

1. Dane wstępne
Czyszczenie danych jest jednym z wyzwań stojących przed zadaniami analizy danych. Materiał ten odzwierciedlał rozwój i rozwiązania, które powstały w wyniku rozwiązania praktycznego problemu analizy bazy danych w kształtowaniu wartości katastralnej. Źródła tutaj .
Uwzględniono plik „Model porównawczy total.ods” zawarty w „Załączniku B. Wyniki wyznaczania KS 5. Informacje o sposobie ustalania wartości katastralnej 5.1 Podejście porównawcze”.
Tabela 1. Wskaźniki statystyczne zbioru danych w pliku „Model porównawczy total.ods”
Całkowita liczba pól, szt. — 44
Łączna liczba rekordów, szt. — 365 490
Całkowita liczba znaków, szt. — 101 714 693
Średnia liczba znaków w rekordzie, szt. — 278,297
Odchylenie standardowe znaków w rekordzie, szt. — 15,510
Minimalna ilość znaków we wpisie, szt. — 198
Maksymalna ilość znaków we wpisie, szt. — 363
2. Część wprowadzająca. Podstawowe standardy
Analizując określoną bazę danych, postawiono zadanie określenia wymagań co do stopnia oczyszczenia, ponieważ – jak dla wszystkich jest jasne – określona baza danych stwarza dla użytkowników konsekwencje prawne i ekonomiczne. W trakcie prac okazało się, że nie ma określonych wymagań co do stopnia oczyszczenia dużych zbiorów danych. Analizując normy prawne w tym zakresie doszedłem do wniosku, że wszystkie one powstają z możliwości. Oznacza to, że pojawiło się określone zadanie, dla zadania zestawiane są źródła informacji, następnie tworzony jest zbiór danych i na podstawie utworzonego zbioru danych narzędzia do rozwiązania problemu. Powstałe rozwiązania stanowią punkty odniesienia przy wyborze alternatyw. Przedstawiłem to na rysunku 1.
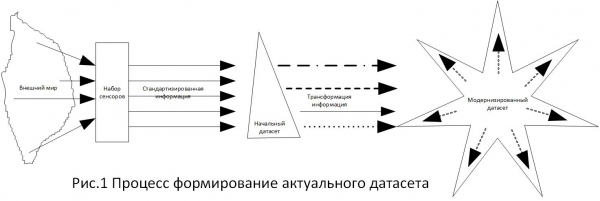
Ponieważ w kwestiach ustalania jakichkolwiek standardów lepiej jest opierać się na sprawdzonych technologiach, wybrałem wymagania określone w , ponieważ uznałem ten dokument za najbardziej wyczerpujący w tej kwestii. W szczególności w tym dokumencie znajduje się sekcja mówiąca: „Należy zauważyć, że wymagania dotyczące integralności danych mają zastosowanie w równym stopniu do danych ręcznych (papierowych), jak i elektronicznych”. (tłumaczenie: „...wymogi dotyczące integralności danych mają zastosowanie zarówno do danych ręcznych (papierowych), jak i elektronicznych”). Sformułowanie to dość specyficznie wiąże się z pojęciem „dowodu pisemnego” w przepisach art. 71 kpc, art. 70 CAS, art. 75 kpc, „w formie pisemnej” art. 84 Kodeks postępowania cywilnego.
Rycina 2 przedstawia schemat kształtowania się podejść do typów informacji w orzecznictwie.
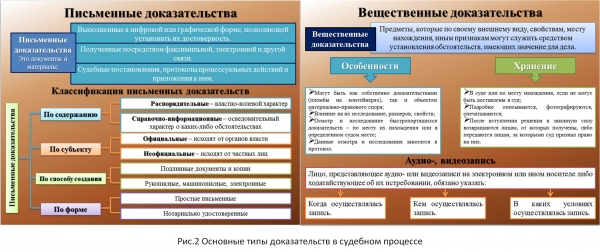
Ryż. 2. Źródło .
Rysunek 3 przedstawia mechanizm z rysunku 1, dla zadań z powyższego „Poradnika”. Dokonując porównania, łatwo zauważyć, że podejścia stosowane przy spełnianiu wymagań integralności informacji we współczesnych standardach systemów informatycznych są znacznie ograniczone w porównaniu z prawnym pojęciem informacji.
