprościć do czegoś takiego jak
Map[NodeId, NodeAddress]. - Czasami rzeczywiste adresy uzyskujemy dopiero w późniejszym momencie, kiedy węzeł jest faktycznie uruchomiony, lub nie mamy adresów węzłów, które jeszcze nie zostały uruchomione. W tym przypadku możemy mieć usługę wykrywania uruchamianą przed wszystkimi innymi węzłami, a każdy węzeł może ogłaszać swój adres w tej usłudze i subskrybować zależności.
- Jeśli możemy zmodyfikować
/etc/hosts, możemy użyć predefiniowanych nazw hostów (npmy-project-main-nodeorazecho-backend) i po prostu powiąż tę nazwę z adresem IP w czasie wdrażania.
W tym poście nie omawiamy tych przypadków bardziej szczegółowo. W rzeczywistości w naszym przykładzie zabawki wszystkie węzły będą miały ten sam adres IP — 127.0.0.1.
W tym poście rozważymy dwa układy systemów rozproszonych:
- Układ z jednym węzłem, w którym wszystkie usługi są umieszczone w jednym węźle.
- Układ dwóch węzłów, w którym usługa i klient znajdują się w różnych węzłach.
Konfiguracja dla układ jest następujący:
Konfiguracja pojedynczego węzła
object SingleNodeConfig extends EchoConfig[String]
with EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
case object Singleton // identifier of the single node
// configuration of server
type NodeId = Singleton.type
def nodeId = Singleton
/** Type safe service port specification. */
override def portNumber: PortNumber = 8088
// configuration of client
/** We'll use the service provided by the same host. */
def echoServiceDependency = echoService
override def testMessage: UrlPathElement = "hello"
def pollInterval: FiniteDuration = 1.second
// lifecycle controller configuration
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9.
}Tutaj tworzymy pojedynczą konfigurację, która rozszerza zarówno konfigurację serwera, jak i klienta. Konfigurujemy także kontroler cyklu życia, który zwykle kończy później pracę klienta i serwera lifetime mija przerwa.
Ten sam zestaw implementacji i konfiguracji usług można wykorzystać do utworzenia układu systemu z dwoma oddzielnymi węzłami. Musimy po prostu tworzyć z odpowiednimi usługami:
Konfiguracja dwóch węzłów
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig
{
type NodeId = NodeIdImpl
def nodeId = NodeServer
override def portNumber: PortNumber = 8080
}
object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
// NB! dependency specification
def echoServiceDependency = NodeServerConfig.echoService
def pollInterval: FiniteDuration = 1.second
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9.
def testMessage: String = "dolly"
}Zobacz jak określamy zależność. Wspominamy o usłudze świadczonej przez drugi węzeł jako o zależności od bieżącego węzła. Typ zależności jest sprawdzany, ponieważ zawiera typ fantomowy opisujący protokół. W czasie wykonywania będziemy mieli poprawny identyfikator węzła. Jest to jeden z ważnych aspektów proponowanego podejścia konfiguracyjnego. Daje nam możliwość ustawienia portu tylko raz i upewnienia się, że odwołujemy się do właściwego portu.
Implementacja dwóch węzłów
Do tej konfiguracji używamy dokładnie tych samych implementacji usług. Żadnych zmian. Tworzymy jednak dwie różne implementacje węzłów, które zawierają inny zestaw usług:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl {
type Config = EchoConfig[String] with SigTermLifecycleConfig
}
object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl {
type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig
}Pierwszy węzeł implementuje serwer i wymaga jedynie konfiguracji po stronie serwera. Drugi węzeł implementuje klienta i wymaga innej części konfiguracji. Obydwa węzły wymagają określonej specyfikacji okresu istnienia. Na potrzeby tego węzła usługi pocztowej będzie on miał nieskończony czas życia, który można zakończyć SIGTERM, podczas gdy klient echo zakończy działanie po skonfigurowanym skończonym czasie trwania. Zobacz .
Ogólny proces rozwoju
Zobaczmy, jak to podejście zmienia sposób, w jaki pracujemy z konfiguracją.
