

Hej Habra! Zapraszamy Inżynierów Danych i specjalistów Machine Learning na bezpłatną lekcję demonstracyjną . Publikujemy także artykuł Luca Monno – Head of Financial Analytics w CDP SpA.
Jedną z najbardziej przydatnych i prostych metod uczenia maszynowego jest uczenie zespołowe. Ensemble Learning to metoda stojąca za XGBoost, Bagging, Random Forest i wieloma innymi algorytmami.
Istnieje wiele świetnych artykułów na temat kierunku Data Science, ale ja wybrałem dwie historie ( и ) co mi się najbardziej podobało. Po co więc pisać kolejny artykuł o EL? Ponieważ chcę ci to pokazać jak to działa na prostym przykładzie, co uświadomiło mi, że nie ma tu żadnej magii.
Kiedy po raz pierwszy zobaczyłem EL w akcji (pracującego z kilkoma bardzo prostymi modelami regresji) nie mogłem uwierzyć własnym oczom i do dziś pamiętam profesora, który nauczył mnie tej metody.
Miałem dwa różne modele (dwa słabe algorytmy szkoleniowe) z metrykami poza próbką R² wynosi odpowiednio 0,90 i 0,93. Zanim spojrzałem na wynik, pomyślałem, że otrzymam R² gdzieś pomiędzy dwiema pierwotnymi wartościami. Innymi słowy, wierzyłem, że EL można zastosować, aby model działał nie tak słabo, jak najgorszy model, ale nie tak dobrze, jak mógłby działać najlepszy model.
Ku mojemu wielkiemu zaskoczeniu, zwykłe uśrednienie przewidywań dało R² wynoszące 0,95.
Na początku zacząłem szukać błędu, ale potem pomyślałem, że może kryje się tu jakaś magia!
Co to jest nauka zespołowa
Dzięki EL możesz połączyć przewidywania dwóch lub więcej modeli, aby stworzyć solidniejszy i wydajniejszy model. Istnieje wiele metod pracy z zespołami modelowymi. Tutaj poruszę dwa najbardziej przydatne, aby dać przegląd.
Z regresja możliwe jest uśrednienie wydajności dostępnych modeli.
Z Klasyfikacja Możesz dać modelom możliwość wyboru etykiet. Najczęściej wybierana etykieta będzie tą, którą wybierze nowy model.
Dlaczego EL działa lepiej
Głównym powodem, dla którego EL działa lepiej, jest to, że każda prognoza zawiera błąd (wiemy to z teorii prawdopodobieństwa), połączenie dwóch prognoz może pomóc zmniejszyć błąd, a tym samym poprawić metryki wydajności (RMSE, R² itp.).d.).
Poniższy diagram pokazuje, jak dwa słabe algorytmy działają na zbiorze danych. Pierwszy algorytm ma nachylenie większe niż potrzebne, podczas gdy drugi ma prawie zerowe nachylenie (prawdopodobnie z powodu nadmiernej regularyzacji). Ale ensemble wykazuje znacznie lepsze rezultaty.
Jeśli spojrzeć na wskaźnik R², to dla pierwszego i drugiego algorytmu uczącego będzie on wynosił odpowiednio -0.01¹, 0.22, natomiast dla zespołu będzie równy 0.73.
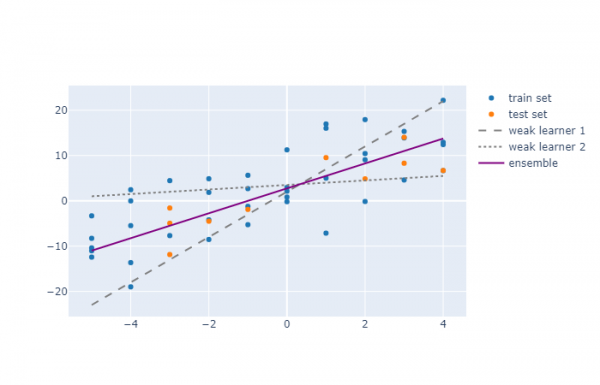
Istnieje wiele powodów, dla których algorytm może być złym modelem nawet w tak podstawowym przykładzie: może zdecydowałeś się zastosować regularyzację, aby uniknąć nadmiernego dopasowania, albo zdecydowałeś się nie wykluczać pewnych anomalii, a może zastosowałeś regresję wielomianową i popełniłeś błąd stopień (przykładowo użyliśmy wielomianu drugiego stopnia, a dane testowe pokazują wyraźną asymetrię, dla której lepiej pasowałby trzeci stopień).
