

Niedawno opowiadałam Wam, jak to zrobić, korzystając ze standardowych przepisów z bazy danych PostgreSQL. Dziś porozmawiamy o tym, jak nagrywanie może odbywać się wydajniej w bazie danych bez stosowania jakichkolwiek „skrętów” w konfiguracji – po prostu poprzez odpowiednią organizację przepływów danych.

#1. Sekcje
Artykuł o tym jak i dlaczego warto organizować już było, tutaj porozmawiamy o praktyce stosowania niektórych podejść w naszym .
„Rzeczy z przeszłości…”
Początkowo, jak każdy MVP, nasz projekt zaczynał się przy dość niewielkim obciążeniu - monitorowanie odbywało się tylko dla dziesięciu najbardziej krytycznych serwerów, wszystkie tabele były stosunkowo niewielkie... Jednak z biegiem czasu liczba monitorowanych hostów stawała się coraz większa i po raz kolejny próbowaliśmy zrobić coś z jednym z nich tabele o rozmiarze 1.5 TB, zdaliśmy sobie sprawę, że choć można tak dalej żyć, jest to jednak bardzo niewygodne.
Czasy były prawie epickie, różne wersje PostgreSQL 9.x były istotne, więc całe partycjonowanie musiało być wykonane „ręcznie” – poprzez dziedziczenie tabeli i wyzwalacze routing z dynamiką EXECUTE.
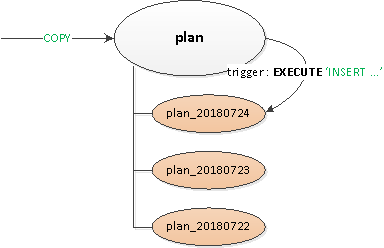
Powstałe rozwiązanie okazało się na tyle uniwersalne, że dało się je przełożyć na wszystkie tabele:
- Zadeklarowano pustą tabelę nadrzędną „nagłówka”, która opisywała wszystko niezbędne indeksy i wyzwalacze.
- Rekord z punktu widzenia klienta został wykonany w tabeli „root” i wykorzystany wewnętrznie wyzwalacz routingu
BEFORE INSERTzapis został „fizycznie” wstawiony do wymaganej sekcji. Jeżeli jeszcze czegoś takiego nie było to złapaliśmy wyjątek i... - … używając została utworzona w oparciu o szablon tabeli nadrzędnej sekcja z ograniczeniem żądanej datytak, aby w przypadku pobrania danych odczyt odbywał się tylko w nich.
PG10: pierwsza próba
Jednak partycjonowanie poprzez dziedziczenie historycznie nie było zbyt dobrze dostosowane do pracy z aktywnym strumieniem zapisu lub dużą liczbą partycji potomnych. Na przykład możesz przypomnieć sobie, że miał algorytm wyboru wymaganej sekcji złożoność kwadratowa, że działa z ponad 100 sekcjami, sam rozumiesz, jak...
W PG10 sytuacja ta została znacznie zoptymalizowana poprzez wdrożenie wsparcia . Dlatego od razu próbowaliśmy go zastosować zaraz po migracji magazynu, ale…
Jak się okazało po przekopaniu instrukcji, natywnie partycjonowana tabela w tej wersji to:
- nie obsługuje opisów indeksów
- nie obsługuje na nim wyzwalaczy
- nie może być niczyim „potomkiem”
- nie wspieraj
INSERT ... ON CONFLICT - nie może wygenerować sekcji automatycznie
Otrzymawszy bolesne uderzenie grabiami w czoło, zdaliśmy sobie sprawę, że bez modyfikacji aplikacji nie da się obejść i odłożyliśmy dalsze badania na sześć miesięcy.
PG10: druga szansa
Zaczęliśmy więc rozwiązywać problemy, które pojawiały się jeden po drugim:
- Ponieważ wyzwalacze i
ON CONFLICTOdkryliśmy, że nadal ich potrzebujemy tu i tam, więc zrobiliśmy etap pośredni, aby je opracować tabela proxy. - Pozbyłem się „routowania” w wyzwalaczach - czyli od
EXECUTE. - Wyjęli to osobno tabela szablonów ze wszystkimi indeksamitak, że nie ma ich nawet w tabeli proxy.