Konfiguracja jako kod zostanie skompilowana i wygeneruje artefakt. Rozsądne wydaje się oddzielenie artefaktów konfiguracyjnych od innych artefaktów kodu. Często możemy mieć wiele konfiguracji w oparciu o tę samą bazę kodu. I oczywiście możemy mieć wiele wersji różnych gałęzi konfiguracyjnych. W konfiguracji możemy wybrać poszczególne wersje bibliotek i pozostanie to stałe przy każdym wdrożeniu tej konfiguracji.
Zmiana konfiguracji staje się zmianą kodu. Dlatego powinno być objęte tym samym procesem zapewniania jakości:
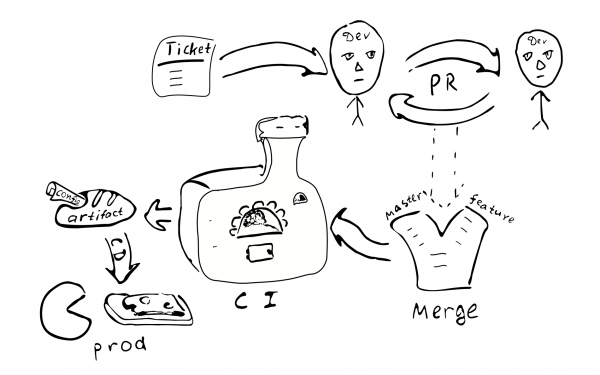
Zgłoszenie -> PR -> recenzja -> połączenie -> ciągła integracja -> ciągłe wdrażanie
Takie podejście ma następujące konsekwencje:
- Konfiguracja jest spójna dla konkretnej instancji systemu. Wygląda na to, że nie ma możliwości nieprawidłowego połączenia między węzłami.
- Nie jest łatwo zmienić konfigurację tylko w jednym węźle. Logowanie i zmiana niektórych plików tekstowych wydaje się nierozsądne. Zatem dryf konfiguracji staje się mniej możliwy.
- Drobne zmiany w konfiguracji nie są łatwe do wprowadzenia.
- Większość zmian konfiguracyjnych będzie podlegać temu samemu procesowi programowania i przejdzie przez pewien okres przeglądu.
Czy potrzebujemy osobnego repozytorium do konfiguracji produkcyjnej? Konfiguracja produkcyjna może zawierać poufne informacje, które chcielibyśmy trzymać poza zasięgiem wielu osób. Dlatego może warto zachować osobne repozytorium z ograniczonym dostępem, które będzie zawierać konfigurację produkcyjną. Konfigurację możemy podzielić na dwie części – jedną zawierającą najbardziej otwarte parametry produkcji i drugą zawierającą tajną część konfiguracji. Umożliwiłoby to większości programistów dostęp do zdecydowanej większości parametrów, jednocześnie ograniczając dostęp do naprawdę wrażliwych rzeczy. Łatwo to osiągnąć, używając cech pośrednich z domyślnymi wartościami parametrów.
Wariacje
Zobaczmy zalety i wady proponowanego podejścia w porównaniu z innymi technikami zarządzania konfiguracją.
Na początek wymienimy kilka alternatyw dla różnych aspektów proponowanego sposobu postępowania z konfiguracją:
- Plik tekstowy na maszynie docelowej.
- Scentralizowane przechowywanie klucz-wartość (np
etcd/zookeeper). - Komponenty podprocesu, które można ponownie skonfigurować/uruchomić bez ponownego uruchamiania procesu.
- Konfiguracja zewnętrznych artefaktów i kontrola wersji.
Plik tekstowy zapewnia pewną elastyczność w zakresie poprawek ad hoc. Administrator systemu może zalogować się do węzła docelowego, wprowadzić zmiany i po prostu ponownie uruchomić usługę. To może nie być tak dobre w przypadku większych systemów. Po zmianie nie pozostają żadne ślady. Zmiana nie jest przeglądana przez inną parę oczu. Ustalenie, co spowodowało tę zmianę, może być trudne. Nie zostało to przetestowane. Z perspektywy systemu rozproszonego administrator może po prostu zapomnieć o aktualizacji konfiguracji w jednym z pozostałych węzłów.
(Przy okazji, jeśli w końcu zajdzie potrzeba rozpoczęcia używania tekstowych plików konfiguracyjnych, będziemy musieli jedynie dodać parser + walidator, który mógłby wygenerować to samo Config type i to wystarczy, aby zacząć używać konfiguracji tekstowych. Pokazuje to również, że złożoność konfiguracji w czasie kompilacji jest nieco mniejsza niż złożoność konfiguracji tekstowych, ponieważ w wersji tekstowej potrzebujemy dodatkowego kodu.)
