


Na jakich zasadach zbudowana jest idealna Hurtownia Danych?
Skoncentruj się na wartości biznesowej i analizach w przypadku braku szablonowego kodu. Zarządzanie DWH jako bazą kodu: wersjonowanie, przegląd, automatyczne testowanie i CI. Modułowe, rozszerzalne, open source i społeczność. Przyjazna dla użytkownika dokumentacja i wizualizacja zależności (Data Lineage).
Więcej o tym wszystkim i o roli DBT w ekosystemie Big Data & Analytics – zapraszamy do cat.
Cześć wszystkim
Artemy Kozyr jest w kontakcie. Od ponad 5 lat zajmuję się hurtowniami danych, budową ETL/ELT oraz analityką i wizualizacją danych. Obecnie pracuję w , uczę w OTUS na kursie , a dzisiaj chcę podzielić się z Wami artykułem, który napisałem w oczekiwaniu na start nowy zapis na kurs.
Krótki przegląd
Struktura DBT opiera się na literze T w akronimie ELT (Extract - Transform - Load).
Wraz z pojawieniem się tak produktywnych i skalowalnych analitycznych baz danych jak BigQuery, Redshift, Snowflake, nie było sensu przeprowadzać transformacji poza Hurtownią Danych.
DBT nie pobiera danych ze źródeł, ale daje duże możliwości pracy z danymi, które zostały już załadowane do Pamięci (w Pamięci Wewnętrznej lub Zewnętrznej).
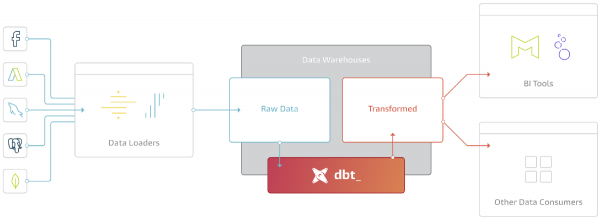
Głównym celem DBT jest pobranie kodu, skompilowanie go do SQL, wykonanie poleceń we właściwej kolejności w Repozytorium.
Struktura projektu DBT
Projekt składa się z katalogów i plików tylko 2 typów:
- Model (.sql) - jednostka transformacji wyrażona zapytaniem SELECT
- Plik konfiguracyjny (.yml) - parametry, ustawienia, testy, dokumentacja
Na podstawowym poziomie praca ma następującą strukturę:
- Użytkownik przygotowuje kod modelu w dowolnym dogodnym dla siebie środowisku IDE
- Używając CLI, uruchamiane są modele, DBT kompiluje kod modelu do SQL
- Skompilowany kod SQL wykonywany jest w Storage w zadanej kolejności (wykres)
Oto jak może wyglądać uruchamianie z poziomu interfejsu CLI:
Wszystko jest WYBIERZ
Jest to zabójcza funkcja platformy Data Build Tool. Innymi słowy, DBT abstrahuje cały kod związany z materializacją twoich zapytań w Sklepie (odmiany poleceń CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ...).
Każdy model wymaga napisania jednego zapytania SELECT, które definiuje wynikowy zestaw danych.
W tym przypadku logika transformacji może być wielopoziomowa i konsolidować dane z kilku innych modeli. Przykład modelu, który zbuduje wizytówkę zamówień (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Jakie ciekawe rzeczy możemy tu zobaczyć?
Po pierwsze: Używane CTE (Common Table Expressions) - do organizowania i zrozumienia kodu zawierającego wiele transformacji i logiki biznesowej
Po drugie: kod modelu jest mieszanką języka SQL i języka (język szablonów).
