


Mamy rok 2019, a my nadal nie mamy standardowego rozwiązania do agregacji logów w Kubernetesie. W tym artykule chcielibyśmy, na przykładach z prawdziwej praktyki, podzielić się naszymi poszukiwaniami, napotkanymi problemami i ich rozwiązaniami.
Najpierw jednak zastrzeżę, że różni klienci zbierając logi, rozumieją bardzo różne rzeczy:
- ktoś chce zobaczyć logi bezpieczeństwa i audytu;
- ktoś - scentralizowane logowanie całej infrastruktury;
- a dla niektórych wystarczy zebrać tylko logi aplikacji, z wyłączeniem np. balanserów.
Poniżej znajduje się fragment opisujący, jak wdrożyliśmy różne „listy życzeń” i jakie napotkaliśmy trudności.
Teoria: o narzędziach do logowania
Podstawowe informacje o elementach systemu logowania
Rejestrowanie przeszło długą drogę, w wyniku której opracowano metodologie gromadzenia i analizowania logów, z których korzystamy dzisiaj. Już w latach pięćdziesiątych Fortran wprowadził analogię standardowych strumieni wejścia/wyjścia, co pomogło programiście debugować jego program. Były to pierwsze logi komputerowe, które ułatwiły życie ówczesnym programistom. Dziś widzimy w nich pierwszy element systemu pozyskiwania drewna - źródło lub „producent” kłód.
Informatyka nie stała w miejscu: pojawiły się sieci komputerowe, pierwsze klastry... Zaczęły działać złożone systemy składające się z kilku komputerów. Teraz administratorzy systemu byli zmuszeni zbierać logi z kilku komputerów, a w szczególnych przypadkach mogli dodawać komunikaty jądra systemu operacyjnego na wypadek konieczności zbadania awarii systemu. Aby opisać scentralizowane systemy gromadzenia dzienników, opublikowano je na początku XXI wieku , który ujednolicił Remote_syslog. Tak pojawił się kolejny ważny element: zbieracz logów i ich przechowywanie.
Wraz ze wzrostem ilości logów i powszechnym wprowadzaniem technologii webowych pojawiło się pytanie, jakie logi należy wygodnie pokazywać użytkownikom. Proste narzędzia konsolowe (awk/sed/grep) zostały zastąpione bardziej zaawansowanymi przeglądający logi - trzeci składnik.
W związku ze wzrostem ilości kłód stało się jasne coś innego: potrzebne są kłody, ale nie wszystkie. Różne kłody wymagają różnych poziomów konserwacji: niektóre można zgubić w ciągu jednego dnia, inne zaś należy przechowywać przez 5 lat. Do systemu logującego dodano więc komponent służący do filtrowania i routingu przepływów danych – nazwijmy to filtr.
Duży skok nastąpił także w przypadku przechowywania danych: od zwykłych plików do relacyjnych baz danych, a następnie do przechowywania zorientowanego na dokumenty (na przykład Elasticsearch). Zatem magazyn został oddzielony od kolektora.
Ostatecznie samo pojęcie dziennika rozrosło się do swego rodzaju abstrakcyjnego strumienia zdarzeń, który chcemy zachować dla historii. A raczej w przypadku konieczności przeprowadzenia śledztwa lub sporządzenia raportu analitycznego...
W rezultacie w stosunkowo krótkim czasie zbieranie logów rozwinęło się w ważny podsystem, który słusznie można nazwać jednym z podsekcji Big Data.
O ile kiedyś do „systemu logowania” wystarczały zwykłe wydruki, teraz sytuacja bardzo się zmieniła.
Kubernetes i logi
Kiedy Kubernetes zawitał do infrastruktury, nie ominął go także istniejący już problem gromadzenia logów. W pewnym sensie stało się to jeszcze bardziej bolesne: zarządzanie platformą infrastrukturalną zostało nie tylko uproszczone, ale i skomplikowane. Wiele starych usług rozpoczęło migrację do mikrousług. W kontekście logów przekłada się to na rosnącą liczbę źródeł logów, ich specyficzny cykl życia i konieczność śledzenia powiązań wszystkich elementów systemu poprzez logi...
Patrząc w przyszłość, mogę stwierdzić, że obecnie niestety nie ma ujednoliconej opcji logowania dla Kubernetesa, która wypadałaby korzystnie w porównaniu ze wszystkimi innymi. Najpopularniejsze schematy w społeczności są następujące:
- ktoś rozwija stos EFK (Elasticsearch, Fluentd, Kibana);
- ktoś próbuje niedawno wydanego lub używa ;
- nas (a może nie tylko my?..) Jestem w dużej mierze zadowolony z własnego rozwoju - ...
Z reguły w klastrach K8s (dla rozwiązań self-hosted) stosujemy następujące pakiety:
- ;
- .
