

Nazywam się Viktor Yagofarov i rozwijam platformę Kubernetes w DomClick jako kierownik ds. rozwoju technicznego w zespole Ops (operacyjnym). Chciałbym porozmawiać o strukturze naszych procesów Dev <-> Ops, o cechach działania jednego z największych klastrów k8s w Rosji, a także o praktykach DevOps/SRE, które stosuje nasz zespół.

Operacje drużynowe
Zespół Ops liczy obecnie 15 osób. Trzech z nich odpowiada za biuro, dwóch pracuje w innej strefie czasowej i jest dyspozycyjnych, także w nocy. W ten sposób ktoś z Ops jest zawsze przy monitorze i jest gotowy zareagować na incydent o dowolnej złożoności. Nie mamy nocnych zmian, co chroni naszą psychikę i daje każdemu możliwość wysypiania się i spędzania wolnego czasu nie tylko przy komputerze.
Każdy ma inne kompetencje: networkerzy, administratorzy baz danych, specjaliści od stosu ELK, administratorzy/programiści Kubernetes, monitoring, wirtualizacja, specjaliści od sprzętu itp. Łączy wszystkich jedno – każdy może w jakimś stopniu zastąpić każdego z nas: np. wprowadzić nowe węzły do klastra k8s, zaktualizować PostgreSQL, napisać potok CI/CD+Ansible, zautomatyzować coś w Pythonie/Bash/Go, połączyć kawałek sprzętu do DPC. Silne kompetencje w jakimkolwiek obszarze nie przeszkadzają w zmianie kierunku działania i rozpoczęciu pompowania w innym obszarze. Na przykład dostałem pracę w firmie jako specjalista od PostgreSQL, a teraz moim głównym obszarem odpowiedzialności są klastry Kubernetes. W zespole każdy wzrost jest mile widziany, a poczucie barku jest bardzo rozwinięte.
A tak przy okazji, szukamy kandydatów. Wymagania wobec kandydatów są dość standardowe. Dla mnie osobiście ważne jest, aby osoba pasowała do zespołu, była nieskłonna do konfrontacji, ale potrafiła bronić swojego punktu widzenia, była chętna do rozwoju, nie bała się próbować czegoś nowego i chętnie dzieliła się swoimi pomysłami. Wymagane są również umiejętności programowania w językach skryptowych i znajomość podstaw. Linux i angielski. Angielski jest potrzebny po prostu po to, żeby w razie pomyłki móc znaleźć rozwiązanie problemu w Google w 10 sekund, a nie w 10 minut. Specjaliści z dogłębną wiedzą Linux Teraz jest bardzo trudno: to zabawne, ale dwóch na trzech kandydatów nie potrafi odpowiedzieć na pytanie „Co to jest Load Average? Z czego się składa?”, a pytanie „Jak utworzyć zrzut pamięci z programu w C” jest uważane za coś dla nadludzi… albo dinozaurów. Musimy się z tym pogodzić, ponieważ ludzie zazwyczaj mają wysoko rozwinięte inne kompetencje, a my nauczymy ich Linuksa. Odpowiedź na pytanie „Po co inżynier DevOps musi to wszystko wiedzieć w nowoczesnym świecie chmury” będzie musiała pozostać poza zakresem tego artykułu, ale krótko mówiąc: wszystko to jest niezbędne.
Polecenie narzędzia
Zespół Narzędzi odgrywa znaczącą rolę w automatyzacji. Ich głównym zadaniem jest tworzenie wygodnych narzędzi graficznych i CLI dla programistów. Na przykład nasz wewnętrzny rozwój Confer umożliwia wdrożenie aplikacji do Kubernetes za pomocą zaledwie kilku kliknięć myszką, skonfigurowanie jej zasobów, kluczy z repozytorium itp. Kiedyś był Jenkins + Helm 2, ale musiałem opracować własne narzędzie, aby wyeliminować kopiuj-wklej i ujednolicić cykl życia oprogramowania.
