

Witam mieszkańców Chabrowska. Dziś rozpoczynają się zajęcia w pierwszej grupie kursu . W związku z tym chcielibyśmy opowiedzieć Państwu o tym, jak odbyło się otwarte webinarium dotyczące tego kursu.

В rozmawialiśmy o wyzwaniach stojących przed bazami danych SQL w dobie chmur i Kubernetesa. Jednocześnie przyjrzeliśmy się, jak bazy danych SQL adaptują się i mutują pod wpływem tych wyzwań.
Webinarium odbyło się , menedżer Google Cloud Practice Delivery w firmie EPAM Systems.
Kiedy drzewa były małe...
Na początek przypomnijmy sobie, jak pod koniec ubiegłego wieku rozpoczął się wybór DBMS. Nie będzie to jednak trudne, ponieważ wybór DBMS w tamtych czasach zaczął się i zakończył wyrocznia.

Pod koniec lat 90. i na początku XXI wieku w zasadzie nie było wyboru, jeśli chodzi o skalowalne przemysłowe bazy danych. Tak, istniały IBM DB2, Sybase i kilka innych baz danych, które pojawiały się i znikały, ale ogólnie nie były one tak zauważalne na tle Oracle. W związku z tym umiejętności inżynierów tamtych czasów były w jakiś sposób powiązane z jedynym istniejącym wyborem.
Oracle DBA musiał być w stanie:
- zainstaluj Oracle Server z pakietu dystrybucyjnego;
- skonfiguruj serwer Oracle:
- init.ora;
- słuchacz.ora;
- tworzyć:
- obszary tabel;
- schemat;
- użytkownicy;
— wykonaj kopię zapasową i przywróć;
— przeprowadzić monitorowanie;
— radzić sobie z nieoptymalnymi żądaniami.
Jednocześnie nie było specjalnych wymagań ze strony Oracle DBA:
- potrafić wybrać optymalny system DBMS lub inną technologię przechowywania i przetwarzania danych;
- zapewnić wysoką dostępność i skalowalność poziomą (nie zawsze był to problem DBA);
- dobra znajomość tematyki, infrastruktury, architektury aplikacji, systemu operacyjnego;
- ładować i rozładowywać dane, migrować dane pomiędzy różnymi systemami DBMS.
Ogólnie rzecz biorąc, jeśli mówimy o wyborze w tamtych czasach, przypomina to wybór w sowieckim sklepie pod koniec lat 80.:

Nasz czas
Od tego czasu oczywiście drzewa urosły, świat się zmienił i stał się mniej więcej taki:

Zmienił się także rynek DBMS, co wyraźnie widać z najnowszego raportu Gartnera:
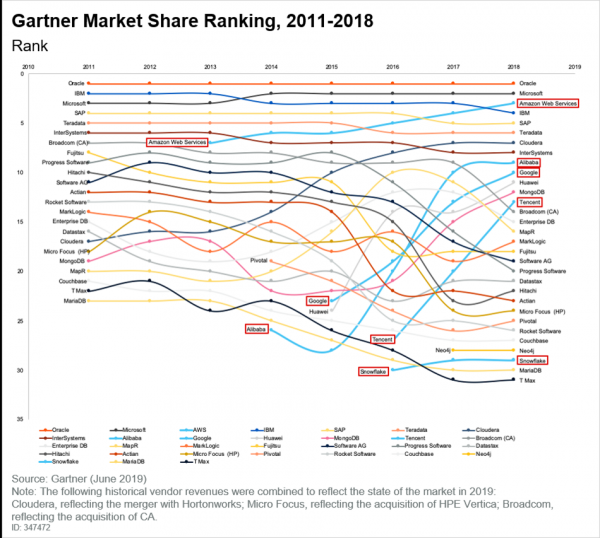
I tutaj należy zauważyć, że chmury, których popularność rośnie, zajęły swoją niszę. Jeśli przeczytamy ten sam raport Gartnera, zobaczymy następujące wnioski:
- Wielu klientów jest na dobrej drodze do przeniesienia aplikacji do chmury.
- Nowe technologie pojawiają się najpierw w chmurze i nie jest faktem, że kiedykolwiek przeniosą się do infrastruktury pozachmurowej.