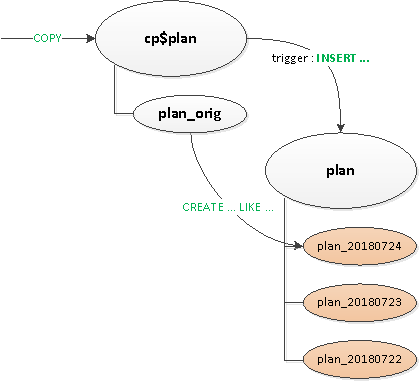
Wreszcie, po tym wszystkim, natywnie podzieliliśmy główny stół. Utworzenie nowej sekcji nadal pozostaje w gestii aplikacji.
Słowniki „piłowania”.
Jak w każdym systemie analitycznym i u nas tak było „fakty” i „cięcia” (słowniki). W naszym przypadku w tej roli pełnili m.in. podobne powolne zapytania lub tekst samego zapytania.
„Fakty” już od dawna były dzielone dzień na dzień, więc spokojnie usuwaliśmy nieaktualne sekcje, a one nam nie przeszkadzały (logi!). Ale był problem ze słownikami...
Nie chcę powiedzieć, że było ich dużo, ale w przybliżeniu Ze 100 TB „faktów” powstał słownik o pojemności 2.5 TB. Z takiej tabeli nie da się wygodnie niczego usunąć, nie da się tego skompresować w odpowiednim czasie, a pisanie do niej stopniowo staje się wolniejsze.
Podobnie jak słownik... w nim każdy wpis powinien być zaprezentowany dokładnie raz... i jest to poprawne, ale!.. Nikt nam nie zabrania posiadania osobny słownik na każdy dzień! Tak, zapewnia to pewną redundancję, ale pozwala:
- pisz/czytaj szybciej ze względu na mniejszy rozmiar sekcji
- zużywają mniej pamięci poprzez pracę z bardziej zwartymi indeksami
- przechowywać mniej danych ze względu na możliwość szybkiego usunięcia przestarzałych
W wyniku całego kompleksu środków Obciążenie procesora spadło o ~30%, obciążenie dysku o ~50%:
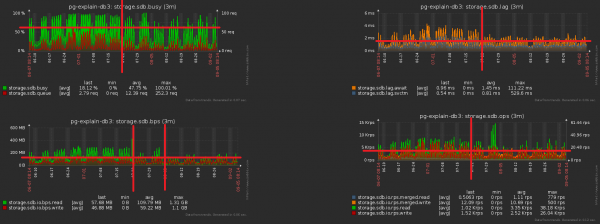
Jednocześnie kontynuowaliśmy zapis do bazy danych dokładnie tego samego, tylko przy mniejszym obciążeniu.
#2. Ewolucja i refaktoryzacja baz danych
Więc zdecydowaliśmy się na to, co mamy każdy dzień ma swój własny rozdział z danymi. Faktycznie, CHECK (dt = '2018-10-12'::date) — istnieje także klucz podziału i warunek, aby rekord znalazł się w określonej sekcji.
Ponieważ wszystkie raporty w naszym serwisie budowane są w kontekście konkretnej daty, indeksy dla nich od „czasów niepartycjonowanych” są wszelkiego rodzaju (Serwer, Data, szablon planu), (Serwer, Data, węzeł planu), (Data, klasa błędu, serwer), ...
Ale teraz żyją na każdym odcinku Twoje kopie każdy taki indeks... I w każdej sekcji data jest stała... Okazuje się, że teraz jesteśmy w każdym takim indeksie po prostu wprowadź stałą jako jedno z pól, co zwiększa zarówno jego objętość, jak i czas wyszukiwania, ale nie przynosi żadnego rezultatu. Zostawili grabie samym sobie, ups...

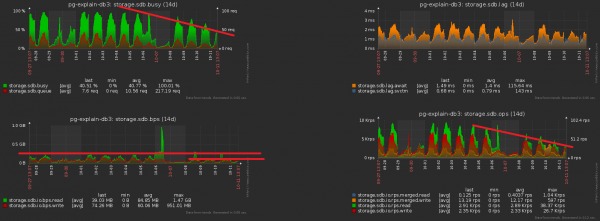
Kierunek optymalizacji jest oczywisty – prosty usuń pole daty ze wszystkich indeksów na podzielonych tabelach. Biorąc pod uwagę nasze wolumeny, zysk jest ok 1 TB/tydzień!
