

Chciałbym podzielić się z Wami moim pierwszym udanym doświadczeniem w przywracaniu pełnej funkcjonalności bazy danych Postgres. Z Postgres DBMS zapoznałem się pół roku temu, wcześniej nie miałem żadnego doświadczenia w administrowaniu bazami danych.

Pracuję jako inżynier semi-DevOps w dużej firmie IT. Nasza firma tworzy oprogramowanie dla usług o dużym obciążeniu, a ja jestem odpowiedzialny za wydajność, konserwację i wdrożenie. Dostałem standardowe zadanie: zaktualizować aplikację na jednym serwerze. Aplikacja jest napisana w Django, podczas aktualizacji wykonywane są migracje (zmiany w strukturze bazy danych), a przed tym procesem na wszelki wypadek wykonujemy pełny zrzut bazy danych poprzez standardowy program pg_dump.
Wystąpił nieoczekiwany błąd podczas wykonywania zrzutu (Postgres wersja 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly błąd „nieprawidłowa strona w bloku” mówi o problemach na poziomie systemu plików, co jest bardzo złe. Na różnych forach sugerowano, żeby tak zrobić PEŁNA PRÓŻNIA z opcją zero_damaged_pages by rozwiązać ten problem. Cóż, spróbujmy…
Przygotowanie do powrotu do zdrowia
UWAGA Przed jakąkolwiek próbą przywrócenia bazy danych wykonaj kopię zapasową Postgres. Jeśli masz maszynę wirtualną, zatrzymaj bazę danych i wykonaj migawkę. Jeżeli wykonanie migawki nie jest możliwe, zatrzymaj bazę danych i skopiuj zawartość katalogu Postgres (łącznie z plikami wal) w bezpieczne miejsce. W naszej działalności najważniejsze jest, aby nie pogarszać sytuacji. Czytać .
Ponieważ baza danych ogólnie mi działała, ograniczyłem się do zwykłego zrzutu bazy danych, ale wykluczyłem tabelę z uszkodzonymi danymi (opcja -T, --exclude-table=TABELA w pg_dump).
Serwer był fizyczny, nie dało się zrobić migawki. Kopia zapasowa została usunięta, przejdźmy dalej.
Kontrola systemu plików
Przed przystąpieniem do przywracania bazy danych musimy upewnić się, że z samym systemem plików wszystko jest w porządku. A w razie błędów popraw je, bo inaczej możesz tylko pogorszyć sytuację.
W moim przypadku zamontowany był system plików z bazą danych "/srv" a typem był ext4.
Zatrzymywanie bazy danych: systemctl stop postgresql@9.5-main.service i sprawdź, czy system plików nie jest przez nikogo używany i czy można go odmontować za pomocą polecenia lsof:
lsof +D /srv
Musiałem także zatrzymać bazę danych Redis, ponieważ ona również korzystała "/srv". Następnie odmontowałem / srv (ilość).
System plików został sprawdzony za pomocą narzędzia e2fsck z przełącznikiem -f (Wymuś sprawdzanie, nawet jeśli system plików jest oznaczony jako czysty):
Następnie skorzystaj z narzędzia wysypisko2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep sprawdzony) możesz sprawdzić, czy kontrola została faktycznie przeprowadzona:

e2fsck mówi, że nie znaleziono żadnych problemów na poziomie systemu plików ext4, co oznacza, że możesz kontynuować próbę przywrócenia bazy danych, a raczej wrócić do próżnia pełna (oczywiście musisz ponownie zamontować system plików i uruchomić bazę danych).
Jeżeli posiadasz serwer fizyczny koniecznie sprawdź stan dysków (poprzez smartctl -a /dev/XXX) lub kontroler RAID, aby upewnić się, że problem nie leży po stronie sprzętu. W moim przypadku RAID okazał się „sprzętowy”, więc poprosiłem lokalnego administratora o sprawdzenie stanu RAID (serwer był kilkaset kilometrów ode mnie). Stwierdził, że nie ma żadnych błędów, co oznacza, że na pewno możemy przystąpić do renowacji.
Próba 1: zero_damaged_pages
Z bazą danych łączymy się poprzez psql za pomocą konta posiadającego uprawnienia superużytkownika. Potrzebujemy superużytkownika, ponieważ... opcja zero_damaged_pages tylko on może się zmienić. W moim przypadku jest to postgres:
psql -h 127.0.0.1 -U postgres -s [nazwa_bazy danych]
Opcja zero_damaged_pages potrzebne, aby zignorować błędy odczytu (ze strony postgrespro):
Gdy PostgreSQL wykryje uszkodzony nagłówek strony, zazwyczaj zgłasza błąd i przerywa bieżącą transakcję. Jeśli włączona jest opcja zero_damaged_pages, system zamiast tego generuje ostrzeżenie, wyzerowuje uszkodzoną stronę z pamięci i kontynuuje przetwarzanie. To zachowanie niszczy dane, a mianowicie wszystkie wiersze na uszkodzonej stronie.