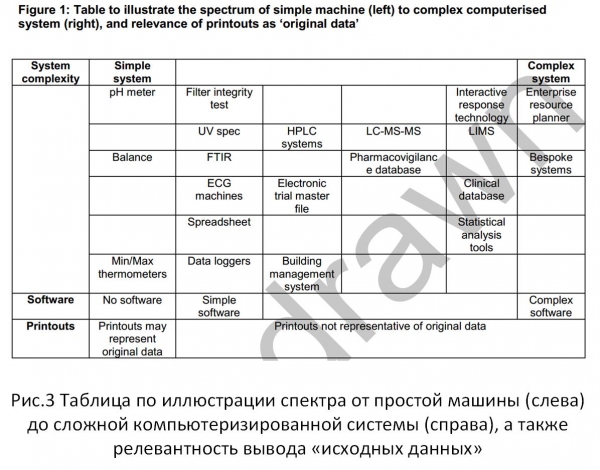
Ris.3
We wskazanym dokumencie (Wytyczne) połączenie z częścią techniczną, możliwości przetwarzania i przechowywania danych dobrze potwierdza cytat z rozdziału 18.2. Relacyjna baza danych: „Ta struktura plików jest z natury bezpieczniejsza, ponieważ dane są przechowywane w dużym formacie pliku, który zachowuje relację między danymi a metadanymi”.
Właściwie w tym podejściu – biorąc pod uwagę istniejące możliwości techniczne – nie ma nic odbiegającego od normy i samo w sobie jest to proces naturalny, gdyż rozwijanie koncepcji wynika z najbardziej badanej działalności – projektowania baz danych. Ale z drugiej strony pojawiają się normy prawne, które nie przewidują rabatów od możliwości technicznych istniejących systemów, na przykład: .

Ryż. 4. Lejek możliwości technicznych ().
W tych aspektach staje się jasne, że pierwotny zbiór danych (ryc. 1) będzie musiał po pierwsze zostać zapisany, a po drugie stanowić podstawę do wydobycia z niego dodatkowych informacji. Cóż, dla przykładu: kamery rejestrujące przepisy ruchu drogowego są wszechobecne, systemy przetwarzania informacji eliminują łamiących przepisy, ale inne informacje mogą być przekazywane także innym konsumentom, np. w ramach marketingowego monitoringu struktury napływu klientów do centrum handlowego. I to jest źródło dodatkowej wartości dodanej podczas korzystania z BigDat. Całkiem możliwe, że gromadzone obecnie zbiory danych będą miały gdzieś w przyszłości wartość według mechanizmu zbliżonego do obecnej wartości rzadkich wydań 1700. W końcu tymczasowe zbiory danych są unikalne i jest mało prawdopodobne, że zostaną powtórzone w przyszłości.
3. Część wprowadzająca. Kryteria oceny
W procesie przetwarzania opracowano następującą klasyfikację błędów.
1. Klasa błędu (na podstawie GOST R 8.736-2011): a) błędy systematyczne; b) błędy losowe; c) błąd.
2. Przez wielokrotność: a) zniekształcenie mono; b) wielokrotne zniekształcenia.
3. Według krytyczności skutków: a) krytycznych; b) niekrytyczne.
4. Według źródła wystąpienia:
A) Techniczne – błędy powstałe podczas eksploatacji urządzenia. Dość istotny błąd w przypadku systemów IoT, systemów mających znaczny wpływ na jakość komunikacji, sprzęt (hardware).
B) Błędy operatora – błędy o szerokim zakresie, od literówek operatora podczas wprowadzania danych po błędy w specyfikacjach technicznych dotyczących projektowania baz danych.
C) Błędy użytkownika – są tu błędy użytkownika w całym zakresie od „zapomniałem przełączyć układ” po pomylenie liczników ze stopami.
5. Podzielone na osobną klasę:
a) „zadanie separatora”, czyli spacji i „:” (w naszym przypadku) w momencie jego zduplikowania;
b) słowa zapisane razem;
c) brak spacji po znakach serwisowych
d) symetrycznie wielokrotnych symboli: (), „”, „…”.