Scentralizowany magazyn klucz-wartość to dobry mechanizm dystrybucji metaparametrów aplikacji. Tutaj musimy pomyśleć o tym, co uważamy za wartości konfiguracyjne, a co to tylko dane. Biorąc pod uwagę funkcję C => A => B zwykle nazywamy rzadko zmieniającymi się wartościami C „konfiguracji”, przy często zmienianych danych A - wystarczy wprowadzić dane. Konfigurację należy podać do funkcji wcześniej niż dane A. Biorąc pod uwagę ten pomysł, możemy powiedzieć, że jest to oczekiwana częstotliwość zmian, która może posłużyć do odróżnienia danych konfiguracyjnych od samych danych. Ponadto dane zazwyczaj pochodzą z jednego źródła (użytkownik), a konfiguracja pochodzi z innego źródła (administrator). Radzenie sobie z parametrami, które można zmienić po procesie inicjalizacji, prowadzi do wzrostu złożoności aplikacji. W przypadku takich parametrów będziemy musieli zająć się mechanizmem dostarczania, analizą i walidacją oraz obsługą nieprawidłowych wartości. Dlatego, aby zmniejszyć złożoność programu, lepiej zmniejszyć liczbę parametrów, które mogą zmieniać się w czasie wykonywania (lub nawet całkowicie je wyeliminować).
Z perspektywy tego wpisu powinniśmy dokonać rozróżnienia pomiędzy parametrami statycznymi i dynamicznymi. Jeśli logika usługi wymaga rzadkich zmian niektórych parametrów w czasie wykonywania, wówczas możemy nazwać je parametrami dynamicznymi. W przeciwnym razie są one statyczne i można je skonfigurować przy użyciu proponowanego podejścia. W przypadku dynamicznej rekonfiguracji mogą być potrzebne inne podejścia. Na przykład części systemu mogą zostać zrestartowane z nowymi parametrami konfiguracyjnymi w podobny sposób, jak ponowne uruchomienie oddzielnych procesów systemu rozproszonego.
(Moim skromnym zdaniem należy unikać rekonfiguracji środowiska wykonawczego, ponieważ zwiększa to złożoność systemu.
Prostsze może być po prostu poleganie na obsłudze systemu operacyjnego przy ponownym uruchamianiu procesów. Chociaż nie zawsze jest to możliwe.)
Jednym z ważnych aspektów korzystania z konfiguracji statycznej, który czasami powoduje, że ludzie rozważają konfigurację dynamiczną (bez innych powodów), są przestoje usług podczas aktualizacji konfiguracji. Rzeczywiście, jeśli musimy wprowadzić zmiany w konfiguracji statycznej, musimy zrestartować system, aby nowe wartości zaczęły obowiązywać. Wymagania dotyczące przestojów są różne dla różnych systemów, więc może to nie być aż tak krytyczne. Jeśli jest to krytyczne, musimy zaplanować z wyprzedzeniem ponowne uruchomienie systemu. Moglibyśmy na przykład wdrożyć . W tym scenariuszu za każdym razem, gdy zachodzi potrzeba ponownego uruchomienia systemu, uruchamiamy równolegle nową instancję systemu, a następnie przełączamy na nią ELB, pozwalając staremu systemowi dokończyć obsługę istniejących połączeń.
A co z utrzymaniem konfiguracji wewnątrz wersjonowanego artefaktu lub na zewnątrz? Utrzymanie konfiguracji w artefakcie oznacza w większości przypadków, że konfiguracja ta przeszła ten sam proces zapewniania jakości, co inne artefakty. Można więc mieć pewność, że konfiguracja jest dobrej jakości i godna zaufania. Natomiast konfiguracja w oddzielnym pliku oznacza, że nie ma żadnych śladów tego, kto i dlaczego dokonał zmian w tym pliku. Czy to ważne? Wierzymy, że w przypadku większości systemów produkcyjnych lepiej mieć stabilną i wysokiej jakości konfigurację.
Wersja artefaktu pozwala dowiedzieć się, kiedy został utworzony, jakie zawiera wartości, jakie funkcje są włączone/wyłączone, kto był odpowiedzialny za dokonanie każdej zmiany w konfiguracji. Utrzymanie konfiguracji wewnątrz artefaktu może wymagać pewnego wysiłku i jest to wybór projektu.