- Model cenowy typu pay-as-you-go stał się powszechny. Każdy chce płacić tylko za to, z czego korzysta i nie jest to nawet trend, a po prostu stwierdzenie faktu.
Co teraz?
Dziś wszyscy jesteśmy w chmurze. A pytania, które się dla nas pojawiają, są kwestiami wyboru. I jest ogromny, nawet jeśli mówimy tylko o wyborze technologii DBMS w formacie On-premise. Mamy również usługi zarządzane i SaaS. Zatem wybór z roku na rok staje się coraz trudniejszy.
Oprócz pytań o wybór, są też czynniki ograniczające:
- cena. Wiele technologii nadal kosztuje;
- umiejętności. Jeśli mówimy o wolnym oprogramowaniu, pojawia się kwestia umiejętności, ponieważ wolne oprogramowanie wymaga wystarczających kompetencji od osób, które je wdrażają i obsługują;
- funkcjonalny. Nie wszystkie usługi dostępne w chmurze i zbudowane, powiedzmy, nawet na tym samym Postgresie, mają te same funkcje, co Postgres On-premise. Jest to istotny czynnik, który należy poznać i zrozumieć. Co więcej, czynnik ten staje się ważniejszy niż znajomość niektórych ukrytych możliwości pojedynczego SZBD.
Czego oczekuje się teraz od DA/DE:
- dobre zrozumienie obszaru tematycznego i architektury aplikacji;
- umiejętność prawidłowego doboru odpowiedniej technologii DBMS, biorąc pod uwagę stojące przed nią zadanie;
- umiejętność wyboru optymalnej metody wdrożenia wybranej technologii w kontekście istniejących ograniczeń;
- możliwość wykonania transferu i migracji danych;
- umiejętność wdrażania i obsługi wybranych rozwiązań.
Poniżej przykład w oparciu o GCP pokazuje, jak działa wybór jednej lub drugiej technologii pracy z danymi w zależności od ich struktury:
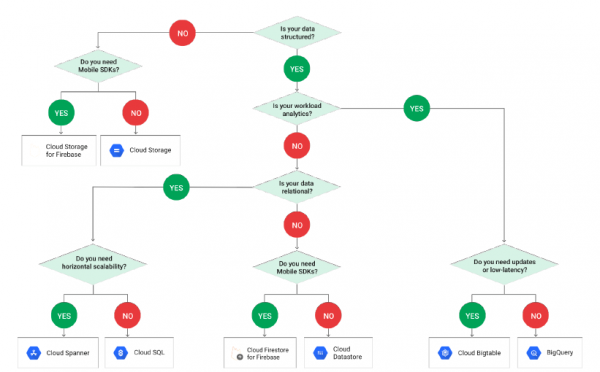
Należy pamiętać, że PostgreSQL nie jest uwzględniony w schemacie, a to dlatego, że jest ukryty pod terminologią CloudSQL. A kiedy dotrzemy do Cloud SQL, musimy ponownie dokonać wyboru:
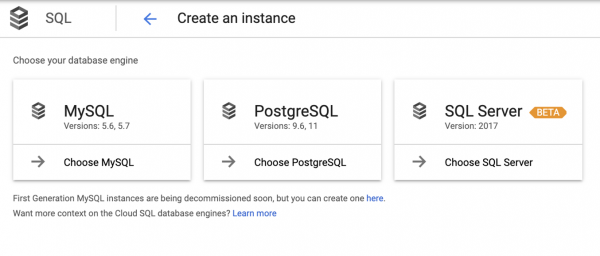
Należy zaznaczyć, że wybór ten nie zawsze jest oczywisty, dlatego twórcy aplikacji często kierują się intuicją.
Razem:
- Im dalej zajdziesz, tym bardziej nagląca staje się kwestia wyboru. I nawet jeśli spojrzysz tylko na GCP, usługi zarządzane i SaaS, to wzmianka o RDBMS pojawia się dopiero w 4. kroku (a tam Spanner jest w pobliżu). Dodatkowo w 5 kroku pojawia się wybór PostgreSQL, a obok niego są jeszcze MySQL i SQL Server, czyli wszystkiego jest mnóstwo, ale trzeba wybierać.
