

Ostatnio na Habré zaczęły pojawiać się coraz częściej wpisy o tym, jak dobry jest Telegram, jak genialni i doświadczeni są bracia Durov w budowaniu systemów sieciowych itp. Jednocześnie bardzo niewiele osób naprawdę zanurzyło się w urządzeniu technicznym - co najwyżej używają dość prostego (i bardzo różniącego się od MTProto) API Bota opartego na JSON i zwykle po prostu akceptują na wierze wszystkie te pochwały i PR, które krążą wokół posłańca. Prawie półtora roku temu mój kolega z NPO Echelon Vasily (niestety jego konto na Habré zostało usunięte wraz z wersją roboczą) zaczął pisać od podstaw własnego klienta Telegrama w Perlu, a później dołączył autor tych linijek. Dlaczego Perl, niektórzy od razu zapytają? Bo są już takie projekty w innych językach, właściwie to nie o to chodzi, gdzie mógłby być jakikolwiek inny język skończona biblioteka, a zatem autor musi iść na całość od zera. Co więcej, kryptografia jest czymś takim - ufaj, ale weryfikuj. W przypadku produktu zorientowanego na bezpieczeństwo nie można po prostu polegać na gotowej bibliotece dostawcy i ślepo w to wierzyć (jest to jednak temat na więcej w drugiej części). W tej chwili biblioteka działa całkiem dobrze na poziomie „średnim” (pozwala na wykonywanie dowolnych żądań API).
Jednak w tej serii postów nie będzie dużo kryptografii i matematyki. Ale będzie wiele innych detali technicznych i architektonicznych kul (przyda się też tym, którzy nie będą pisać od podstaw, tylko będą korzystać z biblioteki w dowolnym języku). Tak więc głównym celem była próba wdrożenia klienta od podstaw zgodnie z oficjalną dokumentacją. To znaczy, załóżmy, że kod źródłowy oficjalnych klientów jest zamknięty (ponownie w drugiej części ujawnimy bardziej szczegółowo temat, czym tak naprawdę jest to się dzieje tak), ale jak za dawnych czasów istnieje na przykład standard typu RFC - czy można napisać klienta według samej specyfikacji, „bez podglądania” źródła, nawet oficjalnego (Telegram Desktop, mobile) , nawet nieoficjalny Telethon?
Spis treści:
Dokumentacja ... czy jest? Czy to prawda?..
Fragmenty notatek do tego artykułu zaczęto zbierać latem ubiegłego roku. Cały ten czas na oficjalnej stronie dokumentacja pochodziła z warstwy 23, tj. utknął gdzieś w 2014 roku (pamiętasz, wtedy nie było jeszcze nawet kanałów?). Oczywiście teoretycznie powinno to pozwolić na wdrożenie klienta z ówczesną funkcjonalnością w 2014 roku. Ale nawet w tym stanie dokumentacja była po pierwsze niekompletna, a po drugie miejscami sobie zaprzeczała. Nieco ponad miesiąc temu, we wrześniu 2019 r., było przypadkowo okazało się, że na stronie jest duża aktualizacja dokumentacji, dla zupełnie świeżej warstwy 105, z dopiskiem, że teraz wszystko trzeba przeczytać od nowa. Rzeczywiście, wiele artykułów zostało poprawionych, ale wiele pozostało niezmienionych. Dlatego czytając poniższą krytykę dotyczącą dokumentacji, należy pamiętać, że niektóre z tych rzeczy nie są już istotne, ale niektóre nadal są. W końcu 5 lat we współczesnym świecie to nie tylko dużo, ale bardzo dużo. Od tego czasu (zwłaszcza jeśli nie brać pod uwagę odrzuconych i wskrzeszonych od tego czasu geoczatów) liczba metod API w schemacie wzrosła ze stu do ponad dwustu pięćdziesięciu!
Od czego zaczynasz jako młody pisarz?
Nie ma znaczenia, czy piszesz od podstaw, czy korzystasz np. z gotowych bibliotek typu lub , w każdym razie będziesz najpierw potrzebować zarejestruj swoją aplikację - api_id и api_hash (ci, którzy pracowali z interfejsem API VKontakte, natychmiast rozumieją), za pomocą którego serwer zidentyfikuje aplikację. Ten musieć ze względów prawnych, ale o tym, dlaczego autorzy bibliotek nie mogą go opublikować, powiemy więcej w drugiej części. Być może będziesz zadowolony z wartości testowych, choć są one bardzo ograniczone - faktem jest, że teraz możesz zarejestrować się na swój numer tylko jeden aplikacji, więc nie spiesz się.
Teraz z technicznego punktu widzenia powinno nas interesować to, że po rejestracji powinniśmy otrzymywać powiadomienia z Telegrama o aktualizacjach dokumentacji, protokołu itp. Oznacza to, że można założyć, że strona z dokami została po prostu „oceniona” i kontynuowała współpracę szczególnie z tymi, którzy zaczęli zdobywać klientów, ponieważ. to jest łatwiejsze. Ale nie, nic takiego nie zaobserwowano, nie nadeszła żadna informacja.
A jeśli piszesz od zera, to wykorzystanie otrzymanych parametrów jest właściwie jeszcze daleko. Chociaż i mówi o nich najpierw w Pierwsze kroki, w rzeczywistości najpierw musisz je wdrożyć - ale jeśli wierzysz na końcu strony ogólnego opisu protokołu, potem zupełnie na próżno.
Tak naprawdę, zarówno przed MTProto, jak i po, na kilku poziomach jednocześnie (jak mówią zagraniczni networkerzy pracujący w jądrze systemu operacyjnego, naruszenie warstwy), na przeszkodzie stanie duży, bolesny i straszny temat…
Serializacja binarna: TL (Type Language) i jego schemat oraz warstwy i wiele innych przerażających słów
Ten temat jest w rzeczywistości kluczem do problemów Telegrama. I będzie wiele okropnych słów, jeśli spróbujesz się w to zagłębić.
A więc schemat. Jeśli pamiętasz to słowo, powiedz: Pomyślałeś dobrze. Cel jest ten sam: jakiś język opisujący możliwy zestaw przesyłanych danych. W rzeczywistości na tym kończy się podobieństwo. Jeśli ze strony , lub z drzewa źródłowego oficjalnego klienta, spróbujemy otworzyć jakiś schemat, zobaczymy coś takiego:
int ? = Int;
long ? = Long;
double ? = Double;
string ? = String;
vector#1cb5c415 {t:Type} # [ t ] = Vector t;
rpc_error#2144ca19 error_code:int error_message:string = RpcError;
rpc_answer_unknown#5e2ad36e = RpcDropAnswer;
rpc_answer_dropped_running#cd78e586 = RpcDropAnswer;
rpc_answer_dropped#a43ad8b7 msg_id:long seq_no:int bytes:int = RpcDropAnswer;
msg_container#73f1f8dc messages:vector<%Message> = MessageContainer;
---functions---
set_client_DH_params#f5045f1f nonce:int128 server_nonce:int128 encrypted_data:bytes = Set_client_DH_params_answer;
ping#7abe77ec ping_id:long = Pong;
ping_delay_disconnect#f3427b8c ping_id:long disconnect_delay:int = Pong;
invokeAfterMsg#cb9f372d msg_id:long query:!X = X;
invokeAfterMsgs#3dc4b4f0 msg_ids:Vector<long> query:!X = X;
account.updateProfile#78515775 flags:# first_name:flags.0?string last_name:flags.1?string about:flags.2?string = User;
account.sendChangePhoneCode#8e57deb flags:# allow_flashcall:flags.0?true phone_number:string current_number:flags.0?Bool = auth.SentCode;Osoba, która zobaczy to pierwszy raz, intuicyjnie rozpozna tylko część tego, co jest napisane – no, to są podobno struktury (choć gdzie jest nazwa, z lewej czy z prawej?), Są w nich pola, po których typ przechodzi przez okrężnicę… prawdopodobnie. Tutaj w nawiasach kątowych są chyba szablony jak w C++ (w rzeczywistości nie do końca). A co znaczą wszystkie inne symbole, pytajniki, wykrzykniki, procenty, kraty (a oczywiście w różnych miejscach oznaczają co innego), przedstawiają gdzieś, ale nie gdzieś, liczby szesnastkowe - i najważniejsze, jak z tego wybrnąć regularne (który nie zostanie odrzucony przez serwer) strumień bajtów? Musisz przeczytać dokumentację (Tak, w pobliżu są linki do schematu w wersji JSON - ale to nie czyni tego jaśniejszym).
Otwieranie strony i zanurzyć się w magiczny świat grzybów i matematyki dyskretnej, coś podobnego do matan na 4 roku. Alfabet, typ, wartość, kombinator, kombinator funkcjonalny, postać normalna, typ złożony, typ polimorficzny... a to dopiero pierwsza strona! Dalej czeka na Ciebie , który, choć zawiera już przykład trywialnej prośby i odpowiedzi, w ogóle nie daje odpowiedzi na bardziej typowe przypadki, co oznacza, że będziesz musiał przebrnąć przez powtarzanie matematyki przetłumaczonej z rosyjskiego na angielski na ośmiu kolejnych zagnieżdżonych strony!
Czytelnicy zaznajomieni z językami funkcyjnymi i automatycznym wnioskowaniem o typach oczywiście widzieli w tym języku opisy, nawet z przykładu, o wiele bardziej znane i mogą powiedzieć, że generalnie nie jest to w zasadzie złe. Zastrzeżeniami do tego są:
- Tak, cel brzmi dobrze, ale niestety nie osiągnięty
- edukacja na rosyjskich uniwersytetach jest różna nawet wśród specjalności informatycznych - nie wszyscy czytają odpowiedni kurs
- Wreszcie, jak zobaczymy, w praktyce tak jest nie jest wymagane, ponieważ używany jest tylko ograniczony podzbiór nawet opisanej TL
Jak zostało powiedziane na kanale #perl w sieci FreeNode IRC, próbując zaimplementować bramkę z Telegrama do Matrixa (tłumaczenie cytatu jest niedokładne z pamięci):
Wydaje się, że ktoś, kto po raz pierwszy zapoznał się z teorią typów, podekscytował się i zaczął się nią bawić, nie bardzo dbając o to, czy jest to konieczne w praktyce.
Przekonaj się sam czy potrzeba gołych typów (int, long itp.) jako czegoś elementarnego nie rodzi pytań – w końcu trzeba je implementować ręcznie – np. spróbujmy z nich wywodzić wektor. czyli w rzeczywistości tablica, jeśli nazwiesz powstałe rzeczy po imieniu.
Ale przedtem
Krótki opis podzbioru składni TL dla tych, którzy nie… czytają oficjalnej dokumentacji
constructor = Type;
myVec ids:Vector<long> = Type;
fixed#abcdef34 id:int = Type2;
fixedVec set:Vector<Type2> = FixedVec;
constructorOne#crc32 field1:int = PolymorType;
constructorTwo#2crc32 field_a:long field_b:Type3 field_c:int = PolymorType;
constructorThree#deadcrc bit_flags_of_what_really_present:# optional_field4:bit_flags_of_what_really_present.1?Type = PolymorType;
an_id#12abcd34 id:int = Type3;
a_null#6789cdef = Type3;Zawsze rozpoczyna definicję projektant, po czym opcjonalnie (w praktyce zawsze) poprzez symbol # musi być CRC32 ze znormalizowanego ciągu opisu danego typu. Następnie następuje opis pól, jeśli są - typ może być pusty. Całość kończy się znakiem równości, nazwą typu, do którego należy dany konstruktor – czyli w istocie podtyp. Typ po prawej stronie znaku równości to polimorficzny - czyli może odpowiadać kilku określonym typom.
Jeśli definicja występuje po wierszu ---functions---, to składnia pozostanie taka sama, ale znaczenie będzie inne: konstruktor stanie się nazwą funkcji RPC, pola staną się parametrami (no, czyli pozostanie dokładnie taka sama dana struktura jak opisana poniżej, będzie to po prostu podane znaczenie), a „typ polimorficzny” to typ zwróconego wyniku. To prawda, że \uXNUMXb\uXNUMXbnadal pozostanie polimorficzny - właśnie zdefiniowany w sekcji ---types---, a ten konstruktor nie będzie brany pod uwagę. Wpisz przeciążenia wywoływanych funkcji według ich argumentów, tj. z jakiegoś powodu kilka funkcji o tej samej nazwie, ale z innym podpisem, jak w C++, nie jest dostępnych w TL.
Dlaczego „konstruktor” i „polimorficzny”, jeśli nie jest to OOP? No faktycznie łatwiej będzie komuś pomyśleć o tym w kategoriach OOP - typ polimorficzny jako klasa abstrakcyjna, a konstruktory to jego bezpośrednie klasy potomne zresztą final w terminologii wielu języków. W rzeczywistości, oczywiście, tutaj podobieństwo z prawdziwie przeciążonymi metodami konstruktorów w językach programowania OO. Ponieważ są tu tylko struktury danych, nie ma metod (chociaż poniższy opis funkcji i metod może wywołać zamieszanie w głowie co do tego, czym one są, ale chodzi o coś innego) - możesz myśleć o konstruktorze jako o wartość od której w trakcie budowy type podczas odczytu strumienia bajtów.
Jak to się stało? Deserializator, który zawsze odczytuje 4 bajty, widzi wartość 0xcrc32 - i rozumie, co będzie dalej field1 z typem int, tj. odczytuje dokładnie 4 bajty na tym polu nakładającym się na typ PolymorType Czytać. Widzi 0x2crc32 i rozumie, że są jeszcze dwa pola dalej, po pierwsze long, więc czytamy 8 bajtów. A potem znowu typ złożony, który jest deserializowany w ten sam sposób. Na przykład, Type3 można zadeklarować w schemacie, gdy tylko odpowiednio dwa konstruktory muszą się z nimi spotkać 0x12abcd34, po czym musisz przeczytać kolejne 4 bajty intLub 0x6789cdef, po którym nie będzie nic. Cokolwiek innego - musisz rzucić wyjątek. W każdym razie po tym wracamy do odczytu 4 bajtów int marginesy field_c в constructorTwo i na tym kończymy czytać nasze PolymorType.
Wreszcie, jeśli zostanie złapany 0xdeadcrc dla constructorThree, wtedy sprawy się komplikują. Nasze pierwsze pole bit_flags_of_what_really_present z typem # - w rzeczywistości jest to tylko alias dla typu natco oznacza „liczbę naturalną”. Nawiasem mówiąc, w rzeczywistości unsigned int jest jedynym przypadkiem, w którym liczby bez znaku znajdują się w rzeczywistych schematach. Następna jest więc konstrukcja ze znakiem zapytania, co oznacza, że to jest pole - będzie obecne na przewodzie tylko wtedy, gdy odpowiedni bit zostanie ustawiony w polu, do którego się odwołuje (w przybliżeniu jak operator trójskładnikowy). Załóżmy więc, że ten bit był włączony, a następnie musisz przeczytać pole takie jak Type, który w naszym przykładzie ma 2 konstruktory. Jeden jest pusty (składa się tylko z identyfikatora), drugi ma pole ids z typem ids:Vector<long>.
Możesz pomyśleć, że zarówno szablony, jak i generyczne są dobre lub Java. Ale nie. Prawie. Ten pojedynczy w przypadku nawiasów ostrych w rzeczywistych obwodach i jest używany TYLKO dla wektora. W strumieniu bajtów będą to 4 bajty CRC32 dla samego typu Vector, zawsze to samo, następnie 4 bajty - liczba elementów tablicy, a następnie same te elementy.