Kiedy EL działa lepiej
Przyjrzyjmy się dwóm algorytmom uczącym pracującym z tymi samymi danymi.
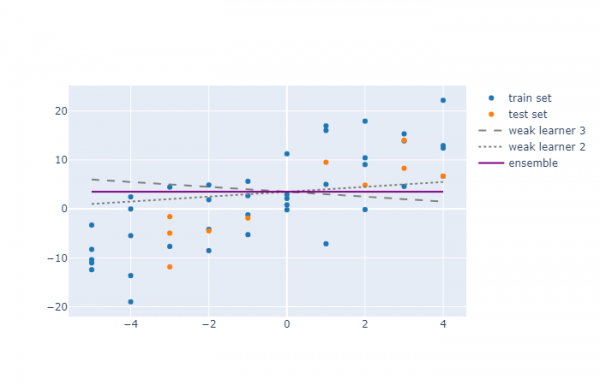
Tutaj widać, że połączenie obu modeli nie poprawiło znacząco wydajności. Początkowo dla obu algorytmów uczących wskaźniki R² wynosiły odpowiednio -0,37 i 0,22, a dla zespołu okazały się wynosić -0,04. Oznacza to, że model EL otrzymał średnią wartość wskaźników.
Istnieje jednak duża różnica między tymi dwoma przykładami: w pierwszym przypadku błędy modelu były skorelowane ujemnie, a w drugim dodatnio (współczynniki trzech modeli nie zostały oszacowane, ale zostały po prostu wybrane przez autor jako przykład).
Dlatego też uczenie zespołowe można wykorzystać do poprawy równowagi odchyleń/wariancji w każdym przypadku, ale kiedy Błędy modelu nie są skorelowane dodatnio, użycie EL może prowadzić do poprawy wydajności.
Modele jednorodne i heterogeniczne
Bardzo często EL stosuje się na modelach jednorodnych (jak w tym przykładzie lub w lesie losowym), ale tak naprawdę można łączyć różne modele (regresja liniowa + sieć neuronowa + XGBoost) z różnymi zestawami zmiennych objaśniających. Prawdopodobnie spowoduje to nieskorelowane błędy i poprawę wydajności.
Porównanie z dywersyfikacją portfela
EL działa podobnie do dywersyfikacji w teorii portfela, ale tym lepiej dla nas.
Dywersyfikując, próbujesz zmniejszyć wariancję swoich wyników, inwestując w nieskorelowane akcje. Dobrze zdywersyfikowany portfel akcji będzie zachowywał się lepiej niż najgorsze pojedyncze akcje, ale nigdy lepiej niż najlepsze.
Cytując Warrena Buffetta:
„Dywersyfikacja jest obroną przed ignorancją; dla kogoś, kto nie wie, co robi, [dywersyfikacja] ma bardzo mało sensu”.
W uczeniu maszynowym EL pomaga zmniejszyć wariancję modelu, ale może skutkować powstaniem modelu o ogólnej wydajności lepszej niż najlepszy oryginalny model.
Zsumować
Łączenie wielu modeli w jeden jest stosunkowo prostą techniką, która może prowadzić do rozwiązania problemu błędu wariancji i poprawy wydajności.
Jeśli masz dwa lub więcej modeli, które dobrze się sprawdzają, nie wybieraj między nimi: używaj ich wszystkich (ale z zachowaniem ostrożności)!
Jesteś zainteresowany rozwojem w tym kierunku? Zapisz się na bezpłatną lekcję demonstracyjną i uczestniczyć — Inżynier uczenia maszynowego w Grupie Mail.ru.
Źródło: www.habr.com