- Nie wolno nam zapominać o ograniczeniach na tle pokus. Zasadniczo każdy chce klucza Spanner, ale jest on drogi. W rezultacie typowe żądanie wygląda mniej więcej tak: „Proszę, zróbcie z nas Spannera, ale za cenę Cloud SQL jesteście profesjonalistami!”

Ale co robić?
Nie udając, że jest to prawda ostateczna, powiedzmy, co następuje:
Musimy zmienić nasze podejście do nauki:
- nie ma sensu uczyć administratorów baz danych w taki sam sposób, w jaki uczono wcześniej administratorów baz danych;
- znajomość jednego produktu już nie wystarczy;
- ale znajomość dziesiątek na poziomie jednego jest niemożliwa.
Musisz wiedzieć nie tylko i ile kosztuje produkt, ale także:
- przypadek użycia jego zastosowania;
- różne metody wdrażania;
- zalety i wady każdej metody;
- podobnych i alternatywnych produktów, aby dokonać świadomego i optymalnego wyboru, a nie zawsze na korzyść znanego produktu.
Trzeba także umieć migrować dane i rozumieć podstawowe zasady integracji z ETL.
prawdziwy przypadek
W niedawnej przeszłości konieczne było stworzenie backendu dla aplikacji mobilnej. Zanim rozpoczęły się nad nim prace, backend był już opracowany i gotowy do wdrożenia, a zespół programistów spędził nad tym projektem około dwóch lat. Postawiono następujące zadania:
- zbuduj CI/CD;
- przegląd architektury;
- uruchomić to wszystko.
Sama aplikacja była mikroserwisami, a kod Python/Django został napisany od podstaw i bezpośrednio w GCP. Jeśli chodzi o grupę docelową, założono, że będą to dwa regiony – USA i UE, a ruch będzie dystrybuowany poprzez Global Load Balancer. Wszystkie obciążenia i obciążenia obliczeniowe działały w Google Kubernetes Engine.
Jeśli chodzi o dane, były 3 struktury:
- Magazyn w chmurze;
- Magazyn danych;
- Chmura SQL (PostgreSQL).
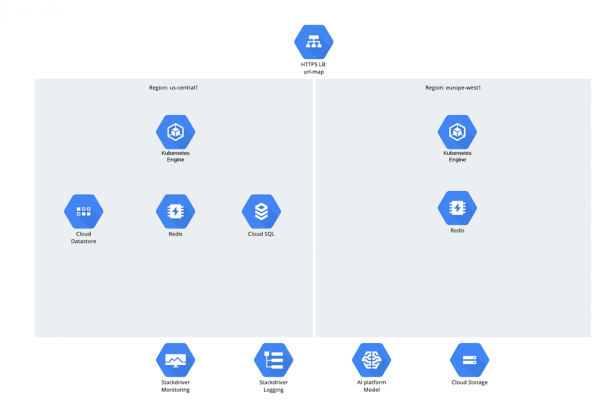
Można się zastanawiać, dlaczego wybrano Cloud SQL? Prawdę mówiąc, takie pytanie wywołało w ostatnich latach pewną niezręczną pauzę - można odnieść wrażenie, że ludzie zaczęli się wstydzić relacyjnych baz danych, a mimo to nadal aktywnie z nich korzystają ;-).
W naszym przypadku wybrano Cloud SQL z następujących powodów:
- Jak wspomnieliśmy, aplikacja została stworzona przy użyciu Django i posiada model mapowania trwałych danych z bazy SQL na obiekty Pythona (Django ORM).
- Sam framework obsługiwał dość skończoną listę systemów DBMS:
- PostgreSQL;
- MariaDB;
- MySQL;
- Wyrocznia;
- SQLite.
W związku z tym PostgreSQL został wybrany z tej listy raczej intuicyjnie (cóż, tak naprawdę to nie Oracle jest wyborem).
Czego brakowało:
- aplikacja została wdrożona tylko w 2 regionach, a w planach pojawił się trzeci (Azja);
- Baza danych znajdowała się w regionie Ameryki Północnej (Iowa);
- ze strony klienta istniały obawy co do możliwości opóźnienia w dostępie z Europy i Azji oraz przerwy czynny w przypadku przestoju DBMS.
