


Variti opracowuje zabezpieczenia przed botami i atakami DDoS, a także przeprowadza testy obciążeniowe i obciążeniowe. Na konferencji HighLoad++ 2018 rozmawialiśmy o tym, jak zabezpieczyć zasoby przed różnego rodzaju atakami. W skrócie: izoluj części systemu, korzystaj z usług w chmurze i CDN oraz regularnie aktualizuj. Ale bez wyspecjalizowanych firm i tak nie poradzisz sobie z ochroną :)
Przed przeczytaniem tekstu możesz zapoznać się z krótkimi abstraktami .
A jeśli nie lubisz czytać lub po prostu chcesz obejrzeć wideo, nagranie naszej relacji znajdziesz poniżej, pod spoilerem.
Nagranie wideo raportu

Wiele firm wie już, jak przeprowadzać testy obciążeniowe, ale nie wszystkie robią testy obciążeniowe. Niektórzy z naszych klientów uważają, że ich witryna jest niezniszczalna, ponieważ mają system o dużym obciążeniu i dobrze chronią przed atakami. Pokazujemy, że nie jest to do końca prawdą.
Oczywiście przed przeprowadzeniem testów uzyskujemy zgodę klienta, podpisaną i opieczętowaną, a przy naszej pomocy nie można na nikogo przeprowadzić ataku DDoS. Testowanie przeprowadzane jest w wybranym przez Klienta czasie, kiedy ruch na jego zasobach jest minimalny, a problemy z dostępem nie będą dotyczyć Klientów. Dodatkowo, ponieważ podczas procesu testowania zawsze może coś pójść nie tak, mamy stały kontakt z klientem. Dzięki temu możesz nie tylko raportować osiągnięte wyniki, ale także coś zmienić w trakcie testów. Po zakończeniu testów zawsze sporządzamy raport, w którym wskazujemy wykryte niedociągnięcia i przedstawiamy rekomendacje dotyczące wyeliminowania słabych punktów witryny.
Jak pracujemy
Podczas testów emulujemy botnet. Ponieważ współpracujemy z klientami, którzy nie są zlokalizowani w naszych sieciach, aby mieć pewność, że test nie zakończy się w pierwszej minucie z powodu uruchomienia limitów lub zabezpieczeń, dostarczamy obciążenie nie z jednego IP, ale z własnej podsieci. Dodatkowo, aby wytworzyć znaczne obciążenie, mamy własny, dość wydajny serwer testowy.
Postulaty
Za dużo nie znaczy dobrze
Im mniejsze obciążenie możemy doprowadzić do awarii zasobu, tym lepiej. Jeśli możesz sprawić, że witryna przestanie działać po jednym żądaniu na sekundę lub nawet jednym żądaniu na minutę, to świetnie. Ponieważ zgodnie z prawem podłości użytkownicy lub osoby atakujące przypadkowo wpadną w tę konkretną lukę.
Częściowa awaria jest lepsza niż całkowita awaria
Zawsze zalecamy tworzenie systemów heterogenicznych. Co więcej, warto je oddzielać na poziomie fizycznym, a nie tylko poprzez konteneryzację. W przypadku fizycznej separacji, nawet jeśli coś w serwisie zawiedzie, istnieje duże prawdopodobieństwo, że nie przestanie ona całkowicie działać, a użytkownicy nadal będą mieli dostęp do przynajmniej części funkcjonalności.
Dobra architektura jest podstawą zrównoważonego rozwoju
Odporność zasobu na awarie oraz jego odporność na ataki i obciążenia należy ustalić już na etapie projektowania, a właściwie już na etapie rysowania pierwszych schematów blokowych w notatniku. Bo jeśli wkradną się fatalne błędy, to można je w przyszłości skorygować, ale jest to bardzo trudne.
Nie tylko kod powinien być dobry, ale także konfiguracja
Wiele osób uważa, że dobry zespół programistów gwarantuje niezawodność usług. Dobry zespół programistów jest rzeczywiście niezbędny, ale potrzebne są również dobre operacje, dobre DevOps. Oznacza to, że potrzebujesz specjalistów, którzy potrafią to poprawnie skonfigurować. Linux i sieci, poprawnie zapisywać pliki konfiguracyjne NGINX, ustawiać limity itd. W przeciwnym razie zasób będzie działał poprawnie tylko w fazie testowej, ale w pewnym momencie w fazie produkcyjnej wszystko się zepsuje.