Dodaj do tego fakt, że serializacja zawsze występuje w słowach 4 bajtowych, wszystkie typy są jej wielokrotnościami - opisane są również typy wbudowane bytes и string z ręczną serializacją długości i tym wyrównaniem o 4 - cóż, wydaje się to brzmieć normalnie, a nawet w miarę wydajnie? Co prawda TL ponoć jest wydajną serializacją binarną, ale do diabła z nimi, czy przy rozszerzaniu czegokolwiek, nawet wartości boolowskich i ciągów jednoznakowych do 4 bajtów, JSON nadal będzie znacznie grubszy? Spójrz, nawet niepotrzebne pola można pominąć flagami bitowymi, wszystko jest w porządku, a nawet rozszerzalne na przyszłość, czy dodałeś później nowe opcjonalne pola do konstruktora? ..
Ale nie, jeśli nie przeczytasz mojego krótkiego opisu, ale pełną dokumentację i pomyślisz o wdrożeniu. Po pierwsze, CRC32 konstruktora jest obliczane na podstawie znormalizowanego ciągu opisu tekstu schematu (usuń dodatkowe spacje itp.) - więc jeśli zostanie dodane nowe pole, zmieni się ciąg opisu typu, a co za tym idzie jego CRC32, a co za tym idzie serializacja. A co by zrobił stary klient gdyby otrzymał pole z ustawionymi nowymi flagami, ale nie wiedział co z nimi dalej zrobić? ..
Po drugie, pamiętajmy CRC32, który jest tutaj używany zasadniczo jako funkcje haszujące aby jednoznacznie określić, jaki typ jest (de) serializowany. Tutaj mamy do czynienia z problemem kolizji - i nie, prawdopodobieństwo nie wynosi jeden do 232, ale znacznie więcej. Kto pamiętał, że CRC32 ma za zadanie wykrywać (i korygować) błędy w kanale komunikacyjnym i odpowiednio poprawiać te właściwości ze szkodą dla innych? Nie zależy jej np. na permutacji bajtów: jeśli policzysz CRC32 z dwóch linii, to w drugiej zamienisz pierwsze 4 bajty z kolejnymi 4 bajtami – będzie to samo. Kiedy jako dane wejściowe mamy ciągi tekstowe z alfabetu łacińskiego (i trochę znaków interpunkcyjnych), a nazwy te nie są szczególnie przypadkowe, prawdopodobieństwo takiej permutacji znacznie wzrasta.
Swoją drogą, kto sprawdził, co tam jest naprawdę CRC32? W jednym z wczesnych źródeł (jeszcze przed Waltmanem) istniała funkcja haszująca mnożąca każdy znak przez liczbę 239, tak ukochaną przez tych ludzi, ha ha!
Wreszcie, w porządku, zdaliśmy sobie sprawę, że konstruktory z typem pola Vector<int> и Vector<PolymorType> będzie miał inny CRC32. A co z prezentacją na linii? A jeśli chodzi o teorię, czy staje się częścią typu? Powiedzmy, że przekazujemy tablicę dziesięciu tysięcy liczb, cóż, za pomocą Vector<int> wszystko jasne, długość i kolejne 40000 XNUMX bajtów. A jeśli to Vector<Type2>, który składa się tylko z jednego pola int i jest to jedyny w typie - czy trzeba powtórzyć 10000xabcdef0 34 razy a potem 4 bajty int, lub język jest w stanie WYŚWIETLIĆ to dla nas z konstruktora fixedVec i zamiast 80000 40000 bajtów, przenieść ponownie tylko XNUMX XNUMX?
To wcale nie jest bezczynne pytanie teoretyczne - wyobraź sobie, że otrzymujesz listę użytkowników grupy, z których każdy ma identyfikator, imię, nazwisko - różnica w ilości danych przesyłanych przez połączenie mobilne może być znacząca. To skuteczność serializacji Telegrama jest nam reklamowana.
Więc…
Wektor, którego nie można było wydedukować
Jeśli spróbujesz przebrnąć przez strony z opisami kombinatorów io nich, zobaczysz, że wektor (a nawet macierz) formalnie próbuje wydedukować kilka arkuszy przez krotki. Ale w końcu zostają uderzeni młotkiem, ostatni krok jest pomijany i po prostu podawana jest definicja wektora, która również nie jest związana z typem. O co tu chodzi? W językach programowanie, zwłaszcza funkcjonalnych, dość typowe jest opisywanie struktury rekurencyjnie - kompilator ze swoją leniwą ewaluacją wszystko zrozumie i zrobi. w języku serializacja danych ale potrzebna jest SKUTECZNOŚĆ: wystarczy po prostu opisać lista, tj. struktura dwóch elementów - pierwszy to element danych, drugi to sama struktura lub puste miejsce na ogon (pakiet (cons) w Lispie). Ale to oczywiście będzie wymagać każdy element dodatkowo poświęca 4 bajty (CRC32 w przypadku TL) na opisanie jego typu. Łatwo jest opisać tablicę stały rozmiar, ale w przypadku tablicy o nieznanej wcześniej długości zrywamy.
Ponieważ TL nie pozwala na wyjście wektora, musiał zostać dodany z boku. Ostatecznie dokumentacja mówi:
Serializacja zawsze używa tego samego konstruktora „wektor” (const 0x1cb5c415 = crc32(„vector t:Type # [ t ] = Vector t”), który nie jest zależny od konkretnej wartości zmiennej typu t.
Wartość opcjonalnego parametru t nie jest zaangażowana w serializację, ponieważ pochodzi z typu wyniku (zawsze znanego przed deserializacją).
Przyjrzyj się bliżej: vector {t:Type} # [ t ] = Vector t - ale nigdzie sama definicja nie mówi, że pierwsza liczba musi być równa długości wektora! I nie wynika to znikąd. Jest to oczywistość, o której musisz pamiętać i wdrażać ją własnymi rękami. W innym miejscu dokumentacja nawet uczciwie wspomina, że typ jest fałszywy:
Pseudotyp polimorficzny Vector t to „typ”, którego wartością jest sekwencja wartości dowolnego typu t, w ramce lub bez.
…ale nie skupia się na tym. Kiedy, zmęczony przedzieraniem się przez matematykę (może nawet znaną Ci z uniwersyteckiego kursu), zdecydujesz się na punktację i zobaczysz, jak faktycznie z nią pracujesz, w głowie pozostaje wrażenie: tutaj Serious Mathematics opiera się na , oczywiście Cool People (dwóch matematyków - zwycięzca ACM), i to nie byle kogo. Cel - zaszaleć - został osiągnięty.
Nawiasem mówiąc, o numerze. Przypomnienie sobie czegoś
#to synonimnat, Liczba naturalna:Istnieją wyrażenia typu (typwyr) i wyrażenia liczbowe (nat-wyr). Są one jednak definiowane w ten sam sposób.
type-expr ::= expr nat-expr ::= exprale w gramatyce są one opisane w ten sam sposób, tj. ponownie tę różnicę należy zapamiętać i ręcznie wprowadzić w życie.
Cóż, tak, typy szablonów (vector<int>, vector<User>) mają wspólny identyfikator (#1cb5c415), tj. jeśli wiesz, że połączenie jest zadeklarowane jako
users.getUsers#d91a548 id:Vector<InputUser> = Vector<User>;wtedy czekasz nie tylko na wektor, ale na wektor użytkowników. Dokładniej, powinien czekaj - w prawdziwym kodzie każdy element, jeśli nie goły typ, będzie miał konstruktora, aw dobrym tego słowa znaczeniu w implementacji należałoby to sprawdzić - i wysłano nas dokładnie w każdym elemencie tego wektora ten typ? A gdyby to był jakiś PHP, w którym tablica może zawierać różne typy w różnych elementach?
W tym momencie zaczynasz się zastanawiać - czy taki TL jest potrzebny? Może dla wózka dałoby się zastosować ludzki serializator, ten sam protobuf, który już wtedy istniał? To była teoria, spójrzmy na praktykę.
Istniejące implementacje TL w kodzie
TL narodził się w trzewiach VKontakte jeszcze przed dobrze znanymi wydarzeniami ze sprzedażą akcji Durowa i (na pewno), jeszcze przed rozwojem Telegramu. I w otwartym kodzie źródłowym można znaleźć wiele zabawnych kul. A sam język został tam zaimplementowany pełniej niż teraz w Telegramie. Na przykład skróty w ogóle nie są używane w schemacie (co oznacza wbudowany pseudotyp (jak wektor) z dewiacyjnym zachowaniem). Lub
Templates are not used now. Instead, the same universal constructors (for example, vector {t:Type} [t] = Vector t) are used wale dla kompletności rozważmy ten obraz, aby prześledzić, że tak powiem, ewolucję Giganta Myśli.
#define ZHUKOV_BYTES_HACK
#ifdef ZHUKOV_BYTES_HACK
/* dirty hack for Zhukov request */Albo ten piękny:
static const char *reserved_words_polymorhic[] = {
"alpha", "beta", "gamma", "delta", "epsilon", "zeta", "eta", "theta", NULL
};Ten fragment dotyczy szablonów, takich jak:
intHash {alpha:Type} vector<coupleInt<alpha>> = IntHash<alpha>;To jest definicja szablonu typu hashmap, jako wektor int - Pary typów. W C++ wyglądałoby to mniej więcej tak:
template <T> class IntHash {
vector<pair<int,T>> _map;
}więc, alpha - słowo kluczowe! Ale tylko w C++ można pisać T, ale trzeba pisać alpha, beta... Ale nie więcej niż 8 parametrów, fantazja skończyła się na theta. Wydaje się więc, że kiedyś w Petersburgu były w przybliżeniu takie dialogi:
-- Надо сделать в TL шаблоны
-- Бл... Ну пусть параметры зовут альфа, бета,... Какие там ещё буквы есть... О, тэта!
-- Грамматика? Ну потом напишем
-- Смотрите, какой я синтаксис придумал для шаблонов и вектора!
-- Ты долбанулся, как мы это парсить будем?
-- Да не ссыте, он там один в схеме, захаркодить -- и окAle chodziło o pierwszą rozplanowaną implementację TL „w ogóle”. Przejdźmy do rozważenia implementacji w rzeczywistych klientach Telegrama.
Słowo Bazylego:
Wasilij, [09.10.18 17:07]
Co mnie naprawdę wkurza, to to, że na szybko zrzucili ze sobą mnóstwo abstrakcji, a potem się z nich wycofali i przyłożyli się do generatora kodu jak do podpórki.
W rezultacie jako pierwszy z doków wyskakuje plik pilot.jpg
Następnie z kodu jekichan.webp
Oczywiście od osób zaznajomionych z algorytmami i matematyką możemy się spodziewać, że czytali Aho, Ullmana i znają narzędzia, które stały się de facto standardem w branży na przestrzeni dziesięcioleci do pisania kompilatorów dla ich DSL-ów, prawda? ..
Przez jest Vitaliy Valtman, co można wywnioskować z występowania formatu TLO poza jego (cli) granicami, członkiem zespołu - teraz przydzielona jest biblioteka do parsowania TL jakie wrażenie na niej robi ? ..
16.12 04:18 Wasilij: moim zdaniem ktoś nie opanował lex + yacc
16.12 04:18 Wasilij: inaczej nie potrafię tego wytłumaczyć
16.12 04:18 Wasilij: cóż, albo zapłacono im za liczbę linii w VK
16.12 04:19 Wasilij: Ponad 3 tysiące linii innych<censored>zamiast parsera
Może wyjątek? Zobaczmy jak to jest OFICJALNY klient — Telegram Desktop:
nametype = re.match(r'([a-zA-Z.0-9_]+)(#[0-9a-f]+)?([^=]*)=s*([a-zA-Z.<>0-9_]+);', line);
if (not nametype):
if (not re.match(r'vector#1cb5c415 {t:Type} # [ t ] = Vector t;', line)):
print('Bad line found: ' + line);1100+ linii w Pythonie, kilka wyrażeń regularnych + specjalne przypadki typu wektor, który oczywiście jest zadeklarowany w schemacie tak, jak powinien być zgodnie ze składnią TL, ale postawili to na tej składni, parsują to więcej ... Pytanie brzmi, po co zawracać sobie głowę tym całym cudemиwięcej puff, jeśli i tak nikt nie zamierza tego analizować zgodnie z dokumentacją?!
Przy okazji... Pamiętasz, jak rozmawialiśmy o sprawdzeniu CRC32? Tak więc w generatorze kodu Telegram Desktop znajduje się lista wyjątków dla tych typów, w których obliczony CRC32 nie pasuje jak pokazano na schemacie!
Wasilij, [18.12 22:49]
i tu trzeba się zastanowić czy taki TL jest konieczny
gdybym chciał zadzierać z alternatywnymi implementacjami, zacząłbym wstawiać podziały linii, połowa parserów zepsuje się na definicjach wielowierszowych
tdesktop jednak też
Pamiętaj o jednej linijce, wrócimy do niej nieco później.
No dobrze, telegram-cli jest nieoficjalny, Telegram Desktop jest oficjalny, ale co z pozostałymi? Kto wie? W kodzie Android- klient w ogóle nie posiadał parsera schematu (co rodzi pytania o jego naturę open source, ale to temat na drugą część), ale znaleziono kilka innych zabawnych fragmentów kodu, ale więcej na ten temat w podsekcji poniżej.
Jakie inne pytania rodzi serializacja w praktyce? Na przykład, oczywiście spieprzyli pola bitowe i pola warunkowe:
Wasilij:
flags.0? true
oznacza, że pole jest obecne i prawdziwe, jeśli flaga jest ustawionaWasilij:
flags.1? int
oznacza, że pole jest obecne i wymaga deserializacjiWasilij: Tyłek, nie pal, co robisz!
Wasilij: Gdzieś w dokumencie jest wzmianka, że prawda to goły typ o zerowej długości, ale zbieranie czegoś z ich dokumentów jest nierealne
Wasilij: Nie ma też czegoś takiego w otwartych wdrożeniach, ale jest dużo kul i rekwizytów
A może Telethon? Patrząc w przyszłość na temat MTProto, przykład - są takie fragmenty w dokumentacji, ale znak % jest opisany tylko jako „odpowiadający danemu typowi nagiemu”, tj. w poniższych przykładach albo błąd, albo coś nieudokumentowanego:
Wasilij, [22.06.18 18:38]
W jednym miejscu:msg_container#73f1f8dc messages:vector message = MessageContainer;W innym:
msg_container#73f1f8dc messages:vector<%Message> = MessageContainer;I to są dwie duże różnice, w prawdziwym życiu pojawia się jakiś nagi wektor
Nie widziałem definicji gołych wektorów i nie natknąłem się na to
Analiza napisana ręcznie w telethonie
Jego schemat skomentował definicję
msg_containerPonownie pozostaje pytanie o %. Nie jest to opisane.
Wadim Gonczarow, [22.06.18 19:22]
a w tdesktop?Wasilij, [22.06.18 19:23]
Ale ich parser TL w regulatorach najprawdopodobniej też tego nie zniesie.
// parsed manuallyTL to piękna abstrakcja, nikt nie implementuje jej w całości
A w ich wersji schematu nie ma %
Ale tutaj dokumentacja sobie zaprzecza, więc xs
Znaleźli to w gramatyce, mogli po prostu zapomnieć opisać semantykę
Cóż, widziałeś dok na TL, nie możesz tego rozgryźć bez pół litra
„Cóż, powiedzmy”, powie inny czytelnik, „wszystko krytykujesz, więc pokaż to tak, jak powinno”.