W przykładzie zastosowano pętlę dla aby wygenerować kwotę dla każdej metody płatności określonej w wyrażeniu zestaw. Funkcja jest również używana ref — możliwość odwoływania się do innych modeli w kodzie:
- Podczas kompilacji ref zostanie przekonwertowany na wskaźnik docelowy do tabeli lub widoku w magazynie
- ref pozwala na zbudowanie wykresu zależności modelu
Dokładnie dodaje niemal nieograniczone możliwości do DBT. Najczęściej stosowane to:
- Instrukcje if / else - instrukcje rozgałęzione
- Dla pętli - cykle
- Zmienne
- Makro - tworzenie makr
Materializacja: tabela, widok, przyrostowa
Strategia materializacji to podejście, zgodnie z którym powstały zestaw danych modelu będzie przechowywany w Storage.
W podstawowym ujęciu jest to:
- Tabela - fizyczna tabela w Magazynie
- Widok - widok, wirtualna tabela w Storage
Istnieją również bardziej złożone strategie materializacji:
- Przyrostowe - ładowanie przyrostowe (dużych tabel faktów); dodawane są nowe linie, aktualizowane są zmienione linie, usunięte linie są usuwane
- Efemeryczny – model nie materializuje się bezpośrednio, ale uczestniczy jako CTE w innych modelach
- Wszelkie inne strategie, które możesz dodać samodzielnie
Oprócz strategii materializacji istnieją możliwości optymalizacji dla konkretnych Magazynów, na przykład:
- Snowflake: tabele przejściowe, zachowanie podczas łączenia, grupowanie tabel, kopiowanie uprawnień, bezpieczne widoki
- Przesunięcie ku czerwieni: Distkey, Sortkey (przeplatany, złożony), późne widoki wiązania
- bigquery: Partycjonowanie i grupowanie tabel, Zachowanie podczas scalania, Szyfrowanie KMS, Etykiety i Tagi
- Iskra: Format pliku (parkiet, csv, json, orc, delta), partycja_by, klaster_by, wiadra, strategia_przyrostowa
Obecnie obsługiwane są następujące magazyny:
- Postgres
- Przesunięcie ku czerwieni
- bigquery
- Snowflake
- Presto (częściowo)
- Iskra (częściowo)
- Microsoft SQL Server (adapter społecznościowy)
Ulepszmy nasz model:
- Sprawmy, aby jego wypełnienie było przyrostowe (przyrostowe)
- Dodajmy klucze segmentacji i sortowania dla Redshift
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Wykres zależności modelu
To także drzewo zależności. Jest również znany jako DAG (kierowany graf acykliczny).
DBT buduje wykres w oparciu o konfigurację wszystkich modeli projektu, lub raczej powiązania ref() w modelach z innymi modelami. Posiadanie wykresu pozwala na wykonanie następujących czynności:
- Uruchamianie modeli we właściwej kolejności
- Równoległość formowania witryn sklepowych
- Uruchamianie dowolnego podgrafu
Przykład wizualizacji wykresu:
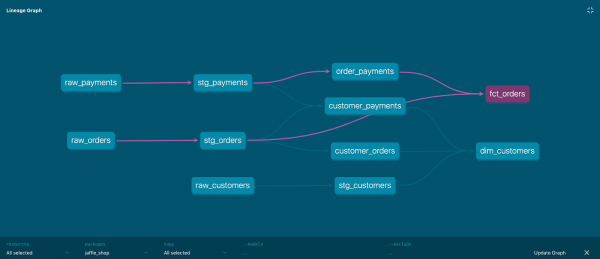
Każdy węzeł grafu jest modelem; krawędzie grafu są określone przez wyrażenie ref.
Jakość danych i dokumentacja
Oprócz generowania samych modeli, DBT umożliwia przetestowanie szeregu założeń dotyczących wynikowego zbioru danych, takich jak:
- Nie jest zerem
- Wyjątkowy
- Integralność referencyjna - integralność referencyjna (na przykład identyfikator_klienta w tabeli zamówień odpowiada identyfikatorowi w tabeli klientów)
- Dopasowanie do listy akceptowalnych wartości
Istnieje możliwość dodania własnych testów (niestandardowych testów danych), takich jak np. odchylenie procentowe przychodów ze wskaźnikami z dnia, tygodnia, miesiąca temu. Testem może stać się każde założenie sformułowane w formie zapytania SQL.
