

Witam wszystkich, nazywam się Sergey Emelyanchik. Jestem szefem firmy Audit-Telecom, głównym deweloperem i autorem systemu Veliam. Postanowiłem napisać artykuł o tym, jak wraz z przyjacielem stworzyliśmy firmę outsourcingową, napisaliśmy dla siebie oprogramowanie, a następnie zaczęliśmy je dystrybuować wśród wszystkich za pośrednictwem systemu SaaS. O tym, jak kategorycznie nie wierzyłem, że to jest możliwe. Artykuł będzie zawierał nie tylko historię, ale także szczegóły techniczne powstania produktu Veliam. Zawiera kilka fragmentów kodu źródłowego. Opowiem Ci, jakie błędy popełniliśmy i jak je później poprawiliśmy. Pojawiły się wątpliwości, czy publikować taki artykuł. Ale pomyślałem, że lepiej to zrobić, uzyskać informację zwrotną i poprawić, niż nie publikować artykułu i zastanawiać się, co by się stało, gdyby…
prehistoria
Pracowałem w jednej firmie jako pracownik IT. Firma była dość duża i posiadała rozbudowaną strukturę sieciową. Nie będę się rozwodzić nad moimi obowiązkami zawodowymi, powiem tylko, że na pewno nie obejmowały one rozwoju czegokolwiek.
Mieliśmy monitoring, ale ze względów akademickich chciałem spróbować napisać własny, najprostszy. Pomysł był taki: chciałem, żeby to było w sieci, żebym mógł łatwo wejść bez instalowania żadnych klientów i zobaczyć, co się dzieje z siecią z dowolnego urządzenia, w tym urządzenia mobilnego, przez Wi-Fi, a ja też naprawdę chciałem szybko zrozumieć, co W pokoju znajduje się sprzęt, który stał się „mętny”, ponieważ… istniały bardzo rygorystyczne wymagania dotyczące czasu reakcji na tego typu problemy. W rezultacie w mojej głowie zrodził się plan napisania prostej strony internetowej, na której znajdowałoby się tło w formacie JPEG ze schematem sieci, wycięcie samych urządzeń z ich adresami IP z tego obrazka, a na wierzchu pokazać dynamiczną zawartość obraz o wymaganych współrzędnych w postaci zielonego lub migającego na czerwono adresu IP. Zadanie zostało postawione, zaczynajmy.
Wcześniej programowałem w Delphi, PHP, JS i bardzo powierzchownie C++. Doskonale wiem, jak działają sieci. VLAN, routing (OSPF, EIGRP, BGP), NAT. To mi wystarczyło, aby samodzielnie napisać prymitywny prototyp monitoringu.
Napisałem to, co miałem na myśli, w PHP. Serwer Apache i PHP były włączone. Windows dlatego Linux dla mnie w tamtym momencie było to coś niezrozumiałego i bardzo trudnego, jak się później okazało, bardzo się myliłem i to w wielu miejscach Linux znacznie prostsze Windows, ale to osobny temat, a wszyscy wiemy, ile świętych wojen toczy się na ten temat. Harmonogram zadań Windows W krótkich odstępach czasu (nie pamiętam dokładnie, ale mniej więcej co trzy sekundy) uruchamiałem skrypt PHP, który sprawdzał wszystkie obiekty za pomocą prostego polecenia ping i zapisywał stan do pliku.
system(“ping -n 3 -w 100 {$ip_address}“);
Tak, tak, praca z bazą danych w tamtym momencie też nie była dla mnie opanowana. Nie wiedziałem, że można zrównoleglić procesy, a przechodzenie przez wszystkie węzły sieci zajmowało dużo czasu, bo... to się wydarzyło w jednym wątku. Problemy pojawiały się zwłaszcza wtedy, gdy kilka węzłów było niedostępnych, ponieważ każdy z nich opóźniał skrypt o 300 ms. Po stronie klienta dostępna była prosta funkcja zapętlania, która w odstępach kilkusekundowych pobierała aktualne informacje z serwera za pomocą żądania Ajax i aktualizowała interfejs. No cóż, po 3 nieudanych pingach z rzędu, jeśli na komputerze była otwarta strona z monitoringiem, odtwarzała się wesoła kompozycja.
Kiedy wszystko się udało, byłem bardzo zainspirowany efektem i pomyślałem, że mogę dodać do niego więcej (ze względu na moją wiedzę i możliwości). Ale zawsze nie lubiłem systemów z milionem wykresów, które wtedy uważałem i do dziś uważam za w większości przypadków niepotrzebne. Chciałem umieścić tam tylko to, co naprawdę pomoże mi w pracy. Zasada ta pozostaje fundamentalna dla rozwoju Veliama do dziś. Co więcej, zdałem sobie sprawę, że byłoby bardzo fajnie, gdybym nie musiał stale monitorować otwartego i wiedzieć o problemach, a kiedy to nastąpiło, otworzyć stronę i zobaczyć, gdzie znajduje się ten problematyczny węzeł sieci i co z tym dalej zrobić . Jakoś nie czytałem wtedy e-maili, po prostu z nich nie korzystałem. W internecie natknąłem się na bramki SMS, do których można wysłać żądanie GET lub POST, a one wyślą na mój telefon SMS z treścią, którą napiszę. Od razu zdałam sobie sprawę, że bardzo tego chciałam. I zacząłem studiować dokumentację. Po pewnym czasie udało mi się i teraz na telefonie komórkowym otrzymałem SMS o problemach z siecią o nazwie „upadły przedmiot”. Mimo, że system był prymitywny, został napisany przeze mnie, a najważniejszą rzeczą, która zmotywowała mnie do jego opracowania, było to, że był to program aplikacyjny, który naprawdę pomógł mi w pracy.