Różnice między testowaniem obciążeniowym i obciążeniowym
Testowanie obciążenia pozwala na identyfikację granic funkcjonowania systemu. Testy warunków skrajnych mają na celu znalezienie słabych punktów w systemie i służą do rozbicia tego systemu i sprawdzenia, jak będzie się on zachowywał w procesie awarii określonych części. W takim przypadku charakter obciążenia zwykle pozostaje nieznany klientowi przed rozpoczęciem testów obciążeniowych.
Charakterystyczne cechy ataków L7
Typy obciążeń dzielimy zazwyczaj na obciążenia na poziomie L7 oraz L3&4. L7 to obciążenie na poziomie aplikacji, najczęściej oznacza to tylko HTTP, ale mamy na myśli dowolne obciążenie na poziomie protokołu TCP.
Ataki L7 mają pewne charakterystyczne cechy. Po pierwsze, trafiają bezpośrednio do aplikacji, to znaczy jest mało prawdopodobne, że zostaną odzwierciedlone za pośrednictwem środków sieciowych. Takie ataki wykorzystują logikę, dzięki czemu bardzo efektywnie i przy niewielkim ruchu zużywają procesor, pamięć, dysk, bazę danych i inne zasoby.
Powódź HTTP
W przypadku jakiegokolwiek ataku obciążenie łatwiej jest stworzyć niż sobie z nim poradzić i w przypadku L7 również to się sprawdza. Nie zawsze łatwo jest odróżnić ruch atakowy od ruchu legalnego i najczęściej można to zrobić na podstawie częstotliwości, ale jeśli wszystko zostanie poprawnie zaplanowane, z dzienników nie da się zrozumieć, gdzie jest atak i gdzie są uzasadnione żądania.
Jako pierwszy przykład rozważmy atak HTTP Flood. Z wykresu wynika, że tego typu ataki są zazwyczaj bardzo potężne – w poniższym przykładzie szczytowa liczba żądań przekroczyła 600 tysięcy na minutę.
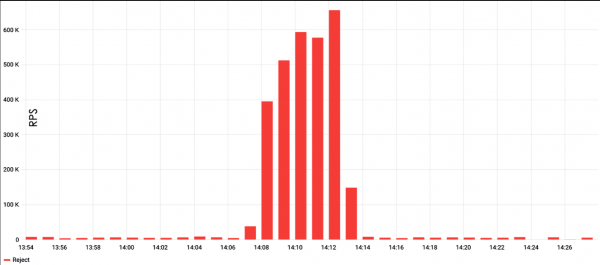
HTTP Flood to najprostszy sposób na utworzenie obciążenia. Zwykle wykorzystuje narzędzie do testowania obciążenia, takie jak ApacheBench, i ustawia żądanie oraz cel. Przy tak prostym podejściu istnieje duże prawdopodobieństwo natknięcia się na buforowanie serwera, ale łatwo je ominąć. Np. dodanie do żądania losowych ciągów znaków, co zmusi serwer do ciągłego serwowania świeżej strony.
Nie zapomnij także o kliencie użytkownika w procesie tworzenia ładunku. Wiele programów klienckich popularnych narzędzi testujących jest filtrowanych przez administratorów systemu i w tym przypadku obciążenie może po prostu nie dotrzeć do backendu. Możesz znacznie poprawić wynik, wstawiając do żądania mniej lub bardziej prawidłowy nagłówek z przeglądarki.
Choć ataki HTTP Flood są proste, mają również swoje wady. Po pierwsze, do wytworzenia obciążenia potrzebna jest duża ilość energii. Po drugie, takie ataki są bardzo łatwe do wykrycia, szczególnie jeśli pochodzą z jednego adresu. W rezultacie żądania natychmiast zaczynają być filtrowane przez administratorów systemu lub nawet na poziomie dostawcy.
Co szukać
Aby zmniejszyć liczbę żądań na sekundę bez utraty wydajności, musisz wykazać się odrobiną wyobraźni i eksplorować witrynę. Dzięki temu możesz załadować nie tylko kanał czy serwer, ale także poszczególne części aplikacji, na przykład bazy danych czy systemy plików. Możesz także poszukać na stronie miejsc, które wykonują duże obliczenia: kalkulatory, strony wyboru produktów itp. Wreszcie często zdarza się, że witryna posiada jakiś skrypt PHP, który generuje stronę składającą się z kilkuset tysięcy linii. Taki skrypt również znacząco obciąża serwer i może stać się celem ataku.