Wasilij odpowiada: „jeśli chodzi o parser, potrzebuję takich rzeczy
args: /* empty */ { $$ = NULL; }
| args arg { $$ = g_list_append( $1, $2 ); }
;
arg: LC_ID ':' type-term { $$ = tl_arg_new( $1, $3 ); }
| LC_ID ':' condition '?' type-term { $$ = tl_arg_new_cond( $1, $5, $3 ); free($3); }
| UC_ID ':' type-term { $$ = tl_arg_new( $1, $3 ); }
| type-term { $$ = tl_arg_new( "", $1 ); }
| '[' LC_ID ']' { $$ = tl_arg_new_mult( "", tl_type_new( $2, TYPE_MOD_NONE ) ); }
;jakoś bardziej niż
struct tree *parse_args4 (void) {
PARSE_INIT (type_args4);
struct parse so = save_parse ();
PARSE_TRY (parse_optional_arg_def);
if (S) {
tree_add_child (T, S);
} else {
load_parse (so);
}
if (LEX_CHAR ('!')) {
PARSE_ADD (type_exclam);
EXPECT ("!");
}
PARSE_TRY_PES (parse_type_term);
PARSE_OK;
}lub
# Regex to match the whole line
match = re.match(r'''
^ # We want to match from the beginning to the end
([w.]+) # The .tl object can contain alpha_name or namespace.alpha_name
(?:
# # After the name, comes the ID of the object
([0-9a-f]+) # The constructor ID is in hexadecimal form
)? # If no constructor ID was given, CRC32 the 'tl' to determine it
(?:s # After that, we want to match its arguments (name:type)
{? # For handling the start of the '{X:Type}' case
w+ # The argument name will always be an alpha-only name
: # Then comes the separator between name:type
[wd<>#.?!]+ # The type is slightly more complex, since it's alphanumeric and it can
# also have Vector<type>, flags:# and flags.0?default, plus :!X as type
}? # For handling the end of the '{X:Type}' case
)* # Match 0 or more arguments
s # Leave a space between the arguments and the equal
=
s # Leave another space between the equal and the result
([wd<>#.?]+) # The result can again be as complex as any argument type
;$ # Finally, the line should always end with ;
''', tl, re.IGNORECASE | re.VERBOSE)to jest CAŁY leksykon:
---functions--- return FUNCTIONS;
---types--- return TYPES;
[a-z][a-zA-Z0-9_]* yylval.string = strdup(yytext); return LC_ID;
[A-Z][a-zA-Z0-9_]* yylval.string = strdup(yytext); return UC_ID;
[0-9]+ yylval.number = atoi(yytext); return NUM;
#[0-9a-fA-F]{1,8} yylval.number = strtol(yytext+1, NULL, 16); return ID_HASH;
n /* skip new line */
[ t]+ /* skip spaces */
//.*$ /* skip comments */
/*.**/ /* skip comments */
. return (int)yytext[0];te. prostsze, delikatnie mówiąc”.
W sumie parser i generator kodu dla faktycznie używanego podzbioru TL mieszczą się w około 100 liniach gramatyki i ~300 liniach generatora (w tym wszystkie printwygenerowany kod), w tym gadżety typu, wpisz informacje do introspekcji w każdej klasie. Każdy typ polimorficzny jest przekształcany w pustą abstrakcyjną klasę bazową, a konstruktory dziedziczą z niej i mają metody serializacji i deserializacji.
Brak typów w języku typów
Mocne pisanie jest dobre, prawda? Nie, to nie jest holivar (chociaż wolę języki dynamiczne), ale postulat w ramach TL. Na jego podstawie język powinien zapewnić nam wszelkiego rodzaju czeki. No dobrze, niech nie on, ale wykonanie, ale powinien przynajmniej je opisać. A jakich możliwości chcemy?
Przede wszystkim ograniczenia. Tutaj widzimy w dokumentacji do przesyłania plików:
Zawartość binarna pliku jest następnie dzielona na części. Wszystkie części muszą mieć ten sam rozmiar ( rozmiar_części ) i muszą być spełnione następujące warunki:
part_size % 1024 = 0(podzielne przez 1KB)524288 % part_size = 0(512 KB musi być równo podzielne przez part_size)Ostatnia część nie musi spełniać tych warunków, pod warunkiem, że jej rozmiar jest mniejszy niż rozmiar_części.
Każda część powinna mieć numer porządkowy, część_pliku, o wartości z zakresu od 0 do 2,999.
Po podzieleniu pliku na partycje należy wybrać sposób zapisania go na serwerze. używać w przypadku, gdy pełny rozmiar pliku jest większy niż 10 MB i dla mniejszych plików.
[…] może zostać zwrócony jeden z następujących błędów wprowadzania danych:
- FILE_PARTS_INVALID — Nieprawidłowa liczba części. Wartość nie jest pomiędzy
1..3000
Czy któryś z nich występuje w schemacie? Czy da się to jakoś wyrazić za pomocą TL? NIE. Ale przepraszam, nawet staromodny Turbo Pascal był w stanie opisać typy podane przez zakresy. I mógł zrobić jeszcze jedną rzecz, teraz lepiej znaną jako enum - typ składający się z wyliczenia ustalonej (niewielkiej) liczby wartości. Pamiętaj, że w językach takich jak C - numeric do tej pory mówiliśmy tylko o typach. liczby. Ale są też tablice, stringi… na przykład fajnie byłoby opisać, że ten string może zawierać tylko numer telefonu, prawda?
Nic z tego nie jest w TL. Ale jest na przykład w JSON Schema. A jeśli ktoś inny może sprzeciwić się podzielności 512 KB, że nadal należy to sprawdzić w kodzie, upewnij się, że klient po prostu nie mogłem wyślij numer poza zasięgiem 1..3000 (a odpowiedni błąd nie mógł powstać) byłoby to możliwe, prawda? ..
Przy okazji, o błędach i zwracanych wartościach. Oko jest zamglone nawet dla tych, którzy pracowali z TL - nie od razu to do nas dotarło każdy funkcja w TL może w rzeczywistości zwrócić nie tylko opisany typ zwracany, ale także błąd. Ale nie można tego wywnioskować za pomocą samej TL. Oczywiście i tak jest to zrozumiałe i nafig nie jest konieczne w praktyce (choć faktycznie RPC można zrobić na różne sposoby, jeszcze do tego wrócimy) - ale co z Czystością pojęć Matematyki Typów Abstrakcyjnych z niebios świecie?.. Złapałem za holownik - tak pasuje.
I wreszcie, co z czytelnością? Cóż, ogólnie rzecz biorąc, chciałbym opis mieć to dobrze w schemacie (znowu w schemacie JSON), ale jeśli już jest napięte, to co z praktyczną stroną - przynajmniej oglądanie różnic podczas aktualizacji jest banalne? Przekonaj się o godz :
-channelFull#76af5481 flags:# can_view_participants:flags.3?true can_set_username:flags.6?true can_set_stickers:flags.7?true hidden_prehistory:flags.10?true id:int about:string participants_count:flags.0?int admins_count:flags.1?int kicked_count:flags.2?int banned_count:flags.2?int read_inbox_max_id:int read_outbox_max_id:int unread_count:int chat_photo:Photo notify_settings:PeerNotifySettings exported_invite:ExportedChatInvite bot_info:Vector<BotInfo> migrated_from_chat_id:flags.4?int migrated_from_max_id:flags.4?int pinned_msg_id:flags.5?int stickerset:flags.8?StickerSet available_min_id:flags.9?int = ChatFull;
+channelFull#1c87a71a flags:# can_view_participants:flags.3?true can_set_username:flags.6?true can_set_stickers:flags.7?true hidden_prehistory:flags.10?true can_view_stats:flags.12?true id:int about:string participants_count:flags.0?int admins_count:flags.1?int kicked_count:flags.2?int banned_count:flags.2?int online_count:flags.13?int read_inbox_max_id:int read_outbox_max_id:int unread_count:int chat_photo:Photo notify_settings:PeerNotifySettings exported_invite:ExportedChatInvite bot_info:Vector<BotInfo> migrated_from_chat_id:flags.4?int migrated_from_max_id:flags.4?int pinned_msg_id:flags.5?int stickerset:flags.8?StickerSet available_min_id:flags.9?int = ChatFull;
lub
-message#44f9b43d flags:# out:flags.1?true mentioned:flags.4?true media_unread:flags.5?true silent:flags.13?true post:flags.14?true id:int from_id:flags.8?int to_id:Peer fwd_from:flags.2?MessageFwdHeader via_bot_id:flags.11?int reply_to_msg_id:flags.3?int date:int message:string media:flags.9?MessageMedia reply_markup:flags.6?ReplyMarkup entities:flags.7?Vector<MessageEntity> views:flags.10?int edit_date:flags.15?int post_author:flags.16?string grouped_id:flags.17?long = Message;
+message#44f9b43d flags:# out:flags.1?true mentioned:flags.4?true media_unread:flags.5?true silent:flags.13?true post:flags.14?true from_scheduled:flags.18?true id:int from_id:flags.8?int to_id:Peer fwd_from:flags.2?MessageFwdHeader via_bot_id:flags.11?int reply_to_msg_id:flags.3?int date:int message:string media:flags.9?MessageMedia reply_markup:flags.6?ReplyMarkup entities:flags.7?Vector<MessageEntity> views:flags.10?int edit_date:flags.15?int post_author:flags.16?string grouped_id:flags.17?long = Message;
Ktoś to lubi, ale na przykład GitHub odmawia wyróżnienia zmian w tak długich liniach. Gra „znajdź 10 różnic” i to, co mózg od razu widzi, to to, że początki i końce są takie same w obu przykładach, trzeba żmudnie czytać gdzieś pośrodku… Moim zdaniem to nie tylko w teorii, ale czysto wizualnie brudny i zaniedbany.
Nawiasem mówiąc, o czystości teorii. Dlaczego potrzebne są pola bitowe? Czy nie wydają się zapach złe z punktu widzenia teorii typów? Wyjaśnienie można znaleźć we wcześniejszych wersjach schematu. Na początku tak, tak było, dla każdego kichnięcia tworzono nowy typ. Te podstawy nadal istnieją w tej formie, na przykład:
storage.fileUnknown#aa963b05 = storage.FileType;
storage.filePartial#40bc6f52 = storage.FileType;
storage.fileJpeg#7efe0e = storage.FileType;
storage.fileGif#cae1aadf = storage.FileType;
storage.filePng#a4f63c0 = storage.FileType;
storage.filePdf#ae1e508d = storage.FileType;
storage.fileMp3#528a0677 = storage.FileType;
storage.fileMov#4b09ebbc = storage.FileType;
storage.fileMp4#b3cea0e4 = storage.FileType;
storage.fileWebp#1081464c = storage.FileType;Ale teraz wyobraź sobie, że jeśli masz 5 opcjonalnych pól w swojej strukturze, potrzebujesz 32 typów dla wszystkich możliwych opcji. wybuch kombinatoryczny. Tak więc krystaliczna czystość teorii TL po raz kolejny zderzyła się z żeliwnym tyłkiem surowej rzeczywistości serializacji.
Ponadto w niektórych miejscach ci faceci sami naruszają własne pisanie. Na przykład w MTProto (następny rozdział) odpowiedź można skompresować przez Gzip, wszystko jest sensowne - poza naruszeniem warstw i schematu. Raz i nie zebrał samego RpcResult, ale jego zawartość. No bo po co to robić?.. Musiałem ciąć kulą, żeby kompresja działała wszędzie.
Lub inny przykład, znaleźliśmy kiedyś błąd - wysłane InputPeerUser zamiast InputUser. Lub odwrotnie. Ale zadziałało! Oznacza to, że serwer nie dbał o typ. Jak to może być? Być może odpowiedź zostanie podana przez fragmenty kodu z telegram-cli:
if (tgl_get_peer_type (E->id) != TGL_PEER_CHANNEL || (C && (C->flags & TGLCHF_MEGAGROUP))) {
out_int (CODE_messages_get_history);
out_peer_id (TLS, E->id);
} else {
out_int (CODE_channels_get_important_history);
out_int (CODE_input_channel);
out_int (tgl_get_peer_id (E->id));
out_long (E->id.access_hash);
}
out_int (E->max_id);
out_int (E->offset);
out_int (E->limit);
out_int (0);
out_int (0);Innymi słowy, tutaj serializacja jest wykonywana RĘCZNIE, nie wygenerowany kod! Może serwer jest zaimplementowany w podobny sposób?.. Zasadniczo to zadziała, jeśli zostanie zrobione raz, ale jak możesz to później wesprzeć aktualizacjami? Czy nie o to chodziło w tym schemacie? A potem przechodzimy do kolejnego pytania.
Wersjonowanie. Warstwy
Dlaczego wersje schematów nazywane są warstwami, można tylko zgadywać na podstawie historii opublikowanych schematów. Najwyraźniej początkowo autorom wydawało się, że podstawowe rzeczy można robić według niezmiennego schematu i tylko tam, gdzie to konieczne, wskazywać na konkretne prośby, że są one wykonywane według innej wersji. W zasadzie nawet dobry pomysł - a nowy niejako „wmiesza się”, nakłada się na stary. Ale zobaczmy, jak to zrobiono. To prawda, że nie można było spojrzeć od samego początku - to zabawne, ale schemat warstwy podstawowej po prostu nie istnieje. Warstwy zaczęły się od 2. Dokumentacja mówi nam o specjalnej funkcji TL:
Jeśli klient obsługuje warstwę 2, należy użyć następującego konstruktora:
invokeWithLayer2#289dd1f6 {X:Type} query:!X = X;W praktyce oznacza to, że przed każdym wywołaniem API int z wartością
0x289dd1f6należy dodać przed numerem metody.
Brzmi dobrze. Ale co stało się dalej? Potem przyszedł
invokeWithLayer3#b7475268 query:!X = X;Więc co dalej? Jak łatwo się domyślić
invokeWithLayer4#dea0d430 query:!X = X;Śmieszny? Nie, jest za wcześnie na śmiech, pomyśl o czym każdy prośba z innej warstwy musi być opakowana w taki specjalny typ - jeśli masz wszystkie różne, jak inaczej je odróżnić? A dodanie zaledwie 4 bajtów z przodu jest dość wydajną metodą. Więc
invokeWithLayer5#417a57ae query:!X = X;Ale wiadomo, że za jakiś czas będzie to jakaś bachanalia. I przyszło rozwiązanie:
Aktualizacja: Począwszy od warstwy 9, metody pomocnicze
invokeWithLayerNmoże być używany razem zinitConnection
Brawo! Po 9 wersjach doszliśmy w końcu do tego, co robiono w protokołach internetowych jeszcze w latach 80-tych - negocjowanie wersji raz na początku połączenia!
Więc co dalej?..
invokeWithLayer10#39620c41 query:!X = X;
...
invokeWithLayer18#1c900537 query:!X = X;A teraz możesz się śmiać. Dopiero po kolejnych 9 warstwach w końcu dodano uniwersalny konstruktor z numerem wersji, który wystarczy wywołać tylko raz na początku połączenia, a znaczenie w warstwach jakby zniknęło, teraz jest to tylko wersja warunkowa, jak gdziekolwiek indziej. Problem rozwiązany.
Prawidłowy?..
Wasilij, [16.07.18 14:01]
Myślałem w piątek:
Teleserver wysyła zdarzenia bez żądania. Żądania muszą być opakowane w InvokeWithLayer. Serwer nie zawija aktualizacji, nie ma struktury do zawijania odpowiedzi i aktualizacji.Te. klient nie może określić warstwy, w której chce aktualizacji
Wadim Gonczarow, [16.07.18 14:02]
Czy InvokeWithLayer nie jest w zasadzie hackiem?Wasilij, [16.07.18 14:02]
To jest jedyny sposóbWadim Gonczarow, [16.07.18 14:02]
co w zasadzie oznacza uzgodnienie warstwy na początku sesjiNawiasem mówiąc, wynika z tego, że obniżenie wersji klienta nie jest zapewnione
Aktualizacje, tj. typ Updates w schemacie jest to to, co serwer wysyła do klienta nie w odpowiedzi na żądanie API, ale samodzielnie, gdy wystąpi zdarzenie. Jest to złożony temat, który zostanie omówiony w innym poście, ale na razie ważne jest, aby wiedzieć, że serwer gromadzi aktualizacje nawet wtedy, gdy klient jest offline.