I przyszedł dzień, kiedy w pracy zepsuł się jeden z kanałów internetowych, a mój monitoring nie dał mi o tym znać. Ponieważ Google DNS nadal pinguje doskonale. Czas pomyśleć o tym, jak możesz monitorować, czy kanał komunikacji żyje. Pomysły, jak to zrobić, były różne. Nie miałem dostępu do całego sprzętu. Musieliśmy dowiedzieć się, jak zrozumieć, który z kanałów jest na żywo, ale nie mogliśmy go w jakiś sposób wyświetlić na samym sprzęcie sieciowym. Wtedy kolega wpadł na pomysł, że możliwe jest, że śledzenie tras do serwerów publicznych może się różnić w zależności od tego, który kanał komunikacyjny jest aktualnie używany do uzyskania dostępu do Internetu. Sprawdziłem i okazało się, że tak. Podczas śledzenia istniały różne trasy.
system(“tracert -d -w 500 8.8.8.8”);
Pojawił się więc kolejny skrypt, a raczej z jakiegoś powodu na końcu tego samego skryptu dodano ślad, który pingował wszystkie urządzenia w sieci. Przecież to kolejny długi proces, który został wykonany w tym samym wątku i spowalniał pracę całego skryptu. Ale wtedy nie było to takie oczywiste. Ale tak czy inaczej wykonał swoją pracę, kod ściśle określił, jaki rodzaj śledzenia powinien być dla każdego z kanałów. Tak zaczął działać system, który monitorował już (mówi się głośno, bo nie było zbierania żadnych metryk, a jedynie ping) urządzenia sieciowe (routery, przełączniki, wi-fi itp.) i kanały komunikacji ze światem zewnętrznym . Wiadomości SMS docierały regularnie, a diagram zawsze wyraźnie wskazywał, gdzie leży problem.
Co więcej, w codziennej pracy musiałem krzyżować się. I znudziło mi się chodzenie za każdym razem do przełączników Cisco, aby zobaczyć, jakiego interfejsu użyć. Jak fajnie byłoby kliknąć na obiekt w monitorowaniu i zobaczyć listę jego interfejsów wraz z opisami. Zaoszczędziłoby mi to czas. Co więcej, w tym schemacie nie byłoby potrzeby uruchamiania Putty ani SecureCRT w celu wprowadzania kont i poleceń. Po prostu kliknąłem na monitoring, zobaczyłem co było potrzebne i zabrałem się do pracy. Zacząłem szukać sposobów interakcji z przełącznikami. Od razu natknąłem się na 2 opcje: SNMP lub zalogowanie się do przełącznika przez SSH, wprowadzenie potrzebnych poleceń i parsowanie wyniku. Odrzuciłem SNMP ze względu na złożoność jego implementacji; nie mogłem się doczekać wyniku. przy SNMP musiałbyś długo grzebać w MIB i na podstawie tych danych generować dane o interfejsach. W CISCO jest wspaniały zespół
show interface statusPokazuje dokładnie, czego potrzebuję do skrzyżowań. Po co zawracać sobie głowę SNMP, skoro chcę tylko zobaczyć wynik tego polecenia, pomyślałem. Po pewnym czasie dostrzegłem tę szansę. Kliknięto obiekt na stronie internetowej. Wywołane zostało zdarzenie, w wyniku którego klient AJAX skontaktował się z serwerem, a ten z kolei połączył się poprzez SSH z potrzebnym mi przełącznikiem (dane uwierzytelniające zostały zakodowane na stałe w kodzie, nie było potrzeby ich udoskonalania, tworzenia osobnych menu, w których byłaby możliwość zmiany kont z poziomu interfejsu, potrzebowałem wyniku i to szybko) Wpisałem tam powyższą komendę i odesłałem ją z powrotem do przeglądarki. Zacząłem więc widzieć informacje o interfejsach jednym kliknięciem myszki. Było to niezwykle wygodne, zwłaszcza gdy trzeba było przeglądać te informacje na różnych przełącznikach jednocześnie.
Monitorowanie kanałów w oparciu o śledzenie okazało się nie najlepszym pomysłem, ponieważ... czasami prowadzono prace na sieci i śledzenie mogło się zmienić, a monitoring zaczął na mnie krzyczeć, że są problemy z kanałem. Jednak po spędzeniu dużej ilości czasu na analizie zdałem sobie sprawę, że wszystkie kanały działają, a mój monitoring mnie oszukał. W rezultacie poprosiłem moich kolegów, którzy zarządzali przełącznikami tworzącymi kanały, aby po prostu wysyłali mi syslog, gdy zmienił się status widoczności sąsiadów. W związku z tym było to znacznie prostsze, szybsze i dokładniejsze niż śledzenie. Nadeszło zdarzenie typu zagubienie sąsiada i od razu wysyłam powiadomienie o wyłączeniu kanału.
Co więcej, po kliknięciu obiektu pojawiło się kilka kolejnych poleceń, dodano również SNMP w celu gromadzenia pewnych danych i to w zasadzie wszystko. System nigdy nie był dalej rozwijany. Zrobił wszystko, czego potrzebowałem, to było dobre narzędzie. Wielu czytelników zapewne powie mi, że w Internecie jest już mnóstwo oprogramowania rozwiązującego te problemy. Ale tak naprawdę nie korzystałem wtedy z Google takich bezpłatnych produktów i naprawdę chciałem rozwinąć swoje umiejętności programowania, a nie było lepszego sposobu na osiągnięcie tego niż prawdziwy problem z aplikacją. W tym momencie pierwsza wersja monitoringu została ukończona i nie była już modyfikowana.
Utworzenie firmy Audit-Telecom
Z biegiem czasu zacząłem pracować na pół etatu w innych firmach, na szczęście mój harmonogram pracy mi na to pozwalał. Kiedy pracujesz w różnych firmach, Twoje umiejętności w różnych obszarach rosną bardzo szybko, a Twoje horyzonty dobrze się rozwijają. Są firmy, w których, jak to mówią, jest się Szwedem, żniwiarzem i trębaczem. Z jednej strony jest to trudne, z drugiej strony jeśli nie jesteś leniwy, stajesz się generalistą, a to pozwala ci szybciej i sprawniej rozwiązywać problemy, bo wiesz, jak działa pokrewna dziedzina.