Gdzie patrzeć
Kiedy skanujemy zasób przed testowaniem, najpierw oczywiście przyglądamy się samej witrynie. Poszukujemy wszelkiego rodzaju pól wejściowych, ciężkich plików - ogólnie wszystkiego, co może powodować problemy dla zasobu i spowalniać jego działanie. Pomagają tu banalne narzędzia programistyczne w Google Chrome i Firefox, pokazujące czasy reakcji strony.
Skanujemy także subdomeny. Na przykład istnieje pewien sklep internetowy abc.com i ma on subdomenę admin.abc.com. Najprawdopodobniej jest to panel administracyjny z autoryzacją, ale jeśli go obciążysz, może to spowodować problemy dla głównego zasobu.
Strona może posiadać subdomenę api.abc.com. Najprawdopodobniej jest to zasób dla aplikacji mobilnych. Aplikację można znaleźć w App Store lub Google Play, zainstalować specjalny punkt dostępu, przeanalizować API i zarejestrować konta testowe. Problem polega na tym, że ludzie często myślą, że wszystko, co jest chronione autoryzacją, jest odporne na ataki typu „odmowa usługi”. Podobno najlepszym CAPTCHA jest autoryzacja, ale tak nie jest. Łatwo jest zrobić 10-20 kont testowych, ale tworząc je, uzyskujemy dostęp do złożonej i nieskrywanej funkcjonalności.
Oczywiście przeglądamy historię, pliki robots.txt i WebArchive, ViewDNS i szukamy starych wersji zasobu. Czasami zdarza się, że programiści wdrożyli, powiedzmy, mail2.yandex.net, ale stara wersja, mail.yandex.net pozostaje. Ta poczta.yandex.net nie jest już obsługiwana, zasoby programistyczne nie są do niej przydzielone, ale nadal zużywa bazę danych. W związku z tym, korzystając ze starej wersji, możesz efektywnie wykorzystać zasoby backendu i wszystkiego, co kryje się za układem. Oczywiście nie zawsze tak się dzieje, ale wciąż spotykamy się z tym dość często.
Oczywiście analizujemy wszystkie parametry żądania i strukturę plików cookie. Możesz, powiedzmy, zrzucić pewną wartość do tablicy JSON wewnątrz pliku cookie, utworzyć wiele zagnieżdżeń i sprawić, że zasób będzie działał przez nieracjonalnie długi czas.
Wyszukaj obciążenie
Pierwszą rzeczą, która przychodzi na myśl podczas wyszukiwania witryny, jest załadowanie bazy danych, ponieważ prawie każdy ma wyszukiwanie i prawie wszyscy, niestety, są słabo chronieni. Z jakiegoś powodu programiści nie zwracają wystarczającej uwagi na wyszukiwanie. Ale jest tutaj jedno zalecenie - nie powinieneś wysyłać żądań tego samego typu, ponieważ możesz spotkać się z buforowaniem, jak ma to miejsce w przypadku zalewu HTTP.
Wykonywanie losowych zapytań do bazy danych również nie zawsze jest skuteczne. Dużo lepiej jest stworzyć listę słów kluczowych odpowiednich dla wyszukiwania. Wracając do przykładu sklepu internetowego: załóżmy, że witryna sprzedaje opony samochodowe i umożliwia ustawienie promienia opon, rodzaju samochodu i innych parametrów. W związku z tym kombinacje odpowiednich słów wymuszą pracę bazy danych w znacznie bardziej złożonych warunkach.
Dodatkowo warto zastosować paginację: znacznie trudniej w wyszukiwaniu zwrócić przedostatnią stronę wyników wyszukiwania niż pierwszą. Oznacza to, że za pomocą paginacji można nieco zróżnicować ładunek.
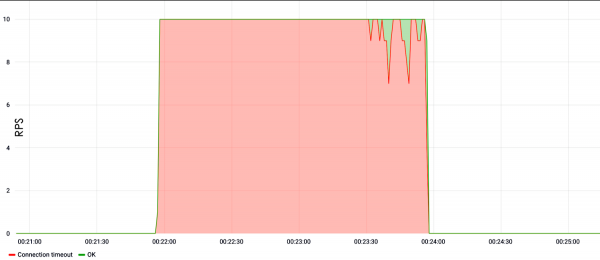
Poniższy przykład pokazuje obciążenie wyszukiwaniem. Widać, że już od pierwszej sekundy testu przy prędkości dziesięciu żądań na sekundę strona przestała działać i nie odpowiadała.
