

Wprowadzenie do systemów operacyjnych
Hej Habra! Pragnę zwrócić Państwa uwagę na cykl artykułów-przekładów jednej ciekawej moim zdaniem literatury - OSTEP. Ten materiał dość szczegółowo omawia działanie uniksowych systemów operacyjnych, a mianowicie pracę z procesami, różnymi programami planującymi, pamięcią i innymi podobnymi komponentami, które składają się na nowoczesny system operacyjny. Oryginał wszystkich materiałów można zobaczyć tutaj . Zaznaczam, że tłumaczenie zostało wykonane nieprofesjonalnie (dość swobodnie), ale mam nadzieję, że zachowałem ogólny sens.
Pracę laboratoryjną na ten temat można znaleźć tutaj:
Inne części:
Możesz również sprawdzić mój kanał na =)
Alarm! Jest laboratorium do tego wykładu! Patrzeć
API procesu
Spójrzmy na przykład tworzenia procesu w systemie UNIX. Odbywa się to poprzez dwa wywołania systemowe widelec() и Exec ().
Zadzwoń do widelca()

Rozważmy program wykonujący wywołanie fork(). Wynik jego wykonania będzie następujący.
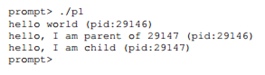
Na początek wchodzimy do funkcji main() i wypisujemy ciąg znaków na ekran. Linia zawiera identyfikator procesu, który w oryginale nazywa się PID lub identyfikator procesu. Identyfikator ten jest używany w systemie UNIX w odniesieniu do procesu. Następne polecenie wywoła fork(). W tym momencie tworzona jest niemal dokładna kopia procesu. W przypadku systemu operacyjnego wygląda na to, że w systemie działają 2 kopie tego samego programu, co z kolei spowoduje wyjście z funkcji fork(). Nowo utworzony proces potomny (w stosunku do procesu nadrzędnego, który go utworzył) nie będzie już wykonywany, zaczynając od funkcji main(). Należy pamiętać, że proces potomny nie jest dokładną kopią procesu macierzystego, w szczególności ma własną przestrzeń adresową, własne rejestry, własny wskaźnik do instrukcji wykonywalnych i tym podobne. Zatem wartość zwrócona wywołującemu funkcję fork() będzie inna. W szczególności proces nadrzędny otrzyma w zamian wartość PID procesu potomnego, a proces potomny otrzyma wartość równą 0. Używając tych kodów powrotu, możesz następnie oddzielić procesy i zmusić każdy z nich do wykonywania własnej pracy . Jednakże wykonanie tego programu nie jest ściśle określone. Po podzieleniu na 2 procesy system operacyjny zaczyna je monitorować, a także planować ich pracę. Jeśli zostanie wykonany na procesorze jednordzeniowym, jeden z procesów, w tym przypadku nadrzędny, będzie kontynuował pracę, a wówczas kontrolę przejmie proces potomny. Po ponownym uruchomieniu sytuacja może być inna.
Zadzwoń, czekaj()
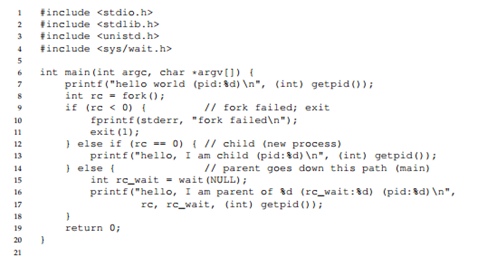
Rozważ następujący program. W tym programie ze względu na obecność połączenia czekać() Proces nadrzędny zawsze będzie czekał na zakończenie procesu potomnego. W tym przypadku otrzymamy na ekranie ściśle określony tekst

wywołanie exec().
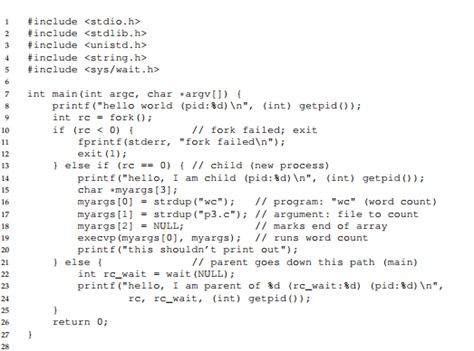
Rozważ wyzwanie Exec (). To wywołanie systemowe przydaje się, gdy chcemy uruchomić zupełnie inny program. Tutaj zadzwonimy execvp() aby uruchomić program wc, który jest programem do liczenia słów. Co się stanie, gdy zostanie wywołane exec()? Do tego wywołania przekazywana jest nazwa pliku wykonywalnego i niektóre parametry jako argumenty. Następnie ładowany jest kod i dane statyczne z tego pliku wykonywalnego, a jego własny segment z kodem zostaje nadpisany. Pozostałe obszary pamięci, takie jak stos i sterta, są ponownie inicjowane. Następnie system operacyjny po prostu wykonuje program, przekazując mu zestaw argumentów. Nie utworzyliśmy więc nowego procesu, po prostu przekształciliśmy aktualnie działający program w inny działający program. Po wykonaniu wywołania exec() w potomku wygląda to tak, jakby oryginalny program w ogóle nie działał.
Ta komplikacja podczas uruchamiania jest całkowicie normalna w przypadku powłoki Uniksa i umożliwia tej powłoce wykonanie kodu po wywołaniu widelec(), ale przed rozmową Exec (). Przykładem takiego kodu byłoby dostosowanie środowiska powłoki do potrzeb uruchamianego programu, jeszcze przed jego uruchomieniem.
Powłoka - tylko program użytkownika. Pokazuje Ci linię zaproszenia i czeka, aż coś w niej napiszesz. W większości przypadków, jeśli wpiszesz tam nazwę programu, powłoka znajdzie jego lokalizację, wywoła metodę fork(), a następnie wywoła jakiś typ exec(), aby utworzyć nowy proces i poczekać na jego zakończenie za pomocą czekaj() zadzwoń. Kiedy proces potomny zakończy działanie, powłoka powróci z wywołania Wait(), ponownie wyświetli monit i zaczeka na wprowadzenie następnego polecenia.
Podział fork() i exec() umożliwia powłoce wykonanie następujących czynności, na przykład:
wc plik > nowy_plik.
W tym przykładzie dane wyjściowe programu wc są przekierowywane do pliku. Sposób, w jaki powłoka osiąga to, jest dość prosty — poprzez utworzenie procesu potomnego przed wywołaniem Exec (), powłoka zamyka standardowe wyjście i otwiera plik nowy plik, a zatem całe wyjście z dalej działającego programu wc zostanie przekierowany do pliku zamiast na ekran.
rura uniksowa implementowane są w podobny sposób, z tą różnicą, że wykorzystują wywołanie pipe(). W tym przypadku strumień wyjściowy procesu zostanie podłączony do kolejki potoków zlokalizowanej w jądrze, do której zostanie podłączony strumień wejściowy innego procesu.
Źródło: www.habr.com