Tak więc, gdy odmawia się zawijania każdy package, aby wskazać jego wersję, stąd logicznie pojawiają się następujące możliwe problemy:
- serwer wysyła aktualizacje do klienta, zanim klient poinformuje, którą wersję obsługuje
- co należy zrobić po aktualizacji klienta?
- kto gwarancjeże opinia serwera o numerze warstwy nie zmieni się w trakcie?
Myślisz, że to myślenie czysto teoretyczne, a w praktyce tak się nie może zdarzyć, bo serwer jest napisany poprawnie (w każdym razie dobrze przetestowany)? Ha! Nie ważne jak!
To jest dokładnie to, na co wpadliśmy w sierpniu. 14 sierpnia błysnęły komunikaty, że coś jest aktualizowane na serwerach Telegrama… a potem w logach:
2019-08-15 09:28:35.880640 MSK warn main: ANON:87: unknown object type: 0x80d182d1 at TL/Object.pm line 213.
2019-08-15 09:28:35.751899 MSK warn main: ANON:87: unknown object type: 0xb5223b0f at TL/Object.pm line 213.a następnie kilka megabajtów śladów stosu (cóż, w tym samym czasie naprawiono rejestrowanie). W końcu, jeśli coś nie zostało rozpoznane w Twojej TL - jest to binarne według podpisów, dalej w strumieniu WSZYSTKO idzie, dekodowanie stanie się niemożliwe. Co zrobić w takiej sytuacji?
Cóż, pierwszą rzeczą, która przychodzi każdemu do głowy, jest rozłączenie się i spróbowanie ponownie. Nie pomogło. Wygooglowaliśmy CRC32 - okazały się to obiekty ze schematu 73, chociaż pracowaliśmy na schemacie 82. Uważnie przyglądamy się logom - są tam identyfikatory z dwóch różnych schematów!
Czy problem może dotyczyć wyłącznie naszego nieoficjalnego klienta? Nie, uruchommy Telegram Desktop 1.2.17 (wersję dołączoną do niektórych dystrybucji). Linux), zapisuje w dzienniku wyjątków: MTP Nieoczekiwany identyfikator typu #b5223b0f odczytany w MTPMessageMedia…
Google pokazało, że podobny problem spotkał już jednego z nieoficjalnych klientów, ale wtedy numery wersji i co za tym idzie założenia były inne…
Więc co robić? Wasilij i ja rozstaliśmy się: próbował zaktualizować schemat do 91, postanowiłem poczekać kilka dni i spróbować do 73. Obie metody zadziałały, ale ponieważ są empiryczne, nie ma zrozumienia, ile wersji trzeba przeskoczyć lub w dół, ani jak długo trzeba czekać.
Później udało mi się odtworzyć sytuację: uruchamiamy klienta, wyłączamy go, rekompilujemy schemat do innej warstwy, restartujemy, ponownie łapiemy problem, wracamy do poprzedniego - ups, bez przełączania schematu i restartowania klienta przez kilka minuty pomogą. Otrzymasz mieszankę struktur danych z różnych warstw.
Wyjaśnienie? Jak można się domyślić z różnych symptomów pośrednich, serwer składa się z wielu różnych typów procesów na różnych maszynach. Najprawdopodobniej ten z serwerów odpowiedzialny za „buforowanie” wstawił do kolejki to, co dały mu wyższe, a oni dali to w schemacie, który był w momencie generowania. I dopóki ta kolejka nie była „zgniła”, nic nie można było z tym zrobić.
Chyba że... ale czy to nie jest okropne obejście?! Nie, zanim zaczniemy myśleć o szalonych pomysłach, spójrzmy na kod oficjalnych klientów. W wersji dla Android Nie znajdujemy żadnego parsera TL, ale znajdujemy ogromny plik (GitHub odmawia jego kolorowania) z (de)serializacją. Oto fragmenty kodu:
public static class TL_message_layer68 extends TL_message {
public static int constructor = 0xc09be45f;
//...
//еще пачка подобных
//...
public static class TL_message_layer47 extends TL_message {
public static int constructor = 0xc992e15c;
public static Message TLdeserialize(AbstractSerializedData stream, int constructor, boolean exception) {
Message result = null;
switch (constructor) {
case 0x1d86f70e:
result = new TL_messageService_old2();
break;
case 0xa7ab1991:
result = new TL_message_old3();
break;
case 0xc3060325:
result = new TL_message_old4();
break;
case 0x555555fa:
result = new TL_message_secret();
break;
case 0x555555f9:
result = new TL_message_secret_layer72();
break;
case 0x90dddc11:
result = new TL_message_layer72();
break;
case 0xc09be45f:
result = new TL_message_layer68();
break;
case 0xc992e15c:
result = new TL_message_layer47();
break;
case 0x5ba66c13:
result = new TL_message_old7();
break;
case 0xc06b9607:
result = new TL_messageService_layer48();
break;
case 0x83e5de54:
result = new TL_messageEmpty();
break;
case 0x2bebfa86:
result = new TL_message_old6();
break;
case 0x44f9b43d:
result = new TL_message_layer104();
break;
case 0x1c9b1027:
result = new TL_message_layer104_2();
break;
case 0xa367e716:
result = new TL_messageForwarded_old2(); //custom
break;
case 0x5f46804:
result = new TL_messageForwarded_old(); //custom
break;
case 0x567699b3:
result = new TL_message_old2(); //custom
break;
case 0x9f8d60bb:
result = new TL_messageService_old(); //custom
break;
case 0x22eb6aba:
result = new TL_message_old(); //custom
break;
case 0x555555F8:
result = new TL_message_secret_old(); //custom
break;
case 0x9789dac4:
result = new TL_message_layer104_3();
break;lub
boolean fixCaption = !TextUtils.isEmpty(message) &&
(media instanceof TLRPC.TL_messageMediaPhoto_old ||
media instanceof TLRPC.TL_messageMediaPhoto_layer68 ||
media instanceof TLRPC.TL_messageMediaPhoto_layer74 ||
media instanceof TLRPC.TL_messageMediaDocument_old ||
media instanceof TLRPC.TL_messageMediaDocument_layer68 ||
media instanceof TLRPC.TL_messageMediaDocument_layer74)
&& message.startsWith("-1");Hm... to wygląda szalenie. Ale prawdopodobnie jest to wygenerowany kod, więc dobrze?.. Ale z pewnością obsługuje wszystkie wersje! To prawda, że \uXNUMXb\uXNUMXbnie jest jasne, dlaczego wszystko jest zmieszane w jednym stosie, tajne rozmowy i wszelkiego rodzaju _old7 jakoś niepodobny do maszynowego generowania... Jednak przede wszystkim oszalałem od
TL_message_layer104
TL_message_layer104_2
TL_message_layer104_3Chłopaki, czy wy nawet w jednej warstwie nie możecie się zdecydować?! No dobra, "dwójka", powiedzmy, została wypuszczona z błędem, no cóż, zdarza się, ale TRZY?.. Od razu znowu na tej samej prowizji? Co to za pornografia, przepraszam? ..
Nawiasem mówiąc, podobnie dzieje się w źródłach Telegram Desktop - jeśli tak, to kilka zatwierdzeń z rzędu do schematu nie zmienia jego numeru warstwy, ale coś poprawia. W warunkach, gdy nie ma oficjalnego źródła danych dla schematu, skąd mogę je uzyskać, z wyjątkiem oficjalnych źródeł klientów? I biorąc to stąd, nie możesz być pewien, że schemat jest całkowicie poprawny, dopóki nie przetestujesz wszystkich metod.
Jak to w ogóle można przetestować? Mam nadzieję, że fani testów jednostkowych, funkcjonalnych i innych podzielą się w komentarzach.
Dobra, spójrzmy na inny fragment kodu:
public static class TL_folders_deleteFolder extends TLObject {
public static int constructor = 0x1c295881;
public int folder_id;
public TLObject deserializeResponse(AbstractSerializedData stream, int constructor, boolean exception) {
return Updates.TLdeserialize(stream, constructor, exception);
}
public void serializeToStream(AbstractSerializedData stream) {
stream.writeInt32(constructor);
stream.writeInt32(folder_id);
}
}
//manually created
//RichText start
public static abstract class RichText extends TLObject {
public String url;
public long webpage_id;
public String email;
public ArrayList<RichText> texts = new ArrayList<>();
public RichText parentRichText;
public static RichText TLdeserialize(AbstractSerializedData stream, int constructor, boolean exception) {
RichText result = null;
switch (constructor) {
case 0x1ccb966a:
result = new TL_textPhone();
break;
case 0xc7fb5e01:
result = new TL_textSuperscript();
break;Ten „ręcznie utworzony” komentarz tutaj sugeruje, że tylko część tego pliku jest napisana ręcznie (możesz sobie wyobrazić koszmar konserwacji?), a reszta jest generowana maszynowo. Jednak wtedy pojawia się kolejne pytanie – czy źródła są dostępne nie całkiem (jak w przypadku blobów GPL w jądrze Linux), ale to już temat na drugą część.
Ale wystarczy. Przejdźmy do protokołu, za którym goni cała ta serializacja.
MT Proto
Więc otwórzmy и a pierwszą rzeczą, na którą się natkniemy, jest terminologia. I z obfitością wszystkiego. Ogólnie rzecz biorąc, wydaje się to być znakiem towarowym Telegrama - nazywać rzeczy w różnych miejscach na różne sposoby lub różne rzeczy jednym słowem lub odwrotnie (na przykład w interfejsie API wysokiego poziomu, jeśli widzisz pakiet naklejek - to nie jest tym, o czym myślałeś).
Na przykład „wiadomość” (wiadomość) i „sesja” (sesja) - tutaj oznaczają coś innego niż w zwykłym interfejsie klienta Telegram. Otóż z komunikatem wszystko jasne, można by to zinterpretować pod kątem OOP, lub po prostu nazwać słowem „pakiet” - to niski, transportowy poziom, nie ma tych samych komunikatów co w interfejsie, jest ich dużo z serwisowych. Ale sesja… ale najważniejsze.
Warstwa transportowa
Pierwsza sprawa to transport. Zostaniemy poinformowani o 5 opcjach:
- TCP
- Gniazdo sieciowe
- Websocket przez HTTPS
- HTTP
- HTTPS
Wasilij, [15.06.18 15:04]
Istnieje również protokół UDP, ale nie jest on udokumentowany.I TCP w trzech wariantach
Pierwszy jest podobny do UDP przez TCP, każdy pakiet zawiera numer sekwencyjny i crc
Dlaczego czytanie doków na wózku jest tak bolesne?
Cóż, teraz :
- Skrócony
- Średniozaawansowany
- wyściełane pośrednie
- Pełny
Ok, wyściełany pośredni dla MTProxy, został później dodany ze względu na znane zdarzenia. Ale po co jeszcze dwie wersje (w sumie trzy), skoro można zrobić jedną? Wszystkie cztery zasadniczo różnią się jedynie tym, jak ustawić długość i ładowność rzeczywistego głównego MTProto, co zostanie omówione dalej:
- w trybie skróconym jest to 1 lub 4 bajty, ale nie 0xef, a następnie treść
- w wersji średniozaawansowanej jest to 4 bajty długości i pole, a klient musi wysłać po raz pierwszy
0xeeeeeeeeaby wskazać, że jest średniozaawansowany - w całości najbardziej uzależniające z punktu widzenia networkera: długość, numer sekwencyjny, a NIE TEN, który jest w zasadzie MTProto, body, CRC32. Tak, wszystko to przez TCP. Który zapewnia nam niezawodny transport w postaci szeregowego strumienia bajtów, nie są potrzebne żadne sekwencje, zwłaszcza sumy kontrolne. Dobra, teraz będą mi sprzeciwiać się, że TCP ma 16-bitową sumę kontrolną, więc dochodzi do uszkodzenia danych. Świetnie, poza tym, że faktycznie mamy protokół kryptograficzny z haszami dłuższymi niż 16 bajtów, wszystkie te błędy – a nawet więcej – zostaną wyłapane na niedopasowaniu SHA na wyższym poziomie. Nie ma sensu w CRC32 nad tym.
Porównajmy Abridged, gdzie możliwy jest jeden bajt długości, z Intermediate, co uzasadnia „W przypadku, gdy potrzebne jest wyrównanie danych 4-bajtowych”, co jest dość nonsensowne. Co, uważa się, że programiści Telegrama są tak niezdarni, że nie potrafią odczytać danych z gniazda do wyrównanego bufora? Nadal musisz to zrobić, ponieważ odczyt może zwrócić ci dowolną liczbę bajtów (a są też serwery proxy, na przykład ...). Lub, z drugiej strony, po co zawracać sobie głowę Abridged, jeśli wciąż mamy mocne dopełnienie z 16 bajtów na górze - zaoszczędź 3 bajty czasami ?
Można odnieść wrażenie, że Nikołaj Durow bardzo lubi wymyślać rowery, w tym protokoły sieciowe, bez rzeczywistej praktycznej potrzeby.
Inne opcje transportu, m.in. Web i MTProxy, nie będziemy teraz rozważać, może w innym poście, jeśli pojawi się prośba. Przypomnijmy teraz tylko o tym właśnie MTProxy, że wkrótce po jego wydaniu w 2018 roku dostawcy szybko nauczyli się blokować dokładnie to, przeznaczone do obejście blokuPrzez rozmiar pakietu! A także fakt, że serwer MTProxy napisany (ponownie przez Waltmana) w C był niepotrzebnie powiązany ze specyfiką Linuksa, chociaż w ogóle nie był wymagany (Phil Kulin potwierdzi), oraz że podobny serwer w Go lub w Node.js zmieścić mniej niż sto wierszy.
Ale wnioski dotyczące umiejętności technicznych tych osób wyciągniemy na końcu tej sekcji, po rozważeniu innych kwestii. Na razie przejdźmy do 5. warstwy OSI, sesji - na której umieścili sesję MTProto.
Klucze, wiadomości, sesje, Diffie-Hellman
Umieścili to tam nie do końca poprawnie… Sesja to nie ta sama sesja, która jest widoczna w interfejsie w sekcji Aktywne sesje. Ale po kolei.
Tutaj otrzymaliśmy ciąg bajtów o znanej długości z warstwy transportowej. Jest to albo zaszyfrowana wiadomość, albo zwykły tekst - jeśli wciąż jesteśmy na kluczowym etapie negocjacji i faktycznie to robimy. O którym z wielu pojęć zwanych „kluczem” mówimy? Wyjaśnijmy tę kwestię samemu zespołowi Telegrama (przepraszam za tłumaczenie własnej dokumentacji z angielskiego dla albo zmęczonego mózgu o 4 rano, łatwiej było zostawić niektóre frazy bez zmian):
Istnieją dwa podmioty tzw Sesja - jeden w interfejsie użytkownika oficjalnych klientów pod „bieżącymi sesjami”, gdzie każda sesja odpowiada całemu urządzeniu / systemowi operacyjnemu.
Drugi to Sesja MTProto, który zawiera numer sekwencyjny komunikatu (w sensie niskiego poziomu) i który może trwać między różnymi połączeniami TCP. Można skonfigurować kilka sesji MTProto w tym samym czasie, na przykład w celu przyspieszenia pobierania plików.Między tymi dwoma Sesje jest koncepcja autoryzacja. W zdegenerowanym przypadku można tak powiedzieć Sesja interfejsu użytkownika jest taki sam jak autoryzacjaAle niestety, to skomplikowane. Patrzymy:
- Użytkownik na nowym urządzeniu najpierw generuje klucz autoryzujący i wiąże go z kontem np. SMS-em - dlatego autoryzacja
- Stało się to w pierwszym Sesja MTProto, który ma
session_idwewnątrz siebie.- Na tym etapie kombinacja autoryzacja и
session_idmożna było nazwać przykład - to słowo znajduje się w dokumentacji i kodzie niektórych klientów- Następnie klient może otworzyć kilka Sesje MTProto pod tym samym klucz autoryzujący - do tego samego DC.