Zespół Ops nie pisze potoków dla programistów, ale może doradzać we wszelkich kwestiach związanych z ich pisaniem (niektórzy nadal mają Helm 3).
DevOps
Jeśli chodzi o DevOps, widzimy to tak:
Zespoły programistów piszą kod, wdrażają go za pośrednictwem Confer to dev -> qa/stage -> prod. Odpowiedzialność za to, aby kod nie spowalniał i nie wyrzucał błędów, spoczywa na zespołach Dev i Ops. W ciągu dnia oficer dyżurny z zespołu Ops powinien odpowiedzieć na incydent swoim zgłoszeniem, a wieczorem i w nocy administrator dyżurny (Ops) powinien obudzić dyżurnego programistę, jeśli wie na pewno, że problem nie jest w infrastrukturze. Wszystkie metryki i alerty w monitorowaniu pojawiają się automatycznie lub półautomatycznie.
Obszar odpowiedzialności Ops zaczyna się od momentu wdrożenia aplikacji do produkcji, ale odpowiedzialność Dev na tym się nie kończy – robimy jedno i jedziemy na tym samym wózku.
Deweloperzy doradzają administratorom, jeśli potrzebują pomocy w pisaniu mikrousługi administracyjnej (na przykład Go backend + HTML5), a administratorzy doradzają programistom we wszelkich kwestiach związanych z infrastrukturą lub k8s.
Nawiasem mówiąc, w ogóle nie mamy monolitu, tylko mikroserwisy. Ich liczba jak dotąd oscyluje między 900 a 1000 w klastrze prod k8s, jeśli mierzyć liczbą wdrożenia. Liczba strąków waha się między 1700 a 2000. Strąków w klastrze produkcyjnym jest obecnie około 2000.
Nie mogę podać dokładnych liczb, ponieważ monitorujemy niepotrzebne mikroserwisy i wycinamy je w trybie półautomatycznym. Śledzenie zbędnych podmiotów w k8s pomaga nam co oszczędza zasoby i pieniądze.
Управление ресурсами
Monitorowanie
Kompetentnie zbudowany i informacyjny monitoring staje się kamieniem węgielnym w działaniu dużego klastra. Nie znaleźliśmy jeszcze uniwersalnego rozwiązania, które pokryłoby 100% wszystkich potrzeb w zakresie monitoringu, dlatego okresowo nitujemy różne niestandardowe rozwiązania w tym środowisku.
- Zabbix. Stary dobry monitoring, który ma za zadanie przede wszystkim monitorować ogólny stan infrastruktury. Mówi nam, kiedy węzeł umiera według procesora, pamięci, dysków, sieci i tak dalej. Nic nadprzyrodzonego, ale mamy też osobnego DaemonSet agentów, za pomocą których np. monitorujemy stan DNS w klastrze: szukamy głupich podów coredns, sprawdzamy dostępność zewnętrznych hostów. Wydawałoby się, że po co zawracać sobie tym głowę, ale przy dużym natężeniu ruchu ten komponent jest poważnym punktem awarii. Wcześniej miałem jak zmagał się z wydajnością DNS w klastrze.
- Operator Prometeusza. Zestaw różnych eksporterów daje doskonały przegląd wszystkich komponentów klastra. Następnie wizualizujemy to wszystko na dużych dashboardach w Grafanie i używamy alertmanagera do powiadomień.
Kolejnym przydatnym dla nas narzędziem jest . Napisaliśmy to po tym, jak kilka razy napotkaliśmy sytuację, w której jeden zespół nałożył się swoimi ścieżkami na Ingress innego zespołu, co spowodowało 50x błędów. Teraz, przed wdrożeniem do produkcji, programiści sprawdzają, czy nikogo nie skrzywdzą, a dla mojego zespołu jest to dobre narzędzie do wstępnej diagnozy problemów z Ingressami. To zabawne, że na początku był napisany dla administratorów i wyglądał raczej „niezdarnie”, ale po tym, jak zespoły programistów zakochały się w tym narzędziu, bardzo się zmieniło i zaczęło wyglądać inaczej niż „administrator zrobił twarz dla administratorów” . Wkrótce zrezygnujemy z tego narzędzia i takie sytuacje będą weryfikowane jeszcze przed uruchomieniem potoku.