Mój przyjaciel Paweł (również informatyk) nieustannie namawiał mnie do założenia własnej firmy. Pomysłów było niezliczona ilość i różne warianty tego, co robili. Dyskutowano o tym od lat. I ostatecznie nie powinno to do niczego dojść, bo ja jestem sceptykiem, a Paweł marzycielem. Za każdym razem, gdy proponował mi jakiś pomysł, zawsze w niego nie wierzyłem i odmawiałem udziału. Ale naprawdę chcieliśmy otworzyć własny biznes.
W końcu udało nam się znaleźć opcję, która odpowiadała nam obojgu i zrobić to, co wiemy, jak zrobić. W 2016 roku postanowiliśmy stworzyć firmę informatyczną, która będzie pomagać firmom w rozwiązywaniu problemów informatycznych. Jest to wdrażanie systemów informatycznych (1C, serwer terminali, serwer pocztowy itp.), ich utrzymanie, klasyczny HelpDesk dla użytkowników i administracja siecią.
Szczerze mówiąc, w momencie tworzenia firmy nie wierzyłem w to na 99,9%. Ale w jakiś sposób Pavelowi udało się nakłonić mnie do spróbowania i patrząc w przyszłość, okazało się, że miał rację. Pavel i ja dołożyliśmy po 300 000 rubli każdy, zarejestrowaliśmy nową spółkę LLC „Audit-Telecom”, wynajęliśmy maleńkie biuro, zrobiliśmy fajne wizytówki, no cóż, ogólnie jak prawdopodobnie najbardziej niedoświadczeni, początkujący biznesmeni i zaczęliśmy szukać klientów. Znalezienie klientów to zupełnie inna historia. Być może napiszemy osobny artykuł w ramach bloga firmowego, jeśli ktoś będzie zainteresowany. Zimne rozmowy telefoniczne, ulotki itp. Nie dało to żadnych rezultatów. Jak czytam teraz w wielu historiach o biznesie, tak czy inaczej, wiele zależy od szczęścia. Mamy szczęście. i dosłownie kilka tygodni po założeniu firmy zgłosił się do nas mój brat Władimir, który przywiózł nam pierwszego klienta. Nie będę Was zanudzał szczegółami pracy z klientami, nie o tym jest ten artykuł, powiem tylko, że poszliśmy na audyt, zidentyfikowaliśmy obszary krytyczne i te obszary uległy załamaniu w momencie podjęcia decyzji o tym, czy współpracują z nami na bieżąco jako outsourcingowcy. Po tym natychmiast podjęto pozytywną decyzję.
Następnie, głównie pocztą pantoflową, za pośrednictwem znajomych, zaczęły pojawiać się inne firmy usługowe. Helpdesk był w jednym systemie. Połączenia ze sprzętem sieciowym i serwerami są różne, a raczej różne. Niektórzy zapisali skróty, inni korzystali z książek adresowych RDP. Monitoring to kolejny odrębny system. Praca zespołu w różnych systemach jest bardzo niewygodna. Ważne informacje zostały utracone z pola widzenia. Cóż, na przykład serwer terminali klienta stał się niedostępny. Zgłoszenia są natychmiast odbierane od użytkowników tego klienta. Specjalista wsparcia otwiera zgłoszenie (otrzymało je telefonicznie). Gdyby incydenty i zgłoszenia zostały zarejestrowane w jednym systemie, specjalista wsparcia od razu dostrzegłby, na czym polega problem użytkownika i poinformował go o tym, jednocześnie łącząc się z wymaganym obiektem w celu wyjaśnienia sytuacji. Wszyscy są świadomi sytuacji taktycznej i działają harmonijnie. Nie znaleźliśmy systemu, w którym to wszystko byłoby połączone. Stało się jasne, że nadszedł czas na stworzenie własnego produktu.
Kontynuacja prac nad systemem monitoringu
Było jasne, że napisany wcześniej system zupełnie nie nadawał się do bieżących zadań. Ani pod względem funkcjonalności, ani jakości. I zdecydowano się napisać system od zera. Graficznie powinno to wyglądać zupełnie inaczej. Musiał to być system hierarchiczny, aby możliwe było szybkie i wygodne otwarcie odpowiedniego obiektu dla odpowiedniego klienta. Schemat podobnie jak w pierwszej wersji nie miał w tym przypadku żadnego uzasadnienia, gdyż Klienci są różni i nie ma żadnego znaczenia, w którym lokalu sprzęt się znajduje. Zostało to już przeniesione do dokumentacji.
A więc zadania to:
- Struktura hierarchiczna;
- Jakiś rodzaj części serwerowej, którą można umieścić u klienta w postaci maszyny wirtualnej, która będzie zbierać potrzebne nam metryki i przesyłać je do centralnego serwera, który to wszystko podsumuje i nam pokaże;
- Alerty. Te, których nie można przegapić, bo... w tamtym czasie nie było możliwości, aby ktoś siedział i po prostu patrzył na monitor;
- Aplikacja systemowa. Zaczęli pojawiać się klienci, dla których serwisowaliśmy nie tylko sprzęt serwerowy i sieciowy, ale także stacje robocze;
- Możliwość szybkiego łączenia się z serwerami i sprzętem z poziomu systemu;
Zadania zostały wyznaczone i zaczęliśmy pisać. Po drodze przetwarzaliśmy prośby od klientów. W tym momencie było nas już czworo. Zaczęliśmy pisać obie części jednocześnie: serwer centralny i serwer do instalacji klienta. W tym momencie Linux nie było nam już obce i postanowiono, że maszyny wirtualne, które zostaną zainstalowane u klientów, będą na DebianNie będzie żadnych instalatorów; po prostu utworzymy projekt po stronie serwera na jednej maszynie wirtualnej, a następnie sklonujemy go na wymaganego klienta. To był kolejny błąd. Później okazało się, że ta konfiguracja nie miała absolutnie żadnego mechanizmu aktualizacji. Dodalibyśmy więc jakąś nową funkcję, a potem dystrybucja jej na wszystkie serwery klienckie byłaby prawdziwym problemem. Ale do tego wrócimy później, w odpowiednim czasie.