Jeśli nie ma wyszukiwania?
Jeśli nie ma wyszukiwania, nie oznacza to, że witryna nie zawiera innych wrażliwych pól wejściowych. Polem tym może być autoryzacja. Obecnie programiści lubią tworzyć złożone skróty, aby chronić bazę danych logowania przed atakiem Rainbow Table. To dobrze, ale takie skróty zużywają dużo zasobów procesora. Duży napływ fałszywych autoryzacji prowadzi do awarii procesora, w efekcie czego strona przestaje działać.
Obecność na stronie wszelkiego rodzaju formularzy komentarzy i opinii jest powodem do wysyłania tam bardzo dużych tekstów lub po prostu tworzenia masowej zalewu. Czasami witryny akceptują załączone pliki, także w formacie gzip. W tym przypadku bierzemy plik o wielkości 1 TB, kompresujemy go do kilku bajtów lub kilobajtów za pomocą programu gzip i wysyłamy na stronę. Następnie rozpina się zamek i uzyskuje się bardzo ciekawy efekt.
Reszta API
Chciałbym poświęcić trochę uwagi tak popularnym usługom jak Rest API. Zabezpieczenie Rest API jest znacznie trudniejsze niż w przypadku zwykłej strony internetowej. Nawet trywialne metody ochrony przed brutalną siłą haseł i innymi nielegalnymi działaniami nie działają w przypadku Rest API.
Rest API jest bardzo łatwe do złamania, ponieważ uzyskuje bezpośredni dostęp do bazy danych. Jednocześnie awaria takiej usługi pociąga za sobą dość poważne konsekwencje dla biznesu. Faktem jest, że Rest API jest zwykle wykorzystywane nie tylko dla strony głównej, ale także dla aplikacji mobilnej i niektórych wewnętrznych zasobów biznesowych. A jeśli to wszystko upadnie, to efekt będzie znacznie silniejszy, niż w przypadku zwykłej awarii strony internetowej.
Ładowanie ciężkich treści
Jeśli zaproponowano nam przetestowanie zwykłej jednostronicowej aplikacji, strony docelowej lub witryny z wizytówkami, która nie ma skomplikowanej funkcjonalności, szukamy ciężkich treści. Np. duże obrazy, które wysyła serwer, pliki binarne, dokumentacja pdf - to wszystko staramy się pobierać. Takie testy dobrze ładują system plików i zatykają kanały, dlatego są skuteczne. Oznacza to, że nawet jeśli nie wyłączysz serwera, pobierając duży plik przy niskiej prędkości, po prostu zatkasz kanał serwera docelowego, a następnie nastąpi odmowa usługi.
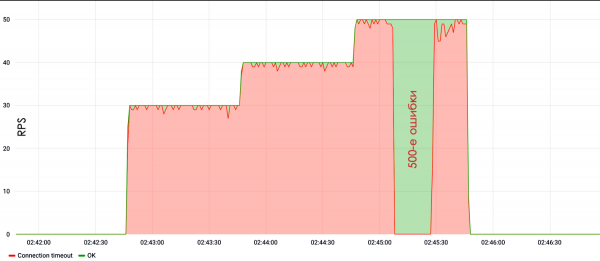
Przykład takiego testu pokazuje, że przy prędkości 30 RPS strona przestała odpowiadać lub wygenerowała 500-ty błąd serwera.
Nie zapomnij o skonfigurowaniu serwerów. Często można spotkać się z sytuacją, że ktoś kupił maszynę wirtualną, zainstalował na niej Apache, skonfigurował wszystko domyślnie, zainstalował aplikację PHP i poniżej możecie zobaczyć efekt.
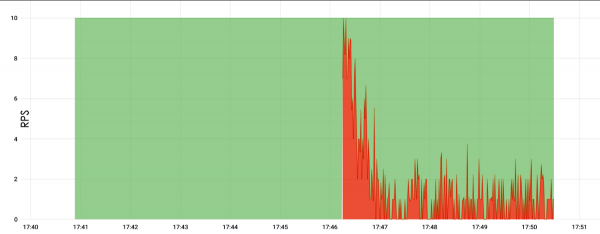
Tutaj obciążenie poszło do korzenia i wyniosło tylko 10 RPS. Czekaliśmy 5 minut i serwer się zawiesił. Co prawda nie do końca wiadomo, dlaczego upadł, ale przypuszcza się, że miał po prostu za dużo pamięci i w związku z tym przestał reagować.