Zasoby zespołu w „Cube”
Zanim przejdziemy do przykładów, warto wyjaśnić, w jaki sposób mamy alokację zasobów mikroserwisy.
Aby zrozumieć, które zespoły iw jakich ilościach ich używają ресурсы (procesor, pamięć, lokalny dysk SSD), alokujemy własne przestrzeń nazw w „Kostce” i ograniczyć jej maksymalne możliwości w zakresie procesora, pamięci i dysku, po uprzednim omówieniu potrzeb zespołów. W związku z tym jedno polecenie w ogólnym przypadku nie zablokuje wdrożenia całego klastra, przydzielając sobie tysiące rdzeni i terabajtów pamięci. Dostępy do przestrzeni nazw są wydawane przez AD (używamy RBAC). Przestrzenie nazw i ich limity są dodawane przez pull request do repozytorium GIT, a następnie wszystko jest automatycznie wdrażane przez potok Ansible.
Przykład alokacji zasobów na zespół:
namespaces:
chat-team:
pods: 23
limits:
cpu: 11
memory: 20Gi
requests:
cpu: 11
memory: 20Gi
Żądania i ograniczenia
sześcienny" PROŚBA to liczba gwarantowanych zarezerwowanych zasobów w ramach pod (jeden lub więcej kontenerów dokerów) w klastrze. Limit jest niegwarantowanym maksimum. Na wykresach często można zobaczyć, jak jakiś zespół ustawił sobie zbyt wiele żądań dla wszystkich swoich aplikacji i nie może wdrożyć aplikacji do „Kostki”, ponieważ w ich przestrzeni nazw wszystkie żądania zostały już „wydane”.
Właściwym wyjściem z tej sytuacji jest przyjrzenie się rzeczywistemu zużyciu zasobów i porównanie go z żądaną kwotą (Request).
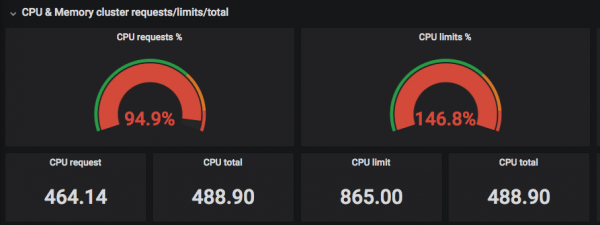
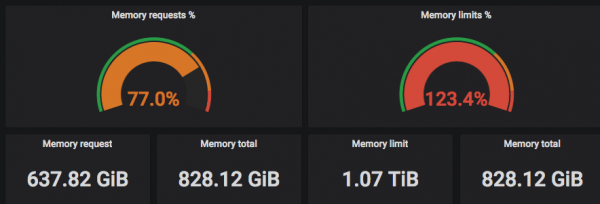
Powyższe zrzuty ekranu pokazują, że „żądane” (żądane) procesory są wybierane do rzeczywistej liczby wątków, a limity mogą przekraczać rzeczywistą liczbę wątków procesora =)
Przyjrzyjmy się teraz bliżej pewnej przestrzeni nazw (wybrałem przestrzeń nazw kube-system - systemowa przestrzeń nazw dla komponentów samej „Kostki”) i zobaczmy stosunek faktycznie wykorzystanego czasu procesora i pamięci do żądanego:
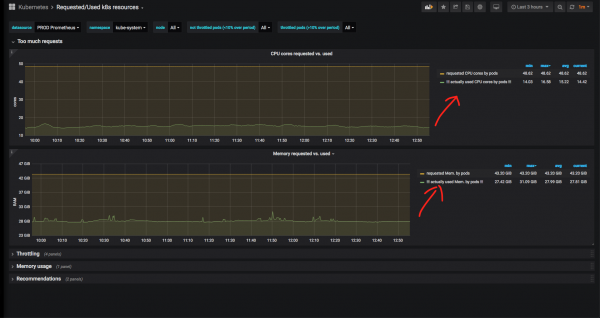
Oczywiste jest, że na usługi systemowe zarezerwowano znacznie więcej pamięci i procesora, niż jest to faktycznie wykorzystywane. W przypadku kube-system jest to uzasadnione: zdarzało się, że kontroler nginx ingress lub nodelocaldns w szczycie spoczął na CPU i zjadał dużo RAM-u, więc tutaj taki margines jest uzasadniony. Ponadto nie możemy polegać na wykresach z ostatnich 3 godzin: pożądane jest przeglądanie danych historycznych w dużym okresie czasu.
