

Wczoraj, 9 grudnia, kolejne wydanie Kubernetesa - 1.17. Zgodnie z tradycją, która rozwinęła się na naszym blogu, mówimy o najważniejszych zmianach w nowej wersji.

Informacje użyte do przygotowania niniejszego materiału pochodzą z oficjalnego komunikatu, , i powiązane problemy, żądania ściągnięcia i propozycje ulepszeń Kubernetes (KEP). Więc co nowego?..
Routing uwzględniający topologię
Społeczność Kubernetes czekała na tę funkcję od dawna - Routing usług uwzględniający topologię. Jeśli pochodzi z października 2018 r. i jest oficjalny — 2 lata temu, zwykłe problemy (tak jak ) - i jeszcze kilka lat starszy...
Ogólną ideą jest zapewnienie możliwości implementacji „lokalnego” routingu dla usług rezydujących w Kubernetesie. „Lokalność” w tym przypadku oznacza „ten sam poziom topologiczny” (poziom topologii), Które może być:
- węzeł identyczny dla usług,
- ta sama szafa serwerowa,
- ten sam region
- ten sam dostawca usług w chmurze,
- ...
Przykłady wykorzystania tej funkcji:
- oszczędności na ruchu w instalacjach chmurowych z wieloma strefami dostępności (multi-AZ) – patrz. na przykładzie ruchu z tego samego regionu, ale różnych AZ w AWS;
- mniejsze opóźnienia wydajności/lepsza przepustowość;
- usługa dzielona, która zawiera lokalne informacje o węźle w każdym fragmencie;
- umieszczenie fluentd (lub analogów) w tym samym węźle z aplikacjami, których logi są gromadzone;
- ...
Taki routing, który „wie” o topologii, nazywany jest także powinowactwem sieciowym - przez analogię , lub pojawił się (i ). Obecny poziom realizacji ServiceTopology w Kubernetesie – wersja alfa.
Aby uzyskać szczegółowe informacje na temat działania tej funkcji i sposobu, w jaki można już z niej korzystać, przeczytaj od jednego z autorów.
Obsługa podwójnego stosu IPv4/IPv6
Znaczący postęp w innej funkcji sieciowej: jednoczesna obsługa dwóch stosów IP, która została po raz pierwszy wprowadzona w . W szczególności nowe wydanie przyniosło następujące zmiany:
- w kube-proxy możliwość jednoczesnej pracy w obu trybach (IPv4 i IPv6);
- в
Pod.Status.PodIPsobsługa API w dół (w tym samym czasie co w/etc/hoststeraz wymagają od hosta dodania adresu IPv6); - obsługa podwójnego stosu (Kubernetes IN Docker) i ;
- zaktualizowane testy e2e.
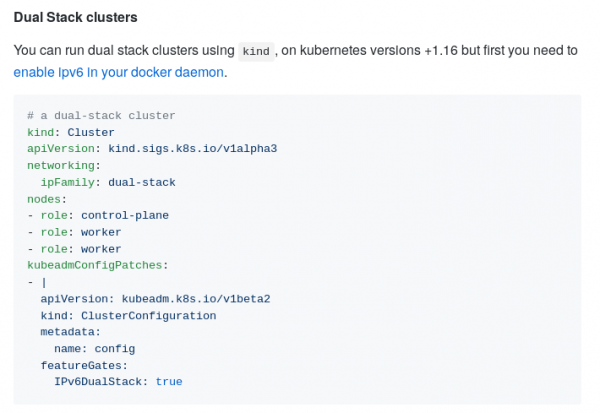
przy użyciu podwójnego stosu IPV4/IPv6 w KIND
Postęp w CSI
Deklarowany jako stabilny do przechowywania danych w oparciu o CSI, wprowadzony po raz pierwszy w .
Inicjatywa dla migracja wtyczek wolumenowych do CSI - - osiągnięto wersję beta. Ta funkcja ma kluczowe znaczenie przy tłumaczeniu istniejących wtyczek pamięci masowej (w drzewie) do nowoczesnego interfejsu (CSI, poza drzewem) niewidoczny dla użytkowników końcowych Kubernetes. Administratorzy klastrów będą musieli jedynie włączyć CSI Migration, po czym istniejące zasoby stanowe i obciążenia będą nadal „po prostu działać”… ale korzystając z najnowszych sterowników CSI zamiast przestarzałych zawartych w rdzeniu Kubernetes.