Zrobiliśmy pierwszy prototyp. Był w stanie pingować potrzebne nam urządzenia sieciowe i serwery klienckie oraz wysyłać te dane do naszego centralnego serwera. A on z kolei zbiorczo zaktualizował te dane na serwerze centralnym. Tutaj napiszę nie tylko historię o tym jak i co się udało, ale także jakie amatorskie błędy popełniono i jak później musiałem za to zapłacić czasem. Zatem całe drzewo obiektów zostało zapisane w jednym pliku w postaci serializowanego obiektu. Podczas gdy podłączyliśmy do systemu kilku klientów, wszystko przebiegało mniej więcej normalnie, chociaż czasami pojawiały się pewne artefakty, które były całkowicie niezrozumiałe. Kiedy jednak podłączyliśmy do systemu kilkanaście serwerów, zaczęły się dziać cuda. Czasami z nieznanego powodu wszystkie obiekty w systemie po prostu znikały. Należy tutaj zauważyć, że serwery, których klienci, co kilka sekund wysyłały dane do serwera centralnego za pośrednictwem żądania POST. Uważny czytelnik i doświadczony programista domyślił się już, że pojawił się problem wielokrotnego dostępu do samego pliku, w którym przechowywany był serializowany obiekt z różnych wątków jednocześnie. I właśnie wtedy, gdy to się działo, działy się cuda wraz ze znikaniem przedmiotów. Plik po prostu stał się pusty. Ale to wszystko nie zostało odkryte od razu, ale dopiero podczas pracy z kilkoma serwerami. W tym czasie dodano funkcję skanowania portów (serwery wysyłały do centrali nie tylko informacje o dostępności urządzeń, ale także o otwartych na nich portach). Dokonano tego poprzez wywołanie polecenia:
$connection = @fsockopen($ip, $port, $errno, $errstr, 0.5);
wyniki były często nieprawidłowe, a skanowanie trwało długo. Zupełnie zapomniałem o pingu, robiono to poprzez fping:
system("fping -r 3 -t 100 {$this->ip}");
To również nie było równoległe i dlatego proces był bardzo długi. Później cała lista adresów IP wymaganych do weryfikacji została od razu wysłana do fping, a z powrotem otrzymaliśmy gotową listę tych, którzy odpowiedzieli. W przeciwieństwie do nas, fping był w stanie zrównoleglić procesy.
Inną częstą rutynową pracą było konfigurowanie niektórych usług za pośrednictwem sieci WWW. No na przykład ECP z MS Exchange. W zasadzie to tylko link. I zdecydowaliśmy, że musimy mieć możliwość dodania takich linków bezpośrednio do systemu, aby nie musieć szukać w dokumentacji lub gdzieś indziej w zakładkach, jak uzyskać dostęp do ECP konkretnego klienta. Tak pojawiła się koncepcja powiązań zasobów dla systemu, ich funkcjonalność jest dostępna do dziś i nie uległa zmianie, no prawie.
Jak działają linki do zasobów w Veliamie
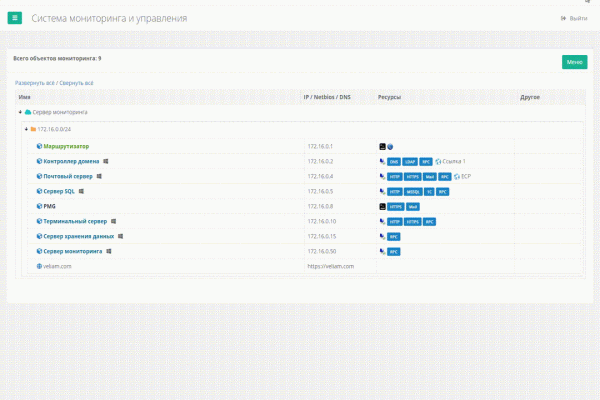
Połączenia zdalne
Tak to wygląda w akcji w aktualnej wersji Veliama
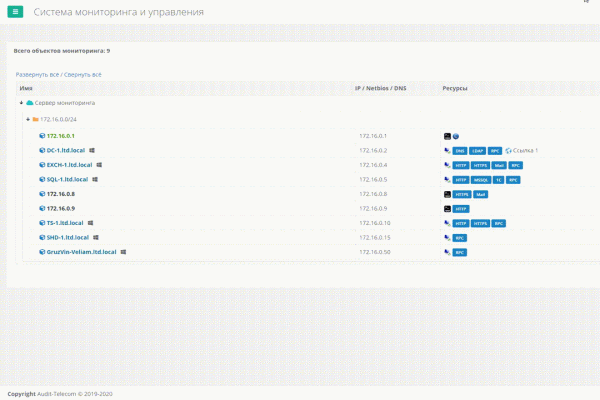
Jednym z zadań było szybkie i wygodne połączenie się z serwerami, których było już wiele (ponad sto) i sortowanie milionów wcześniej zapisanych skrótów RDP było wyjątkowo niewygodne. Potrzebne było narzędzie. W Internecie istnieje oprogramowanie, które jest czymś w rodzaju książki adresowej dla takich połączeń RDP, ale nie są one zintegrowane z systemem monitorowania i nie można zapisywać kont. Wprowadzanie kont dla różnych klientów za każdym razem to czyste piekło, gdy łączysz się dziesiątki razy dziennie z różnymi serwerami. W przypadku SSH jest trochę lepiej; istnieje wiele dobrego oprogramowania, które pozwala organizować takie połączenia w foldery i zapamiętywać z nich konta. Ale są 2 problemy. Po pierwsze, nie znaleźliśmy ani jednego programu do połączeń RDP i SSH. Po drugie, jeśli w pewnym momencie nie będę przy komputerze i będę musiał szybko się połączyć, albo po prostu przeinstalowałem system, to będę musiał sięgnąć do dokumentacji, żeby zajrzeć do konta z tego klienta. Jest to niewygodne i strata czasu.
Hierarchiczna struktura, której potrzebowaliśmy dla serwerów klienckich, była już dostępna w naszym wewnętrznym produkcie. Musiałem tylko wymyślić, jak podłączyć tam szybkozłącza do niezbędnego sprzętu. Na początek przynajmniej w obrębie Twojej sieci.