Pomimo tego, że samo Django potrafi pracować równolegle z kilkoma bazami danych i dzielić je na odczyt i zapis, w aplikacji nie było zbyt wiele pisania (ponad 90% to czytanie). I w ogóle, i w ogóle, jeśli można to zrobić czytaj-replika głównej bazy w Europie i Azjibyłoby to rozwiązanie kompromisowe. No i co w tym takiego skomplikowanego?
Trudność polegała na tym, że klient nie chciał rezygnować z usług zarządzanych i Cloud SQL. Możliwości Cloud SQL są obecnie ograniczone. Cloud SQL obsługuje wysoką dostępność (HA) i replikę odczytu (RR), ale ten sam RR jest obsługiwany tylko w jednym regionie. Po utworzeniu bazy danych w regionie amerykańskim nie można wykonać repliki do odczytu w regionie europejskim za pomocą Cloud SQL, chociaż sam Postgres nie przeszkadza ci w tym. Korespondencja z pracownikami Google nie prowadziła donikąd i kończyła się obietnicami w stylu „znamy problem i pracujemy nad nim, kiedyś problem zostanie rozwiązany”.
Jeśli krótko wymienimy możliwości Cloud SQL, będzie to wyglądać mniej więcej tak:
1. Wysoka dostępność (HA):
- w jednym regionie;
- poprzez replikację dyskową;
- Silniki PostgreSQL nie są używane;
- możliwe sterowanie automatyczne i ręczne - przełączanie awaryjne/awaryjne;
- Podczas przełączania system DBMS jest niedostępny przez kilka minut.
2. Przeczytaj replikę (RR):
- w jednym regionie;
- gorący tryb gotowości;
- Replikacja strumieniowa PostgreSQL.
Ponadto, jak to zwykle bywa, wybierając technologię, zawsze masz do czynienia z jakąś ograniczenia:
- klient nie chciał tworzyć podmiotów i korzystać z IaaS inaczej niż poprzez GKE;
- klient nie chciałby wdrażać samoobsługowego PostgreSQL/MySQL;
- No cóż, ogólnie rzecz biorąc, Google Spanner byłby całkiem odpowiedni, gdyby nie jego cena, jednak Django ORM nie może z nim współpracować, ale to dobrze.
Biorąc pod uwagę zaistniałą sytuację, klient otrzymał pytanie uzupełniające: „Czy możesz zrobić coś podobnego, aby działało jak Google Spanner, ale jednocześnie działało z Django ORM?”
Opcja rozwiązania nr 0
Pierwsze co mi przyszło do głowy:
- pozostań w CloudSQL;
- nie będzie wbudowanej replikacji pomiędzy regionami w jakiejkolwiek formie;
- spróbuj dołączyć replikę do istniejącego Cloud SQL przez PostgreSQL;
- uruchom gdzieś i w jakiś sposób instancję PostgreSQL, ale przynajmniej nie dotykaj mastera.
Niestety okazało się, że nie da się tego zrobić, bo nie ma dostępu do hosta (jest w zupełnie innym projekcie) - pg_hba itd., a także nie ma dostępu pod superużytkownikiem.
Opcja rozwiązania nr 1
Po głębszej refleksji i uwzględnieniu wcześniejszych okoliczności tok myślenia nieco się zmienił:
- Wciąż staramy się pozostać przy CloudSQL, jednak przechodzimy na MySQL, gdyż Cloud SQL by MySQL posiada zewnętrznego mastera, który:
— jest serwerem proxy dla zewnętrznego MySQL;
- wygląda jak instancja MySQL;
- wymyślony do migracji danych z innych chmur lub lokalnie.
Ponieważ ustawienie replikacji MySQL nie wymaga dostępu do hosta, w zasadzie wszystko działało, ale było bardzo niestabilne i niewygodne. A kiedy poszliśmy dalej, zrobiło się już zupełnie strasznie, bo całą konstrukcję rozłożyliśmy za pomocą terraformu i nagle okazało się, że zewnętrzny master nie był wspierany przez terraform. Tak, Google ma CLI, ale z jakiegoś powodu wszystko tu od czasu do czasu działało - czasem jest tworzone, czasem nie. Być może dlatego, że CLI zostało wynalezione do zewnętrznej migracji danych, a nie do replik.