A teraz zauważmy, że ten terabajt trzeba było jeszcze jakoś zapisać. To znaczy my także dysk powinien teraz ładować mniej! To zdjęcie wyraźnie pokazuje efekt uzyskany po czyszczeniu, któremu poświęciliśmy tydzień:
#3. „Rozkładanie” obciążenia szczytowego
Jednym z największych problemów obciążonych systemów jest redundantna synchronizacja niektóre operacje, które tego nie wymagają. Czasem „bo nie zauważyli”, czasem „tak było łatwiej”, ale prędzej czy później trzeba się tego pozbyć.
Powiększmy poprzedni obrazek i zobaczmy, że mamy dysk „pompuje” pod obciążeniem z podwójną amplitudą pomiędzy sąsiednimi próbkami, co oczywiście „statystycznie” nie powinno mieć miejsca przy takiej liczbie operacji:
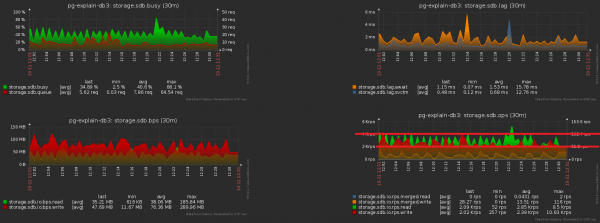
Jest to dość łatwe do osiągnięcia. Rozpoczęliśmy już monitoring prawie 1000 serwerów, każdy jest przetwarzany przez oddzielny wątek logiczny i każdy wątek resetuje zgromadzone informacje, które mają być wysyłane do bazy danych z określoną częstotliwością, mniej więcej tak:
setInterval(sendToDB, interval)Problem polega właśnie na tym, że wszystkie wątki rozpoczynają się mniej więcej w tym samym czasie, więc czas ich wysłania prawie zawsze pokrywa się „do rzeczy”. Ups #2...
Na szczęście można to dość łatwo naprawić, dodanie „losowego” rozbiegu z czasem:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Buforujemy to, czego potrzebujemy
Trzecim tradycyjnym problemem związanym z dużym obciążeniem jest brak pamięci podręcznej gdzie on jest mógł być.
Na przykład umożliwiliśmy analizę pod kątem węzłów planu (wszystkie te Seq Scan on users), ale od razu pomyśl, że to w większości to samo - zapomnieli.
Nie, oczywiście, nic nie jest ponownie zapisywane w bazie danych, powoduje to odcięcie wyzwalacza INSERT ... ON CONFLICT DO NOTHING. Ale te dane nadal docierają do bazy danych i są niepotrzebne czytanie w celu sprawdzenia konfliktu musieć zrobić. Ups #3...
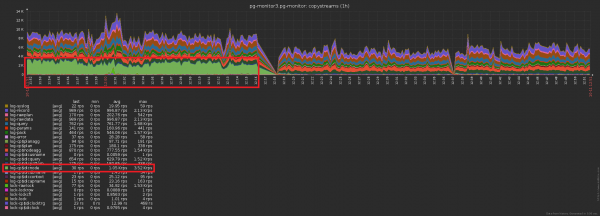
Różnica w liczbie rekordów wysłanych do bazy danych przed/po włączeniu buforowania jest oczywista:
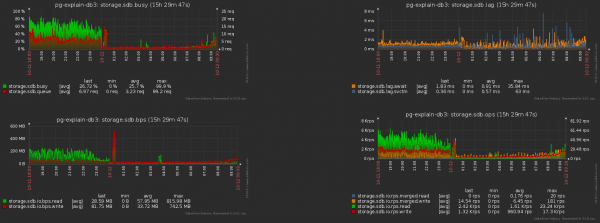
A to towarzyszący spadek obciążenia pamięci:
Razem
„Terabajt dziennie” brzmi po prostu przerażająco. Jeśli zrobisz wszystko dobrze, to jest to sprawiedliwe 2^40 bajtów / 86400 sekund = ~12.5 MB/sże nawet śruby IDE komputera stacjonarnego trzymają się. 🙂
Ale tak na poważnie, nawet przy dziesięciokrotnym „przekrzywieniu” obciążenia w ciągu dnia, bez problemu można sprostać możliwościom nowoczesnych dysków SSD.

Źródło: www.habr.com