Za I przeciw
W tym miejscu chcielibyśmy podkreślić niektóre zalety i omówić pewne wady proponowanego podejścia.
Zalety
Cechy kompilowalnej konfiguracji kompletnego systemu rozproszonego:
- Statyczna kontrola konfiguracji. Daje to wysoki poziom pewności, że konfiguracja jest poprawna, biorąc pod uwagę ograniczenia typu.
- Bogaty język konfiguracji. Zazwyczaj inne podejścia konfiguracyjne ograniczają się do co najwyżej podstawienia zmiennych.
Korzystając ze Scali, można skorzystać z szerokiej gamy funkcji językowych w celu usprawnienia konfiguracji. Na przykład możemy użyć cech, aby zapewnić wartości domyślne, obiektów, aby ustawić inny zakres, do którego możemy się odwołaćvals zdefiniowano tylko raz w zakresie zewnętrznym (DRY). Możliwe jest użycie sekwencji literałów lub instancji określonych klas (Seq,MapItp.). - DSL. Scala ma przyzwoite wsparcie dla twórców DSL. Można wykorzystać te funkcje do ustalenia języka konfiguracji, który będzie wygodniejszy i przyjazny dla użytkownika końcowego, tak aby ostateczna konfiguracja była przynajmniej czytelna dla użytkowników domeny.
- Integralność i spójność między węzłami. Jedną z korzyści posiadania konfiguracji całego systemu rozproszonego w jednym miejscu jest to, że wszystkie wartości są definiowane ściśle raz, a następnie ponownie wykorzystywane we wszystkich miejscach, gdzie są potrzebne. Wpisz także deklaracje bezpiecznego portu, aby we wszystkich możliwych poprawnych konfiguracjach węzły systemu mówiły tym samym językiem. Istnieją wyraźne zależności pomiędzy węzłami, co sprawia, że trudno zapomnieć o świadczeniu niektórych usług.
- Wysoka jakość zmian. Ogólne podejście polegające na przechodzeniu zmian konfiguracji przez normalny proces PR ustanawia wysokie standardy jakości również w konfiguracji.
- Jednoczesne zmiany konfiguracji. Ilekroć dokonamy jakichkolwiek zmian w konfiguracji, automatyczne wdrożenie gwarantuje, że wszystkie węzły zostaną zaktualizowane.
- Uproszczenie aplikacji. Aplikacja nie musi analizować i weryfikować konfiguracji oraz obsługiwać nieprawidłowych wartości konfiguracyjnych. Upraszcza to całe zastosowanie. (Pewien wzrost złożoności występuje w samej konfiguracji, ale jest to świadomy kompromis w stronę bezpieczeństwa.) Powrót do zwykłej konfiguracji jest całkiem prosty — wystarczy dodać brakujące elementy. Łatwiej jest zacząć od skompilowanej konfiguracji i odłożyć wdrożenie dodatkowych elementów na później.
- Wersjonowana konfiguracja. Ze względu na to, że zmiany konfiguracji przebiegają według tego samego procesu rozwojowego, w efekcie otrzymujemy artefakt z unikalną wersją. Pozwala nam to w razie potrzeby przełączyć konfigurację z powrotem. Możemy nawet wdrożyć konfigurację, która była używana rok temu i będzie działać dokładnie tak samo. Stabilna konfiguracja poprawia przewidywalność i niezawodność systemu rozproszonego. Konfiguracja jest ustalana w czasie kompilacji i nie można jej łatwo zmienić w systemie produkcyjnym.
- Modułowość. Proponowana struktura ma charakter modułowy, a moduły można łączyć na różne sposoby
obsługują różne konfiguracje (ustawienia/układy). W szczególności możliwe jest posiadanie układu pojedynczego węzła na małą skalę i ustawienia wielu węzłów na dużą skalę. Rozsądne jest posiadanie wielu układów produkcyjnych. - Testowanie. Do celów testowych można zaimplementować próbną usługę i użyć jej jako zależności w sposób bezpieczny dla typu. Można jednocześnie utrzymywać kilka różnych układów testowych z różnymi częściami zastąpionymi próbami.