Nie będę się jednak rozwodzić nad instrukcjami ich instalacji i konfiguracji. Zamiast tego skupię się na ich niedociągnięciach i ogólnie na wnioskach na temat sytuacji z logami.
Ćwicz z kłodami w K8

„Dzienne dzienniki”, ilu Was jest?..
Scentralizowane gromadzenie logów z dość dużej infrastruktury wymaga znacznych zasobów, które zostaną przeznaczone na gromadzenie, przechowywanie i przetwarzanie logów. Podczas realizacji różnych projektów napotykaliśmy na różnorodne wymagania i wynikające z nich problemy operacyjne.
Spróbujmy ClickHouse
Przyjrzyjmy się scentralizowanemu magazynowi w projekcie z aplikacją, która dość aktywnie generuje logi: ponad 5000 linii na sekundę. Zacznijmy pracować z jego logami, dodając je do ClickHouse.
Gdy tylko wymagany będzie maksymalny czas rzeczywisty, 4-rdzeniowy serwer z ClickHouse będzie już przeciążony w podsystemie dyskowym:
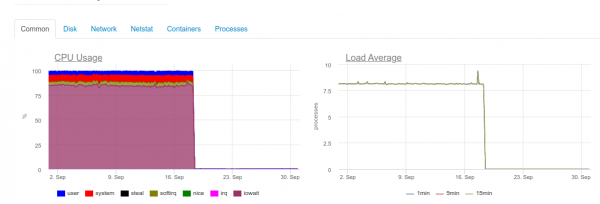
Ten rodzaj ładowania wynika z tego, że staramy się pisać w ClickHouse tak szybko, jak to możliwe. A baza danych reaguje na to zwiększonym obciążeniem dysku, co może powodować następujące błędy:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts
Faktem jest, że w ClickHouse (zawierają dane dziennika) mają własne trudności podczas operacji zapisu. Wstawione do nich dane generują tymczasową partycję, która następnie jest scalana z tabelą główną. W rezultacie nagranie okazuje się bardzo wymagające na dysku, a także podlega ograniczeniu, o którym otrzymaliśmy wcześniej informację: w ciągu 1 sekundy można połączyć nie więcej niż 300 podpartycji (w rzeczywistości jest to 300 wstawek na sekundę).
Aby uniknąć takiego zachowania, w jak największych kawałkach i nie częściej niż 1 raz na 2 sekundy. Jednak pisanie dużymi seriami sugeruje, że w ClickHouse powinniśmy pisać rzadziej. To z kolei może prowadzić do przepełnienia bufora i utraty logów. Rozwiązaniem jest zwiększenie bufora Fluentd, ale wtedy wzrośnie również zużycie pamięci.
Operacja: Kolejnym problematycznym aspektem naszego rozwiązania z ClickHouse był fakt, że partycjonowanie w naszym przypadku (loghouse) realizowane jest poprzez zewnętrzne tabele połączone . Prowadzi to do tego, że przy próbkowaniu w dużych odstępach czasu wymagana jest nadmierna ilość pamięci RAM, ponieważ metatablica iteruje po wszystkich partycjach - nawet tych, które oczywiście nie zawierają niezbędnych danych. Jednak teraz to podejście można bezpiecznie uznać za przestarzałe dla obecnych wersji ClickHouse (ok ).
W rezultacie staje się jasne, że nie każdy projekt ma wystarczające zasoby, aby gromadzić logi w czasie rzeczywistym w ClickHouse (a dokładniej ich dystrybucja nie będzie właściwa). Ponadto będziesz musiał użyć akumulator, do którego powrócimy później. Opisany powyżej przypadek jest autentyczny. A w tamtym czasie nie byliśmy w stanie zaoferować niezawodnego i stabilnego rozwiązania, które odpowiadałoby klientowi i pozwalało na zbieranie logów z minimalnym opóźnieniem...
A co z Elasticsearchem?
Wiadomo, że Elasticsearch radzi sobie z dużymi obciążeniami. Spróbujmy tego w tym samym projekcie. Teraz obciążenie wygląda tak:
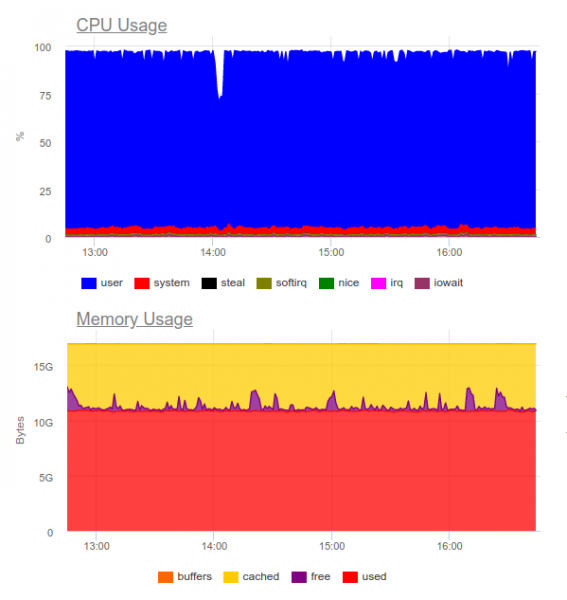
Elasticsearch był w stanie przetrawić strumień danych, jednak zapisywanie w nim takich woluminów znacznie obciąża procesor. Decyduje o tym organizacja klastra. Technicznie nie jest to problem, ale okazuje się, że tylko do obsługi systemu zbierania logów wykorzystujemy już około 8 rdzeni i mamy w systemie dodatkowy mocno obciążony komponent...