Podsumowując, wraz z usystematyzowaniem błędów baz danych przedstawionym na rysunku 5, powstaje dość efektywny układ współrzędnych do wyszukiwania błędów i opracowania algorytmu czyszczenia danych dla tego przykładu.
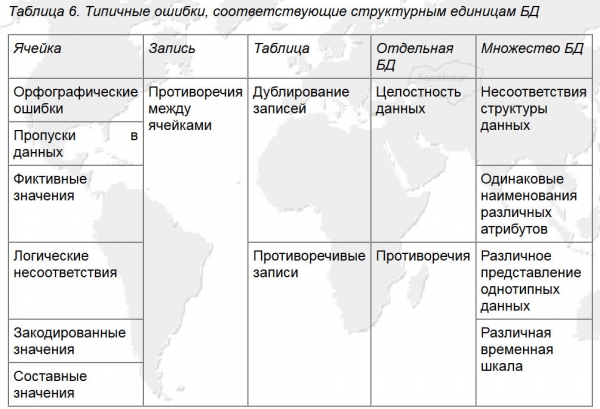
Ryż. 5. Typowe błędy odpowiadające jednostkom strukturalnym bazy danych (Źródło: ).
Dokładność, integralność domeny, typ danych, spójność, nadmiarowość, kompletność, powielanie, zgodność z regułami biznesowymi, określoność strukturalna, anomalia danych, przejrzystość, aktualność, zgodność z zasadami integralności danych. (Strona 334. Podstawy hurtowni danych dla specjalistów IT / Paulraj Ponniah. — wyd. 2)
W nawiasach podano angielskie sformułowanie i rosyjskie tłumaczenie maszynowe.
Dokładność. Wartość przechowywana w systemie dla elementu danych jest właściwą wartością dla tego wystąpienia elementu danych. Jeśli masz nazwę klienta i adres zapisane w rejestrze, wówczas adres jest poprawnym adresem dla klienta o tej nazwie. Jeśli w rekordzie zamówienia o numerze 1000 znajdziesz zamówioną ilość wynoszącą 12345678 jednostek, będzie to dokładna ilość dla tego zamówienia.
[Dokładność. Wartość elementu danych przechowywana w systemie jest poprawną wartością dla tego wystąpienia elementu danych. Jeśli masz nazwę i adres klienta zapisane w rejestrze, wówczas adres jest prawidłowym adresem dla klienta o tej nazwie. Jeśli w rekordzie zamówienia o numerze 1000 znajdziesz zamówioną ilość wynoszącą 12345678 jednostek, wówczas ta ilość jest dokładną ilością dla tego zamówienia.]
Integralność domeny. Wartość danych atrybutu mieści się w zakresie dopuszczalnych, zdefiniowanych wartości. Typowym przykładem są dopuszczalne wartości „mężczyzna” i „kobieta” dla elementu danych płci.
[Integralność domeny. Wartość danych atrybutu mieści się w zakresie prawidłowych, zdefiniowanych wartości. Ogólnym przykładem są prawidłowe wartości „male” i „female” dla elementu danych płci.]
Typ danych. Wartość atrybutu danych jest w rzeczywistości przechowywana jako typ danych zdefiniowany dla tego atrybutu. Jeśli typ danych pola nazwy sklepu jest zdefiniowany jako „tekst”, wszystkie wystąpienia tego pola zawierają nazwę sklepu wyświetlaną w formacie tekstowym, a nie kody numeryczne.
[Typ danych. Wartość atrybutu danych jest faktycznie przechowywana jako typ danych zdefiniowany dla tego atrybutu. Jeśli typ danych pola nazwy sklepu jest zdefiniowany jako „tekst”, wszystkie wystąpienia tego pola zawierają nazwę sklepu wyświetlaną w formacie tekstowym, a nie w postaci kodów numerycznych.]
Konsystencja. Forma i zawartość pola danych jest taka sama w wielu systemach źródłowych. Jeśli kod produktu dla produktu ABC w jednym systemie wynosi 1234, to kod tego produktu będzie wynosił 1234 w każdym systemie źródłowym.
[Konsystencja. Forma i zawartość pola danych jest taka sama w różnych systemach źródłowych. Jeśli kod produktu ABC w jednym systemie to 1234, wówczas kod tego produktu to 1234 w każdym systemie źródłowym.]
