

Na podstawie dyskusji na czacie
Ostatnio rozgorzały prawdziwe spory wokół definicji DevOps i SRE.
Pomimo tego, że pod wieloma względami dyskusje na ten temat już mnie irytowały, w tym mnie, postanowiłem przedstawić swoje zdanie na ten temat przed sądem społeczności Habra. Zainteresowanych zapraszamy na kot. I niech wszystko zacznie się od nowa!
prehistoria
Tak więc w czasach starożytnych zespół programistów i administratorów serwerów żył osobno. Pierwszy z sukcesem napisał kod, drugi używając różnych ciepłych, serdecznych słów skierowanych do pierwszego, skonfigurował serwery, okresowo przychodząc do programistów i otrzymując w odpowiedzi wyczerpujące „wszystko działa na mojej maszynie”. Firma czekała na oprogramowanie, wszystko było bezczynne, okresowo się psuło, wszyscy byli zdenerwowani. Zwłaszcza ten, który zapłacił za cały ten bałagan. Chwalebna era lampy. Cóż, już wiesz, skąd pochodzi DevOps.
Narodziny praktyk DevOps
Potem przyszli poważni faceci i powiedzieli – to nie jest branża, nie można tak pracować. I wprowadzili modele cyklu życia. Oto na przykład model V.
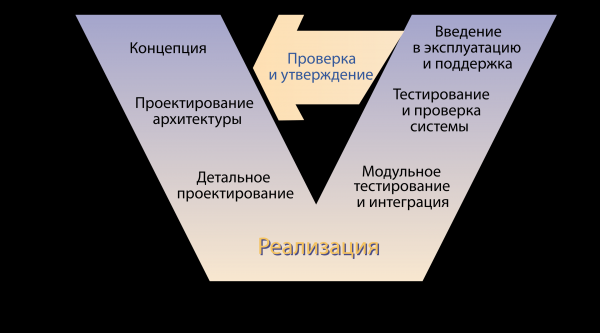
Co więc widzimy? Firma ma koncepcję, architekci projektują rozwiązania, programiści piszą kod, a potem kończy się to niepowodzeniem. Ktoś w jakiś sposób testuje produkt, ktoś w jakiś sposób dostarcza go końcowemu użytkownikowi, a gdzieś na wyjściu tego cudownego modelu siedzi samotny klient biznesowy, czekający na obiecaną pogodę nad morzem. Doszliśmy do wniosku, że potrzebujemy metod, które pozwolą nam ustalić ten proces. I postanowiliśmy stworzyć praktyki, które je wdrożą.
Liryczna dygresja na temat tego, czym jest praktyka
Przez praktykę mam na myśli połączenie technologii i dyscypliny. Przykładem jest praktyka opisywania infrastruktury za pomocą kodu terraformowego. Dyscyplina polega na opisaniu infrastruktury kodem, jest w głowie programisty, a technologia sama w sobie jest terraformą.
I postanowili nazwać je praktykami DevOps – myślę, że mieli na myśli od rozwoju do operacji. Wymyśliliśmy różne sprytne rzeczy – praktyki CI/CD, praktyki oparte na zasadzie IaC, tysiące takich. I gotowe, programiści piszą kod, inżynierowie DevOps przekształcają opis systemu w postaci kodu na działające systemy (tak, kod to niestety tylko opis, a nie ucieleśnienie systemu), dostawa trwa, i tak dalej. Wczorajsi administratorzy, po opanowaniu nowych praktyk, z dumą przekwalifikowali się na inżynierów DevOps i od tego wszystko poszło. I nastał wieczór, i nastał poranek... Przepraszam, nie stamtąd.