W ten sposób można wyłapać niepożądane odchylenia i błędy w danych w oknach Magazynu.
Jeśli chodzi o dokumentację, DBT zapewnia mechanizmy dodawania, wersjonowania i dystrybucji metadanych i komentarzy na poziomie modelu, a nawet atrybutu.
Oto jak wygląda dodawanie testów i dokumentacji na poziomie pliku konfiguracyjnego:
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
A tak wygląda ta dokumentacja na wygenerowanej stronie internetowej:
Makra i moduły
Celem DBT nie jest stanie się zestawem skryptów SQL, ale zapewnienie użytkownikom potężnych i bogatych w funkcje środków do tworzenia własnych transformacji i dystrybucji tych modułów.
Makra to zestawy konstrukcji i wyrażeń, które można wywoływać jako funkcje w modelach. Makra umożliwiają ponowne wykorzystanie języka SQL pomiędzy modelami i projektami zgodnie z zasadą inżynierską DRY (Don't Repeat Yourself).
Przykład makro:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
I jego zastosowania:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
DBT jest wyposażony w menedżera pakietów, który pozwala użytkownikom publikować i ponownie wykorzystywać poszczególne moduły i makra.
Oznacza to możliwość ładowania i używania bibliotek takich jak:
- : praca z datą/godziną, kluczami zastępczymi, testami schematu, Pivot/Unpivot i innymi
- Gotowe szablony prezentacji dla usług takich jak и
- Biblioteki dla konkretnych Data Stores, np.
- — Moduł do rejestrowania pracy DBT
Pełną listę pakietów można znaleźć na stronie .
Jeszcze więcej funkcji
Tutaj opiszę kilka innych ciekawych funkcji i implementacji, z których korzystam wraz z zespołem przy budowie Hurtowni Danych .
Rozdzielenie środowisk uruchomieniowych DEV - TEST - PROD
Nawet w ramach tego samego klastra DWH (w ramach różnych schematów). Na przykład, używając następującego wyrażenia:
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Ten kod dosłownie mówi: dla środowisk deweloper, test, ci pobieraj dane tylko z ostatnich 3 dni i nie więcej. Oznacza to, że działanie w takich środowiskach będzie znacznie szybsze i będzie wymagało mniej zasobów. Podczas uruchamiania w środowisku szturchać warunek filtra zostanie zignorowany.
Materializacja z alternatywnym kodowaniem kolumn
Redshift to kolumnowy system DBMS, który umożliwia ustawienie algorytmów kompresji danych dla każdej pojedynczej kolumny. Wybór optymalnych algorytmów może zmniejszyć ilość miejsca na dysku o 20-50%.
Makro wykona polecenie ANALYZE COMPRESSION, utworzy nową tabelę z zalecanymi algorytmami kodowania kolumn, określonymi kluczami segmentacji (dist_key) i sortowania (sort_key), przeniesie do niej dane i w razie potrzeby usunie starą kopię.
Podpis makro:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List<String>,
dist_style=none|all|even,
dist_key=none|String) }}
Uruchomienie modelu rejestrowania
Do każdego wykonania modelu możesz dołączyć hooki, które zostaną wykonane przed uruchomieniem lub bezpośrednio po zakończeniu tworzenia modelu:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
Moduł logowania umożliwi Ci zapisanie w osobnej tabeli wszystkich niezbędnych metadanych, które później można wykorzystać do audytu i analizy wąskich gardeł.
Tak wygląda dashboard na podstawie logowania danych w Lookerze:
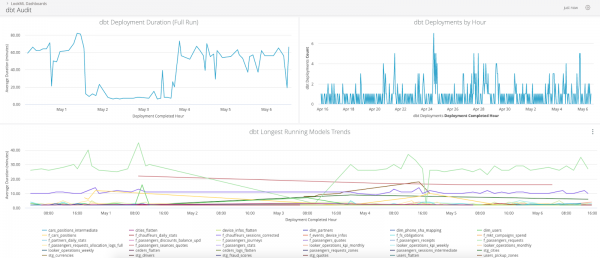
Automatyzacja obsługi magazynu
Jeśli korzystasz z niektórych rozszerzeń funkcjonalności używanego Repozytorium, jak np. UDF (Funkcje Definiowane przez Użytkownika), to wersjonowanie tych funkcji, kontrola dostępu i automatyczne wdrażanie nowych wydań jest bardzo wygodne w DBT.