Nadmierność. Te same dane nie mogą być przechowywane w więcej niż jednym miejscu systemu. Jeśli ze względów wydajnościowych element danych jest celowo przechowywany w więcej niż jednym miejscu systemu, należy wyraźnie zidentyfikować i zweryfikować nadmiarowość.
[Nadmierność. Nie należy przechowywać tych samych danych w więcej niż jednym miejscu systemu. Jeśli ze względu na wydajność element danych jest celowo przechowywany w wielu lokalizacjach w systemie, należy jasno zdefiniować i zweryfikować nadmiarowość.]
Kompletność. W systemie nie ma brakujących wartości dla danego atrybutu. Na przykład w pliku klienta musi znajdować się prawidłowa wartość pola „stan” dla każdego klienta. W pliku szczegółów zamówienia każdy zapis dotyczący szczegółów zamówienia musi być całkowicie wypełniony.
[Kompletność. W systemie nie ma brakujących wartości dla tego atrybutu. Na przykład plik klienta musi mieć prawidłową wartość pola „status” dla każdego klienta. W pliku szczegółów zamówienia każdy zapis dotyczący szczegółów zamówienia musi być całkowicie wypełniony.]
Powielanie. Całkowicie rozwiązano problem duplikacji rekordów w systemie. Jeżeli wiadomo, że w pliku produktu znajdują się zduplikowane rekordy, wówczas identyfikowane są wszystkie zduplikowane rekordy dla każdego produktu i tworzone jest powiązanie.
[Duplikować. Całkowicie wyeliminowano powielanie zapisów w systemie. Jeśli wiadomo, że plik produktu zawiera zduplikowane wpisy, wówczas identyfikowane są wszystkie zduplikowane wpisy dla każdego produktu i tworzone jest odniesienie.]
Zgodność z zasadami biznesowymi. Wartości każdego elementu danych są zgodne z określonymi regułami biznesowymi. W systemie aukcyjnym cena młotkowa lub sprzedażowa nie może być niższa od ceny wywoławczej. W systemie kredytów bankowych saldo kredytu musi być zawsze dodatnie lub zerowe.
[Przestrzeganie zasad biznesowych. Wartości każdego elementu danych są zgodne z ustalonymi regułami biznesowymi. W systemie aukcyjnym cena młotkowa lub sprzedażowa nie może być niższa od ceny wywoławczej. W bankowym systemie kredytowym saldo kredytu musi być zawsze dodatnie lub zerowe.]
Definitywność strukturalna. Wszędzie tam, gdzie element danych można w naturalny sposób podzielić na pojedyncze komponenty, element ten musi zawierać dobrze zdefiniowaną strukturę. Na przykład imię danej osoby w naturalny sposób dzieli się na imię, inicjał drugiego imienia i nazwisko. Wartości imion osób muszą być przechowywane jako imię, inicjał drugiego imienia i nazwisko. Ta cecha jakości danych upraszcza egzekwowanie standardów i redukuje brakujące wartości.
[Pewność strukturalna. Jeżeli element danych można w naturalny sposób podzielić na pojedyncze komponenty, element ten musi zawierać dobrze zdefiniowaną strukturę. Na przykład imię osoby jest naturalnie podzielone na imię, inicjał drugiego imienia i nazwisko. Wartości dla poszczególnych imion należy przechowywać jako imię, inicjał drugiego imienia i nazwisko. Ta cecha jakości danych upraszcza stosowanie standardów i redukuje brakujące wartości.]
Anomalia danych. Pole musi być używane wyłącznie w celu, dla którego zostało zdefiniowane. Jeżeli pole Adres-3 jest zdefiniowane dla ewentualnej trzeciej linii adresu dla długich adresów, wówczas tego pola należy używać wyłącznie do zapisu trzeciej linii adresu. Nie należy go używać do wprowadzania numeru telefonu lub faksu dla klienta.
[Anomalia danych. Pole może być używane wyłącznie w celu, dla którego zostało zdefiniowane. Jeżeli pole Adres-3 jest zdefiniowane dla ewentualnej trzeciej linii adresowej dla długich adresów, to pole to będzie wykorzystywane jedynie do zapisania trzeciej linii adresowej. Nie należy go używać do wprowadzania numeru telefonu lub faksu klienta.]