Opracowano system „rekomendacji”. Na przykład tutaj możesz zobaczyć, które zasoby lepiej byłoby podnieść „limity” (górny dozwolony pasek), aby „throttling” nie wystąpił: moment, w którym kapsuła zużyła już procesor lub pamięć na przydzielony kwant czasu i czeka, aż zostanie „odmrożony”:
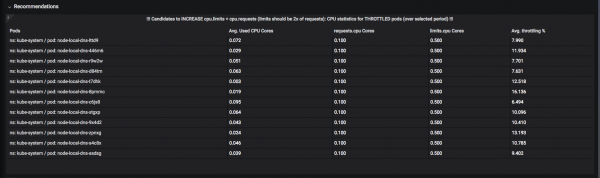
A oto strąki, które powinny złagodzić ich apetyt:
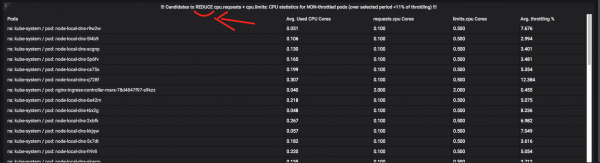
Про dławienie + monitorowanie zasobów, możesz napisać więcej niż jeden artykuł, więc zadawaj pytania w komentarzach. W kilku słowach mogę powiedzieć, że zadanie automatyzacji takich metryk jest bardzo trudne i wymaga dużo czasu oraz balansowania z funkcjami „okienkowymi” i „CTE” Prometheus / VictoriaMetrics (te terminy są w cudzysłowie, ponieważ prawie nic takiego w PromQL, a przerażające zapytania trzeba stawiać na kilku ekranach tekstu i je optymalizować).
Dzięki temu programiści mają narzędzia do monitorowania swoich przestrzeni nazw w „Kostce” i są w stanie wybrać, gdzie iw jakim czasie, które aplikacje mogą „obcinać” zasoby, a które pody mogą mieć cały procesor przez całą noc.
Metodologie
W towarzystwie jak teraz modny, przestrzegamy DevOps- i SRE-praktykujący Kiedy firma ma 1000 mikroserwisów, około 350 programistów i 15 administratorów dla całej infrastruktury, trzeba „być modnym”: za tymi wszystkimi „modnymi hasłami” kryje się pilna potrzeba automatyzacji wszystkiego i wszystkiego, a administratorzy nie powinni być wąskim gardłem w procesach.
Jako Ops zapewniamy różne wskaźniki i pulpity nawigacyjne dla programistów związane z szybkością reakcji usługi i błędami usługi.
Wykorzystujemy metodyki takie jak: , и łącząc je ze sobą. Staramy się minimalizować liczbę kokpitów tak, aby na pierwszy rzut oka było jasne, która usługa jest obecnie degradowana (na przykład kody odpowiedzi na sekundę, czas odpowiedzi na 99 percentylu) i tak dalej. Gdy tylko pojawią się nowe metryki dla ogólnych pulpitów nawigacyjnych, natychmiast je rysujemy i dodajemy.
Od miesiąca nie rysuję grafiki. To chyba dobry znak: oznacza to, że większość „chceń” została już zrealizowana. Tak się złożyło, że przez tydzień przynajmniej raz dziennie rysowałem jakiś nowy wykres.