Oparty na fali
W ciągu ostatniego roku lub dwóch ataki falowe stały się dość popularne. Wynika to z faktu, że wiele organizacji kupuje określone elementy sprzętu do ochrony DDoS, które wymagają określonej ilości czasu na zgromadzenie statystyk i rozpoczęcie filtrowania ataku. Oznacza to, że nie filtrują ataku w ciągu pierwszych 30-40 sekund, ponieważ gromadzą dane i uczą się. W związku z tym w ciągu tych 30-40 sekund możesz uruchomić na stronie tyle, że zasób będzie leżał przez długi czas, dopóki wszystkie żądania nie zostaną usunięte.
W przypadku poniższego ataku nastąpiła przerwa wynosząca 10 minut, po której nadeszła nowa, zmodyfikowana część ataku.
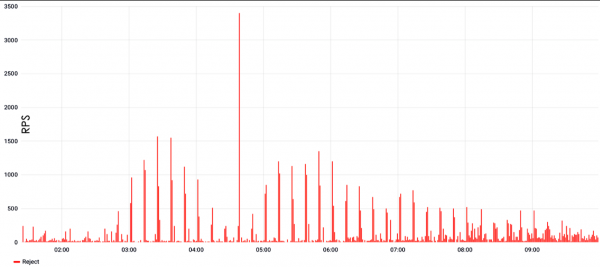
Oznacza to, że obrona nauczyła się, zaczęła filtrować, ale nadeszła nowa, zupełnie inna część ataku i obrona zaczęła się ponownie uczyć. W rzeczywistości filtrowanie przestaje działać, ochrona staje się nieskuteczna, a strona jest niedostępna.
Ataki falowe charakteryzują się bardzo dużymi wartościami w szczycie, mogą sięgać stu tysięcy lub miliona żądań na sekundę, w przypadku L7. Jeśli mówimy o L3 i 4, wówczas ruch może wynosić setki gigabitów lub odpowiednio setki MP/s, jeśli liczyć w pakietach.
Problemem takich ataków jest synchronizacja. Ataki pochodzą z botnetu i wymagają wysokiego stopnia synchronizacji, aby spowodować bardzo duży jednorazowy wzrost. I ta koordynacja nie zawsze się sprawdza: czasami na wyjściu pojawia się jakiś paraboliczny szczyt, który wygląda dość żałośnie.
Nie sam HTTP
Oprócz HTTP na L7 lubimy wykorzystywać inne protokoły. Z reguły zwykła strona internetowa, zwłaszcza zwykły hosting, ma protokoły pocztowe i wystający MySQL. Protokoły pocztowe podlegają mniejszemu obciążeniu niż bazy danych, ale mogą być również ładowane dość skutecznie, co może skutkować przeciążeniem procesora na serwerze.
Udało nam się całkiem skutecznie wykorzystać lukę SSH 2016. Teraz ta luka została naprawiona dla prawie wszystkich, ale nie oznacza to, że nie można przesłać ładunku do SSH. Móc. Jest po prostu ogromne obciążenie autoryzacjami, SSH zjada prawie cały procesor na serwerze, a następnie witryna załamuje się z jednego lub dwóch żądań na sekundę. W związku z tym jednego lub dwóch żądań opartych na logach nie można odróżnić od prawidłowego obciążenia.
Wiele połączeń, które otwieramy na serwerach, również pozostaje aktualnych. Wcześniej Apache był tego winny, teraz nginx jest tego winny, ponieważ często jest domyślnie skonfigurowany. Liczba połączeń, które nginx może utrzymać otwarte, jest ograniczona, więc otwieramy tę liczbę połączeń, nginx nie akceptuje już nowego połączenia, w wyniku czego strona nie działa.
Nasz klaster testowy ma wystarczającą ilość procesora, aby zaatakować uzgadnianie SSL. W zasadzie, jak pokazuje praktyka, botnety też czasami lubią to robić. Z jednej strony jasne, że bez SSL nie da się obejść, bo wyniki Google, ranking, bezpieczeństwo. Z drugiej strony SSL ma niestety problem z procesorem.