Znów nie jest dobrze, dzięki Bogu
Gdy tylko wszystko się uspokoiło i różni przebiegli „metodolodzy” zaczęli pisać grube książki na temat praktyk DevOps, po cichu rozgorzały spory o to, kim był osławiony inżynier DevOps i że DevOps to kultura produkcyjna, ponownie pojawiło się niezadowolenie. Nagle okazało się, że dostarczenie oprogramowania jest zadaniem absolutnie nietrywialnym. Każda infrastruktura programistyczna ma swój własny stos, gdzieś trzeba ją złożyć, gdzieś trzeba wdrożyć środowisko, tutaj potrzebny jest Tomcat, tutaj potrzebny jest sprytny i skomplikowany sposób na jego uruchomienie - ogólnie głowa pęka. I, co dziwne, problem okazał się przede wszystkim w organizacji procesów - ta funkcja dostarczania, niczym wąskie gardło, zaczęła blokować procesy. Ponadto nikt nie odwołał Operacji. W modelu V nie jest to widoczne, ale po prawej stronie nadal jest cały cykl życia. W rezultacie konieczne jest utrzymanie infrastruktury, monitorowanie monitoringu, rozwiązywanie incydentów, a także zajmowanie się dostawą. Te. siedzieć jedną nogą zarówno w rozwoju, jak i działaniu - i nagle okazało się, że jest to Development & Operations. A potem pojawił się ogólny szum wokół mikrousług. A wraz z nimi rozwój z maszyn lokalnych zaczął przenosić się do chmury - spróbuj debugować coś lokalnie, jeśli są dziesiątki i setki mikrousług, to ciągłe dostarczanie staje się sposobem na przetrwanie. Jak na „małą, skromną firmę” było w porządku, ale jednak? A co z Googlem?
SRE od Google
Przyszedł Google, zjadł największe kaktusy i zdecydował - nie potrzebujemy tego, potrzebujemy niezawodności. Trzeba zarządzać niezawodnością. I zdecydowałem, że potrzebujemy specjalistów, którzy poradzą sobie z niezawodnością. Zadzwoniłem do nich inżynierami SR i powiedziałem: to tyle, róbcie to dobrze, jak zwykle. Tu jest SLI, tu jest SLO, tu jest monitoring. I wtykał nos w operacje. I nazwał swój „niezawodny DevOps” SRE. Wszystko wydaje się być w porządku, ale jest jeden brudny hack, na który Google mogło sobie pozwolić - na stanowisko inżynierów SR zatrudnić ludzi, którzy byli wykwalifikowanymi programistami, a także odrobili trochę pracy domowej i zrozumieli funkcjonowanie działających systemów. Co więcej, sam Google ma problemy z zatrudnieniem takich osób – głównie dlatego, że tutaj konkuruje sam ze sobą – trzeba komuś opisywać logikę biznesową. Dostawę powierzono inżynierom wydania, SR - inżynierowie zarządzają niezawodnością (oczywiście nie bezpośrednio, ale poprzez wpływ na infrastrukturę, zmianę architektury, śledzenie zmian i wskaźników, radzenie sobie z incydentami). Fajnie, możesz . Ale co, jeśli nie jesteś Google, ale niezawodność nadal jest w jakiś sposób problemem?
Rozwój pomysłów DevOps
Właśnie wtedy pojawił się Docker, który wyrósł z lxc, a potem różne systemy orkiestracji, takie jak Docker Swarm i Kubernetes, a inżynierowie DevOps wyszli z domu – ujednolicenie praktyk uprościło dostarczanie. Uprościło to do tego stopnia, że możliwe stało się nawet zlecanie dostaw programistom na zewnątrz – czyli czym jest Deployment.yaml. Konteneryzacja rozwiązuje problem. A dojrzałość systemów CI/CD jest już na poziomie napisania jednego pliku i jedziemy - programiści sami sobie z tym poradzą. A potem zaczynamy rozmawiać o tym, jak możemy stworzyć własne SRE z… lub przynajmniej z kimś.
SRE nie ma w Google
No cóż, dostawa dostarczona, wygląda na to, że możemy odetchnąć, wrócić do starych, dobrych czasów, kiedy admini obserwowali obciążenie procesora, strojili systemy i po cichu popijali z kubków coś niezrozumiałego w ciszy i spokoju... Stop. Nie po to wszystko zaczęliśmy (szkoda!). Nagle okazuje się, że w podejściu Google’a możemy łatwo przyjąć doskonałe praktyki – nie liczy się obciążenie procesora, a nie to, jak często zmieniamy tam dyski czy optymalizujemy koszty w chmurze, ale metryki biznesowe są te same notoryczne SLx. Nikt też nie odebrał im zarządzania infrastrukturą, a oni muszą rozwiązywać incydenty, okresowo pełnić obowiązki i ogólnie być na bieżąco z procesami biznesowymi. I chłopaki, zacznijcie stopniowo programować na dobrym poziomie, Google już na Was czeka.
Podsumowując. Nagle, ale jesteś już zmęczony czytaniem i nie możesz się doczekać, aż spluniesz i napiszesz do autora w komentarzu do artykułu. DevOps jako praktyka dostarczania zawsze była i będzie. I to nigdzie nie zmierza. SRE jako zbiór praktyk operacyjnych sprawia, że ta realizacja jest skuteczna.
Źródło: www.habr.com