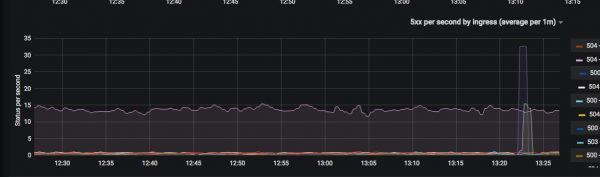
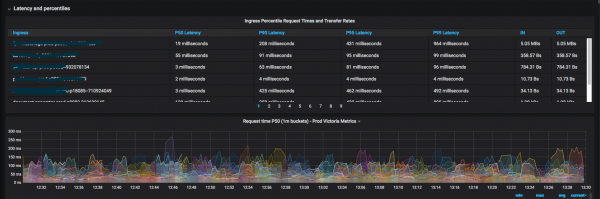
Otrzymany wynik jest cenny, ponieważ obecnie programiści rzadko zwracają się do administratorów z pytaniem „gdzie można zobaczyć jakieś metryki”.
Внедрение Siatka serwisowa jest tuż za rogiem i powinno ułatwić wszystkim życie, koledzy z Tools są już blisko wdrożenia abstrakcyjnego „Istio zdrowego człowieka”: cykl życia każdego żądania HTTP (s) będzie widoczny w monitoringu, a zawsze będzie można zrozumieć „na jakim etapie wszystko się zepsuło” podczas interakcji między usługami (i nie tylko). Subskrybuj wiadomości z centrum DomClick. =)
Wsparcie infrastruktury Kubernetes
Historycznie używamy wersji z poprawkami Kubespray - Rola ansible do wdrażania, rozszerzania i aktualizowania Kubernetes. W pewnym momencie wsparcie dla instalacji innych niż kubeadm zostało odcięte od głównej gałęzi, a proces przejścia do kubeadm nie został zaproponowany. W rezultacie Southbridge stworzył własny fork (z obsługą kubeadm i szybką poprawką krytycznych problemów).
Proces aktualizacji dla wszystkich klastrów k8s wygląda następująco:
- Weź Kubespray z Southbridge, skontaktuj się z naszym oddziałem, Merjim.
- Wdrażanie aktualizacji do Napięcia- "Sześcian".
- Wprowadzamy aktualizację po jednym węźle na raz (w Ansible jest to „serial: 1”) w dev- "Sześcian".
- Aktualizowanie Szturchać w sobotę wieczorem, jeden węzeł na raz.
W przyszłości są plany wymiany Kubespray do czegoś szybszego i idź do kubeadm.
W sumie mamy trzy „kostki”: Stress, Dev i Prod. Planujemy uruchomienie kolejnegogorący stan gotowości) Prod- „Cube” w drugim centrum danych. Napięcia и dev na żywo w maszynach wirtualnych (oVirt for Stress i VMWare cloud for Dev). Szturchać- „Cube” żyje na „bare metal” (bare metal): to te same węzły z 32 wątkami procesora, 64-128 GB pamięci i 300 GB SSD RAID 10 – jest ich łącznie 50. Trzy „cienkie” węzły są dedykowane „mistrzom” Szturchać- „Kuba”: 16 GB pamięci, 12 wątków procesora.
Do sprzedaży wolimy używać „gołego metalu” i unikać zbędnych warstw typu OpenStack: nie potrzebujemy „hałaśliwych sąsiadów” i procesora ukraść czas. A złożoność administracji wzrasta o około połowę w przypadku wewnętrznego OpenStack.
Dla CI/CD Cubic i innych komponentów infrastruktury używamy oddzielnego serwera GIT, Helm 3 atomowy), Jenkins, Ansible i Docker. Uwielbiamy gałęzie funkcji i wdrażamy je w różnych środowiskach z tego samego repozytorium.
wniosek

Tak ogólnie wygląda proces DevOps w DomClick od strony inżyniera operacyjnego. Artykuł okazał się mniej techniczny, niż się spodziewałem: dlatego śledźcie newsy DomClick na temat Habré: będzie więcej „hardkorowych” artykułów o Kubernetes i nie tylko.
Źródło: www.habr.com