Biorąc pod uwagę, że klientem w naszym systemie była przeglądarka, która nie miała dostępu do zasobów lokalnych komputera, aby po prostu uruchomić potrzebną nam aplikację za pomocą jakiegoś polecenia, postanowiono wszystko zrobić poprzez „Windows „niestandardowy schemat URL”. W ten sposób powstała „wtyczka” dla naszego systemu, która po prostu zawierała Putty i Remote Desktop Plus, a po instalacji po prostu rejestrowała schemat URI w WindowsTeraz, gdy chcieliśmy połączyć się z obiektem przez RDP lub SSH, klikaliśmy tę akcję w naszym systemie, a uruchamiał się niestandardowy URI. Standardowy plik mstsc.exe wbudowany w Windows lub PuTTY, który został dołączony jako część „wtyczki”. Słowo „wtyczka” umieściłem w cudzysłowie, ponieważ nie jest to wtyczka do przeglądarki w klasycznym rozumieniu tego słowa.
To było coś. Wygodna książka adresowa. A w przypadku Putty wszystko było w porządku; można było podać adres IP połączenia, login i hasło jako parametry wejściowe. To znaczy, Linux Łączyliśmy się już z serwerami w naszej sieci jednym kliknięciem, bez wpisywania haseł. Ale RDP nie jest takie proste. Nie można przekazać danych uwierzytelniających jako parametrów do standardowego mstsc. Z pomocą przyszedł Remote Desktop Plus. Umożliwił nam to. Od tamtej pory radziliśmy sobie bez niego, ale przez długi czas był niezawodnym asystentem w naszym systemie. Strony HTTP(S) są proste; takie obiekty po prostu otwierają się w przeglądarce i to wszystko. Wygodne i praktyczne. Ale to było tylko błogosławieństwo dla sieci wewnętrznej.
Ponieważ zdecydowaną większość problemów rozwiązywaliśmy zdalnie z biura, najłatwiejszym sposobem było skonfigurowanie sieci VPN dla klientów. Wtedy mogliśmy się z nimi łączyć z naszego systemu. Ale i tak było to dość uciążliwe. Dla każdego klienta musieliśmy przechowywać na każdym komputerze kilka haseł. VPN Połączenia, a przed połączeniem z którymkolwiek z nich, należało włączyć odpowiednią sieć VPN. Korzystaliśmy z tego rozwiązania przez długi czas. Jednak liczba klientów rosła, podobnie jak liczba sieci VPN, i wszystko to zaczynało być irytujące, więc trzeba było coś z tym zrobić. Było to szczególnie uciążliwe po ponownej instalacji systemu, kiedy musiałem ponownie wprowadzić dziesiątki połączeń VPN w nowym profilu Windows. Powiedziałem: „Mam już tego dość” i zacząłem się zastanawiać, co można z tym zrobić.
Tak się złożyło, że wszyscy klienci mieli jako routery urządzenia znanej firmy Mikrotik. Są bardzo funkcjonalne i wygodne w wykonywaniu niemal każdego zadania. Wadą jest to, że są „porwane”. Rozwiązaliśmy ten problem po prostu zamykając cały dostęp z zewnątrz. Trzeba było jednak jakoś mieć do nich dostęp, bez konieczności przychodzenia do klienta, bo… to jest długie. Po prostu zrobiliśmy tunele dla każdego takiego Mikrotika i podzieliliśmy je na oddzielny basen. bez żadnego routingu, dzięki czemu nie ma połączenia Twojej sieci z sieciami klientów i ich sieci między sobą.
Pomysł narodził się, aby mieć pewność, że kiedy kliknę na obiekt, którego potrzebuję w systemie, centralny serwer monitorujący, znając konta SSH wszystkich klientów Mikrotika, łączy się z żądanym, tworzy regułę przekazywania do żądanego hosta z wymaganego portu. Jest tu kilka punktów. Rozwiązanie nie jest uniwersalne - będzie działać tylko dla Mikrotika, ponieważ składnia poleceń jest inna dla wszystkich routerów. Ponadto takie przekierowania musiały zostać w jakiś sposób usunięte, a część serwerowa naszego systemu w zasadzie nie mogła w żaden sposób śledzić, czy zakończyłem sesję RDP. Cóż, takie przekierowanie to dziura dla klienta. Ale nie dążyliśmy do uniwersalności, bo... produkt był używany wyłącznie w naszej firmie i nie było myśli o udostępnieniu go społeczeństwu.
Każdy z problemów został rozwiązany na swój sposób. W momencie tworzenia reguły to przekazywanie było dostępne tylko dla jednego konkretnego zewnętrznego adresu IP (z którego inicjowano połączenie). W ten sposób uniknięto luki w zabezpieczeniach. Jednak przy każdym takim połączeniu do strony NAT dodawana była reguła Mikrotika, która nie była usuwana. I wszyscy wiedzą, że im więcej reguł, tym bardziej obciążony jest procesor routera. I w ogóle nie mogłem się pogodzić z tym, że pewnego dnia pójdę na jakiegoś Mikrotika, a tam będą setki martwych, bezużytecznych zasad.
Ponieważ nasz serwer nie może śledzić stanu połączenia, pozwól Mikrotikowi śledzić je samodzielnie. I napisałem skrypt, który na bieżąco monitorował wszystkie reguły przekazywania z konkretnym opisem i sprawdzał, czy połączenie TCP ma odpowiednią regułę. Jeśli przez jakiś czas go nie było, oznacza to, że połączenie prawdopodobnie zostało już nawiązane i to przekierowanie można usunąć. Wszystko się udało, scenariusz działał dobrze.