- Testy integracyjne. Czasami w systemach rozproszonych trudno jest przeprowadzić testy integracyjne. Stosując opisane podejście do bezpiecznej konfiguracji całego systemu rozproszonego, możemy w kontrolowany sposób uruchomić wszystkie rozproszone części na jednym serwerze. Łatwo jest naśladować tę sytuację
gdy jedna z usług stanie się niedostępna.
Wady
Skompilowane podejście do konfiguracji różni się od „normalnej” konfiguracji i może nie odpowiadać wszystkim potrzebom. Oto niektóre wady skompilowanej konfiguracji:
- Konfiguracja statyczna. Może nie nadawać się do wszystkich zastosowań. W niektórych przypadkach istnieje potrzeba szybkiego naprawienia konfiguracji w środowisku produkcyjnym z pominięciem wszelkich zabezpieczeń. Takie podejście sprawia, że jest to trudniejsze. Po dokonaniu jakichkolwiek zmian w konfiguracji wymagana jest kompilacja i ponowne wdrożenie. Jest to zarówno cecha, jak i obciążenie.
- Generowanie konfiguracji. Kiedy konfiguracja jest generowana przez jakieś narzędzie do automatyzacji, podejście to wymaga późniejszej kompilacji (co z kolei może zakończyć się niepowodzeniem). Integracja tego dodatkowego kroku z systemem kompilacji może wymagać dodatkowego wysiłku.
- Instrumenty. Obecnie w użyciu jest wiele narzędzi, które opierają się na konfiguracjach tekstowych. Niektórzy z nich
nie będzie miało zastosowania po skompilowaniu konfiguracji. - Konieczna jest zmiana sposobu myślenia. Programiści i DevOps znają tekstowe pliki konfiguracyjne. Pomysł kompilacji konfiguracji może wydawać im się dziwny.
- Przed wprowadzeniem konfigurowalnej konfiguracji wymagany jest proces tworzenia oprogramowania o wysokiej jakości.
Zaimplementowany przykład ma pewne ograniczenia:
- Jeśli zapewnimy dodatkową konfigurację, która nie jest wymagana przez implementację węzła, kompilator nie pomoże nam wykryć braku implementacji. Można temu zaradzić, stosując
HListlub ADT (klasy przypadków) do konfiguracji węzła zamiast cech i wzorca ciasta. - Musimy podać szablon w pliku konfiguracyjnym: (
package,import,objectdeklaracje;
override def's dla parametrów, które mają wartości domyślne). Można to częściowo rozwiązać za pomocą łącza DSL. - W tym poście nie omawiamy dynamicznej rekonfiguracji klastrów podobnych węzłów.
Wniosek
W tym poście omówiliśmy pomysł przedstawienia konfiguracji bezpośrednio w kodzie źródłowym w sposób bezpieczny dla typu. Podejście to można zastosować w wielu aplikacjach jako zamiennik konfiguracji XML i innych konfiguracji tekstowych. Pomimo tego, że nasz przykład został zaimplementowany w Scali, można go również przetłumaczyć na inne języki kompilowalne (takie jak Kotlin, C#, Swift itp.). Można wypróbować to podejście w nowym projekcie, a jeśli nie pasuje, przejść na staroświecki sposób.
Oczywiście kompilowalna konfiguracja wymaga wysokiej jakości procesu programowania. W zamian obiecuje zapewnić równie wysoką jakość i solidną konfigurację.
Podejście to można rozszerzyć na różne sposoby:
- Można używać makr do sprawdzania poprawności konfiguracji i kończyć się niepowodzeniem w czasie kompilacji w przypadku jakichkolwiek niepowodzeń związanych z ograniczeniami logiki biznesowej.
- Można wdrożyć DSL w celu reprezentowania konfiguracji w sposób przyjazny dla użytkownika domeny.
- Dynamiczne zarządzanie zasobami z automatycznymi dostosowaniami konfiguracji. Na przykład, gdy dostosowujemy liczbę węzłów klastra, możemy chcieć, aby (1) węzły uzyskały nieco zmodyfikowaną konfigurację; (2) menedżer klastra, aby otrzymywać informacje o nowych węzłach.
Dzięki
Chciałbym podziękować Andriejowi Saksonowowi, Pavelowi Popovowi i Antonowi Nehaevowi za inspirujące uwagi na temat wersji tego posta, które pomogły mi uczynić wszystko jaśniejszym.
Źródło: www.habr.com