L3 i 4
Kiedy mówimy o ataku na poziomach L3 i 4, zwykle mówimy o ataku na poziomie łącza. Taki ładunek prawie zawsze można odróżnić od prawidłowego, chyba że jest to atak typu SYN-flood. Problemem z atakami SYN-flood na narzędzia bezpieczeństwa jest ich duża liczba. Maksymalna wartość L3&4 wynosiła 1,5-2 Tbit/s. Tego rodzaju ruch jest bardzo trudny do przetworzenia nawet dla dużych firm, m.in. Oracle i Google.
SYN i SYN-ACK to pakiety używane podczas nawiązywania połączenia. Dlatego SYN-flood trudno odróżnić od legalnego obciążenia: nie jest jasne, czy jest to SYN, który przyszedł w celu nawiązania połączenia, czy też część powodzi.
Powódź UDP
Zwykle napastnicy nie mają takich możliwości, jakie mamy, więc do organizowania ataków można wykorzystać wzmocnienie. Oznacza to, że osoba atakująca skanuje Internet i znajduje podatne na ataki lub niepoprawnie skonfigurowane serwery, które na przykład w odpowiedzi na jeden pakiet SYN odpowiadają trzema komunikatami SYN-ACK. Spoofingując adres źródłowy z adresu serwera docelowego, można zwiększyć moc, powiedzmy, trzykrotnie za pomocą jednego pakietu i przekierować ruch do ofiary.
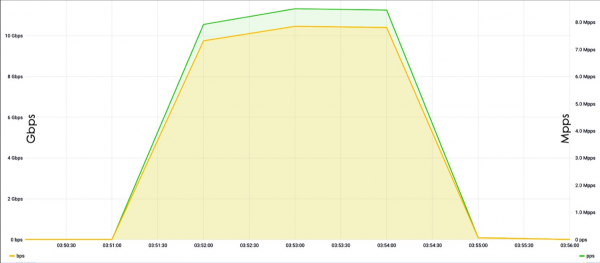
Problem z amplifikacjami polega na tym, że są one trudne do wykrycia. Do ostatnich przykładów należy sensacyjny przypadek podatnego na ataki memcached. Ponadto obecnie istnieje wiele urządzeń IoT, kamer IP, które również w większości są skonfigurowane domyślnie i domyślnie są skonfigurowane nieprawidłowo, dlatego napastnicy najczęściej dokonują ataków za pośrednictwem takich urządzeń.
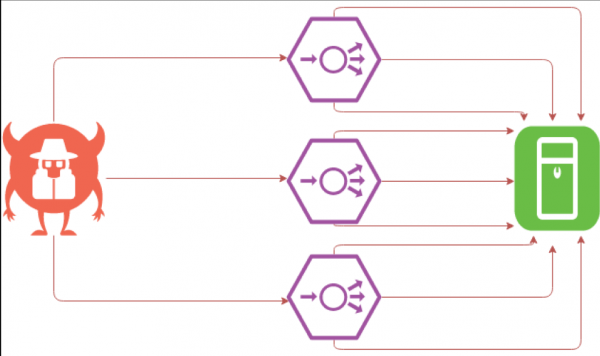
Trudna powódź SYN
SYN-flood jest prawdopodobnie najciekawszym rodzajem ataku z punktu widzenia programisty. Problem polega na tym, że administratorzy systemów często używają blokowania adresów IP w celu ochrony. Co więcej, blokowanie adresów IP dotyka nie tylko administratorów systemów działających za pomocą skryptów, ale także, niestety, niektórych systemów bezpieczeństwa, które są kupowane za duże pieniądze.
Ta metoda może okazać się katastrofą, ponieważ jeśli atakujący zastąpią Adresy IPFirma zablokuje własną podsieć. Gdy zapora sieciowa zablokuje własny klaster, komunikacja zewnętrzna zostanie przerwana, a zasób ulegnie awarii.
Co więcej, zablokowanie własnej sieci nie jest trudne. Jeśli w biurze klienta znajduje się sieć Wi-Fi lub wydajność zasobów mierzona jest za pomocą różnych systemów monitorowania, wówczas bierzemy adres IP tego systemu monitorowania lub Wi-Fi w biurze klienta i wykorzystujemy go jako źródło. Na koniec zasób wydaje się być dostępny, ale docelowe adresy IP są zablokowane. Tym samym sieć Wi-Fi konferencji HighLoad, w której prezentowany jest nowy produkt firmy, może zostać zablokowana, a to wiąże się z pewnymi kosztami biznesowymi i ekonomicznymi.