Włączamy opcję i staramy się wykonać pełne odkurzanie tabel:
VACUUM FULL VERBOSE 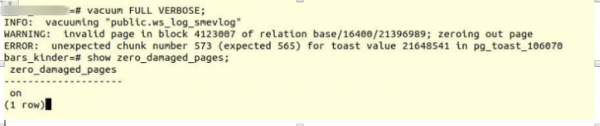
Niestety pech.
Napotkaliśmy podobny błąd:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070– mechanizm przechowywania „długich danych” w Poetgresie, jeśli nie mieszczą się one na jednej stronie (domyślnie 8kb).
Próba 2: ponowne indeksowanie
Pierwsza rada Google nie pomogła. Po kilku minutach poszukiwań znalazłam drugą wskazówkę – do zrobienia reindeksować uszkodzony stół. Widziałem tę radę w wielu miejscach, ale nie wzbudziła ona zaufania. Zindeksujmy ponownie:
reindex table ws_log_smevlog 
reindeksować ukończone bez problemów.
Jednak to nie pomogło, PRÓŻNIA PEŁNA uległ awarii z podobnym błędem. Jako że jestem przyzwyczajony do niepowodzeń, zacząłem dalej szukać porad w Internecie i trafiłem na dość ciekawe .
Próba 3: WYBIERZ, OGRANICZ, PRZESUŃ
W powyższym artykule zasugerowano przejrzenie tabeli wiersz po wierszu i usunięcie problematycznych danych. Najpierw musieliśmy przyjrzeć się wszystkim liniom:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneW moim przypadku tabela zawierała 1 628 991 linie! Trzeba było o to dobrze dbać , ale to już temat na osobną dyskusję. Była sobota, uruchomiłem to polecenie w tmux i poszedłem spać:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneRano postanowiłem sprawdzić, jak się sprawy mają. Ku mojemu zaskoczeniu odkryłem, że po 20 godzinach zeskanowano tylko 2% danych! Nie chciałem czekać 50 dni. Kolejna kompletna porażka.
Ale nie poddałem się. Zastanawiałem się, dlaczego skanowanie trwało tak długo. Z dokumentacji (ponownie na postgrespro) dowiedziałem się:
OFFSET określa pominięcie określonej liczby wierszy przed rozpoczęciem wyprowadzania wierszy.
Jeśli określono zarówno OFFSET, jak i LIMIT, system najpierw pominie wiersze OFFSET, a następnie rozpocznie zliczanie wierszy dla ograniczenia LIMIT.Podczas korzystania z LIMIT ważne jest również użycie klauzuli ORDER BY, aby wiersze wyników były zwracane w określonej kolejności. W przeciwnym razie zwrócone zostaną nieprzewidywalne podzbiory wierszy.
Oczywiście powyższe polecenie było błędne: po pierwsze, nie było Zamów przez, wynik może być błędny. Po drugie, Postgres musiał najpierw skanować i pomijać wiersze OFFSET, a także zwiększać OFFSET produktywność spadłaby jeszcze bardziej.
Próba 4: zrób zrzut w formie tekstowej
Wtedy przyszedł mi do głowy pozornie genialny pomysł: zrób zrzut w formie tekstowej i przeanalizuj ostatnią nagraną linijkę.
Ale najpierw przyjrzyjmy się strukturze tabeli. ws_log_smevlog:
W naszym przypadku mamy kolumnę "ID", który zawierał unikalny identyfikator (licznik) wiersza. Plan był taki:
- Zaczynamy robić zrzut w formie tekstowej (w postaci poleceń sql)
- W pewnym momencie zrzut zostanie przerwany z powodu błędu, ale plik tekstowy nadal zostanie zapisany na dysku
- Patrzymy na koniec pliku tekstowego i w ten sposób znajdujemy identyfikator (id) ostatniej linii, która została pomyślnie usunięta
Zacząłem robić zrzut w formie tekstowej:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpZrzut, zgodnie z oczekiwaniami, został przerwany z powodu tego samego błędu:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 Dalej przez ogon Spojrzałem na koniec zrzutu (ogon -5 ./my_dump.dump) odkrył, że zrzut został przerwany na linii o identyfikatorze 186 525. „Więc problem dotyczy linii o identyfikatorze 186 526, jest uszkodzony i należy go usunąć!” - Myślałem. Ale wykonanie zapytania do bazy danych:
«wybierz * z ws_log_smevlog, gdzie identyfikator = 186529„Okazało się, że z tą linią wszystko było w porządku... Wiersze o indeksach 186 530 - 186 540 również działały bez problemów. Kolejny „genialny pomysł” nie powiódł się. Później zrozumiałem, dlaczego tak się stało: podczas usuwania i zmiany danych z tabeli nie są one fizycznie usuwane, ale są oznaczane jako „martwe krotki”, po czym pojawia się autopróżnia i oznacza te linie jako usunięte i pozwala na ich ponowne wykorzystanie. Aby zrozumieć, jeśli dane w tabeli ulegną zmianie i włączona jest automatyczna próżnia, wówczas nie są one przechowywane sekwencyjnie.