Używamy UDF w Pythonie do obliczania skrótów, domen e-mail i dekodowania masek bitowych.
Przykład makra tworzącego UDF na dowolnym środowisku wykonawczym (dev, test, prod):
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
W Wheely używamy Amazon Redshift, który jest oparty na PostgreSQL. W przypadku Redshift ważne jest regularne zbieranie statystyk z tabel i zwalnianie miejsca na dysku - odpowiednio polecenia ANALYZE i VACUUM.
W tym celu co noc wykonywane są polecenia z makra redshift_maintenance:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
Chmura DBT
Istnieje możliwość wykorzystania DBT jako usługi (Managed Service). Dołączony:
- Web IDE do tworzenia projektów i modeli
- Konfiguracja i harmonogram zadań
- Prosty i wygodny dostęp do logów
- Strona internetowa z dokumentacją Twojego projektu
- Łączenie CI (ciągła integracja)
wniosek
Przygotowanie i spożywanie DWH staje się tak samo przyjemne i korzystne jak picie koktajlu. DBT składa się z Jinja, rozszerzeń użytkownika (modułów), kompilatora, modułu wykonującego i menedżera pakietów. Łącząc te elementy, otrzymujesz kompletne środowisko pracy dla swojej Hurtowni Danych. Nie ma obecnie lepszego sposobu na zarządzanie transformacją w DWH.

Przekonania, którymi kierują się twórcy DBT, formułują się następująco:
- Kod, a nie GUI, jest najlepszą abstrakcją do wyrażania złożonej logiki analitycznej
- Praca z danymi powinna uwzględniać najlepsze praktyki inżynierii oprogramowania (Inżynieria oprogramowania)
- Krytyczna infrastruktura danych powinna być kontrolowana przez społeczność użytkowników jako oprogramowanie typu open source
- Nie tylko narzędzia analityczne, ale także kod w coraz większym stopniu staną się własnością społeczności Open Source
Te podstawowe przekonania dały początek produktowi, z którego korzysta obecnie ponad 850 firm, i stanowią podstawę wielu ekscytujących rozszerzeń, które zostaną stworzone w przyszłości.
Dla zainteresowanych udostępniam filmik z lekcją otwartą, którą udzieliłem kilka miesięcy temu w ramach lekcji otwartej w OTUS - .
Oprócz DBT i Data Warehousing, w ramach kursu Data Engineer na platformie OTUS, ja i moi współpracownicy prowadzimy zajęcia z szeregu innych istotnych i nowoczesnych tematów:
- Koncepcje architektoniczne dla zastosowań Big Data
- Ćwicz ze Sparkiem i Spark Streaming
- Poznanie metod i narzędzi ładowania źródeł danych
- Budowanie wizytówek analitycznych w DWH
- Koncepcje NoSQL: HBase, Cassandra, ElasticSearch
- Zasady monitorowania i orkiestracji
- Projekt końcowy: połączenie wszystkich umiejętności w ramach wsparcia mentorskiego
Linki:
- — Oficjalna dokumentacja
- — Artykuł przeglądowy jednego z autorów DBT
- — YouTube, nagranie otwartej lekcji OTUS
- — Najbliższa lekcja otwarta odbędzie się 15 maja 2020 r
- —OTUS
- — Spojrzenie w przyszłość danych i analiz
- — Ewolucja analityki i wpływ Open Source
- — Zasady budowania CI z wykorzystaniem DBT
- — Praktyka, Instrukcje krok po kroku dotyczące samodzielnej pracy
- — Github, kod projektu edukacyjnego
Źródło: www.habr.com