W tej chwili migracja sterowników AWS EBS jest gotowa w wersji beta (kubernetes.io/aws-ebs) i GCE PD (kubernetes.io/gce-pd). Prognozy dla pozostałych obiektów magazynowych przedstawiają się następująco:
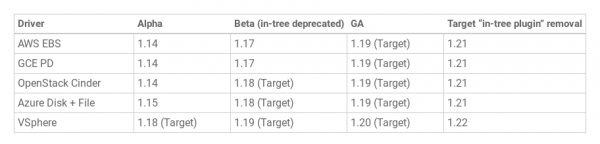
Rozmawialiśmy o tym, jak „tradycyjna” obsługa pamięci masowej w K8 pojawiła się w CSI . I dedykowane jest przejście migracji CSI do statusu beta na blogu projektu.
Dodatkowo kolejna istotna funkcjonalność w kontekście CSI, która wywodzi się (implementacja alfa) w K1.17s 8, osiągnęła status beta (tj. domyślnie włączona) w wydaniu Kubernetes 1.12 - i wyzdrowienie z nich. Wśród zmian wprowadzonych w Kubernetes Volume Snapshot w drodze do wersji beta:
- podzielenie wózka bocznego z zewnętrznym migawką CSI na dwa kontrolery,
- dodano sekret do usunięcia (tajemnica usunięcia) jako adnotacja do zawartości migawki woluminu,
- nowy finalizator (finalizator) aby zapobiec usunięciu obiektu API migawki, jeśli istnieją pozostałe połączenia.
W chwili wydania 1.17 funkcja jest obsługiwana przez trzy sterowniki CSI: sterownik CSI GCE Persistent Disk, sterownik Portworx CSI i sterownik CSI NetApp Trident. Więcej szczegółów na temat jego wdrożenia i stosowania można znaleźć w na blogu.
Etykiety dostawcy chmury
Oznacza to automatycznie przypisane do utworzonych węzłów i woluminów w zależności od używanego dostawcy chmury, są dostępne w Kubernetesie w wersji beta już od bardzo dawna – od wydania K8s 1.2 (kwiecień 2016!). Biorąc pod uwagę ich szerokie zastosowanie przez tak długi czas, programiści , że nadszedł czas, aby ogłosić, że funkcja jest stabilna (GA).
Dlatego wszystkie zostały odpowiednio przemianowane (według topologii):
-
beta.kubernetes.io/instance-type→node.kubernetes.io/instance-type -
failure-domain.beta.kubernetes.io/zone→topology.kubernetes.io/zone -
failure-domain.beta.kubernetes.io/region→topology.kubernetes.io/region
... ale nadal są dostępne pod starymi nazwami (w celu zapewnienia kompatybilności wstecznej). Jednak wszystkim administratorom zaleca się przejście na obecne etykiety. K8s został zaktualizowany.
Ustrukturyzowane wyjście kubeadm
Po raz pierwszy zaprezentowane w wersji alfa . Obsługiwane formaty: JSON, YAML, szablon Go.
Motywacja do wdrożenia tej funkcji (wg ) Jest:
Chociaż Kubernetes można wdrożyć ręcznie, de facto (jeśli nie de iure) standardem dla tej operacji jest użycie kubeadm. Popularne narzędzia do zarządzania systemami, takie jak Terraform, korzystają z kubeadm przy wdrażaniu Kubernetes. Planowane ulepszenia interfejsu Cluster API obejmują komponowalny pakiet do ładowania Kubernetes za pomocą kubeadm i cloud-init.
Bez uporządkowanego wyjścia nawet najbardziej nieszkodliwe zmiany na pierwszy rzut oka mogą zepsuć Terraform, Cluster API i inne oprogramowanie korzystające z wyników kubeadm.