Przejrzystość. Element danych może posiadać wszystkie inne cechy danych jakościowych, ale jeśli użytkownicy nie rozumieją jasno jego znaczenia, wówczas element danych nie ma dla nich żadnej wartości. Właściwe konwencje nazewnictwa pomagają zapewnić dobre zrozumienie elementów danych przez użytkowników.
[Przejrzystość. Element danych może posiadać wszystkie inne cechy dobrych danych, ale jeśli użytkownicy nie rozumieją jasno jego znaczenia, wówczas element danych nie ma dla nich żadnej wartości. Prawidłowe konwencje nazewnictwa pomagają użytkownikom dobrze zrozumieć elementy danych.]
Aktualny. Użytkownicy decydują o aktualności danych. Jeżeli użytkownicy oczekują, że dane o wymiarach klienta nie będą starsze niż jeden dzień, zmiany danych klientów w systemach źródłowych muszą być codziennie nanoszone w hurtowni danych.
[W odpowiednim czasie. Użytkownicy decydują o aktualności danych. Jeśli użytkownicy oczekują, że dane wymiaru klienta nie będą starsze niż jeden dzień, zmiany danych klientów w systemach źródłowych powinny być codziennie nanoszone do hurtowni danych.]
Przydatność. Każdy element danych w hurtowni danych musi spełniać pewne wymagania dotyczące zbioru użytkowników. Element danych może być dokładny i wysokiej jakości, ale jeśli nie ma wartości dla użytkowników, wówczas nie ma potrzeby, aby ten element danych znajdował się w hurtowni danych.
[Pożytek. Każdy element danych w magazynie danych musi spełniać pewne wymagania dotyczące kolekcji użytkownika. Element danych może być dokładny i wysokiej jakości, ale jeśli nie zapewnia wartości użytkownikom, nie jest konieczne, aby ten element danych znajdował się w hurtowni danych.]
Przestrzeganie zasad integralności danych. Dane przechowywane w relacyjnych bazach danych systemów źródłowych muszą spełniać zasady integralności podmiotowej i integralności referencyjnej. Każda tabela, która dopuszcza wartość null jako klucz podstawowy, nie ma integralności jednostki. Integralność referencyjna wymusza prawidłowe ustanowienie relacji rodzic–dziecko. W relacji klient-zamówienie integralność referencyjna zapewnia istnienie klienta dla każdego zamówienia w bazie danych.
[Przestrzeganie zasad integralności danych. Dane przechowywane w relacyjnych bazach danych systemów źródłowych muszą spełniać zasady integralności encji i integralności referencyjnej. Każda tabela, która dopuszcza wartość null jako klucz podstawowy, nie ma integralności jednostki. Integralność referencyjna wymusza prawidłowe nawiązanie relacji pomiędzy rodzicami i dziećmi. W relacji klient-zamówienie integralność referencyjna zapewnia istnienie klienta dla każdego zamówienia w bazie danych.]
4. Jakość czyszczenia danych
Jakość czyszczenia danych jest dość problematyczną kwestią w przypadku bigdata. Odpowiedź na pytanie, jaki stopień oczyszczenia danych jest niezbędny do wykonania zadania, jest kluczowa dla każdego analityka danych. W większości aktualnych problemów każdy analityk ustala to sam i jest mało prawdopodobne, aby ktokolwiek z zewnątrz był w stanie ocenić ten aspekt w jego rozwiązaniu. Jednak dla zadania w tej sprawie kwestia ta była niezwykle ważna, ponieważ wiarygodność danych prawnych powinna zmierzać do jednego.