Swoją drogą, oto on:
global atmonrulecounter {"dontDelete"="dontDelete"}
:foreach i in=[/ip firewall nat find comment~"atmon_script_main"] do={
local dstport [/ip firewall nat get value-name="dst-port" $i]
local dstaddress [/ip firewall nat get value-name="dst-address" $i]
local dstaddrport "$dstaddress:$dstport"
#log warning message=$dstaddrport
local thereIsCon [/ip firewall connection find dst-address~"$dstaddrport"]
if ($thereIsCon = "") do={
set ($atmonrulecounter->$dstport) ($atmonrulecounter->$dstport + 1)
#:log warning message=($atmonrulecounter->$dstport)
if (($atmonrulecounter->$dstport) > 5) do={
#log warning message="Removing nat rules added automaticaly by atmon_script"
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_main_$dstport"]
/ip firewall nat remove [/ip firewall nat find comment~"atmon_script_sub_$dstport"]
set ($atmonrulecounter->$dstport) 0
}
} else {
set ($atmonrulecounter->$dstport) 0
}
}
Na pewno można było to zrobić piękniej, szybciej itp., ale zadziałało, nie załadowało Mikrotika i wykonało świetną robotę. Nareszcie mogliśmy połączyć się z serwerami i sprzętem sieciowym klientów za pomocą jednego kliknięcia. Bez otwierania VPN i wprowadzania haseł. Praca z systemem stała się naprawdę wygodna. Czas obsługi został skrócony, a my wszyscy spędziliśmy czas na pracy, a nie na podłączaniu się do niezbędnych obiektów.
Kopia zapasowa Mikrotika
Skonfigurowaliśmy kopię zapasową wszystkich Mikrotika na FTP. I ogólnie wszystko było w porządku. Ale kiedy trzeba było uzyskać kopię zapasową, trzeba było otworzyć ten FTP i tam go poszukać. Mamy system, w którym wszystkie routery są połączone; możemy komunikować się z urządzeniami poprzez SSH. Dlaczego nie zrobić tak, aby sam system codziennie pobierał kopie zapasowe wszystkich Mikrotików, pomyślałem. I zaczął to realizować. Połączyliśmy się, zrobiliśmy kopię zapasową i zabraliśmy ją do magazynu.
Kod skryptu w PHP do wykonania kopii zapasowej z Mikrotika:
<?php
$IP = '0.0.0.0';
$LOGIN = 'admin';
$PASSWORD = '';
$BACKUP_NAME = 'test';
$connection = ssh2_connect($IP, 22);
if (!ssh2_auth_password($connection, $LOGIN, $PASSWORD)) exit;
ssh2_exec($connection, '/system backup save name="atmon" password="atmon"');
stream_get_contents($connection);
ssh2_exec($connection, '/export file="atmon.rsc"');
stream_get_contents($connection);
sleep(40); // Waiting bakup makes
$sftp = ssh2_sftp($connection);
// Download backup file
$size = filesize("ssh2.sftp://$sftp/atmon.backup");
$stream = fopen("ssh2.sftp://$sftp/atmon.backup", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . ‘.backup’,$contents);
@fclose($stream);
sleep(3);
// Download RSC file
$size = filesize("ssh2.sftp://$sftp/atmon.rsc");
$stream = fopen("ssh2.sftp://$sftp/atmon.rsc", 'r');
$contents = '';
$read = 0;
$len = $size;
while ($read < $len && ($buf = fread($stream, $len - $read))) {
$read += strlen($buf);
$contents .= $buf;
}
file_put_contents ($BACKUP_NAME . ‘.rsc’,$contents);
@fclose($stream);
ssh2_exec($connection, '/file remove atmon.backup');
ssh2_exec($connection, '/file remove atmon.rsc');
?>
Kopia zapasowa wykonywana jest w dwóch formach – konfiguracji binarnej i tekstowej. Plik binarny pomaga szybko przywrócić wymaganą konfigurację, a tekstowy pozwala zrozumieć, co należy zrobić, jeśli nastąpi wymuszona wymiana sprzętu i nie można do niego wgrać pliku binarnego. W rezultacie otrzymaliśmy kolejną wygodną funkcjonalność w systemie. Co więcej, dodając nowy Mikrotik, nie było potrzeby niczego konfigurować, po prostu dodałem obiekt do systemu i założyłem dla niego konto przez SSH. Następnie system sam zajął się robieniem kopii zapasowych. Obecna wersja SaaS Veliam nie posiada jeszcze tej funkcjonalności, ale wkrótce ją przeportujemy.
Zrzuty ekranu jak to wyglądało w systemie wewnętrznym
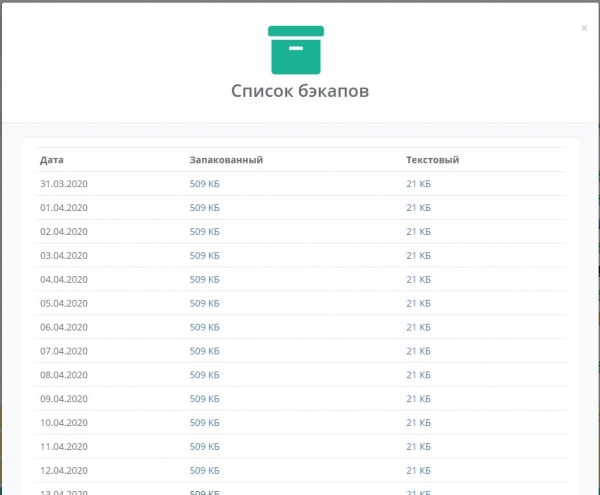
Przejście do normalnego przechowywania baz danych
Pisałem już powyżej, że pojawiły się artefakty. Czasami po prostu znikała cała lista obiektów w systemie, czasami podczas edycji obiektu informacja nie została zapisana i trzeba było trzykrotnie zmienić nazwę obiektu. To wszystkich strasznie irytowało. Zniknięcie obiektów zdarzało się rzadko i można je było łatwo przywrócić poprzez przywrócenie tego samego pliku, ale awarie podczas edycji obiektów zdarzały się dość często. Prawdopodobnie początkowo nie robiłem tego przez bazę danych, bo nie mieściło mi się w głowie, jak można zachować drzewo ze wszystkimi połączeniami w płaskiej tabeli. Jest płaski, ale drzewo jest hierarchiczne. Jednak dobrym rozwiązaniem dla wielokrotnego dostępu, a później (w miarę jak system staje się bardziej złożony) transakcyjnego, jest DBMS. Prawdopodobnie nie jestem pierwszym, który spotyka się z tym problemem. Zacząłem googlować. Okazało się, że wszystko zostało już przede mną wynalezione i istnieje kilka algorytmów budujących drzewo z płaskiej tabeli. Po zapoznaniu się z każdym z nich, wdrożyłem jeden z nich. Ale to była już nowa wersja systemu, bo... Faktycznie, z tego powodu musiałem sporo przepisać. Rezultat był naturalny, problemy związane z przypadkowym zachowaniem systemu zniknęły. Niektórzy mogą powiedzieć, że błędy mają charakter bardzo amatorski (skrypty jednowątkowe, przechowywanie informacji, do których uzyskiwano wielokrotny dostęp jednocześnie z różnych wątków w pliku itp.) w dziedzinie tworzenia oprogramowania. Może to prawda, ale moją główną pracą była administracja, a programowanie było dla mnie zajęciem pobocznym, a ja po prostu nie miałem doświadczenia w pracy w zespole programistów, gdzie takie podstawowe rzeczy od razu by mi zasugerował starszy towarzysze. Dlatego wszystkie te nierówności wypełniałem sam, ale materiału opanowałem bardzo dobrze. Poza tym moja praca wiąże się ze spotkaniami z klientami, działaniami mającymi na celu promocję firmy, szeregiem spraw administracyjnych wewnątrz firmy i wieloma, wieloma innymi rzeczami. Ale tak czy inaczej, na to, co już było, było zapotrzebowanie. Ja i chłopaki używaliśmy tego produktu w codziennej pracy. Były szczerze nieudane pomysły i rozwiązania, na które marnowano czas, ale ostatecznie stało się jasne, że to nie było działające narzędzie i nikt go nie używał i nie trafiło do Veliama.