- Pewnego dnia klient musi poprosić o plik inny DC - i dla tego DC zostanie wygenerowany nowy klucz autoryzujący !
- Aby powiedzieć systemowi, że nie jest to rejestracja nowego użytkownika, ale ten sam autoryzacja (Sesja interfejsu użytkownika), klient używa wywołań API
auth.exportAuthorizationw domu DCauth.importAuthorizationw nowym DC.- Mimo to może być kilka otwartych Sesje MTProto (każdy ze swoim
session_id) do tego nowego DC, pod jego klucz autoryzujący.- Wreszcie, klient może chcieć zachowania idealnej tajemnicy przekazywania. Każdy klucz autoryzujący było stały key — na kontroler domeny — a klient może dzwonić
auth.bindTempAuthKeydo użycia tymczasowy klucz autoryzujący - i znowu tylko jeden temp_auth_key na DC, wspólne dla wszystkich Sesje MTProto do tego DC.Należy pamiętać, że sól (i przyszłe sole) również jeden na klucz autoryzujący te. udostępniony wszystkim Sesje MTProto do tego samego DC.
Co oznacza „między różnymi połączeniami TCP”? To znaczy, że to coś jak ciasteczko autoryzacyjne na stronie internetowej - utrzymuje (przeżywa) wiele połączeń TCP z tym serwerem, ale pewnego dnia się zepsuje. Tylko w przeciwieństwie do HTTP w MTProto w ramach sesji wiadomości są kolejno numerowane i potwierdzane, weszły do tunelu, połączenie zostało zerwane - po nawiązaniu nowego połączenia serwer uprzejmie prześle wszystko w tej sesji, czego nie dostarczył w poprzednie połączenie TCP.
Powyższe informacje są jednak wyciskiem po wielu miesiącach sporów. A tymczasem wdrażamy naszego klienta od podstaw? - wróćmy do początku.
Więc generujemy auth_key nadotycząca . Spróbujmy zrozumieć dokumentację...
Wasilij, [19.06.18 20:05]
data_with_hash := SHA1(data) + data + (dowolne losowe bajty); tak, że długość wynosi 255 bajtów;
zaszyfrowane_dane:= RSA(dane_z_haszem, klucz_publiczny_serwera); liczba o długości 255 bajtów (big endian) jest podnoszona do wymaganej potęgi nad wymaganym modułem, a wynik jest zapisywany jako liczba o długości 256 bajtów.Dostali trochę narkotyku DH
Nie wygląda na DH u zdrowej osoby
W dx nie ma dwóch kluczy publicznych
Cóż, w końcu się domyśliliśmy, ale osad pozostał - dowód pracy jest wykonany przez klienta, że był w stanie rozłożyć liczbę na czynniki. Rodzaj ochrony przed atakami DoS. A klucz RSA jest używany tylko raz w jednym kierunku, zasadniczo do szyfrowania new_nonce. Ale chociaż ta pozornie prosta operacja zakończy się sukcesem, z czym będziesz musiał się zmierzyć?
Wasilij, [20.06.18 00:26]
Nie dotarłem jeszcze do prośby o appid.Wysłałem zapytanie do DH
A w stacji dokującej na transporcie jest napisane, że może odpowiedzieć 4 bajtami kodu błędu. I to wszystko
Cóż, powiedział mi -404, i co z tego?
Oto ja do niego: „złap swoją efigna zaszyfrowaną kluczem serwera z odciskiem palca takiego a takiego, chcę DH”, a on głupio odpowiada 404
Co sądzisz o takiej odpowiedzi serwera? Co robić? Nie ma kogo zapytać (ale o tym w drugiej części).
Tutaj całe zainteresowanie dokiem jest do zrobienia
Nie mam nic innego do roboty, marzyłem tylko o przeliczaniu liczb tam iz powrotem
Dwie liczby 32-bitowe. Zapakowałem je jak wszyscy inni
Ale nie, to właśnie tych dwóch potrzebujesz najpierw w linii jako BE
Wadim Gonczarow, [20.06.18 15:49]
a z powodu tego 404?Wasilij, [20.06.18 15:49]
TakWadim Gonczarow, [20.06.18 15:50]
Nie rozumiem, dlaczego nie mógł tego „znaleźć”.Wasilij, [20.06.18 15:50]
okołoNie znalazłem takiego rozkładu na proste dzielniki%)
Nawet raportowanie błędów nie zostało opanowane
Wasilij, [20.06.18 20:18]
A, i jest jeszcze MD5. To trzy różne skróty.Kluczowy odcisk palca jest obliczany w następujący sposób:
digest = md5(key + iv) fingerprint = substr(digest, 0, 4) XOR substr(digest, 4, 4)SHA1 i sha2
Więc postawmy auth_key Otrzymaliśmy rozmiar 2048 bitów według Diffie-Hellmana. Co dalej? Wtedy dowiadujemy się, że dolne 1024 bity tego klucza nie są w żaden sposób wykorzystywane… ale pomyślmy o tym na razie. Na tym etapie mamy wspólny sekret z serwerem. Ustanowiono analog sesji TLS, bardzo kosztowną procedurę. Ale serwer jeszcze nic nie wie o tym, kim jesteśmy! Właściwie jeszcze nie upoważnienie. Te. jeśli myślałeś w kategoriach „hasło logowania”, jak to było kiedyś w ICQ, lub przynajmniej „klucz logowania”, jak w SSH (na przykład na jakimś gitlab / github). Zostaliśmy anonimowi. A jeśli serwer odpowie nam „te numery telefonów są obsługiwane przez inny DC”? A może nawet „Twój numer telefonu jest zbanowany”? Najlepszą rzeczą, jaką możemy zrobić, to zapisać klucz w nadziei, że do tego czasu będzie nadal użyteczny i nie zgnije.
Nawiasem mówiąc, „przyjęliśmy” go z zastrzeżeniami. Na przykład, czy ufamy serwerowi? Czy on jest fałszywy? Potrzebujemy kontroli kryptograficznych:
Wasilij, [21.06.18 17:53]
Oferują klientom mobilnym sprawdzenie pierwszości liczby 2kbitowej.Ale to wcale nie jest jasne, nafeijoa
Wasilij, [21.06.18 18:02]
Lekarz nie mówi, co zrobić, jeśli okaże się, że to nie jest takie proste.
Nie powiedziano. Zobaczmy, co w tym przypadku robi oficjalny klient na Androida? A (i tak, cały plik jest tam interesujący) - jak to mówią, po prostu go tu zostawię:
278 static const char *goodPrime = "c71caeb9c6b1c9048e6c522f70f13f73980d40238e3e21c14934d037563d930f48198a0aa7c14058229493d22530f4dbfa336f6e0ac925139543aed44cce7c3720fd51f69458705ac68cd4fe6b6b13abdc9746512969328454f18faf8c595f642477fe96bb2a941d5bcd1d4ac8cc49880708fa9b378e3c4f3a9060bee67cf9a4a4a695811051907e162753b56b0f6b410dba74d8a84b2a14b3144e0ef1284754fd17ed950d5965b4b9dd46582db1178d169c6bc465b0d6ff9ca3928fef5b9ae4e418fc15e83ebea0f87fa9ff5eed70050ded2849f47bf959d956850ce929851f0d8115f635b105ee2e4e15d04b2454bf6f4fadf034b10403119cd8e3b92fcc5b";
279 if (!strcasecmp(prime, goodPrime)) {Nie, oczywiście, że tam Niektóre są testy na prostotę liczby, ale osobiście nie mam już wystarczającej wiedzy z matematyki.
Dobra, mamy klucz główny. Aby się zalogować, tj. wysyłania żądań konieczne jest wykonanie dalszego szyfrowania, już przy użyciu AES.
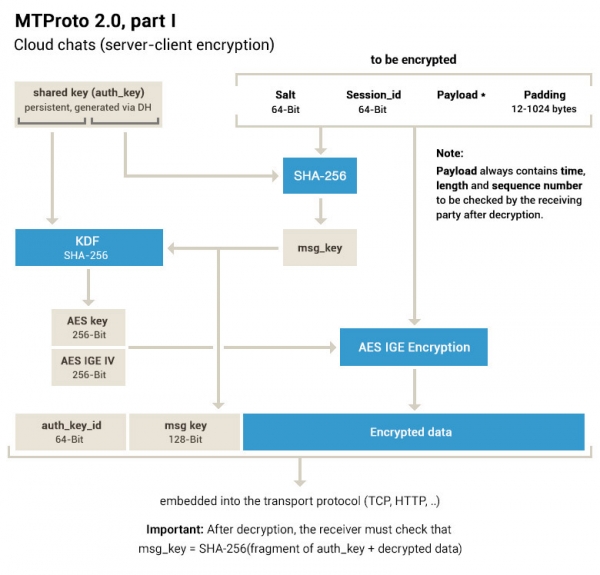
Klucz komunikatu jest zdefiniowany jako 128 środkowych bitów SHA256 treści komunikatu (w tym sesji, identyfikatora komunikatu itp.), w tym bajtów dopełniających, poprzedzonych 32 bajtami pobranymi z klucza autoryzacji.
Wasilij, [22.06.18 14:08]
Średnia, suka, kawałkiOtrzymane
auth_key. Wszystko. Dalej im… nie wynika to z doków. Zapraszam do studiowania otwartego kodu źródłowego.Zauważ, że MTProto 2.0 wymaga od 12 do 1024 bajtów dopełnienia, nadal pod warunkiem, że wynikowa długość wiadomości będzie podzielna przez 16 bajtów.
Więc ile włożyć wkładki?
I tak, tutaj też, 404 w przypadku błędu
Jeśli ktoś uważnie przestudiował schemat i treść dokumentacji, zauważył, że nie ma tam żadnego MACa. I że AES jest używany w niektórych trybach IGE, które nie są używane nigdzie indziej. Piszą o tym oczywiście w swoim FAQ... Tutaj np. sam klucz wiadomości jest jednocześnie haszem SHA odszyfrowanych danych służącym do sprawdzenia integralności - a w przypadku niezgodności dokumentacja dla jakiś powód zaleca milczące ich ignorowanie (ale co z bezpieczeństwem, nagle nas złamie?).
Nie jestem kryptografem, może w tym trybie w tym przypadku nie ma nic złego z teoretycznego punktu widzenia. Ale na pewno mogę wymienić praktyczny problem na przykładzie Telegram Desktop. Szyfruje lokalną pamięć podręczną (wszystkie te D877F783D5D3EF8C) w taki sam sposób jak wiadomości w MTProto (tylko w tym przypadku wersja 1.0), tj. najpierw klucz wiadomości, potem same dane (i gdzieś na marginesie główny big auth_key 256 bajtów, bez których msg_key bezużyteczny). Tak więc problem staje się zauważalny w przypadku dużych plików. Mianowicie, musisz zachować dwie kopie danych - zaszyfrowaną i odszyfrowaną. A czy są to megabajty, czy strumieniowe wideo np.?.. Klasyczne schematy z MAC po zaszyfrowanym tekście pozwalają na odczytanie go strumieniowo, natychmiastowe przesłanie. A z MTProto musisz pierwszy zaszyfrować lub odszyfrować całą wiadomość, dopiero potem przenieść ją do sieci lub na dysk. Dlatego w najnowszych wersjach Telegram Desktop w pamięci podręcznej w user_data używany jest już inny format - z AES w trybie CTR.
Wasilij, [21.06.18 01:27]
O, dowiedziałem się, czym jest IGE: IGE był pierwszą próbą stworzenia „uwierzytelniającego trybu szyfrowania”, pierwotnie przeznaczonego dla Kerberosa. Była to nieudana próba (nie zapewniała ochrony integralności) i musiała zostać usunięta. To był początek 20-letnich poszukiwań działającego uwierzytelniającego trybu szyfrowania, które niedawno zaowocowały powstaniem trybów takich jak OCB i GCM.A teraz argumenty od strony koszyka:
Zespół stojący za Telegramem, kierowany przez Nikołaja Durowa, składa się z sześciu mistrzów ACM, z których połowa ma doktoraty z matematyki. Wdrożenie aktualnej wersji MTProto zajęło im około dwóch lat.
Co jest zabawne. Dwa lata do niższego poziomu
Albo możemy po prostu wziąć tls
Dobra, powiedzmy, że zrobiliśmy szyfrowanie i inne niuanse. Czy możemy w końcu wysyłać żądania z serializacją TL i deserializować odpowiedzi? Co więc należy wysłać i jak? Oto metoda może to jest to?
Wasilij, [25.06.18 18:46]
Inicjuje połączenie i zapisuje informacje na urządzeniu i aplikacji użytkownika.Akceptuje app_id, device_model, system_version, app_version i lang_code.
I jakieś zapytanie
Dokumentacja jak zwykle. Zapraszam do studiowania open source
Jeśli wszystko było z grubsza jasne z invokeWithLayer, to co to jest? Okazuje się, że załóżmy, że klient miał już o co zapytać serwer - jest żądanie, które chcieliśmy wysłać:
Wasilij, [25.06.18 19:13]
Sądząc po kodzie, pierwsze wywołanie jest zawinięte w ten syf, a sam syf jest zawinięty w invokewithlayer
Dlaczego initConnection nie może być osobnym wywołaniem, ale musi być opakowaniem? Tak, jak się okazało, trzeba to robić każdorazowo na początku każdej sesji, a nie jednorazowo, jak przy kluczu głównym. Ale! Nie może być wywołany przez nieautoryzowanego użytkownika! Tutaj doszliśmy do etapu, w którym ma to zastosowanie strona dokumentacji - i mówi nam, że ...
Tylko niewielka część metod API jest dostępna dla nieautoryzowanych użytkowników:
- wyślij kod
- kod ponownego wysłania
- konto.pobierzhasło
- auth.checkPassword
- autoryzacjaTelefon
- autoryzacja.rejestracja
- uwierzytelnianie.logowanie
- auth.importAutoryzacja
- pomoc.getConfig
- help.getNearestDc
- pomoc.getAppUpdate
- pomoc.getCdnConfig
- langpack.getLangPack
- langpack.getStrings
- langpack.getRóżnica
- langpack.getJęzyki
- langpack.getJęzyk
Pierwszy z nich auth.sendCode, i jest to cenne pierwsze żądanie, w którym wyślemy api_id i api_hash, po czym otrzymamy SMS z kodem. A jeśli trafiliśmy do złego DC (numery telefonów z tego kraju obsługuje np. inny), to otrzymamy błąd z numerem żądanego DC. Aby dowiedzieć się, z którym adresem IP musimy się połączyć za pomocą numeru DC, pomoże nam help.getConfig. Kiedyś wpisów było tylko 5, ale po dobrze znanych wydarzeniach z 2018 roku liczba ta znacząco wzrosła.
Przypomnijmy sobie teraz, że trafiliśmy na ten etap na anonimowy serwer. Czy uzyskanie adresu IP nie jest zbyt drogie? Dlaczego nie wykonać tej i innych operacji w niezaszyfrowanej części MTProto? Słyszę sprzeciw: „skąd pewność, że to nie RKN odpowie fałszywymi adresami?”. Do tego przypominamy sobie, że w rzeczywistości w oficjalnych klientach wbudowane klucze RSA, tj. możesz po prostu podpisać ta informacja. Właściwie jest to już zrobione w przypadku informacji o omijaniu blokad, które klienci otrzymują innymi kanałami (logiczne jest, że nie można tego zrobić w samym MTProto, ponieważ nadal trzeba wiedzieć, gdzie się połączyć).