Rozważenie technologii testowania oprogramowania w celu określenia niezawodności operacyjnej. Dziś tych modeli jest więcej . Wiele modeli wykorzystuje model obsługi roszczeń:
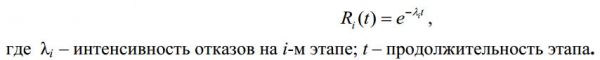
Rys.. 6
Myśląc w ten sposób: „Jeśli znaleziony błąd jest zdarzeniem podobnym do zdarzenia awarii w tym modelu, to jak znaleźć analogię parametru t?” I skompilowałem następujący model: Wyobraźmy sobie, że czas potrzebny testerowi na sprawdzenie jednego rekordu wynosi 1 minutę (dla danej bazy danych), a następnie na znalezienie wszystkich błędów będzie potrzebował 365 494 minut, czyli w przybliżeniu 3 lata i 3 miesięcy czasu pracy. Jak rozumiemy jest to bardzo duży nakład pracy i koszty sprawdzenia bazy będą zaporowe dla kompilatora tej bazy. W tej refleksji pojawia się ekonomiczne pojęcie kosztów i po analizie doszedłem do wniosku, że jest to dość skuteczne narzędzie. W oparciu o prawo ekonomii: „Wielkość produkcji (w jednostkach), przy której przedsiębiorstwo osiąga maksymalny zysk, znajduje się w punkcie, w którym krańcowy koszt wytworzenia nowej jednostki produkcji jest porównywany z ceną, jaką może uzyskać przedsiębiorstwo dla nowej jednostki.” Wychodząc z postulatu, że znalezienie każdego kolejnego błędu wymaga coraz częstszego sprawdzania zapisów, jest to czynnik kosztowy. Oznacza to, że postulat przyjęty w testowaniu modeli nabiera fizycznego znaczenia według następującego schematu: jeśli aby znaleźć i-ty błąd trzeba było sprawdzić n rekordów, to aby znaleźć kolejny (i+1) błąd konieczne będzie aby sprawdzić m rekordów i jednocześnie n
- Gdy liczba sprawdzanych rekordów przed wykryciem nowego błędu ustabilizuje się;
- Gdy liczba rekordów sprawdzanych przed znalezieniem kolejnego błędu wzrośnie.
Aby określić wartość krytyczną, sięgnąłem po koncepcję wykonalności ekonomicznej, którą w tym przypadku, korzystając z koncepcji kosztów społecznych, można sformułować w następujący sposób: „Koszty skorygowania błędu powinien ponieść podmiot gospodarczy, który może to zrobić to po najniższej cenie.” Mamy jednego agenta - testera, który spędza 1 minutę na sprawdzaniu jednego rekordu. W kategoriach pieniężnych, jeśli zarabiasz 6000 rubli dziennie, będzie to 12,2 rubla. (mniej więcej dzisiaj). Pozostaje określić drugą stronę równowagi w prawie gospodarczym. Rozumowałem w ten sposób. Istniejący błąd będzie wymagał od zainteresowanej osoby włożenia wysiłku w jego naprawienie, czyli właściciela nieruchomości. Załóżmy, że wymaga to 1 dnia działania (złóż wniosek, otrzymaj poprawiony dokument). Wtedy ze społecznego punktu widzenia jego koszty będą równe przeciętnemu dziennemu wynagrodzeniu. Średnie naliczone wynagrodzenie w Chanty-Mansyjskim Okręgu Autonomicznym 73285 rub. lub 3053,542 rubli dziennie. W związku z tym otrzymujemy wartość krytyczną równą:
3053,542: 12,2 = 250,4 jednostek rekordów.
Oznacza to, że ze społecznego punktu widzenia, jeśli tester sprawdził 251 rekordów i znalazł jeden błąd, jest to równoznaczne z naprawieniem tego błędu przez użytkownika. Odpowiednio, jeśli tester spędził czas równy sprawdzeniu 252 rekordów w celu znalezienia kolejnego błędu, wówczas w tym przypadku lepiej jest przerzucić koszt korekty na użytkownika.
Przedstawiono tu podejście uproszczone, gdyż ze społecznego punktu widzenia należy uwzględnić całą wartość dodatkową wygenerowaną przez każdego specjalistę, czyli koszty obejmujące podatki i składki społeczne, ale model jest jasny. Konsekwencją tej relacji jest następujący wymóg stawiany specjalistom: specjalista z branży IT musi mieć wynagrodzenie wyższe od średniej krajowej. Jeśli jego pensja jest niższa niż średnia pensja potencjalnych użytkowników bazy danych, to on sam musi osobiście sprawdzić całą bazę danych.
Stosując opisane kryterium, powstaje pierwsze wymaganie dotyczące jakości bazy danych:
ja(tr). Udział błędów krytycznych nie powinien przekraczać 1/250,4 = 0,39938%. Trochę mniej niż złoto w przemyśle. A pod względem fizycznym nie ma więcej niż 1459 rekordów z błędami.