Helpdesk – Helpdesk
Nie wypada wspomnieć o tym, jak powstał HelpDesk. To zupełnie inna historia, bo... w Veliam to już 3. zupełnie nowa wersja, która różni się od wszystkich poprzednich. Teraz jest to system prosty, intuicyjny, pozbawiony zbędnych bajerów, z możliwością integracji z domeną, a także możliwością dostępu do tego samego profilu użytkownika z dowolnego miejsca za pomocą linku z maila. A co najważniejsze, możliwe jest połączenie się z wnioskodawcą poprzez VNC z dowolnego miejsca (w domu lub w biurze) bezpośrednio z aplikacji bez VPN i przekierowania portów. Opowiem Ci, jak do tego doszliśmy, co wydarzyło się wcześniej i jakie straszne decyzje zostały podjęte.
Łączyliśmy się z użytkownikami poprzez dobrze znany TeamViewer. Wszystkie komputery, których użytkowników obsługujemy, mają zainstalowany telewizor. Pierwszą rzeczą, którą zrobiliśmy źle, a następnie usunęliśmy, było połączenie każdego klienta HD ze sprzętem. W jaki sposób użytkownik logował się do systemu HD, aby zostawić prośbę? Oprócz telewizji każdy miał na swoim komputerze zainstalowane specjalne narzędzie napisane w języku Lazarus (wiele osób tutaj przewróci oczami, a może nawet sprawdzi w Google, co to jest, ale najlepiej skompilowanym językiem, jaki znałem, był Delphi, a Lazarus jest prawie to samo, tylko za darmo). Ogólnie rzecz biorąc, użytkownik uruchomił specjalny plik wsadowy, który uruchomił to narzędzie, które z kolei odczytało HWID systemu, a następnie uruchomiła się przeglądarka i nastąpiła autoryzacja. Dlaczego to zrobiono? W niektórych firmach ilość obsługiwanych użytkowników liczona jest indywidualnie, a cena usługi za każdy miesiąc uzależniona jest od ilości osób. To zrozumiałe, mówisz, ale dlaczego jest to powiązane ze sprzętem? To bardzo proste, niektóre osoby wróciły do domu i złożyły prośbę na swoim domowym laptopie w stylu „uczyń mnie tutaj wszystkim pięknym”. Oprócz odczytania systemowego HWID, narzędzie pobrało aktualny identyfikator Teamviewer z rejestru i również przesłało go do nas. Teamviewer posiada API do integracji. I dokonaliśmy tej integracji. Ale był jeden haczyk. Za pośrednictwem tych API nie ma możliwości połączenia się z komputerem użytkownika, jeśli nie inicjuje on jawnie tej sesji i po próbie połączenia się z nią musi także kliknąć „potwierdź”. Wtedy wydawało nam się logiczne, że nikt nie powinien łączyć się bez prośby użytkownika, a skoro dana osoba jest przy komputerze, to on zainicjuje sesję i odpowie twierdząco na żądanie zdalnego połączenia. Wszystko okazało się nie tak. Wnioskodawcy zapomnieli nacisnąć przycisk rozpoczęcia sesji i musieli im to powiedzieć w rozmowie telefonicznej. Było to stratą czasu i frustracją po obu stronach procesu. Co więcej, nierzadko zdarza się, że dana osoba zostawia prośbę, ale może się połączyć tylko wtedy, gdy wychodzi na lunch. Ponieważ problem nie jest krytyczny i nie chce, aby jego proces pracy został przerwany. W związku z tym nie będzie naciskał żadnych przycisków, aby umożliwić połączenie. Tak pojawiła się dodatkowa funkcjonalność przy logowaniu do HelpDeska - odczytanie ID Teamviewera. Znaliśmy stałe hasło, które zostało użyte podczas instalacji Teamviewera. Dokładniej, wiedział o tym tylko system, ponieważ był wbudowany w instalator i nasz system. W związku z tym w aplikacji pojawił się przycisk połączenia, po kliknięciu którego nie trzeba było na nic czekać, ale Teamviewer natychmiast się otworzył i nastąpiło połączenie. W rezultacie istniały dwa rodzaje możliwych połączeń. Poprzez oficjalny interfejs API Teamviewer i nasz własny. Ku mojemu zaskoczeniu niemal natychmiast przestali używać tego pierwszego, chociaż była instrukcja, aby używać go tylko w wyjątkowych przypadkach i wtedy, gdy sam użytkownik wyrazi zgodę. Mimo to, zapewnij mi teraz bezpieczeństwo. Okazało się jednak, że wnioskodawcy tego nie potrzebowali. Wszystkie są w porządku, jeśli można się z nimi połączyć bez przycisku potwierdzenia. A ponieważ tak było, funkcjonalność połączenia API została później wyeliminowana jako niepotrzebna.