OK. Na tym etapie autoryzacji klienta nie jesteśmy jeszcze autoryzowani i nie zarejestrowaliśmy naszej aplikacji. Na razie chcemy tylko zobaczyć, jak serwer zareaguje na metody dostępne dla nieautoryzowanego użytkownika. I tu…
Wasilij, [10.07.18 14:45]
config#7dae33e0 [...] = Config; help.getConfig#c4f9186b = Config;config#232d5905 [...] = Config; help.getConfig#c4f9186b = Config;W schemacie pojawia się pierwszy, drugi
W schemacie tdesktop trzecią wartością jest
Tak, od tego czasu oczywiście dokumentacja została zaktualizowana. Chociaż wkrótce może to znowu stać się nieistotne. A skąd początkujący programista powinien wiedzieć? Może jak zarejestrujesz swoją aplikację, to Cię poinformują? Wasilij to zrobił, ale niestety nic mu nie wysłano (ponownie porozmawiamy o tym w drugiej części).
... Zauważyliście, że już niejako przenieśliśmy się do API, tj. przejść na wyższy poziom i przegapiłeś coś w motywie MTProto? Nic dziwnego:
Wasilij, [28.06.18 02:04]
Mm, udostępniają niektóre algorytmy na e2eMtproto definiuje algorytmy szyfrowania i klucze dla obu domen, a także trochę struktury opakowania
Ale ciągle mieszają różne poziomy stosu, więc nie zawsze jest jasne, gdzie skończyło się mtproto, a zaczął następny poziom.
Jak są mieszane? Oto na przykład ten sam klucz tymczasowy dla PFS (nawiasem mówiąc, Telegram Desktop nie wie, jak to zrobić). Jest wykonywany przez żądanie API auth.bindTempAuthKey, tj. z najwyższego poziomu. Ale jednocześnie ingeruje w szyfrowanie na niższym poziomie - po nim np. trzeba zrobić to jeszcze raz initConnection itp. to nie po prostu normalna prośba. Oddzielnie zapewnia również, że możesz mieć tylko JEDEN tymczasowy klucz na DC, chociaż pole auth_key_id w każdej wiadomości pozwala na zmianę klucza przynajmniej w każdej wiadomości, oraz że serwer ma prawo w każdej chwili „zapomnieć” klucz tymczasowy – co w takim przypadku zrobić, dokumentacja nie mówi… no właśnie, po co nie byłoby możliwe posiadanie kilku kluczy, jak w przypadku zestawu przyszłych soli, ale?..
W motywie MTProto warto zwrócić uwagę na kilka innych rzeczy.
Wiadomości, msg_id, msg_seqno, potwierdzenia, pingi w złym kierunku i inne dziwactwa
Dlaczego warto o nich wiedzieć? Bo „przeciekają” poziom wyżej, a trzeba o nich wiedzieć podczas pracy z API. Załóżmy, że nie interesuje nas msg_key, niższy poziom odszyfrował wszystko za nas. Ale wewnątrz odszyfrowanych danych mamy następujące pola (także długość danych, aby wiedzieć, gdzie jest dopełnienie, ale to nie jest ważne):
- sól-int64
- identyfikator_sesji - int64
- identyfikator_wiadomości - int64
- seq_no-int32
Przypomnij sobie, że sól jest jedna dla całego DC. Po co o niej wiedzieć? Nie tylko dlatego, że jest prośba get_future_salts, który mówi, które interwały będą ważne, ale także dlatego, że jeśli twoja sól jest „zgniła”, to wiadomość (prośba) po prostu zostanie utracona. Serwer oczywiście zgłosi nową sól poprzez wydanie new_session_created - ale ze starym trzeba będzie jakoś wysłać ponownie np. I to pytanie wpływa na architekturę aplikacji.
Serwer może całkowicie porzucić sesje i odpowiedzieć w ten sposób z wielu powodów. Właściwie czym jest sesja MTProto od strony klienta? To są dwie liczby session_id и seq_no wiadomości w tej sesji. No i oczywiście bazowe połączenie TCP. Powiedzmy, że nasz klient wciąż nie wie, jak zrobić wiele rzeczy, rozłączony, ponownie połączony. Jeśli stało się to szybko - stara sesja była kontynuowana w nowym połączeniu TCP, wzrost seq_no dalej. Jeśli to zajmie dużo czasu, serwer może go usunąć, ponieważ po swojej stronie jest to również kolejka, jak się dowiedzieliśmy.
Co powinno być seq_no? Och, to trudne pytanie. Spróbuj szczerze zrozumieć, o co chodziło:
Wiadomość związana z treścią
Wiadomość wymagająca wyraźnego potwierdzenia. Obejmują one wszystkie komunikaty użytkownika i wiele komunikatów serwisowych, praktycznie wszystkie z wyjątkiem kontenerów i potwierdzeń.
Numer sekwencyjny wiadomości (msg_seqno)
Liczba 32-bitowa równa dwukrotności wiadomości „treściowych” (wymagających potwierdzenia, a w szczególności niebędących kontenerami) utworzonych przez nadawcę przed tą wiadomością, a następnie zwiększanych o jeden, jeśli bieżąca wiadomość jest wiadomością wiadomość związana z treścią. Kontener jest zawsze generowany po całej jego zawartości; dlatego jego numer porządkowy jest większy lub równy numerom porządkowym zawartych w nim komunikatów.
Co to za cyrk z przyrostem o 1, a potem o kolejne 2?.. Podejrzewam, że pierwotne znaczenie brzmiało „niski bit dla ACK, reszta to liczba”, ale wynik nie jest do końca poprawny - w szczególności, okazuje się, że można go wysłać kilka potwierdzenia, które mają to samo seq_no! Jak? Otóż serwer np. coś do nas wysyła, wysyła, a my sami milczymy, odpowiadamy tylko wiadomościami z potwierdzeniem usługi o otrzymaniu jego wiadomości. W takim przypadku nasze potwierdzenia wychodzące będą miały ten sam numer wychodzący. Jeśli jesteś zaznajomiony z TCP i pomyślałeś, że to brzmi trochę szalenie, ale wydaje się, że nie jest to zbyt szalone, ponieważ w TCP seq_no nie zmienia się, a potwierdzenie przechodzi do seq_no po drugiej stronie - wtedy spieszę się zdenerwować. Do MTProto napływają potwierdzenia NIE nadotycząca seq_no, jak w TCP, ale msg_id !
Co to jest msg_id, najważniejsza z tych dziedzin? Unikalny identyfikator wiadomości, jak sama nazwa wskazuje. Jest zdefiniowany jako liczba 64-bitowa, której najmniej znaczące bity ponownie mają magię serwer-nie-serwer, a reszta to znacznik czasu Unix, w tym część ułamkowa, przesunięta o 32 bity w lewo. Te. timestamp per se (a wiadomości ze zbyt różnymi czasami będą odrzucane przez serwer). Z tego wynika, że generalnie jest to identyfikator globalny dla klienta. Podczas - pamiętaj session_id - gwarantujemy: W żadnym wypadku wiadomość przeznaczona dla jednej sesji nie może zostać przesłana do innej sesji. To znaczy okazuje się, że już jest trzy poziom — sesja, numer sesji, id wiadomości. Dlaczego taka komplikacja, ta tajemnica jest bardzo wielka.
W ten sposób msg_id potrzebne…
RPC: żądania, odpowiedzi, błędy. Potwierdzenia.
Jak być może zauważyłeś, nigdzie w schemacie nie ma specjalnego typu ani funkcji „utwórz żądanie RPC”, chociaż istnieją odpowiedzi. W końcu mamy wiadomości merytoryczne! To jest, każdy wiadomość może być prośbą! Albo nie być. Mimo wszystko, każdy jest msg_id. A oto odpowiedzi:
rpc_result#f35c6d01 req_msg_id:long result:Object = RpcResult;Tutaj jest wskazana, na jaką wiadomość jest to odpowiedź. W związku z tym na najwyższym poziomie API będziesz musiał pamiętać jaki numer miała Twoja prośba – chyba nie trzeba tłumaczyć, że praca jest asynchroniczna, a jednocześnie może być kilka próśb, na które odpowiedzi można zwrócić w dowolnej kolejności? W zasadzie na podstawie tego i komunikatów o błędach, takich jak brak pracowników, można prześledzić architekturę, która za tym stoi: serwer, który utrzymuje połączenie TCP z tobą, jest równoważnikiem front-end, kieruje żądania do backendów i zbiera je z powrotem message_id. Wszystko wydaje się tu jasne, logiczne i dobre.
Tak?.. A jeśli się nad tym zastanowić? W końcu sama odpowiedź RPC również ma pole msg_id! Czy musimy krzyczeć na serwer „nie odpowiadasz na moją odpowiedź!”? I tak, co tam było o potwierdzeniu? O stronie mówi nam, co jest
msgs_ack#62d6b459 msg_ids:Vector long = MsgsAck;i każda ze stron musi to zrobić. Ale nie zawsze! Jeśli otrzymasz RpcResult, samo w sobie służy jako potwierdzenie. Oznacza to, że serwer może odpowiedzieć na żądanie za pomocą komunikatu MsgsAck — na przykład „Otrzymałem”. Może natychmiast odpowiedzieć RpcResult. Może to być jedno i drugie.
I tak, nadal musisz odpowiedzieć na odpowiedź! Potwierdzenie. W przeciwnym razie serwer uzna przesyłkę za niedostarczoną i ponownie ją wyrzuci. Nawet po ponownym podłączeniu. Ale tutaj oczywiście pojawi się kwestia limitów czasu. Przyjrzyjmy się im nieco później.
W międzyczasie rozważmy możliwe błędy w wykonaniu zapytania.
rpc_error#2144ca19 error_code:int error_message:string = RpcError;Och, ktoś wykrzyknie, tutaj jest bardziej ludzki format - jest linia! Nie spiesz się. Tutaj ale na pewno nie kompletne. Z niego dowiadujemy się, że kod to − coś jak Błędy HTTP (oczywiście semantyka odpowiedzi nie jest respektowana, w niektórych miejscach są rozdzielane kodami losowo), a ciąg znaków wygląda tak CAPITAL_LETTERS_AND_NUMBERS. Na przykład PHONE_NUMBER_OCCUPIED lub FILE_PART_X_MISSING. Cóż, to znaczy, że nadal masz do tej linii analizować. Na przykład FLOOD_WAIT_3600 będzie oznaczać, że będziesz musiał czekać godzinę i PHONE_MIGRATE_5że numer telefonu z tym prefiksem powinien być zarejestrowany w 5 DC. Mamy język typów, prawda? Nie potrzebujemy argumentu z łańcucha, wystarczą wyrażenia regularne, cho.
Ponownie, nie ma tego na stronie komunikatów serwisowych, ale, jak to już jest w zwyczaju w przypadku tego projektu, informacje można znaleźć na innej stronie dokumentacji. Or wzbudzić podejrzliwość. Po pierwsze, spójrz, naruszenie pisania/warstw - RpcError można w nie inwestować RpcResult. Dlaczego nie na zewnątrz? Czego nie wzięliśmy pod uwagę?.. W związku z tym, gdzie jest gwarancja, że RpcError nie można w nie inwestować RpcResult, ale być bezpośrednio lub zagnieżdżonym w innym typie? brakuje mu req_msg_id ? ..
Ale przejdźmy dalej do komunikatów serwisowych. Klient może pomyśleć, że serwer myśli przez długi czas i złożyć takie wspaniałe żądanie:
rpc_drop_answer#58e4a740 req_msg_id:long = RpcDropAnswer;Istnieją na to trzy możliwe odpowiedzi, ponownie przecinające się z mechanizmem potwierdzania, aby spróbować zrozumieć, jakie powinny być (i jaka jest lista typów, które w ogóle nie wymagają potwierdzenia), czytelnikowi pozostawia się jako pracę domową (uwaga: informacje w źródłach Telegram Desktop nie są kompletne).
Uzależnienie: statusy wiadomości
Generalnie wiele miejsc w TL, MTProto i Telegram w ogóle pozostawia poczucie uporu, ale z grzeczności, taktu i innych umiejętności miękkich grzecznie milczeliśmy na ten temat, a wulgaryzmy w dialogach zostały ocenzurowane. Jednak to miejsceОwiększość strony nt szokuje nawet mnie, który od dawna pracuje z protokołami sieciowymi i widział rowery o różnym stopniu krzywizny.
Zaczyna się niewinnie, od potwierdzeń. Następnie powiedziano nam o
bad_msg_notification#a7eff811 bad_msg_id:long bad_msg_seqno:int error_code:int = BadMsgNotification;
bad_server_salt#edab447b bad_msg_id:long bad_msg_seqno:int error_code:int new_server_salt:long = BadMsgNotification;Cóż, każdy, kto zacznie pracować z MTProto, będzie musiał się z nimi zmierzyć, w cyklu „poprawione - przekompilowane - uruchomione” błędy liczbowe lub sól, która zepsuła się podczas edycji, to codzienność. Jednak są tutaj dwa punkty:
- Wynika z tego, że oryginalna wiadomość została utracona. Musimy odgrodzić niektóre kolejki, rozważymy to później.
- Co to za dziwne numery błędów? 16, 17, 18, 19, 20, 32, 33, 34, 35, 48, 64... gdzie jest reszta liczb, Tommy?
Dokumentacja stwierdza:
Intencją jest pogrupowanie wartości error_code (kod_błędu >> 4): na przykład kody 0x40 - 0x4f odpowiadają błędom w dekompozycji kontenera.
ale, po pierwsze, przesunięcie w innym kierunku, a po drugie, nie ma znaczenia, gdzie jest reszta kodów? W głowie autora?.. Jednak to są drobiazgi.
Uzależnienie zaczyna się w wiadomościach o stanie postów i kopiach postów:
- Żądanie informacji o statusie wiadomości
Jeśli któraś ze stron nie otrzymywała przez jakiś czas informacji o statusie swoich wiadomości wychodzących, może wyraźnie zażądać ich od drugiej strony:
msgs_state_req#da69fb52 msg_ids:Vector long = MsgsStateReq; - Komunikat informacyjny dotyczący statusu komunikatów
msgs_state_info#04deb57d req_msg_id:long info:string = MsgsStateInfo;
Tutaj,infojest ciągiem zawierającym dokładnie jeden bajt statusu wiadomości dla każdej wiadomości z listy przychodzących msg_ids:- 1 = nic nie wiadomo o wiadomości (msg_id za niskie, druga strona mogła o tym zapomnieć)
- 2 = wiadomość nie została odebrana (msg_id mieści się w zakresie przechowywanych identyfikatorów, jednak druga strona na pewno nie otrzymała takiej wiadomości)
- 3 = wiadomość nie została odebrana (msg_id za wysokie; jednak druga strona na pewno jeszcze jej nie otrzymała)
- 4 = otrzymano wiadomość (zauważ, że ta odpowiedź jest jednocześnie potwierdzeniem odbioru)
- +8 = wiadomość już potwierdzona
- +16 = wiadomość niewymagająca potwierdzenia
- +32 = zapytanie RPC zawarte w przetwarzanym komunikacie lub przetwarzanie już zakończone
- +64 = odpowiedź merytoryczna na już wygenerowaną wiadomość
- +128 = druga strona wie na pewno, że wiadomość została już odebrana
Ta odpowiedź nie wymaga potwierdzenia. Jest to samo w sobie potwierdzenie odpowiedniego msgs_state_req.