Ekonomiczny odwrót.
Tak naprawdę, popełniając taką ilość błędów w ewidencji, społeczeństwo godzi się na straty ekonomiczne w wysokości:
1459*3053,542 = 4 455 118 rubli.
O kwocie tej decyduje fakt, że społeczeństwo nie posiada narzędzi pozwalających na redukcję tych kosztów. Wynika z tego, że jeśli ktoś posiada technologię, która pozwala mu zmniejszyć liczbę rekordów z błędami do np. 259, to pozwoli to społeczeństwu zaoszczędzić:
1200*3053,542 = 3 664 250 rubli.
Ale jednocześnie może poprosić o swój talent i pracę, cóż, powiedzmy - 1 milion rubli.
Oznacza to, że koszty społeczne zmniejszają się poprzez:
3 664 250 – 1 000 000 = 2 664 250 rubli.
W istocie efekt ten stanowi wartość dodaną wynikającą z zastosowania technologii BigDat.
Jednak tutaj należy wziąć pod uwagę, że jest to efekt społeczny, a właścicielem bazy są władze gmin, których dochody z tytułu korzystania z nieruchomości zarejestrowanych w tej bazie, według stawki 0,3%, wynoszą: 2,778 miliarda rubli/ rok. A te koszty (4 455 118 rubli) nie przeszkadzają mu zbytnio, ponieważ przechodzą na właścicieli nieruchomości. I w tym aspekcie twórca bardziej udoskonalających technologii w Bigdata będzie musiał wykazać się umiejętnością przekonania właściciela tej bazy danych, a takie rzeczy wymagają nie lada talentu.
W tym przykładzie algorytm oceny błędów został wybrany w oparciu o model Schumanna [2] weryfikacji oprogramowania podczas badania niezawodności. Ze względu na jego powszechność w Internecie i możliwość uzyskania niezbędnych wskaźników statystycznych. Metodologia została zaczerpnięta z Monakhova Yu.M. „Stabilność funkcjonalna systemów informatycznych”, patrz pod spoilerem na ryc. 7-9.
Ryż. 7 – 9 Metodologia modelu Schumanna


W drugiej części tego materiału przedstawiono przykład czyszczenia danych, w którym uzyskuje się wyniki z wykorzystaniem modelu Schumanna.
Przedstawię uzyskane wyniki:
Szacunkowa liczba błędów N = 3167 n.
Parametr C, lambda i funkcja niezawodności:
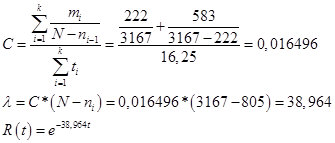
Ris.17
Zasadniczo lambda jest rzeczywistym wskaźnikiem intensywności wykrywania błędów na każdym etapie. Jeśli spojrzeć na drugą część, oszacowanie tego wskaźnika wyniosło 42,4 błędów na godzinę, co jest dość porównywalne ze wskaźnikiem Schumanna. Powyżej ustalono, że tempo znajdowania błędów przez programistę nie powinno być mniejsze niż 1 błąd na 250,4 rekordów przy sprawdzaniu 1 rekordu na minutę. Stąd krytyczna wartość lambda dla modelu Schumanna:
60 / 250,4 = 0,239617.
Oznacza to, że należy przeprowadzić procedury wykrywania błędów, dopóki lambda z istniejących 38,964 nie spadnie do 0,239617.
Lub do czasu, aż wskaźnik N (potencjalna liczba błędów) minus n (skorygowana liczba błędów) spadnie poniżej przyjętego przez nas progu - 1459 szt.
literatura
- Monakhov, Yu M. Stabilność funkcjonalna systemów informatycznych. W 3 godziny Część 1. Niezawodność oprogramowania: podręcznik. zasiłek / Yu M. Monachow; Władim. państwo uniw. – Władimir: Izvo Vladim. państwo Uniwersytet, 2011. – 60 s. – ISBN 978-5-9984-0189-3.
- Martin L. Shooman, „Modele probabilistyczne do przewidywania niezawodności oprogramowania”.
- Podstawy hurtowni danych dla specjalistów IT / Paulraj Ponniah. — wyd. 2.
Źródło: www.habr.com