Przejście do wielowątkowości w Linux
Kwestia przyspieszenia przejścia skanera sieciowego pod kątem otwartości z góry określonej listy portów i prostego pingowania obiektów sieciowych już dawno zaczęła się pojawiać. Tutaj oczywiście pierwsze rozwiązanie jakie przychodzi na myśl to wielowątkowość. Ponieważ główny czas poświęcany na polecenie ping to oczekiwanie na zwrot pakietu, a kolejne polecenie ping nie może się rozpocząć, dopóki poprzedni pakiet nie zostanie zwrócony, w firmach, które miały nawet ponad 20 serwerów i sprzęt sieciowy, działało to już dość wolno. Chodzi o to, że jeden pakiet może zniknąć, ale nie należy od razu informować o tym administratora systemu. Po prostu bardzo szybko przestanie przyjmować taki spam. Oznacza to, że musisz pingować każdy obiekt więcej niż raz, zanim wyciągniesz wniosek o niedostępności. Nie wchodząc w szczegóły, należy to zrównoleglić, bo jeśli tego nie zrobimy, to najprawdopodobniej administrator systemu dowie się o problemie od klienta, a nie od systemu monitorującego.
Sam PHP nie obsługuje wielowątkowości od razu po wyjęciu z pudełka. Możliwość przetwarzania wieloprocesowego, można forkować. Ale tak naprawdę miałem już napisany mechanizm odpytywania i chciałem to zrobić tak, aby raz policzyć wszystkie potrzebne mi węzły z bazy, pingować wszystko na raz, czekać na odpowiedź od każdego i dopiero potem od razu pisać dane. Oszczędza to liczbę żądań odczytu. Wielowątkowość idealnie wpasowuje się w tę ideę. W PHP dostępny jest moduł PThreads, który pozwala na prawdziwą wielowątkowość, chociaż ustawienie tego w PHP 7.2 wymagało sporo majsterkowania, ale udało się. Skanowanie portów i pingowanie są teraz szybkie. I zamiast wcześniej np. 15 sekund na okrążenie, proces ten zaczął trwać 2 sekundy. To był dobry wynik.
Szybki audyt nowych firm
Jak powstała funkcjonalność gromadzenia różnych metryk i charakterystyk sprzętu? To proste. Czasami zlecamy nam po prostu audyt aktualnej infrastruktury IT. Cóż, to samo jest konieczne, aby przyspieszyć audyt nowego klienta. Potrzebowaliśmy czegoś, co pozwoli nam przyjechać do średniej lub dużej firmy i szybko zorientować się, co mają. Moim zdaniem ping w sieci wewnętrznej blokują tylko ci, którzy chcą sobie skomplikować życie, a z naszego doświadczenia wynika, że jest ich niewielu. Ale są też tacy ludzie. W związku z tym możesz szybko skanować sieci pod kątem obecności urządzeń za pomocą prostego polecenia ping. Następnie możemy je dodać i przeskanować w poszukiwaniu otwartych portów, które nas interesują. Tak naprawdę ta funkcjonalność już istniała; wystarczyło jedynie dodać polecenie z serwera centralnego do serwera podrzędnego, aby przeskanował określone sieci i dodał wszystko, co znalazł, do listy. Zapomniałem dodać, założono, że mamy już gotowy obraz ze skonfigurowanym systemem (serwer monitorujący slave), który w trakcie audytu możemy po prostu wyrzucić z klienta i podłączyć do naszej chmury.
Jednak wynik audytu zazwyczaj zawiera wiele różnych informacji, a jedną z nich jest rodzaj urządzeń w sieci. Interesowało nas przede wszystkim Windows serwery i stacje robocze Windows Jako część domeny. W średnich i dużych firmach brak domeny jest prawdopodobnie wyjątkiem, a nie regułą. Mówiąc tym samym językiem, firma średniej wielkości, moim zdaniem, to firma zatrudniająca ponad 100 osób. Musieliśmy opracować sposób na zbieranie danych ze wszystkich komputerów i serwerów Windows, znając ich adresy IP i konta administratorów domeny, bez konieczności instalowania oprogramowania na każdym z nich. Z pomocą przyszedł interfejs WMI. Windows Instrumentacja zarządzania (WMI) oznacza dosłownie instrumentację zarządzania WindowsWMI to jedna z podstawowych technologii centralnego zarządzania i monitorowania różnych części infrastruktury komputerowej pod kontrolą platformy Windows. Z wiki. Potem musiałem znowu pokombinować, żeby zbudować wmic (klient WMI) dla DebianGdy wszystko było gotowe, pozostało tylko zapytanie wymaganych węzłów za pomocą wmic o potrzebne informacje. Za pomocą WMI można uzyskać Windows Komputerowi można przechwycić niemal każdą informację, a co więcej, można nim sterować, np. zlecić jego restart. W ten sposób zbierane są informacje o Windows stacji i serwerów w naszym systemie. Uzupełnieniem były aktualne informacje o aktualnych wskaźnikach obciążenia systemu. O te informacje prosimy częściej, natomiast o informacje o sprzęcie rzadziej. Po tym audyt stał się nieco przyjemniejszy.
Decyzja dotycząca dystrybucji oprogramowania
Sami korzystamy z systemu na co dzień i jest on zawsze otwarty dla każdego pracownika technicznego. I pomyśleliśmy, że możemy podzielić się z innymi tym, co już mamy. System nie był jeszcze gotowy do dystrybucji. Wiele trzeba było przerobić, aby wersja lokalna zamieniła się w SaaS. Należą do nich zmiany w różnych aspektach technicznych systemu (połączenia zdalne, usługa wsparcia), analiza modułów do licencjonowania, sharding baz danych klientów, skalowanie każdej usługi i rozwój systemów automatycznej aktualizacji dla wszystkich części. Ale to będzie druga część artykułu.
Aktualizacja
Źródło: www.habr.com