Pamiętaj, że jeśli nagle okaże się, że druga strona nie ma wiadomości, która wygląda na wysłaną do niej, wiadomość można po prostu wysłać ponownie. Nawet jeśli druga strona otrzyma jednocześnie dwie kopie wiadomości, duplikat zostanie zignorowany. (Jeśli minęło zbyt dużo czasu, a oryginalny msg_id jest już nieaktualny, wiadomość ma być owinięta w msg_copy).
- Dobrowolne informowanie o statusie wiadomości
Każda ze stron może dobrowolnie informować drugą stronę o statusie wiadomości przesyłanych przez drugą stronę.
msgs_all_info#8cc0d131 msg_ids:Vector long info:string = MsgsAllInfo - Rozszerzone dobrowolne powiadomienie o statusie jednej wiadomości
...
msg_detailed_info#276d3ec6 msg_id:long answer_msg_id:long bytes:int status:int = MsgDetailedInfo;
msg_new_detailed_info#809db6df answer_msg_id:long bytes:int status:int = MsgDetailedInfo; - Wyraźna prośba o ponowne wysłanie wiadomości
msg_resend_req#7d861a08 msg_ids:Vector long = MsgResendReq;
Strona zdalna natychmiast odpowiada, ponownie wysyłając żądane wiadomości […] - Wyraźna prośba o ponowne wysłanie odpowiedzi
msg_resend_ans_req#8610baeb msg_ids:Vector long = MsgResendReq;
Strona zdalna natychmiast odpowiada, wysyłając ponownie odpowiedzi do żądanych wiadomości […] - Kopie wiadomości
W niektórych sytuacjach stara wiadomość z nieaktualnym już identyfikatorem msg_id wymaga ponownego wysłania. Następnie jest opakowywany w kontener kopii:
msg_copy#e06046b2 orig_message:Message = MessageCopy;
Po odebraniu wiadomość jest przetwarzana tak, jakby nie było opakowania. Jeśli jednak wiadomo na pewno, że wiadomość orig_message.msg_id została odebrana, to nowa wiadomość nie jest przetwarzana (jednocześnie jest potwierdzana i orig_message.msg_id). Wartość orig_message.msg_id musi być mniejsza niż msg_id kontenera.
Przemilczmy nawet fakt, że w msgs_state_info znowu wystają uszy niedokończonej TL (potrzebowaliśmy wektora bajtów, aw dolnych dwóch bitach enum, aw starszych bitach flagi). Chodzi o coś innego. Czy ktoś rozumie, dlaczego to wszystko jest w praktyce w prawdziwym kliencie konieczne?.. Z trudem, ale możesz sobie wyobrazić pewną korzyść, jeśli dana osoba jest zaangażowana w debugowanie iw trybie interaktywnym - zapytaj serwer, co i jak. Ale prośby są opisane tutaj podróż w obie strony.
Wynika z tego, że każda ze stron musi nie tylko szyfrować i wysyłać wiadomości, ale także przechowywać dane o nich, o odpowiedziach na nie i przez nieokreślony czas. Dokumentacja nie opisuje chronometrażu ani praktycznego zastosowania tych funkcji. W żaden sposób nie. Najbardziej zaskakujące jest to, że są one faktycznie używane w kodzie oficjalnych klientów! Najwyraźniej powiedziano im coś, czego nie było w otwartej dokumentacji. Zrozum z kodu dlaczego, nie jest już tak prosta jak w przypadku TL - nie jest to (stosunkowo) izolowana logicznie część, ale część powiązana z architekturą aplikacji, tj. będzie wymagało znacznie więcej czasu na zrozumienie kodu aplikacji.
Pingi i timingi. Kolejki.
Ze wszystkiego, jeśli przypomnieć sobie domysły na temat architektury serwera (rozkładu żądań na backendy), wynika dość nudna rzecz - pomimo wszystkich gwarancji dostarczenia, które w TCP (albo dane zostały dostarczone, albo zostaniesz poinformowany o przerwa, ale dane będą dostarczane do momentu wystąpienia problemu), że potwierdzenia w samym MTProto - żadnych gwarancji. Serwer może łatwo zgubić lub wyrzucić Twoją wiadomość i nic nie da się z tym zrobić, tylko ogrodzić kulami różnego typu.
A przede wszystkim - kolejki komunikatów. Cóż, po pierwsze, wszystko było oczywiste od samego początku – niepotwierdzoną wiadomość trzeba zapisać i wysłać ponownie. A po jakim czasie? I błazen go zna. Być może te komunikaty serwisowe w jakiś sposób rozwiązują ten problem za pomocą kul, powiedzmy, w Telegram Desktop odpowiada im około 4 kolejek (może więcej, jak już wspomniano, w tym celu należy poważniej zagłębić się w jego kod i architekturę; jednocześnie wiemy, że nie można go traktować jako próbki, nie stosuje się w nim pewnej liczby typów ze schematu MTProto).
Dlaczego to się dzieje? Prawdopodobnie programiści serwerów nie byli w stanie zapewnić niezawodności w obrębie klastra, a przynajmniej buforowania na przednim balanserze i przerzucili ten problem na klienta. Z desperacji Wasilij próbował zaimplementować alternatywną opcję, z tylko dwiema kolejkami, używając algorytmów z TCP - mierząc RTT do serwera i dostosowując rozmiar „okna” (w wiadomościach) w zależności od liczby niepotwierdzonych żądań. Czyli taka z grubsza heurystyka do oszacowania obciążenia serwera - ile naszych próśb może jednocześnie przeżuć i nie stracić.
Cóż, to znaczy, rozumiesz, prawda? Jeśli musisz ponownie zaimplementować protokół TCP na bazie protokołu działającego w oparciu o protokół TCP, oznacza to bardzo źle zaprojektowany protokół.
O tak, dlaczego potrzebna jest więcej niż jedna kolejka i ogólnie, co to oznacza dla osoby pracującej z API wysokiego poziomu? Słuchaj, składasz wniosek, serializujesz go, ale często niemożliwe jest natychmiastowe wysłanie. Dlaczego? Bo odpowiedź będzie msg_id, co jest tymczasoweаJestem wytwórnią, której wizytę lepiej odłożyć jak najpóźniej - nagle serwer ją odrzuci z powodu niedopasowania czasowego między nami a nią (oczywiście możemy zrobić kulę, która przesunie nasz czas z teraźniejszości do czasu serwera dodając deltę obliczoną na podstawie odpowiedzi serwera - robią to oficjalni klienci, ale ta metoda jest prymitywna i niedokładna ze względu na buforowanie). Kiedy więc wysyłasz żądanie z lokalnym wywołaniem funkcji z biblioteki, wiadomość przechodzi przez następujące etapy:
- Leży w tej samej kolejce i czeka na zaszyfrowanie.
- Wyznaczony
msg_idi wiadomość trafiła do innej kolejki - możliwe przekierowanie; wysłać do gniazda. - a) Serwer odpowiedział MsgsAck - wiadomość została dostarczona, usuwamy ją z "innej kolejki".
b) Lub odwrotnie, coś mu się nie podobało, odpowiedział badmsg - wysyłamy ponownie z „innej kolejki”
c) Nic nie wiadomo, konieczne jest ponowne wysłanie wiadomości z innej kolejki - ale nie wiadomo dokładnie kiedy. - Serwer w końcu odpowiedział
RpcResult- rzeczywista odpowiedź (lub błąd) - nie tylko dostarczona, ale również przetworzona.
Być może, użycie kontenerów mogłoby częściowo rozwiązać problem. Dzieje się tak, gdy kilka wiadomości jest spakowanych w jedną, a serwer odpowiada potwierdzeniem dla wszystkich naraz, jednym msg_id. Ale odrzuci też tę paczkę, jak coś pójdzie nie tak, to i całość.
I w tym momencie w grę wchodzą względy nietechniczne. Z doświadczenia widzieliśmy wiele kul, a w dodatku teraz zobaczymy więcej przykładów złych rad i architektury – czy w takich warunkach warto ufać i podejmować takie decyzje? Pytanie jest retoryczne (oczywiście, że nie).
O czym gadamy? Jeśli w temacie „uzależniające wiadomości o wiadomościach” nadal możesz spekulować z zastrzeżeniami typu „jesteś głupi, nie zrozumiałeś naszego genialnego pomysłu!” (więc najpierw napisz dokumentację, jak normalni ludzie powinni, z uzasadnieniem i przykładami wymiany pakietów, potem pogadamy), potem timingi/timeouty to kwestia czysto praktyczna i konkretna, tu wszystko od dawna wiadomo. Ale co dokumentacja mówi nam o limitach czasu?
Serwer zwykle potwierdza otrzymanie wiadomości od klienta (zwykle zapytania RPC) za pomocą odpowiedzi RPC. Jeśli na odpowiedź trzeba długo czekać, serwer może najpierw wysłać potwierdzenie odbioru, a nieco później samą odpowiedź RPC.
Klient zwykle potwierdza otrzymanie wiadomości z serwera (zwykle jest to odpowiedź RPC) poprzez dodanie potwierdzenia do następnego zapytania RPC, jeśli nie zostanie ono przesłane zbyt późno (jeśli zostanie wygenerowane, powiedzmy, 60-120 sekund po otrzymaniu wiadomości z serwera). Jeśli jednak przez dłuższy czas nie ma powodu do wysyłania komunikatów do serwera lub gdy z serwera napływa duża liczba niepotwierdzonych komunikatów (powiedzmy ponad 16), klient przesyła autonomiczne potwierdzenie.
... Tłumaczę: sami nie wiemy, ile i jak to jest potrzebne, no to oszacujmy, że niech tak będzie.
A co do pingów:
Wiadomości ping (PING/PONG)
ping#7abe77ec ping_id:long = Pong;Odpowiedź jest zwykle zwracana do tego samego połączenia:
pong#347773c5 msg_id:long ping_id:long = Pong;Te wiadomości nie wymagają potwierdzenia. Pong jest transmitowany tylko w odpowiedzi na ping, podczas gdy ping może zostać zainicjowany przez dowolną stronę.
Odroczone zamknięcie połączenia + PING
ping_delay_disconnect#f3427b8c ping_id:long disconnect_delay:int = Pong;Działa jak ping. Ponadto, po odebraniu tego, serwer uruchamia licznik czasu, który zamknie bieżące połączenie z opóźnieniem_rozłączenia kilka sekund później, chyba że otrzyma nową wiadomość tego samego typu, która automatycznie zresetuje wszystkie poprzednie liczniki czasu. Jeśli klient wysyła te pingi raz na 60 sekund, może ustawić parametr „disconnect_delay” na 75 sekund.
Postradałeś rozum?! Za 60 sekund pociąg wjedzie na stację, wyrzuci i zabierze pasażerów i znowu straci połączenie w tunelu. Za 120 sekund, kiedy będziesz się grzebać, on dotrze do kolejnego, a połączenie najprawdopodobniej zostanie zerwane. Cóż, jasne jest, skąd wyrastają nogi - „Słyszałem dzwonienie, ale nie wiem, gdzie to jest”, jest algorytm Nagle i opcja TCP_NODELAY, która była przeznaczona do pracy interaktywnej. Ale przepraszam, opóźnienie jego wartości domyślnej - 200 Millisekundy. Jeśli naprawdę chcesz przedstawić coś podobnego i zaoszczędzić na możliwej parze pakietów - cóż, odłóż to przynajmniej na 5 sekund lub jakikolwiek limit czasu wiadomości „Użytkownik pisze ...” jest teraz równy. Ale nie wiecej.
I na koniec pingi. To znaczy sprawdzanie żywotności połączenia TCP. To zabawne, ale około 10 lat temu napisałem krytyczny tekst o komunikatorze hostelu naszego wydziału - tam autorzy również pingowali serwer od klienta, a nie odwrotnie. Ale studenci trzeciego roku to jedno, a międzynarodowe biuro to drugie, prawda? ..
Na początek mały program edukacyjny. Połączenie TCP, przy braku wymiany pakietów, może działać tygodniami. Jest to zarówno dobre, jak i złe, w zależności od celu. Cóż, jeśli miałeś otwarte połączenie SSH z serwerem, wstałeś od komputera, zrestartowałeś power router, wróciłeś na swoje miejsce - sesja przez ten serwer nie została przerwana (nic nie wpisywałeś, nie było żadnych pakietów), wygodny. Źle, jeśli na serwerze są tysiące klientów, każdy zabiera zasoby (cześć Postgres!), a host klienta mógł się już dawno zrestartować - ale o tym nie będziemy wiedzieć.
Systemy czatu/komunikatorów internetowych należą do drugiej kategorii z jeszcze jednego, dodatkowego powodu: statusów online. Jeśli użytkownik „rozłączy się”, jego rozmówcy muszą zostać o tym poinformowani. W przeciwnym razie popełnisz ten sam błąd, który popełnili twórcy Jabbera (i naprawiali przez 20 lat): użytkownik rozłącza się, ale wiadomości nadal do niego wysyłane są, wierząc, że jest online (i które zostały całkowicie utracone w ciągu kilku minut przed wykryciem rozłączenia). Nie, opcja TCP_KEEPALIVE, którą wiele osób nie rozumiejących działania timerów TCP macha na siłę (ustawiając szalone wartości, takie jak dziesiątki sekund), tutaj nie pomoże. Musisz upewnić się, że nie tylko jądro systemu operacyjnego użytkownika jest aktywne, ale także działa poprawnie, jest w stanie reagować i że sama aplikacja (myślisz, że nie może się zawiesić? Telegram Desktop na Ubuntu 18.04 zawiesił mi się kilka razy).
Dlatego należy pingować Serwer klienta, a nie odwrotnie - jeśli klient to zrobi, gdy połączenie zostanie zerwane, ping nie zostanie dostarczony, cel nie zostanie osiągnięty.
A co widzimy w Telegramie? Wszystko jest dokładnie na odwrót! Cóż, tj. formalnie oczywiście obie strony mogą pingować się nawzajem. W praktyce klienci używają kuli ping_delay_disconnect, który ustawia licznik czasu na serwerze. Cóż, przepraszam, to nie jest sprawa klienta, aby decydować, jak długo chce tam mieszkać bez pingu. Serwer na podstawie obciążenia wie lepiej. Ale oczywiście, jeśli nie żałujesz zasobów, to źli Pinokio są sami, a kula spadnie ...
Jak to miało być zaprojektowane?
Uważam, że powyższe fakty dość wyraźnie wskazują na niezbyt wysokie kompetencje zespołu Telegram/VKontakte w zakresie transportu (i niższego) poziomu sieci komputerowych oraz ich niskie kwalifikacje w odpowiednich kwestiach.
Dlaczego okazało się to tak skomplikowane i jak architekci Telegrama mogą próbować się sprzeciwić? Fakt, że próbowali stworzyć sesję, która przetrwa zerwanie połączenia TCP, czyli to, czego nie dostarczyliśmy teraz, dostarczymy później. Prawdopodobnie próbowali też zrobić transport UDP, choć napotkali trudności i porzucili go (dlatego dokumentacja jest pusta - nie było się czym chwalić). Ale z powodu braku zrozumienia, jak ogólnie działają sieci, a w szczególności TCP, gdzie można na nim polegać, a gdzie trzeba to zrobić samodzielnie (i jak), oraz próby połączenia tego z kryptografią „jeden strzał z dwóch ptaki na jednym ogniu” - okazało się takie zwłoki.
Jak powinno być? Opierając się na fakcie, że msg_id jest znacznikiem czasu, który jest kryptograficznie niezbędny do zapobiegania atakom polegającym na powtórce, błędem jest dołączanie do niego funkcji unikalnego identyfikatora. Dlatego bez drastycznej zmiany obecnej architektury (kiedy powstaje wątek Updates, jest to temat API wysokiego poziomu na inną część tej serii postów), należałoby:
- Serwer utrzymujący połączenie TCP z klientem bierze na siebie odpowiedzialność - jeśli odjąłeś od gniazda, potwierdź, przetwórz lub zwróć błąd, bez strat. Wtedy potwierdzenie nie jest wektorem id, ale po prostu „ostatni otrzymany seq_no” - tylko liczba, jak w TCP (dwie liczby - twoja własna seq i potwierdzona). Zawsze jesteśmy na sesji, prawda?