Nasze najbliższe plany obejmują obsługę (w formie ustrukturyzowanych wyników) następujących poleceń kubeadm:
-
alpha certs -
config images list -
init -
token create -
token list -
upgrade plan -
version
Ilustracja odpowiedzi JSON na polecenie kubeadm init -o json:
{
"node0": "192.168.20.51:443",
"caCrt": "sha256:1f40ff4bd1b854fb4a5cf5d2f38267a5ce5f89e34d34b0f62bf335d74eef91a3",
"token": {
"id": "5ndzuu.ngie1sxkgielfpb1",
"ttl": "23h",
"expires": "2019-05-08T18:58:07Z",
"usages": [
"authentication",
"signing"
],
"description": "The default bootstrap token generated by 'kubeadm init'.",
"extraGroups": [
"system:bootstrappers:kubeadm:default-node-token"
]
},
"raw": "Rm9yIHRoZSBhY3R1YWwgb3V0cHV0IG9mIHRoZSAia3ViZWFkbSBpbml0IiBjb21tYW5kLCBwbGVhc2Ugc2VlIGh0dHBzOi8vZ2lzdC5naXRodWIuY29tL2FrdXR6LzdhNjg2ZGU1N2JmNDMzZjkyZjcxYjZmYjc3ZDRkOWJhI2ZpbGUta3ViZWFkbS1pbml0LW91dHB1dC1sb2c="
}Stabilizacja pozostałych innowacji
Generalnie wydanie Kubernetesa 1.17 odbyło się pod hasłem „stabilność" Ułatwiło to fakt, że wiele zawartych w nim funkcji (ich łączna liczba wynosi 14) otrzymał status GA. Pomiędzy nimi:
- „oznaczanie” węzłów według określonych warunków (), pojawił się w ;
- - nowy typ wydarzeń, które mają etykietę informującą, że wszystkie obiekty są do określonej wersji (
resourceVersion) zostały już przetworzone przez zegarek; - (domyślnie) dla zasobów niestandardowych;
- w przestrzeniach nazw procesów pod;
-
ScheduleDaemonSetPods- przy użyciu kube-scheduler (zamiast kontrolera DaemonSet); - od liczby woluminów w zależności od typu węzła;
- dla nazw katalogów zamontowanych jako
subPath; - do specjalistycznego Lease API;
- „ochrona finalizatora” () dla modułów równoważenia obciążenia (sprawdzanie odpowiednich zasobów Usługi przed usunięciem zasobów LoadBalancer);
- wydajność podczas pracy z wieloma zegarkami monitorującymi identyczne zestawy obiektów - osiągnięta poprzez uniknięcie powtarzającej się serializacji tych samych obiektów dla każdego obserwatora.
Inne zmiany
Pełna lista nowości w Kubernetesie 1.17 nie ogranicza się oczywiście do tych wymienionych powyżej. Oto kilka innych (a pełniejsza lista znajduje się w ):
- Funkcja zaprezentowana w ostatniej wersji osiągnęła wersję beta ;
- podobna zmiana EndpointSlice API (również od K8s 1.16), jednak na razie to rozwiązanie poprawiające wydajność/skalowalność Endpoint API nie jest domyślnie włączone;
- zasobniki mają teraz kluczowe znaczenie dla działania klastra nie tylko w przestrzeniach nazw
kube-system(szczegółowe informacje można znaleźć w dokumentacji dot ); - nowa opcja dla kubelet - — umożliwia jednoznaczne zdefiniowanie listy procesorów zarezerwowanych dla systemu;
- dla
kubectl logsnowa flaga--prefix, dodając nazwę poda i kontenera źródłowego do każdej linii dziennika; - в
label.SelectorRequiresExactMatch; - wszystkie kontenery w kube-dns z mniejszymi przywilejami;
- wydzielone do osobnego repozytorium GitHub i nie będą już zawarte w wydaniach Kubernetes;
- dużo kube-proxy dla portów innych niż UDP.
Zmiany zależności:
- Wersja CoreDNS zawarta w kubeadm to 1.6.5;
- wersja crictl zaktualizowana do wersji 1.16.1;
- CSI 1.2.0;
- itp. 3.4.3;
- Najnowsza testowana wersja Dockera zaktualizowana do 19.03;
- Minimalna wersja Go wymagana do zbudowania Kubernetes 1.17 to 1.13.4.
PS
Przeczytaj także na naszym blogu:
- «";
- «";
- «";
- «".
Źródło: www.habr.com