Właściwie w tym momencie stało się jasne, że Cloud SQL w ogóle się nie nadaje. Jak mówią, zrobiliśmy wszystko, co mogliśmy.
Opcja rozwiązania nr 2
Ponieważ nie dało się pozostać w frameworku Cloud SQL, staraliśmy się sformułować wymagania na rozwiązanie kompromisowe. Okazało się, że wymagania są następujące:
- praca w Kubernetesie, maksymalne wykorzystanie zasobów i możliwości Kubernetesa (DCS,…) i GCP (LB,…);
- brak balastu od sterty niepotrzebnych rzeczy w chmurze typu proxy HA;
- możliwość uruchomienia PostgreSQL lub MySQL w głównym regionie HA; w innych regionach - HA z RR głównego regionu plus jego kopia (dla niezawodności);
- multi master (nie chciałem się z nim kontaktować, ale nie było to zbyt ważne)
.
W wyniku tych żądań podpowiednie DBMS i opcje wiązania:
- Galeria MySQL;
- KaraluchDB;
- Narzędzia PostgreSQL
:
- pgpool-II;
— Patroni.
Galera MySQL
Technologia MySQL Galera została opracowana przez Codership i jest wtyczką do InnoDB. Osobliwości:
- wielu mistrzów;
- replikacja synchroniczna;
- odczyt z dowolnego węzła;
- nagrywanie do dowolnego węzła;
- wbudowany mechanizm HA;
- Istnieje wykres Helma z Bitnami.
KaraluchDB
Według opisu rzecz jest absolutnie bombowa i jest projektem open source napisanym w Go. Głównym uczestnikiem jest Cockroach Labs (założone przez ludzi z Google). Ten relacyjny system DBMS został pierwotnie zaprojektowany do dystrybucji (ze skalowaniem poziomym od razu po wyjęciu z pudełka) i odporny na błędy. Jej autorzy z firmy nakreślili cel, jakim jest „połączenie bogactwa funkcjonalności SQL z dostępnością poziomą znaną z rozwiązań NoSQL”.
Miłym dodatkiem jest obsługa protokołu połączenia post-gres.
Pgpool
Jest to dodatek do PostgreSQL, a właściwie nowy podmiot, który przejmuje wszystkie połączenia i je przetwarza. Posiada własny moduł równoważenia obciążenia i parser, licencjonowany na licencji BSD. Daje spore możliwości, jednak wygląda nieco przerażająco, gdyż obecność nowego bytu może stać się źródłem dodatkowych przygód.
Patroni
To ostatnia rzecz, na którą padł mój wzrok i, jak się okazało, nie na próżno. Patroni to narzędzie typu open source, które w zasadzie jest demonem języka Python, który umożliwia automatyczne utrzymywanie klastrów PostgreSQL z różnymi typami replikacji i automatycznym przełączaniem ról. Rzecz okazała się bardzo ciekawa, gdyż dobrze integruje się z kostką i nie wprowadza żadnych nowych bytów.
Co ostatecznie wybrałeś?
Wybór nie był łatwy:
- KaraluchDB - ogień, ale ciemny;
- Galera MySQL - też nieźle, jest używany w wielu miejscach, ale MySQL;
- Pgpool — dużo niepotrzebnych bytów, taka sobie integracja z chmurą i K8s;
- Patroni - doskonała integracja z K8s, brak zbędnych bytów, dobrze integruje się z GCP LB.
Zatem wybór padł na Patroni.
odkrycia
Czas na krótkie podsumowanie. Tak, świat infrastruktury IT znacząco się zmienił, a to dopiero początek. A jeśli wcześniej chmury były po prostu innym rodzajem infrastruktury, teraz wszystko jest inne. Co więcej, innowacje w chmurach stale się pojawiają, będą pojawiać się, a być może pojawią się tylko w chmurach i dopiero wtedy, dzięki staraniom startupów, zostaną przeniesione do On-premise.
Jeśli chodzi o SQL, SQL będzie żywy. Oznacza to, że musisz znać PostgreSQL i MySQL i umieć z nimi pracować, ale jeszcze ważniejsza jest umiejętność ich prawidłowego używania.
Źródło: www.habr.com