- Sygnatura czasowa zapobiegająca atakom powtórkowym staje się oddzielnym polem, a la nonce. Sprawdzone, ale nic więcej nie jest naruszone. Wystarczy i
uint32- jeśli nasza sól zmienia się co najmniej co pół dnia, możemy przeznaczyć 16 bitów na dolne bity części całkowitej aktualnego czasu, resztę - na ułamkową część sekundy (tak jak jest teraz). - wycofane
msg_idw ogóle - z punktu widzenia rozróżniania żądań na backendach jest po pierwsze id klienta, a po drugie id sesji i połączyć je. Odpowiednio, jako identyfikator żądania wystarczy tylko jedenseq_no.
Również nie jest to najlepsza opcja, kompletna losowość może służyć jako identyfikator - nawiasem mówiąc, jest to już zrobione w interfejsie API wysokiego poziomu podczas wysyłania wiadomości. Lepiej byłoby całkowicie zmienić architekturę z względnej na absolutną, ale to już temat na inną część, nie ten wpis.
API?
Ta dama! Tak więc, przebywszy drogę pełną bólu i kul, mogliśmy w końcu wysyłać dowolne żądania do serwera i otrzymywać na nie dowolne odpowiedzi, a także otrzymywać aktualizacje z serwera (nie w odpowiedzi na żądanie, ale sam do nas wysyła, np. PUSH, jeśli ktoś jest o wiele jaśniejszy).
Uwaga, teraz w artykule będzie jedyny przykład Perla! (dla tych, którzy nie znają składni, pierwszym argumentem na błogosławieństwo jest struktura danych obiektu, drugim jego klasa):
2019.10.24 12:00:51 $1 = {
'cb' => 'TeleUpd::__ANON__',
'out' => bless( {
'filter' => bless( {}, 'Telegram::ChannelMessagesFilterEmpty' ),
'channel' => bless( {
'access_hash' => '-6698103710539760874',
'channel_id' => '1380524958'
}, 'Telegram::InputPeerChannel' ),
'pts' => '158503',
'flags' => 0,
'limit' => 0
}, 'Telegram::Updates::GetChannelDifference' ),
'req_id' => '6751291954012037292'
};
2019.10.24 12:00:51 $1 = {
'in' => bless( {
'req_msg_id' => '6751291954012037292',
'result' => bless( {
'pts' => 158508,
'flags' => 3,
'final' => 1,
'new_messages' => [],
'users' => [],
'chats' => [
bless( {
'title' => 'Хулиномика',
'username' => 'hoolinomics',
'flags' => 8288,
'id' => 1380524958,
'access_hash' => '-6698103710539760874',
'broadcast' => 1,
'version' => 0,
'photo' => bless( {
'photo_small' => bless( {
'volume_id' => 246933270,
'file_reference' => '
'secret' => '1854156056801727328',
'local_id' => 228648,
'dc_id' => 2
}, 'Telegram::FileLocation' ),
'photo_big' => bless( {
'dc_id' => 2,
'local_id' => 228650,
'file_reference' => '
'secret' => '1275570353387113110',
'volume_id' => 246933270
}, 'Telegram::FileLocation' )
}, 'Telegram::ChatPhoto' ),
'date' => 1531221081
}, 'Telegram::Channel' )
],
'timeout' => 300,
'other_updates' => [
bless( {
'pts_count' => 0,
'message' => bless( {
'post' => 1,
'id' => 852,
'flags' => 50368,
'views' => 8013,
'entities' => [
bless( {
'length' => 20,
'offset' => 0
}, 'Telegram::MessageEntityBold' ),
bless( {
'length' => 18,
'offset' => 480,
'url' => 'https://alexeymarkov.livejournal.com/[url_вырезан].html'
}, 'Telegram::MessageEntityTextUrl' )
],
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'text' => '???? 165',
'data' => 'send_reaction_0'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 9'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'message' => 'А вот и новая книга!
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
напечатаю.',
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'date' => 1571724559,
'edit_date' => 1571907562
}, 'Telegram::Message' ),
'pts' => 158508
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'pts' => 158508,
'message' => bless( {
'edit_date' => 1571907589,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'date' => 1571807301,
'message' => 'Почему Вы считаете Facebook плохой компанией? Можете прокомментировать? По-моему, это шикарная компания. Без долгов, с хорошей прибылью, а если решат дивы платить, то и еще могут нехило подорожать.
Для меня ответ совершенно очевиден: потому что Facebook делает ужасный по качеству продукт. Да, у него монопольное положение и да, им пользуется огромное количество людей. Но мир не стоит на месте. Когда-то владельцам Нокии было смешно от первого Айфона. Они думали, что лучше Нокии ничего быть не может и она навсегда останется самым удобным, красивым и твёрдым телефоном - и доля рынка это красноречиво демонстрировала. Теперь им не смешно.
Конечно, рептилоиды сопротивляются напору молодых гениев: так Цукербергом был пожран Whatsapp, потом Instagram. Но всё им не пожрать, Паша Дуров не продаётся!
Так будет и с Фейсбуком. Нельзя всё время делать говно. Кто-то когда-то сделает хороший продукт, куда всё и уйдут.
#соцсети #facebook #акции #рептилоиды',
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 452'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'text' => '???? 21',
'data' => 'send_reaction_1'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'entities' => [
bless( {
'length' => 199,
'offset' => 0
}, 'Telegram::MessageEntityBold' ),
bless( {
'length' => 8,
'offset' => 919
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'offset' => 928,
'length' => 9
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 6,
'offset' => 938
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 11,
'offset' => 945
}, 'Telegram::MessageEntityHashtag' )
],
'views' => 6964,
'flags' => 50368,
'id' => 854,
'post' => 1
}, 'Telegram::Message' ),
'pts_count' => 0
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'message' => bless( {
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 213'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 8'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'views' => 2940,
'entities' => [
bless( {
'length' => 609,
'offset' => 348
}, 'Telegram::MessageEntityItalic' )
],
'flags' => 50368,
'post' => 1,
'id' => 857,
'edit_date' => 1571907636,
'date' => 1571902479,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'message' => 'Пост про 1С вызвал бурную полемику. Человек 10 (видимо, 1с-программистов) единодушно написали:
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
Я бы добавил, что блестящая у 1С дистрибуция, а маркетинг... ну, такое.'
}, 'Telegram::Message' ),
'pts_count' => 0,
'pts' => 158508
}, 'Telegram::UpdateEditChannelMessage' ),
bless( {
'pts' => 158508,
'pts_count' => 0,
'message' => bless( {
'message' => 'Здравствуйте, расскажите, пожалуйста, чем вредит экономике 1С?
// [текст сообщения вырезан чтоб не нарушать правил Хабра о рекламе]
#софт #it #экономика',
'edit_date' => 1571907650,
'date' => 1571893707,
'to_id' => bless( {
'channel_id' => 1380524958
}, 'Telegram::PeerChannel' ),
'flags' => 50368,
'post' => 1,
'id' => 856,
'reply_markup' => bless( {
'rows' => [
bless( {
'buttons' => [
bless( {
'data' => 'send_reaction_0',
'text' => '???? 360'
}, 'Telegram::KeyboardButtonCallback' ),
bless( {
'data' => 'send_reaction_1',
'text' => '???? 32'
}, 'Telegram::KeyboardButtonCallback' )
]
}, 'Telegram::KeyboardButtonRow' )
]
}, 'Telegram::ReplyInlineMarkup' ),
'views' => 4416,
'entities' => [
bless( {
'offset' => 0,
'length' => 64
}, 'Telegram::MessageEntityBold' ),
bless( {
'offset' => 1551,
'length' => 5
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'length' => 3,
'offset' => 1557
}, 'Telegram::MessageEntityHashtag' ),
bless( {
'offset' => 1561,
'length' => 10
}, 'Telegram::MessageEntityHashtag' )
]
}, 'Telegram::Message' )
}, 'Telegram::UpdateEditChannelMessage' )
]
}, 'Telegram::Updates::ChannelDifference' )
}, 'MTProto::RpcResult' )
};
2019.10.24 12:00:51 $1 = {
'in' => bless( {
'update' => bless( {
'user_id' => 2507460,
'status' => bless( {
'was_online' => 1571907651
}, 'Telegram::UserStatusOffline' )
}, 'Telegram::UpdateUserStatus' ),
'date' => 1571907650
}, 'Telegram::UpdateShort' )
};
2019.10.24 12:05:46 $1 = {
'in' => bless( {
'chats' => [],
'date' => 1571907946,
'seq' => 0,
'updates' => [
bless( {
'max_id' => 141719,
'channel_id' => 1295963795
}, 'Telegram::UpdateReadChannelInbox' )
],
'users' => []
}, 'Telegram::Updates' )
};
2019.10.24 13:01:23 $1 = {
'in' => bless( {
'server_salt' => '4914425622822907323',
'unique_id' => '5297282355827493819',
'first_msg_id' => '6751307555044380692'
}, 'MTProto::NewSessionCreated' )
};
2019.10.24 13:24:21 $1 = {
'in' => bless( {
'chats' => [
bless( {
'username' => 'freebsd_ru',
'version' => 0,
'flags' => 5440,
'title' => 'freebsd_ru',
'min' => 1,
'photo' => bless( {
'photo_small' => bless( {
'local_id' => 328733,
'volume_id' => 235140688,
'dc_id' => 2,
'file_reference' => '
'secret' => '4426006807282303416'
}, 'Telegram::FileLocation' ),
'photo_big' => bless( {
'dc_id' => 2,
'file_reference' => '
'volume_id' => 235140688,
'local_id' => 328735,
'secret' => '71251192991540083'
}, 'Telegram::FileLocation' )
}, 'Telegram::ChatPhoto' ),
'date' => 1461248502,
'id' => 1038300508,
'democracy' => 1,
'megagroup' => 1
}, 'Telegram::Channel' )
],
'users' => [
bless( {
'last_name' => 'Panov',
'flags' => 1048646,
'min' => 1,
'id' => 82234609,
'status' => bless( {}, 'Telegram::UserStatusRecently' ),
'first_name' => 'Dima'
}, 'Telegram::User' )
],
'seq' => 0,
'date' => 1571912647,
'updates' => [
bless( {
'pts' => 137596,
'message' => bless( {
'flags' => 256,
'message' => 'Создать джейл с именем покороче ??',
'to_id' => bless( {
'channel_id' => 1038300508
}, 'Telegram::PeerChannel' ),
'id' => 119634,
'date' => 1571912647,
'from_id' => 82234609
}, 'Telegram::Message' ),
'pts_count' => 1
}, 'Telegram::UpdateNewChannelMessage' )
]
}, 'Telegram::Updates' )
};Tak, szczególnie nie pod spoilerem - jeśli nie czytałeś, idź i zrób to!
Och, wai~~… jak to wygląda? Coś bardzo znajomego… może to jest struktura danych typowego Web API w JSON, z wyjątkiem tego, że być może klasy były dołączone do obiektów?..
Okazuje się więc... Co to jest, towarzysze?... Tyle wysiłku - i zatrzymaliśmy się, by odpocząć tam, gdzie programiści WWW dopiero zaczyna?.. Czy po prostu JSON przez HTTPS nie byłby łatwiejszy?! A co dostaliśmy w zamian? Czy te wysiłki były tego warte?
Oceńmy, co dał nam TL+MTProto i jakie alternatywy są możliwe. Cóż, żądanie-odpowiedź HTTP nie pasuje, ale przynajmniej coś na szczycie TLS?
kompaktowa serializacja. Widząc tę strukturę danych, podobną do JSON, przypomina się, że istnieją jej binarne warianty. Oznaczmy MsgPack jako niedostatecznie rozszerzalny, ale jest np. CBOR - notabene standard opisany w . Charakteryzuje się tym, że definiuje tagi, jako mechanizm rozszerzający i wśród są:
- 25 + 256 - zastąpienie zduplikowanych linii odnośnikiem do numeru linii, taka tania metoda kompresji
- 26 - serializowany obiekt Perla z nazwą klasy i argumentami konstruktora
- 27 - serializowany obiekt niezależny od języka z nazwą typu i argumentami konstruktora
Cóż, próbowałem serializować te same dane w TL i CBOR z włączonym pakowaniem ciągów znaków i obiektów. Wynik zaczął się różnić na korzyść CBOR gdzieś od megabajta:
cborlen=1039673 tl_len=1095092W ten sposób produkcja: Istnieją znacznie prostsze formaty, które nie są narażone na błąd synchronizacji lub problem z nieznanym identyfikatorem, z porównywalną wydajnością.
Szybkie nawiązywanie połączenia. Oznacza to zero RTT po ponownym podłączeniu (kiedy klucz był już raz wygenerowany) - obowiązuje od pierwszego komunikatu MTProto, ale z pewnymi zastrzeżeniami - weszli w tę samą sól, sesja nie zepsuła się itp. Co TLS oferuje nam w zamian? Powiązany cytat:
Podczas korzystania z PFS w TLS bilety sesji TLS (), aby wznowić zaszyfrowaną sesję bez renegocjacji kluczy i bez przechowywania informacji o kluczu na serwerze. Podczas otwierania pierwszego połączenia i generowania kluczy serwer szyfruje stan połączenia i przesyła go do klienta (w postaci biletu sesyjnego). W związku z tym po wznowieniu połączenia klient wysyła z powrotem do serwera bilet sesyjny zawierający między innymi klucz sesyjny. Sam bilet jest szyfrowany kluczem tymczasowym (kluczem biletu sesyjnego), który jest przechowywany na serwerze i musi zostać rozesłany do wszystkich serwerów frontendowych obsługujących SSL w rozwiązaniach klastrowych.[10] Tym samym wprowadzenie biletu sesyjnego może naruszyć PFS w przypadku naruszenia tymczasowych kluczy serwera, np. gdy są one przechowywane przez długi czas (OpenSSL, nginx, Apache domyślnie przechowują je przez cały czas działania programu; popularne strony używać klucza przez kilka godzin, do kilku dni).
Tutaj RTT nie jest zerowe, trzeba wymienić co najmniej ClientHello i ServerHello, po czym razem z Finished klient może już wysyłać dane. Ale tutaj należy pamiętać, że nie mamy sieci Web z jej wiązką nowo otwieranych połączeń, ale komunikatora, którego połączenie to często jedno i mniej lub bardziej długotrwałe, stosunkowo krótkie żądania dotyczące stron internetowych - wszystko jest multipleksowane wewnątrz. To jest całkiem do przyjęcia, jeśli nie trafiliśmy na bardzo zły odcinek metra.
Zapomniałeś czegoś jeszcze? Napisz w komentarzach.
Ciąg dalszy nastąpi!
W drugiej części tej serii wpisów zajmiemy się kwestiami organizacyjnymi, a nie technicznymi - podejściem, ideologią, interfejsem, podejściem do użytkowników itp. Na podstawie jednak przedstawionych tu informacji technicznych.
Trzecia część będzie kontynuacją analizy komponentu technicznego / doświadczeń rozwojowych. Dowiesz się w szczególności:
- kontynuacja pandemonium z różnymi typami TL
- nieznane rzeczy o kanałach i supergrupach
- niż dialogi jest gorsze niż lista
- o bezwzględnym i względnym adresowaniu wiadomości
- jaka jest różnica między zdjęciem a obrazem
- jak emotikony ingerują w tekst pisany kursywą
i inne kule! Czekać na dalsze informacje!
Źródło: www.habr.com