Konkluzja: tę opcję można uzasadnić, ale tylko wtedy, gdy projekt jest duży, a jego kierownictwo jest gotowe przeznaczyć znaczne zasoby na scentralizowany system rejestrowania.
Wtedy pojawia się naturalne pytanie:
Jakie logi są naprawdę potrzebne?
 Spróbujmy zmienić samo podejście: logi powinny jednocześnie pełnić funkcję informacyjną, a nie zakrywającą co zdarzenie w systemie.
Spróbujmy zmienić samo podejście: logi powinny jednocześnie pełnić funkcję informacyjną, a nie zakrywającą co zdarzenie w systemie.
Załóżmy, że mamy odnoszący sukcesy sklep internetowy. Jakie logi są ważne? Świetnym pomysłem jest zebranie jak największej ilości informacji np. z bramki płatniczej. Ale nie wszystkie logi z usługi wycinania obrazów w katalogu produktów są dla nas krytyczne: wystarczą same błędy i zaawansowany monitoring (na przykład procent 500 błędów, które generuje ten komponent).
Doszliśmy więc do wniosku, że scentralizowane rejestrowanie nie zawsze jest uzasadnione. Bardzo często klient chce zebrać wszystkie logi w jednym miejscu, choć tak naprawdę z całego logu potrzeba jedynie warunkowo 5% wiadomości kluczowych dla biznesu:
- Czasami wystarczy skonfigurować powiedzmy tylko rozmiar dziennika kontenera i modułu zbierającego błędy (na przykład Sentry).
- Do zbadania incydentów często wystarczy powiadomienie o błędzie i sam duży dziennik lokalny.
- Mieliśmy projekty, które opierały się wyłącznie na testach funkcjonalnych i systemach zbierania błędów. Deweloper nie potrzebował logów jako takich - widział wszystko, począwszy od śladów błędów.
Ilustracja z życia
Dobrym przykładem może być inna historia. Otrzymaliśmy zgłoszenie od zespołu ds. bezpieczeństwa jednego z naszych klientów, który korzystał już z komercyjnego rozwiązania opracowanego na długo przed wprowadzeniem Kubernetesa.
Należało „zaprzyjaźnić” scentralizowany system gromadzenia logów z korporacyjnym czujnikiem wykrywania problemów – QRadar. System ten może odbierać logi za pośrednictwem protokołu syslog i pobierać je z FTP. Jednak zintegrowanie go z wtyczką Remote_syslog dla Fluentd nie było od razu możliwe (jak się okazało, ). Problemy z konfiguracją QRadaru okazały się być po stronie zespołu bezpieczeństwa klienta.
W efekcie część logów o znaczeniu krytycznym dla biznesu została przesłana na serwer FTP QRadar, a część została przekierowana poprzez zdalny syslog bezpośrednio z węzłów. W tym celu nawet pisaliśmy - być może pomoże to komuś rozwiązać podobny problem... Dzięki powstałemu schematowi klient sam otrzymał i przeanalizował krytyczne logi (używając swoich ulubionych narzędzi), a nam udało się obniżyć koszt systemu logującego, oszczędzając jedynie w zeszłym miesiącu.
Inny przykład dość dobrze pokazuje, czego nie należy robić. Jeden z naszych klientów do przeróbki każdy zdarzenia pochodzące od użytkownika, wykonane w trybie multiline nieustrukturyzowane wyjście informacja w logu. Jak można się domyślić, takie dzienniki były wyjątkowo niewygodne zarówno do odczytu, jak i przechowywania.
Kryteria dzienników
Takie przykłady prowadzą do wniosku, że oprócz wyboru systemu zbierania logów trzeba jeszcze zaprojektuj także same kłody! Jakie są tutaj wymagania?
- Dzienniki muszą być w formacie do odczytu maszynowego (na przykład JSON).