Próba 5: WYBIERZ, OD, GDZIE id=
Porażki czynią nas silniejszymi. Nigdy nie należy się poddawać, trzeba iść do końca i wierzyć w siebie i swoje możliwości. Postanowiłem więc wypróbować inną opcję: po prostu przejrzyj jeden po drugim wszystkie rekordy w bazie danych. Znając strukturę mojej tabeli (patrz wyżej), mamy pole identyfikatora, które jest unikalne (klucz podstawowy). W tabeli mamy 1 628 991 wierszy id są w porządku, co oznacza, że możemy je przeglądać jeden po drugim:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneJeśli ktoś nie rozumie, polecenie działa w następujący sposób: skanuje tabelę wiersz po wierszu i wysyła standardowe wyjście do / dev / null, ale jeśli wykonanie polecenia SELECT nie powiedzie się, to wypisywany jest tekst błędu (do konsoli wysyłane jest stderr) i drukowana jest linia zawierająca błąd (dzięki ||, co oznacza, że wybór miał problemy (kod powrotu polecenia nie jest 0)).
Miałem szczęście, miałem indeksy utworzone na polu id:

Oznacza to, że znalezienie linii o żądanym identyfikatorze nie powinno zająć dużo czasu. Teoretycznie powinno działać. Cóż, uruchommy polecenie tmux i chodźmy do łóżka.
Do rana odkryłem, że obejrzano około 90 000 wpisów, co stanowi nieco ponad 5%. Doskonały wynik w porównaniu z poprzednią metodą (2%)! Ale nie chciałem czekać 20 dni...
Próba 6: WYBIERZ, OD, GDZIE id >= i id <
Klient miał doskonały serwer dedykowany dla bazy danych: dwuprocesorowy Intel Xeon E5 2697 v2, w naszej lokalizacji było aż 48 wątków! Obciążenie serwera było średnie, bez problemu udało nam się pobrać około 20 wątków. RAMu było też wystarczająco dużo: aż 384 gigabajty!
Dlatego polecenie należało zrównoleglić:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneTutaj udało się napisać piękny i elegancki skrypt, ale wybrałem najszybszą metodę zrównoleglenia: ręcznie podziel zakres 0-1628991 na przedziały po 100 000 rekordów i osobno uruchom 16 poleceń w postaci:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneAle to nie wszystko. Teoretycznie połączenie z bazą danych również zajmuje trochę czasu i zasobów systemowych. Podłączenie 1 628 991 nie było zbyt mądre, zgodzisz się. Dlatego pobierzmy 1000 wierszy zamiast połączenia jeden na jedno. W rezultacie zespół zmienił się w następujący sposób:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; doneOtwórz 16 okien w sesji tmux i uruchom polecenia:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Dzień później otrzymałam pierwsze wyniki! Mianowicie (wartości XXX i ZZZ nie są już zachowywane):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000Oznacza to, że trzy linie zawierają błąd. Identyfikatory pierwszego i drugiego rekordu problemu mieściły się w przedziale od 829 000 do 830 000, identyfikator trzeciego zawierał się w przedziale od 146 000 do 147 000. Następnie musieliśmy po prostu znaleźć dokładną wartość identyfikatora rekordów problemów. W tym celu przeglądamy naszą ofertę z problematycznymi rekordami w kroku 1 i identyfikujemy identyfikator:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Szczęśliwe zakończenie
Znaleźliśmy problematyczne linie. Wchodzimy do bazy danych przez psql i próbujemy je usunąć:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1Ku mojemu zaskoczeniu wpisy zostały usunięte bez problemu nawet bez takiej opcji zero_damaged_pages.
Potem połączyłem się z bazą danych, tak PRÓŻNIA PEŁNA (Myślę, że nie było to konieczne) i w końcu pomyślnie usunąłem kopię zapasową za pomocą pg_dump. Zrzut został pobrany bez żadnych błędów! Problem został rozwiązany w tak głupi sposób. Radość nie miała granic, po tylu niepowodzeniach udało się znaleźć rozwiązanie!
Podziękowania i wnioski
Tak wyglądało moje pierwsze doświadczenie z przywracaniem prawdziwej bazy danych Postgres. Zapamiętam to przeżycie na długo.
Na koniec chciałbym podziękować firmie PostgresPro za przetłumaczenie dokumentacji na język rosyjski i za , co bardzo pomogło podczas analizy problemu.
Źródło: www.habr.com