Podczas testów nie możemy używać wzmocnienia poprzez memcached z żadnymi zasobami zewnętrznymi, ponieważ istnieją umowy na wysyłanie ruchu tylko na dozwolone adresy IP. W związku z tym stosujemy wzmocnienie poprzez SYN i SYN-ACK, gdy system odpowiada na wysłanie jednego SYN dwoma lub trzema SYN-ACK, a na wyjściu atak jest mnożony dwa lub trzy razy.
Narzędzia
Jednym z głównych narzędzi, których używamy do obciążenia L7, jest Yandex-tank. W szczególności fantom służy jako broń, a ponadto istnieje kilka skryptów do generowania nabojów i analizowania wyników.
Tcpdump służy do analizy ruchu sieciowego, a Nmap do analizy serwerów. Do generowania obciążenia na poziomie L3 i L4 wykorzystuje się OpenSSL i odrobinę magii z biblioteką DPDK. DPDK to biblioteka Intela, która umożliwia pracę z interfejsem sieciowym bez konieczności przechodzenia przez stos. Linux, zwiększając w ten sposób wydajność. Oczywiście używamy DPDK nie tylko na poziomie L3 i L4, ale także na poziomie L7, ponieważ pozwala nam to generować bardzo duże obciążenia, nawet do kilku milionów żądań na sekundę z jednej maszyny.
Korzystamy również z określonych generatorów ruchu i specjalnych narzędzi, które piszemy do konkretnych testów. Jeśli przypomnimy sobie lukę w zabezpieczeniach SSH, to powyższego zestawu nie można wykorzystać. Jeśli zaatakujemy protokół pocztowy, bierzemy narzędzia pocztowe lub po prostu piszemy na nich skrypty.
odkrycia
Na zakończenie chciałbym powiedzieć:
- Oprócz klasycznych testów obciążeniowych konieczne jest przeprowadzenie testów obciążeniowych. Mamy prawdziwy przykład, w którym podwykonawca partnera przeprowadził jedynie testy obciążeniowe. Wykazano, że zasób może wytrzymać normalne obciążenie. Ale potem pojawiło się nienormalne obciążenie, odwiedzający witrynę zaczęli nieco inaczej korzystać z zasobu, w wyniku czego podwykonawca się położył. Dlatego warto szukać podatności nawet jeśli jesteś już chroniony przed atakami DDoS.
- Konieczne jest odizolowanie niektórych części systemu od innych. Jeśli masz wyszukiwanie, musisz przenieść je na osobne maszyny, czyli nawet do Dockera. Ponieważ jeśli wyszukiwanie lub autoryzacja nie powiedzie się, przynajmniej coś będzie nadal działać. W przypadku sklepu internetowego użytkownicy będą w dalszym ciągu wyszukiwać produkty w katalogu, przechodzić z agregatora, dokonywać zakupów, jeśli mają już autoryzację lub dokonywać autoryzacji poprzez OAuth2.
- Nie zaniedbuj wszelkiego rodzaju usług w chmurze.
- Używaj CDN nie tylko do optymalizacji opóźnień w sieci, ale także jako środka ochrony przed atakami polegającymi na wyczerpaniu kanału i po prostu zalewaniu ruchu statycznego.
- Konieczne jest skorzystanie ze specjalistycznych usług ochrony. Nie możesz uchronić się przed atakami L3 i 4 na poziomie kanału, ponieważ najprawdopodobniej po prostu nie masz wystarczającego kanału. Jest również mało prawdopodobne, że będziesz w stanie odeprzeć ataki L7, ponieważ mogą być bardzo duże. Poza tym poszukiwanie małych ataków jest nadal domeną służb specjalnych i specjalnych algorytmów.
- Aktualizuj regularnie. Dotyczy to nie tylko jądra, ale także demona SSH, zwłaszcza jeśli masz je otwarte na zewnątrz. W zasadzie wszystko wymaga aktualizacji, ponieważ jest mało prawdopodobne, że będziesz w stanie samodzielnie wyśledzić pewne luki.
Źródło: www.habr.com