- Dzienniki powinny być zwarte i umożliwiać zmianę stopnia rejestrowania w celu usunięcia ewentualnych problemów. Jednocześnie w środowiskach produkcyjnych należy uruchamiać systemy z poziomem logowania np Ostrzeżenie lub Błąd.
- Logi muszą być znormalizowane, to znaczy w obiekcie dziennika wszystkie wiersze muszą mieć ten sam typ pola.
Logi nieustrukturyzowane mogą powodować problemy z załadowaniem logów do magazynu i całkowitym zatrzymaniem ich przetwarzania. Jako ilustrację podam przykład z błędem 400, z którym wielu z pewnością spotkało się w logach Fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
Błąd oznacza, że wysyłasz do indeksu pole, którego typ jest niestabilny, z gotowym mapowaniem. Najprostszym przykładem jest pole w logu nginx ze zmienną $upstream_status. Może zawierać liczbę lub ciąg znaków. Na przykład:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
Z dzienników wynika, że serwer 10.100.0.10 odpowiedział błędem 404 i żądanie zostało wysłane do innego magazynu zawartości. W rezultacie wartość w dziennikach wyglądała następująco:
"upstream_response_time": "0.001, 0.007"
Sytuacja ta jest tak powszechna, że zasługuje nawet na osobną .
A co z niezawodnością?
Są chwile, kiedy wszystkie dzienniki bez wyjątku są niezbędne. W związku z tym typowe schematy gromadzenia logów dla K8 zaproponowane/omówione powyżej stwarzają problemy.
Na przykład fluentd nie może zbierać logów z krótkotrwałych kontenerów. W jednym z naszych projektów kontener migracji bazy danych żył krócej niż 4 sekundy, po czym został usunięty – zgodnie z odpowiednią adnotacją:
"helm.sh/hook-delete-policy": hook-succeeded
Z tego powodu dziennik wykonania migracji nie został uwzględniony w magazynie. Polityka może w tym przypadku pomóc. before-hook-creation.
Innym przykładem jest rotacja logów Dockera. Załóżmy, że istnieje aplikacja, która aktywnie zapisuje dane w dziennikach. W normalnych warunkach udaje nam się przetworzyć wszystkie logi, jednak gdy tylko pojawi się problem - na przykład opisany powyżej z nieprawidłowym formatem - przetwarzanie zostaje zatrzymane, a Docker obraca plik. W rezultacie dzienniki o znaczeniu krytycznym dla firmy mogą zostać utracone.
Właśnie dlatego ważne jest oddzielenie strumieni dziennika, osadzając wysyłanie najcenniejszych bezpośrednio do aplikacji, aby zapewnić ich bezpieczeństwo. Ponadto tworzenie niektórych nie byłoby zbyteczne „akumulator” kłód, które mogą przetrwać krótką niedostępność pamięci, jednocześnie zapisując krytyczne wiadomości.
Na koniec nie możemy o tym zapominać Ważne jest, aby właściwie monitorować każdy podsystem. W przeciwnym razie łatwo wpaść w sytuację, w której biegły jest w stanie CrashLoopBackOff i nic nie wysyła, a to grozi utratą ważnych informacji.
odkrycia
W tym artykule nie przyglądamy się rozwiązaniom SaaS, takim jak Datadog. Wiele z opisanych tutaj problemów zostało już w ten czy inny sposób rozwiązanych przez komercyjne firmy specjalizujące się w zbieraniu logów, jednak nie każdy może z różnych powodów korzystać z SaaS (główne to koszt i zgodność z 152-FZ).
Scentralizowane gromadzenie logów na pierwszy rzut oka wydaje się prostym zadaniem, ale wcale takie nie jest. Ważne jest, aby pamiętać, że:
- Tylko krytyczne komponenty wymagają szczegółowego logowania, natomiast monitorowanie i zbieranie błędów można skonfigurować dla innych systemów.
- Kłody w produkcji powinny być minimalne, aby nie dodawać niepotrzebnego obciążenia.
- Dzienniki muszą nadawać się do odczytu maszynowego, znormalizowane i mieć ściśle określony format.
- Logi naprawdę krytyczne należy przesyłać w osobnym strumieniu, który należy oddzielić od głównych.
- Warto rozważyć akumulator kłód, który może uchronić Cię przed impulsami dużego obciążenia i sprawić, że obciążenie magazynu stanie się bardziej równomierne.

Te proste zasady, zastosowane wszędzie, pozwoliłyby na działanie opisanych powyżej obwodów - nawet jeśli brakuje w nich ważnych elementów (akumulatora). Jeśli nie zastosujesz się do takich zasad, zadanie z łatwością zaprowadzi Ciebie i infrastrukturę do innego, mocno obciążonego (a jednocześnie nieefektywnego) elementu systemu.
PS
Przeczytaj także na naszym blogu:
- «";
- «";
- «".
Źródło: www.habr.com
